






下面要讲的字符集主要是下面几种:UTF8,UTF16,GB,ASCII。使用该字符集存储的文件对应的也有点特殊处理,下面会讲到的。对于文件的格式,可以采用Uedit来查看二进制码,下面用存储“abc”的文本文档举例。
ASCII是最普遍是用的一种字符集了,因为在Windows平台上的文本文档默认的都是这个字符集,所有的字符都用单字来表示。没有什么可以讲,就是存储每一个字符对应的ASCII码,文件格式也没有特殊。如下所示
后面的三种格式,可以广义的称为unicode的格式。因为双字节或多个字节来标示一个字符的。当为单纯的字符时,这是文件的内容为

可以看到文件的开头会有两个字节的文件类型的标识符FF FE,这说明这个文件的存储格式是Unicode的。每一个字符的UTF8表示格式都是后面补充00。不同的文件系统的存储方式不尽相同,如果文件的标示符为“FE FF”,那么对应的字母a的表示将是“00 61”了。因为有00的存在,在做文件读取的时候如果readline的话(按照string的风格读取),肯定会在遇到00就认为是“/0”,就结束了。所以Unicode的文件不能简单的读取,只能以二进制的方式读取。
对于GB主要汉字的一种字符集。有自己的对应的字符集。它肯定是双字表示的,无论是在ASCII格式还是UTF8格式的文件中。例如:“你好ABC”在unicode文件格式中
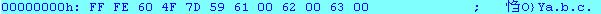
可以看到,汉字就不会简单的像字符一样补充00。至于为什么“联通”会在记事本中保存后显示乱码的原因,大家可以看看二进制码就知道了,因为他的GB字符集对应的正好是“FFFE”,记事本以为它是Unicode的文件,所以就错误的显示了。
UTF8的应用最为广泛,在数据的网络传输的过程中,大量使用UTF8。那么UTF8和ASCII相互转化很简单
//UTF8 to ASCII
DWORD dwNum = WideCharToMultiByte(CP_ACP,0,(LPCWSTR)data+1,-1,NULL,0,NULL,FALSE);
psText = new char[dwNum];
if(!psText)
{
delete []psText;
}
int len = wcslen((LPCWSTR)data+1); //这里用的不是strlen,大小很重要
WideCharToMultiByte(CP_ACP,0,(LPCWSTR)data+1,-1,psText,dwNum,NULL,FALSE);
//ASCII to UTF8
DWORD dwNum;
dwNum = MultiByteToWideChar (CP_ACP, 0 , szXML, -1, NULL, 0);
char *psText;
psText = new char[dwNum*2]; //注意留足够的空间
if(!psText)
{
delete []psText;
}
printf("szXML");
MultiByteToWideChar (CP_ACP, 0 ,szXML,-1,(unsigned short *)psText,dwNum);
如果是GB,那么转化的方式稍微复杂一点。要将GB先转化为UTF16,然后转化为UTF8,函数与上面相同
const char *gbks;
unsigned short *wbuf; //这里不是char,是unsigned short,unsigned short 其实== w_tchar
int wbuf_len;
gbks_len = strlen(gbks);
MultiByteToWideChar(0, 0, gbks, gbks_len, wbuf, wbuf_len); //GB to UTF16
WideCharToMultiByte(CP_UTF8, 0, ucs, ucs_len, (char *)cbuf, cbuf_len, NULL, NULL); //UTF16 to UTF8
程序从我以前的例子中节选,不一定可以调试,^_^。但是方法大致就是这样子的。
另外还有文件格式中,dos格式和Unix格式也不相同,大致的驱别在于dos的换行为/n,Unix的为/r/n,很多国际标准的协议文本中都会要求是后者。
提醒文件写成Unicode,记得加上文件标示头“FF FE”















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









