






分布式存储探索
一些概念
CAP理论的真实含义(CAP理论中的P到底是个什么意思? - 四猿外的回答 - 知乎 https://www.zhihu.com/question/54105974/answer/1643846752)
CAP定理指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)这三个要素最多只能同时实现两点。
C:数据一致性。即强一致性,写请求的变化能立即反映到读请求中。
如果节点间无法保证一致性,为了保证系统对外的数据一致性,不能返回任何数据。
A:可用性。正常工作的节点必须在一定时间内返回结果。
节点数据有问题时也必须返回一个结果,可能会返回旧数据。
P:分区容忍性。如果出现了分区问题,我们的分布式存储系统还需要继续运行。不能因为出现了分区问题,整个分布式节点就全部停止服务。
只要有节点通信出现了问题就会发生分区;所以分区容忍性必须被保障。
例子:
-
当一套系统在发生分区故障后,客户端的任何请求都被卡死或者超时,但是,系统的每个节点总是会返回一致的数据,则这套系统就是 CP 系统,经典的比如 Zookeeper。
-
如果一套系统发生分区故障后,客户端依然可以访问系统,但是获取的数据有的是新的数据,有的还是老数据,那么这套系统就是 AP 系统,经典的比如 Eureka。
CAP有很多不足,不能反映真实复杂的工程实践,Dan Pritchett吸取经验,从CAP理论中延伸出了BASE理论。
BASE理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态)和 Eventually Consistent(最终一致性)。BASE 理论是对CAP 中一致性(C)和可用性(A)权衡的结果。
最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。
Basically Available(基本可用)
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。
允许损失部分可用性:
- 响应时间上的损失: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3s。
- 系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
Soft-state(软状态)
软状态指允许系统中的数据存在中间状态(CAP 理论中的数据不一致),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
Eventually Consistent(最终一致性)
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。
因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
分布式存储的简单分类(云存储的底层关键技术有哪些? - int32bit的回答 - 知乎 https://www.zhihu.com/question/25834847/answer/348271275)
-
块存储:即提供裸的块设备服务,裸设备什么都没有,需要用户自己创建分区、创建文件系统、挂载到操作系统才能用,挂一个块存储设备到操作系统,相当于插一个新U盘。只实现了read、write、ioctl等接口。SAN、LVM、Ceph RBD、OpenStack Cinder等都属于块存储服务。
-
文件存储:可以简单理解为分布式文件系统,通常实现了POSIX接口,不需要安装文件系统,直接像NFS一样挂载到操作系统就能用。典型的文件存储如NAS、HDFS、CephFS、GlusterFS、OpenStack Manila等。
-
对象存储:提供Web存储服务,通过HTTP协议访问,只需要Web浏览器即可使用,不需要挂载到本地操作系统,实现的接口如GET、POST、DELETE等,典型的对象存储如百度网盘、S3、OpenStack Swift、Ceph RGW等。
对象存储和键值存储的区别(https://zh.wikipedia.org/wiki/%E5%AF%B9%E8%B1%A1%E5%AD%98%E5%82%A8)
不幸的是,对象存储和键-值存储之间的边界是模糊的,键值存储有时被宽泛地称为对象存储。
传统的块存储接口使用一系列固定大小的块,这些块从0开始编号。数据必须是准确的固定大小,并且可以存储在一个特定的块中,该块由其逻辑块编号(LBN)识别。之后,人们可以通过指定其唯一的LBN来检索该数据块。
在键值存储中,数据是由一个键而不是LBN来识别的。一个键可能是“cat” 或“olive”或“42”。它可以是一个任意长度的任意字节序列。数据(在这里称为值)不需要有固定的大小,也可以是任意长度的任意字节序列。人们通过向数据存储提交密钥和数据(值)来存储数据,随后可以通过提交密钥来检索数据。这个概念在编程语言中可以看到。Python称其为字典,Perl称其为散列,Java和C++称其为map(映射),等等。一些数据存储也实现了键值存储,如Memcached、Redis和CouchDB。
对象存储在两个方面与键值存储相似:
- 首先,对象的标识符或URL(相当于键)可以是一个任意的字符串。
- 第二,数据可以是任意大小的。
然而,键值存储和对象存储之间有几个关键的区别:
- 首先,对象存储还允许人们将一组有限的属性(元数据)与每一个数据联系起来。一个键、值和一组属性的组合被称为一个对象。
- 其次,对象存储为大量的数据(几百兆字节甚至几千兆字节)进行了优化,而对于键值存储来说,value预计相对较小(千兆字节)。
- 最后,对象存储通常提供较弱的一致性保证,如最终一致性,而键值存储提供强一致性。
一些论文
经典论文大全
TODO
一些实例
ZooKeeper中一致性和可用性的权衡(https://blog.csdn.net/u014297175/article/details/119944207)
Zookeeper保证了A可用性、P分区容错性、C中的写入强一致性,丧失了C中的读取强一致性。
- 从一个读写请求分析,保证了A可用性(不用阻塞等待全部follwer同步完成),保证不了数据的C一致性,所以是ap。
- 从zk架构分析,zk在leader选举期间,会暂停对外提供服务(为啥会暂停,因为zk依赖leader来保证数据一致性),所以丢失了可用性,保证了一致性。
- 不严格地说,可以把Zookeeper整体看作是一个CP系统(C是最终一致性)。
Zookeeper写入流程和读取流程另见链接。
GFS设计(https://www.cnblogs.com/yorkyang/p/9889525.html)
GFS是一个典型的集中式分布式文件存储系统。
注意GFS是有一个假设场景的,不是万金油分布式文件系统:
- 服务器都是普通的计算机,不是那么可靠,集群出现节点故障是常态。
- 存储主体是大文件,GB级别以上的文件很常见。
- 顺序读较多,随机读较少。连续写为主,随机写很少。文件很少被修改。
- 高宽带比低延迟更重要。
附GFS论文:https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/gfs-sosp2003.pdf
Ceph简单介绍(https://zhuanlan.zhihu.com/p/42793948)
Ceph是一种软件定义存储(即SDS),可以运行在几乎所有主流的Linux发行版(比如CentOS和Ubuntu)和其它类UNIX操作系统(典型如FreeBSD)。Ceph的分布式基因使其可以轻易管理成百上千个节点、PB级及以上存储容量的大规模集群,同时基于计算的扁平寻址设计使得Ceph客户端可以直接和服务端的任意节点通信,从而避免因为存在访问热点而导致性能瓶颈。
Ceph是一个统一存储系统,即支持传统的块、文件存储协议,例如SAN和NAS;也支持对象存储协议,例如S3和Swift。
SAN是存储区域网络,NAS是网络附加存储。SAN存储设备通过光纤连接,而NAS存储设备通过TCP/IP连接。详见https://zhuanlan.zhihu.com/p/50897964。
S3是Amazon的简单存储服务,Swift是OpenStack的存储设施。
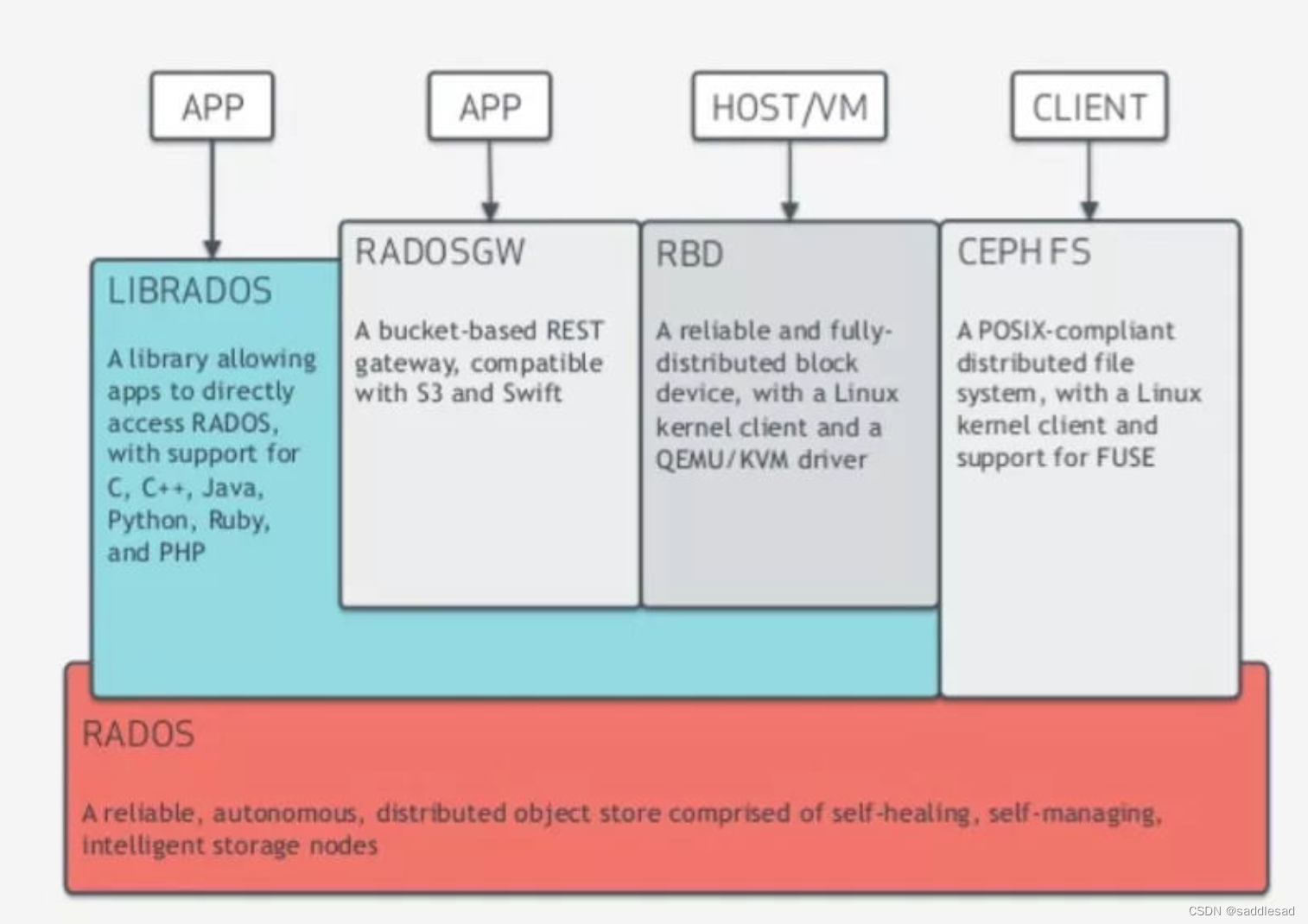
不同于集中式分布式存储系统(例如GFS)维护一张元数据的查找表,ceph使用CRUSH算法实现了动态计算元数据,不需要管理一个集中式的查找表。CRUSH也使得Ceph能够自我管理和自我治愈。当故障区域中的组件故障时,CRUSH能够感知哪个组件故障了,并确定其对集群的影响。无须管理员的任何干预,CRUSH就会进行自我管理和自我疗愈,为因故障而丢失的数据执行恢复操作。
附CRUSH论文http://tom.nos-eastchina1.126.net/weil-crush-sc06.pdf














 1160
1160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









