







 这个博客介绍了如何将curl命令转换为Python代码,以便在Python中执行HTTP请求。它提供了一个名为`curl_to_python`的函数,该函数接受curl命令作为输入并生成等效的requests库代码。此外,还提供了`res_to_curl`函数,用于将requests响应转换回curl命令。代码示例包括处理cookies、headers和不同方法的请求。
这个博客介绍了如何将curl命令转换为Python代码,以便在Python中执行HTTP请求。它提供了一个名为`curl_to_python`的函数,该函数接受curl命令作为输入并生成等效的requests库代码。此外,还提供了`res_to_curl`函数,用于将requests响应转换回curl命令。代码示例包括处理cookies、headers和不同方法的请求。
是的,你没看错,读起来有点拗口,但真的会很好用。
这是转换浏览器中复制的curl语句的代码
代码来源于curltopy库的源代码。需要的朋友可以前往github查看
安装后发现直接按照他的介绍运行不起来,所以这里修改了一些地方,才可以正常使用!
如何复制curl命令
复制的时候选curl bash,另外一个cmd以^作为换行,会影响解析
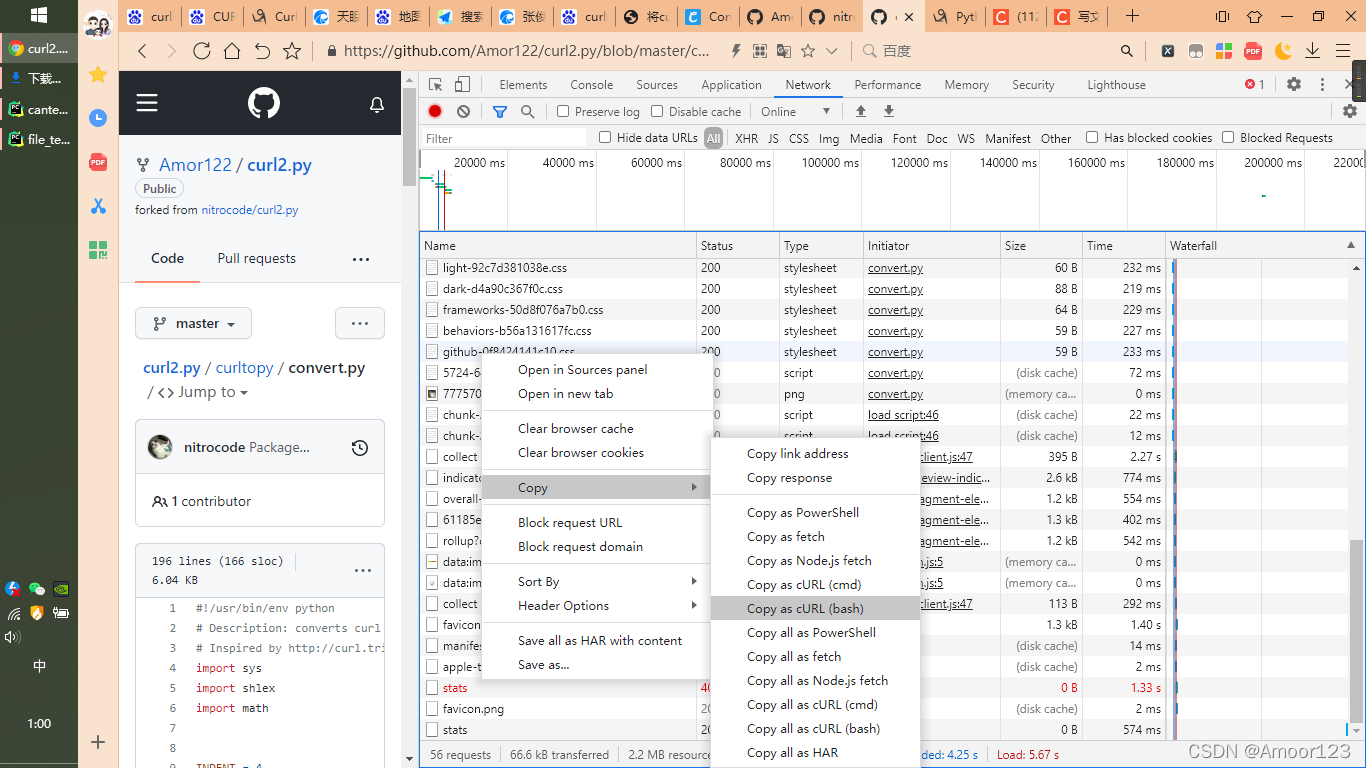
如果是Charles这种工具里,选第二个带request的选项,将复制出来的字符串的url放到curl 开头,不然url会解析错误
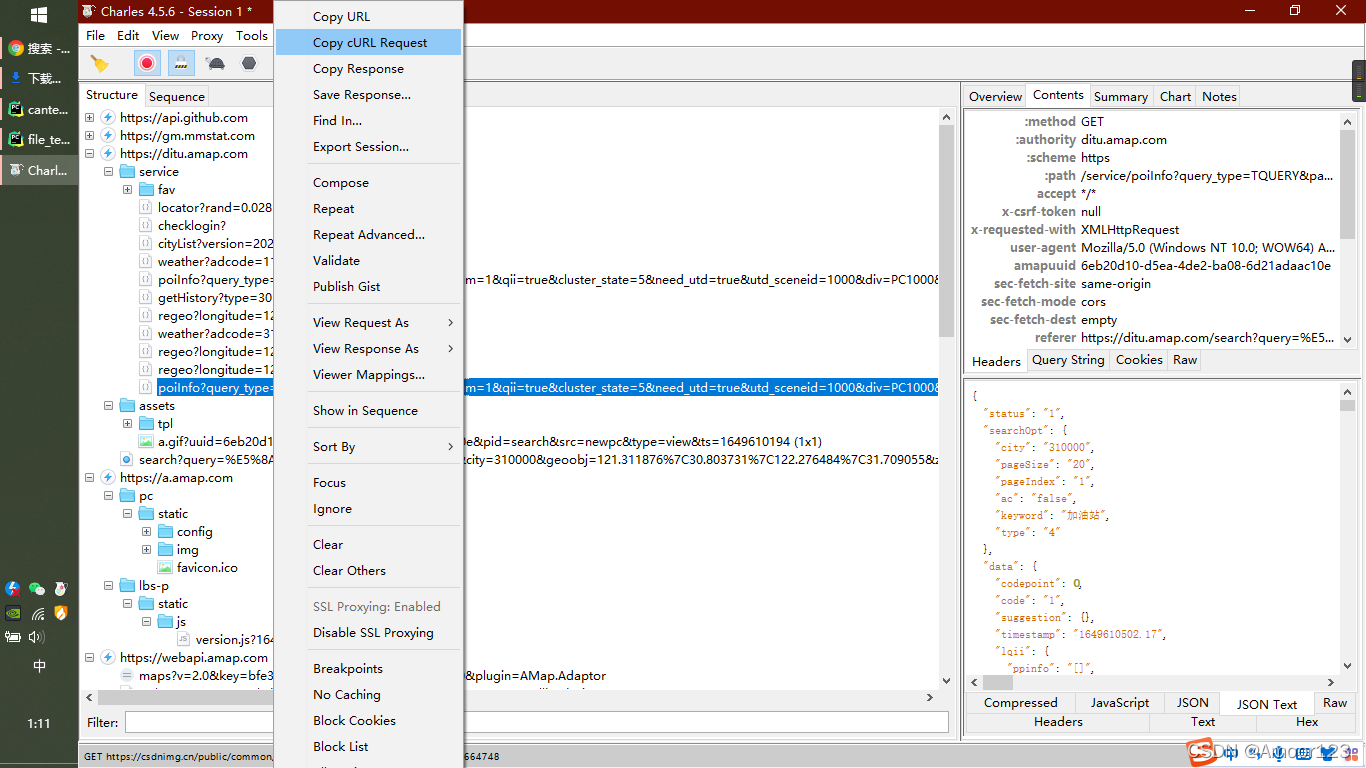
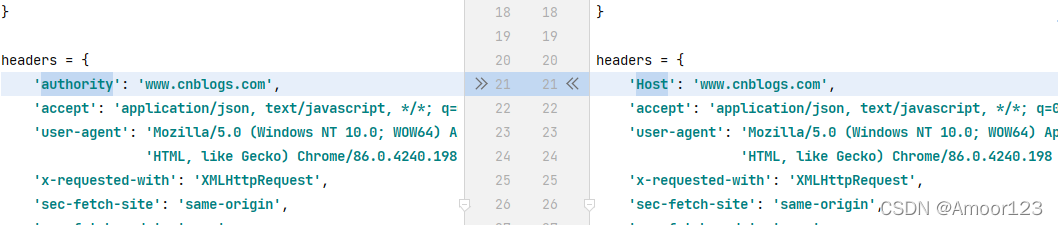
charles的和浏览器的区别
一个是charles喜欢用host,浏览器喜欢用authority。
通俗理解就是 host 是 authority 的子串,authority 可以包含端口,而 host 不含端口。
参考:
https://blog.csdn.net/qq_26810645/article/details/106853573
代码段
下面是代码
#!/usr/bin/env python
# Description: converts curl statements to python code
# Inspired by http://curl.trillworks.com/
import sys
import shlex
import math
from urllib3.connectionpool import xrange
INDENT = 4
PRINTLINE = 80
def print_key_val(init, value, pre_indent=0, end=','):
"""Print the key and value and insert it into the code list.
:param init: string to initialize value e.g.
"'key': " or "url = "
:param value: value to print in the dictionary
:param pre_indent: optional param to set the level of indentation,
defaults to 0
:param end: optional param to set the end, defaults to comma
"""
indent = INDENT * pre_indent
# indent is up to the first single quote
start = indent + len(init)
# 80 is the print line minus the starting indent
# minus 2 single quotes, 1 space, and 1 backslash
left = PRINTLINE - start - 4
code = []
code.append("{i}{s}'{v}'".format(i=" " * indent, s=init, v=value[:left]))
if len(value) > left:
code[-1] += " \\"
# figure out lines by taking the length of the value and dividing by
# chars left to the print line
lines = int(math.ceil(len(value) / float(left)))
for i in xrange(1, lines):
delim = " \\"
if i == lines - 1:
delim = end
code.append("{i}'{v}'{d}".format(i=" " * start,
v=value[i * left:(i + 1) * left],
d=delim))
else:
code[-1] += end
return code
def dict_to_code(name, simple_dict):
"""Converts a dictionary to a python compatible key value pair
>>> code = dict_to_code("cookies", cookies)
:param name: name of the variable
:param simple_dict: dictionary to iterate
:return: python compatible code in a list
"""
code = []
if simple_dict:
code.append("{} = {{".format(name))
# check for python3
try:
for k, v in simple_dict.items():
init = "'{k}': ".format(k=k)
code += print_key_val(init, v, 1)
except:
for k, v in simple_dict.iteritems():
init = "'{k}': ".format(k=k)
code += print_key_val(init, v, 1)
code.append("}\n")
return code
def create_request(url, method, cookies, headers, data=None):
"""Create request code from params
>>> code = create_request("https://localhost:8080", None, "get", None,
None)
:param url: url requested
:param method: method used e.g. get, post, delete, put
:param cookies: dict of each cookie
:param headers: dict of each header
:param data: optional param to provided data to the request
:return: python compatible code in a list
"""
code = []
key_value = "{i}'{k}': '{v}'"
# check for cookies
code += dict_to_code("cookies", cookies)
# check for headers
code += dict_to_code("headers", headers)
code += print_key_val("url = ", url, end='')
resstr = "res = requests.{}(url, ".format(method)
append = "headers=headers"
# if there are cookies / data, then attach it to the requests call
if cookies:
append += ", cookies=cookies"
if data:
code.append("data = '{}'".format(data))
append += ", data=data"
code.append(resstr + append + ")")
code.append("print(res.content)\n")
return code
def curl_to_python(command):
"""Convert curl command to python script.
>>> code = curl_to_python(command)
>>> print('\n'.join(code))
:param command: curl command exported from Chrome's Dev Tools
:return: python compatible code in a list
"""
# remove quotations
args = shlex.split(command)
data = None
# check for method
if '-X' in args:
method = args[args.index('-X') + 1]
elif '--data' in args:
method = 'post'
data = args[args.index('--data') + 1]
else:
method = 'get'
url = args[1]
# gather all the headers
headers = {}
for i, v in enumerate(args):
if '-H' in v:
myargs = args[i + 1].split(':')
headers[myargs[0]] = ''.join(myargs[1:]).strip()
cookies = {}
# gather all the cookies
if 'Cookie' in headers or 'cookie' in headers:
if 'Cookie' in headers:
cookie_key = 'Cookie'
else:
cookie_key = 'cookie'
cookie = headers[cookie_key]
# remove cookies from headers because it will be added separately
del headers[cookie_key]
cookies = dict([c.strip().split('=', 1) for c in cookie.split(';')])
code = []
code.append("#!/usr/bin/env python")
code.append("import requests\n")
code += create_request(url, method, cookies, headers, data)
return code
def res_to_curl(res):
"""converts a requests response to a curl command
>>> res = requests.get('http://www.example.com')
>>> print(res_to_curl(res))
curl 'http://www.example.com/' -X 'GET' ...
Source: http://stackoverflow.com/a/17936634
:param res: request object
"""
req = res.request
command = "curl '{uri}' -X '{method}' -H {headers}"
headers = ["{}: {}".format(k, v) for k, v in req.headers.items()]
header_line = " -H ".join(['"{}"'.format(h) for h in headers])
if req.method == "GET":
return command.format(method=req.method, headers=header_line,
uri=req.url)
else:
command += " --data-binary '{data}'"
return command.format(method=req.method, headers=header_line,
data=req.body, uri=req.url)
def main(command=None):
"""Main entry point.
Purposely didn't use argparse or another command line parser to keep this
script simple.
"""
if not command:
command = 'curl "http://www.example.com" ' + \
'-H "Pragma: no-cache" ' + \
'-H "Accept-Encoding: gzip, deflate" ' + \
'-H "Accept-Language: en-US,en;q=0.8"'
code = curl_to_python(command)
print('\n'.join(code))
with open('my_code.py','w') as f:
f.write('\n'.join(code))
if __name__ == "__main__":
command = """curl 'https://ditu.amap.com/service/poiInfo?query_type=TQUERY&pagesize=20&pagenum=1&qii=true&cluster_state=5&need_utd=true&utd_sceneid=1000&div=PC1000&addr_poi_merge=true&is_classify=true&zoom=9.45&city=310000&geoobj=121.311876%7C30.803731%7C122.276484%7C31.709055&keywords=%E5%8A%A0%E6%B2%B9%E7%AB%99' \
-H 'authority: ditu.amap.com' \
-H 'accept: */*' \
-H 'x-csrf-token: null' \
-H 'x-requested-with: XMLHttpRequest' \
-H 'user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' \
-H 'amapuuid: 6eb20d10-d5ea-4de2-ba08-6d21adaac10e' \
-H 'sec-fetch-site: same-origin' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-dest: empty' \
-H 'referer: https://ditu.amap.com/' \
-H 'accept-language: zh-CN,zh;q=0.9,ja;q=0.8' \
-H 'cookie: cna=1y6ZGixOx2UCAbfAJTLJF0Nz; UM_distinctid=17f54a67a4e7-04145a72489c9b-3e604809-100200-17f54a67a4f38c; guid=4133-d74b-a13a-7da7; xlly_s=1; _uab_collina=164960964925517921868322; l=eBauGa7ng1lUhHXzBOfwhurza77OOIRf_uPzaNbMiOCP9JC257wCW620BVYyCnGVH6rMk37vCcaaByLpsyIVM74V7WXXH1MmndC..; tfstk=cLRlB7NKNLWWleXDCb1SOOJ-sO1lZraPVOB2g4fDtlzfuURViqe4QNn4ViumiJ1..; isg=BF5e6sfNsNrv5ecfQmPZdftmr_SgHyKZeYrQJAjn5KGcK_8Ffa_xqamJIzcnFBqx' \
--compressed"""
main(command)
用法
将你复制的命令行粘贴到最底下的command字符串后运行文件,如果是Charles的,注意将url提前到最前面
生成的代码会放到目录下的my_code.py中,注意查看自己的有没有同名文件
运行这段生成的代码需要安装requests库
如果ssl有问题,尝试requests参数中设置verify=False,并检查是否有代理工具在运行。


















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











