







首先,由于自然语言处理(NLP)模型无法直接处理原始文本,计算机只能处理数值数据,而文本是由字符和单词组成的。因此,需要将文本转换为数值表示;而又因为模型的词汇表是有限的,无法包含所有可能的单词。故需要将语言的输入经过分词器进行分割
拿"I love natural language processing."来举例
分割流程:
①分词器将句子分割为子词或单词,["I", "love", "natural", "language", "processing", "."]
②每个子词或单词被映射到词汇表中的唯一 ID:[101, 1045, 2066, 3012, 7953, 1012, 102];
其中,101 和 102 可能是特殊标记 [CLS] 和 [SEP] 的 ID。
③如果序列长度不足,则进行填充;如果过长,则进行截断,以确保输入长度符合模型要求。
④创建一个二进制掩码,指示哪些标记是有效的(1 表示有效,0 表示填充)。
分割效果如下图所示

注:[CLS] 标记通常位于输入序列的开头。在 BERT 的预训练任务(如句子对分类)中,[CLS] 的隐藏状态(即模型最后一层的输出)被用作整个序列或句子对的表示。
[SEP] 标记用于分隔句子,特别是在处理句子对任务,帮助模型区分不同的句子,避免信息混淆。(在句子对任务中,输入可能是 [CLS] 句子1 [SEP] 句子2 [SEP]。)
我这次的任务是根据酒店评价的文字来进行分类,训练集如下所示,每行开头的数字代表好评还是差评,1为好评,0为好评

这次项目采取分模块编写的思想,data,model,train分别写在不同的文件之中,然后通过main来调用
1.data:负责产生训练集和验证集数据加载器
导入相关的包
import torch
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split # 给出X,Y,分割比例,得到一个分割出来的训练集和验证集的X,Y读取文件的函数
def read_file(path):
with open(path, "r", encoding="utf-8") as f:
data = []
label = []
for i, line in enumerate(f):
if i == 0: # 不读入第一行,第一行是无用的数据
continue
# 数据太多,故采用这种方式读取少量数据,完整训练时可去掉
if i > 200 and i < 7500:
continue
line = line.strip("/n") # 去掉句子后面的/n
line = line.split(",", 1) # 把这句话按照“,”分割,1表示分割次数
# 读入数据和标签
data.append(line[1])
label.append(line[0])
print("读入了%d的数据"%len(data))
return data, label
处理数据和标签,得到数据集
class jdDataset(Dataset):
def __init__(self, data, label):
self.X = data
self.Y = torch.LongTensor([int(i) for i in label]) # 要把标签由字符型转换为整型
def __getitem__(self, item):
return self.X[item], self.Y[item]
def __len__(self):
return len(self.Y)对数据集进行读取,分割,得到数据加载器
def get_data_loader(path, batchsize, val_size=0.2):
# 读入数据
data, label = read_file(path)
# 分割数据集
# 输入参数
# 数据,标签,指定验证集所占的比例
# test_size,指定验证集所占的比例
# shuffle,是否在划分数据前对数据进行洗牌
# stratify=label,表示在划分数据集时,会保持训练集和验证集中各个类别的比例与原始数据集中相同
train_x, val_x, train_y, val_y = train_test_split(data, label, test_size=0.1, shuffle=True, stratify=label)
# 创建数据集
train_set = jdDataset(train_x, train_y)
val_set = jdDataset(val_x, val_y)
# 创建数据加载器
train_loader = DataLoader(train_set, batchsize, shuffle=True)
val_loader = DataLoader(val_set, batchsize, shuffle=True)
return train_loader, val_loader
2.model:
导入相关的包
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer, BertConfigbert模型
class myBertModel(nn.Module):
def __init__(self, bert_path, num_class, device):
super(myBertModel, self).__init__()
self.device = device
# 既加载设置,又加载参数
self.bert = BertModel.from_pretrained(bert_path)
# # 先加载设置,根据这个设置自己构建一个模型,自己训练参数
# config = BertConfig.from_pretrained(bert_path)
# self.bert = BertModel(config)
# 定义分类头,将bert输出
self.cls_head = nn.Linear(768, num_class)
# 加载与Bert模型相对应的分词器
self.tokenizer = BertTokenizer.from_pretrained(bert_path)
def forward(self, text):
# 使用分词器对输入文本进行编码,返回张量格式,并进行截断和填充
# BertTokenizer 是 transformers 库中提供的分词器,专门用于处理 BERT 模型的输入。
# text:输入文本
# return_tensors="pt":表示返回 PyTorch 张量(torch.Tensor)
# truncation=True:如果输入文本的长度超过了指定的最大长度(max_length),则会被截断到最大长度。
# padding="max_length":指定是对输入文本进行填充到相同的长度max_length
# 返回的input 是一个字典,包含了编码后的输入 ID、token 类型 ID 和注意力掩码
input = self.tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
# 将编码后的输入 ID 转移到指定设备
input_ids = input["input_ids"].to(self.device)
# 将 token 类型 ID 转移到指定设备(用于区分句子对)
token_type_ids = input["token_type_ids"].to(self.device)
# 将注意力掩码转移到指定设备(用于指示哪些 token 是有效的)
attention_mask = input["attention_mask"].to(self.device)
# 将编码后的输入传递给 BERT 模型,并获取模型的输出。
# return_dict=False 时,模型返回一个元组 (sequence_output, pooled_output)。
# eturn_dict=True 时,模型返回一个字典,包含 last_hidden_state 和 pooler_output 等键。
sequence_out, pooler_out = self.bert(input_ids=input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_mask,
return_dict=False)
# 使用分类头对池化后的输出进行分类
pred = self.cls_head(pooler_out)
return pred
3.train:
导入相关的包
import torch
import time
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
训练函数
这个训练函数与前几个项目不同的是,加了scheduler.step()函数,用于调整学习率,因为在训练过程中,固定的学习率可能不是最优的。学习率调度器可以根据训练进度动态地减小或增大学习率。
还加了torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0),用于梯度裁剪的一个函数。它的主要作用是防止在训练深度神经网络时,梯度爆炸导致的问题。他设置梯度的最大范数为 1.0,如果梯度的范数超过这个值,梯度将被缩放,使其范数等于 max_norm。
def train_val(para):
########################################################
model = para['model']
train_loader =para['train_loader']
val_loader = para['val_loader']
scheduler = para['scheduler']
optimizer = para['optimizer']
loss = para['loss']
epoch = para['epoch']
device = para['device']
save_path = para['save_path']
max_acc = para['max_acc']
val_epoch = para['val_epoch']
#################################################
plt_train_loss = []
plt_train_acc = []
plt_val_loss = []
plt_val_acc = []
val_rel = []
for i in range(epoch):
start_time = time.time()
model.train()
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
for batch in tqdm(train_loader):
model.zero_grad()
text, labels = batch[0], batch[1].to(device)
pred = model(text)
bat_loss = loss(pred, labels)
bat_loss.backward()
optimizer.step()
scheduler.step() # scheduler 调整学习率
optimizer.zero_grad()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁切
train_loss += bat_loss.item() # .detach 表示去掉梯度
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1)== labels.cpu().numpy())
plt_train_loss . append(train_loss/train_loader.dataset.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__())
if i % val_epoch == 0:
model.eval()
with torch.no_grad():
for batch in tqdm(val_loader):
val_text, val_labels = batch[0], batch[1].to(device)
val_pred = model(val_text)
val_bat_loss = loss(val_pred, val_labels)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == val_labels.cpu().numpy())
val_rel.append(val_pred)
if val_acc > max_acc:
torch.save(model, save_path+str(epoch)+"ckpt")
max_acc = val_acc
plt_val_loss.append(val_loss/val_loader.dataset.__len__())
plt_val_acc.append(val_acc/val_loader.dataset.__len__())
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f | valAcc: %3.6f valLoss: %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1])
)
if i % 50 == 0:
torch.save(model, save_path+'-epoch:'+str(i)+ '-%.2f'%plt_val_acc[-1])
else:
plt_val_loss.append(plt_val_loss[-1])
plt_val_acc.append(plt_val_acc[-1])
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1])
)
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()
4.main:
导入相关的包,设计随机种子,引入三个以上文件中的函数,并设置超参数
开始训练
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, eta_min=1e-9) 是学习率调度器,
import random
import torch
import torch.nn as nn
import numpy as np
import os
from model_utils.mydata import get_data_loader
from model_utils.mymodel import myBertModel
from model_utils.mytrain import train_val
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
# 超参数
lr = 0.0001
batchsize = 16
loss = nn.CrossEntropyLoss()
bert_path = "bert-base-chinese"
num_class = 2
data_path = "jiudian.txt"
max_acc = 0.6
device = "cuda" if torch.cuda.is_available() else "cpu"
model = myBertModel(bert_path, num_class, device).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=0.00001)
train_loader, val_loader = get_data_loader(data_path, batchsize)
epochs = 5 #
save_path = "model_save/best_model.pth"
# 学习率调取器,在每个周期结束时,使用余弦函数来调整学习率
# optimizer:要调整学习率的优化器实例,
# T_0:第一个周期的长度(以 epoch 为单位),
# eta_min:学习率的最小值。在每个周期的末尾,学习率会退火到这个最小值。
# 注意事项:T_0 的选择会影响训练过程。较小的 T_0 可能导致学习率变化过快,而较大的 T_0 可能使训练过程过于缓慢。
# eta_min 应该足够小,以确保在周期结束时模型仍然能够进行精细的参数调整。
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, eta_min=1e-9) # 改变学习率
val_epoch = 1
para = {
"model": model,
"train_loader": train_loader,
"val_loader": val_loader,
"scheduler" :scheduler,
"optimizer": optimizer,
"loss": loss,
"epoch": epochs,
"device": device,
"save_path": save_path,
"max_acc": max_acc,
"val_epoch": val_epoch # 训练多少论验证一次
}
train_val(para)
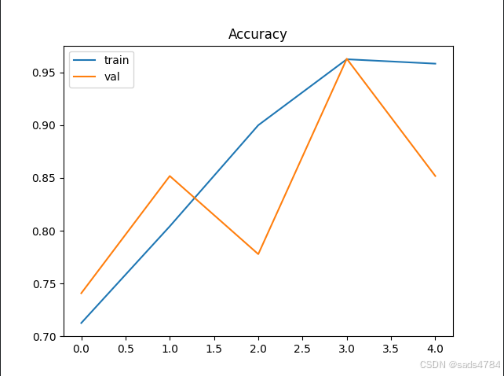
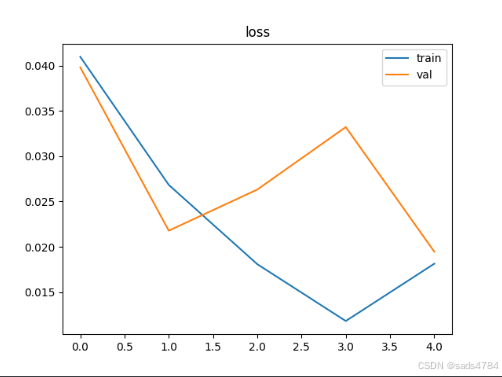
5.训练结果
样本过大,考虑到时间问,仅训练少部分数据作为演示,
①只使用Bert模型不使用训练好的参数
即在模型的初始化中调用这两句
# 先加载设置,根据这个设置自己构建一个模型,自己训练参数
config = BertConfig.from_pretrained(bert_path)
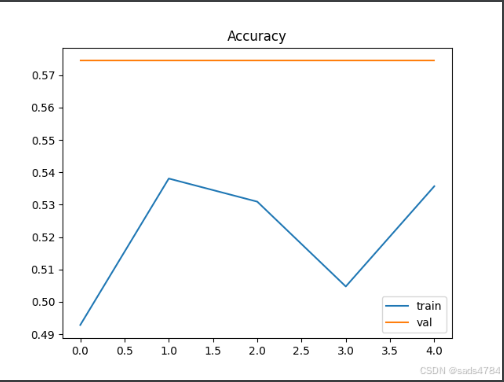
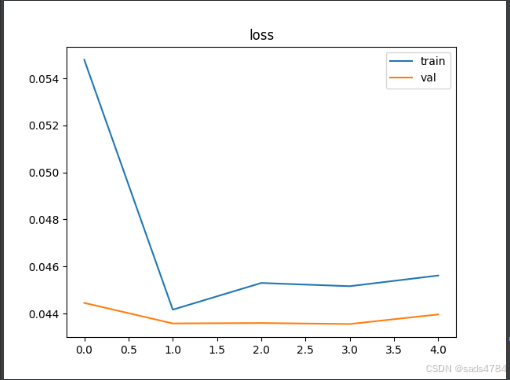
self.bert = BertModel(config)训练结果如图所示: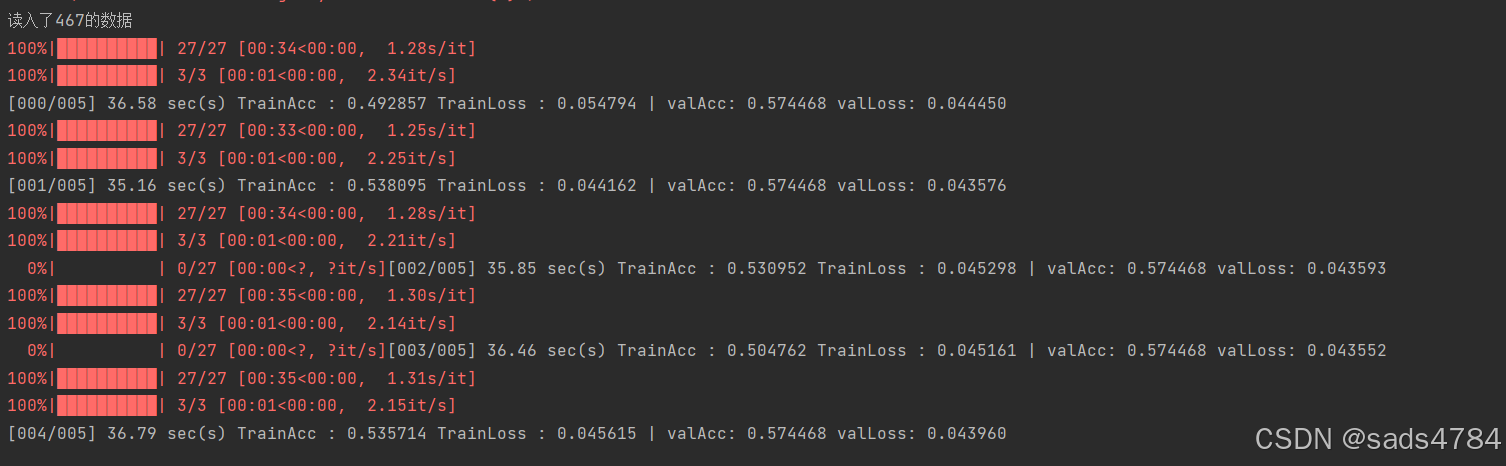
注意:我这里训练的样本中标签为1的恰好占比57%,所一在全猜1的情况下,准确率是57%,实际上我的参数训练的模型很差
②既使用Bert模型也使用训练好的参数
在模型的初始化中调改为调用这行代码
# 既加载设置,又加载参数
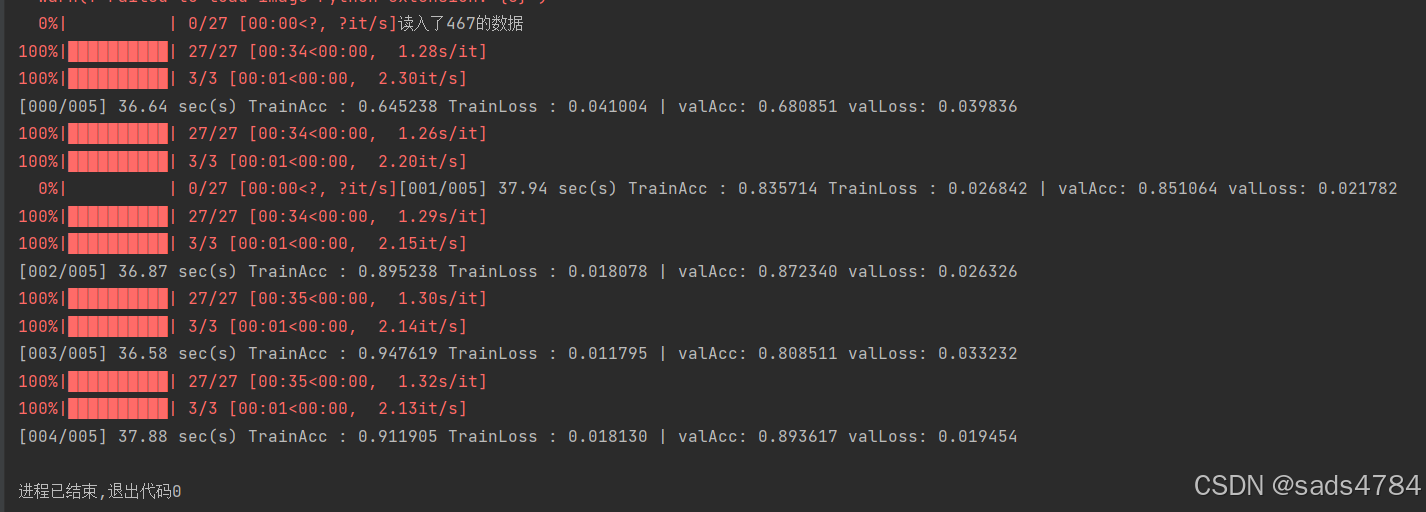
self.bert = BertModel.from_pretrained(bert_path)训练结果如图所示:明显要好于上面那种情况
Bert中的维度变化过程
输入句子有:我爱自然语言处理",“你喜欢机器学习吗”
1.使用BERT的分词器对句子进行分词。
结果:"我爱自然语言处理" → ["[CLS]", "我", "爱", "自然", "语言", "处理", "[SEP]"]
"你喜欢机器学习吗" → ["[CLS]", "你", "喜欢", "机器", "学习", "吗", "[SEP]"]
维度:字符串变为Token序列列表。
2.Token到ID的映射
每个Token被映射到BERT词汇表中的一个唯一ID。
["[CLS]", "我", "爱", "自然", "语言", "处理", "[SEP]"] → [101, 2769, 2658, 7596, 6963, 3221, 102]
["[CLS]", "你", "喜欢", "机器", "学习", "吗", "[SEP]"] → [101, 872, 2400, 4638, 3300, 5029, 102]
维度:Token序列变为ID序列。
3.Padding(填充)与Batch处理
假设最长句子长度为7(包括[CLS]和[SEP]),则不需要额外填充(在这个例子中)。
Batch表示:
句子1:[101, 2769, 2658, 7596, 6963, 3221, 102]
句子2:[101, 872, 2400, 4638, 3300, 5029, 102]
维度:变为二维张量,形状为(2, 7),其中2是batch size,7是序列长度。
4.Embedding Layer(嵌入层)
将每个ID转换为固定长度的向量(假设隐藏层维度为768)。结果:每个ID被转换为一个768维的向量。
维度:二维张量变为三维张量,形状为(2, 7, 768),其中2是batch size,7是序列长度,768是隐藏层维度。
5.通过Transformer层
Transformer层:BERT由多个Transformer层堆叠而成,每个层都会处理输入张量。
维度:经过Transformer层后,张量的维度保持不变,仍为(2, 7, 768)。
6.通过Dense层(全连接层)
用于将Transformer层输出的高维特征(如[CLS] Token的隐藏状态)转换为任务所需的输出格式(如类别概率)。
输入:[CLS],(2,768)
输出:假设类别数为768,则Dense层输出形状为(2, 768)。再经过Softmax激活函数将Dense层的输出(logits)转换为概率分布,形状仍为(2, 768)。
7.输出处理
①若不是句子分类处理(如序列标注、问答系统等):
采取Pooling(池化)
取[CLS] Token的Embedding:形状变为(2, 768);或对所有Token的Embedding进行平均:形状也变为(2, 768)。
②若是句子分类处理:而是直接使用[CLS] 即Token的隐藏状态进行输出(或经过Dense层后的输出)。
维度:根据池化操作,张量的维度从三维降低为二维。
8.总结
原始字符串 → Token序列(分词)
Token序列 → ID序列(词汇表映射)
ID序列(Batch处理与Padding) → 二维张量(形状为(batch_size, sequence_length))
二维张量 → 三维张量(嵌入层,形状为(batch_size, sequence_length, hidden_size))
三维张量(Transformer层) → 三维张量(形状保持不变)
(可选)三维张量 → 二维张量(池化或者danse层,形状为(batch_size, hidden_size))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









