







阅读本文需要的背景知识点:拉格朗日乘子法、KKT条件、一丢丢编程知识
一、引言
前面一节我们介绍了一种分类算法——朴素贝叶斯分类器算法,从概率分布的角度进行分类。下面我们会花几节来介绍另一种在分类问题中有着重要地位的算法——支持向量机1 (Support Vector Machine/SVM)。
SVM从基础到复杂可以分成三种分别为线性可分支持向量机(也就是硬间隔支持向量机)、线性支持向量机(软间隔支持向量机)、非线性支持向量机(核函数支持向量机),这一节先来介绍第一种最基础的算法——硬间隔支持向量机算法(Hard-margin Support Vector Machine)。
二、模型介绍
原始模型
先来看下图,展示了一组线性可分的数据集,其中红点表示 -1、蓝叉表示 1 ,可以看到将该数据集分开的直线有无限多条,那么如何选择一条相对合适的直线呢?如下图中的两条直线 A、B,直观上似乎直线 A 比直线 B 更适合作为决策边界,因为对于直线 B,离某些样本点过于近,虽然依然能正确分类样本点,但当在该样本点附近预测时,会得到完全不同的结果,似乎不符合直觉,其泛化能力更差一些,而反观直线 A,其更具有鲁棒性。
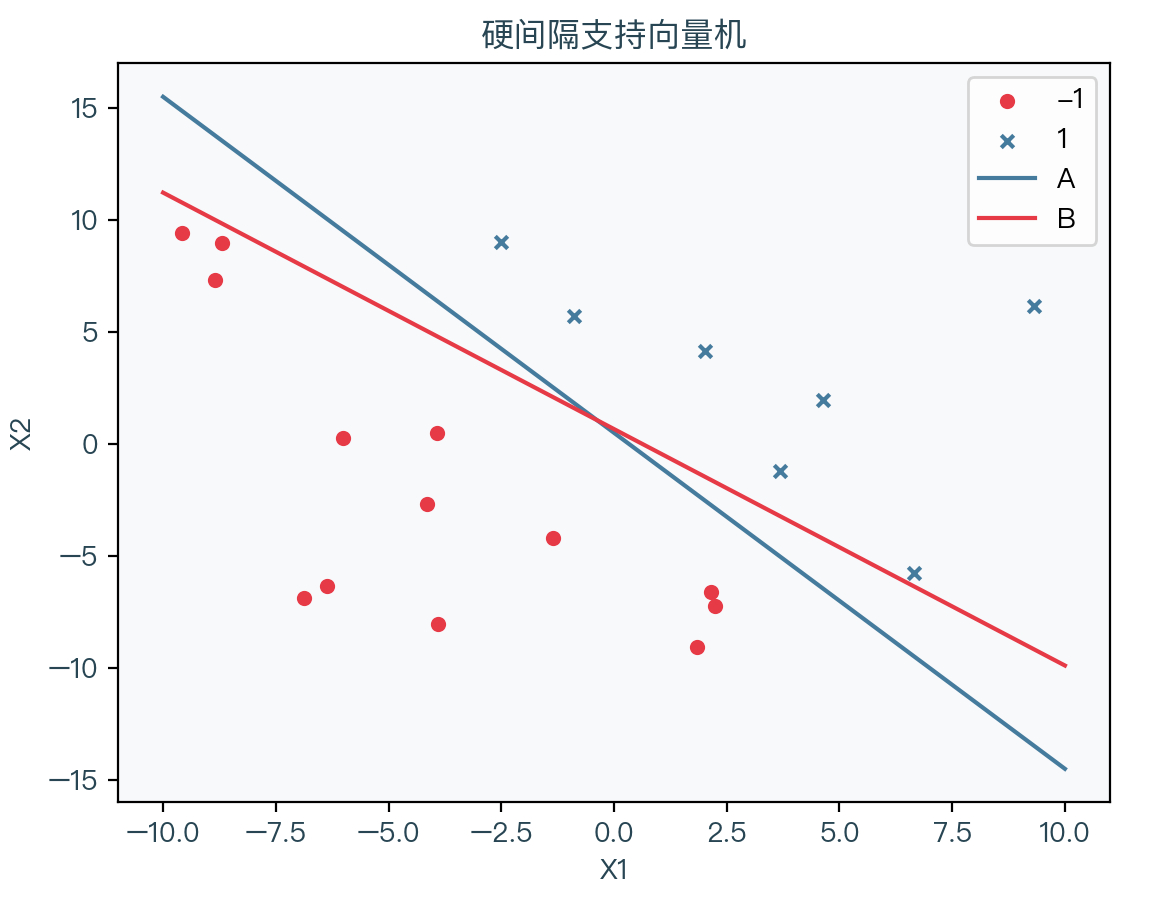
根据上面的推断,我们的目标为找到一条直线(多维时为超平面),使得任意样本点到该超平面的距离的最小值最大。超平面表达式如下:
w
T
x
+
b
=
0
w^Tx + b = 0
wTx+b=0
同时使得每个样本点都在正确的分类下面,即满足下式:
{
w
T
x
i
+
b
>
0
y
i
=
+
1
w
T
x
i
+
b
<
0
y
i
=
−
1
⇒
y
i
(
w
T
x
i
+
b
)
>
0
\left\{\begin{array}{c} w^{T} x_{i}+b>0 & y_{i}=+1 \\ w^{T} x_{i}+b<0 & y_{i}=-1 \end{array} \quad \Rightarrow \quad y_{i}\left(w^{T} x_{i}+b\right)>0\right.
{wTxi+b>0wTxi+b<0yi=+1yi=−1⇒yi(wTxi+b)>0
观察下图,可以将问题转化为找到两个超平面 A、C,使得两个超平面之间的距离最大,同时每个样本点分类正确。
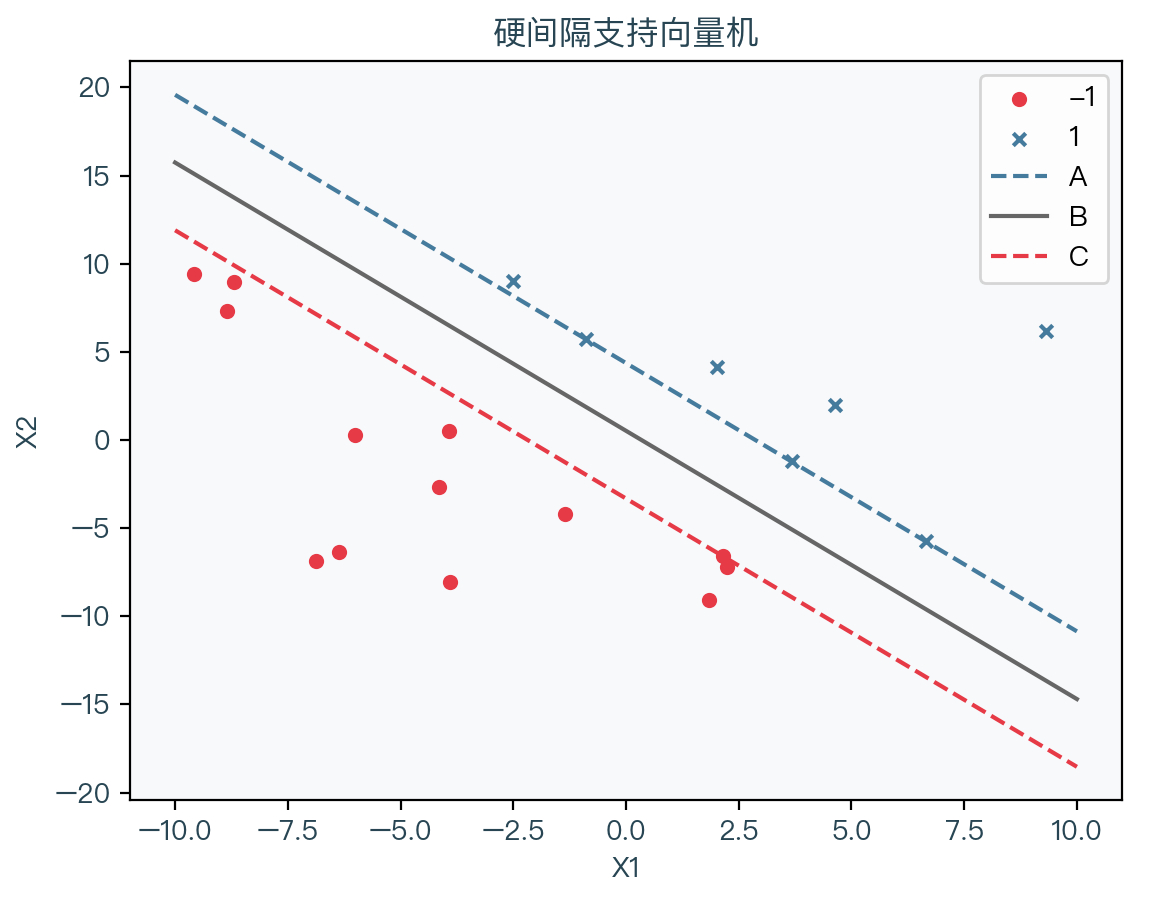
不妨假设超平面 A 为
w
x
+
b
=
1
wx + b = 1
wx+b=1,超平面 B 为
w
x
+
b
=
−
1
wx + b = -1
wx+b=−1(由于
w
、
b
w、b
w、b 都可以成比例缩放,所以必然可以找到对应的值使得上式成立),同时分类正确的条件如下:
{
w
T
x
i
+
b
≥
1
y
i
=
+
1
w
T
x
i
+
b
≤
−
1
y
i
=
−
1
⇒
y
i
(
w
T
x
i
+
b
)
≥
1
\left\{\begin{array}{c} w^{T} x_{i}+b \ge 1 & y_{i}=+1 \\ w^{T} x_{i}+b \le -1 & y_{i}=-1 \end{array} \quad \Rightarrow \quad y_{i}\left(w^{T} x_{i}+b\right) \ge 1\right.
{wTxi+b≥1wTxi+b≤−1yi=+1yi=−1⇒yi(wTxi+b)≥1
任意一点到超平面
w
x
+
b
=
0
wx + b = 0
wx+b=0 的距离为(推导见四):
d
=
∣
w
T
x
+
b
∣
∣
w
∣
d = \frac{\mid w^Tx + b \mid}{\mid w \mid}
d=∣w∣∣wTx+b∣
由上式可知超平面 A:
w
x
+
b
=
1
wx + b = 1
wx+b=1,超平面 B:
w
x
+
b
=
−
1
wx + b = -1
wx+b=−1 之间的间距为(推导见四):
margin
=
2
∣
w
∣
\text{margin} = \frac{2}{\mid w \mid}
margin=∣w∣2
那么问题转化为了如下形式:
max
w
,
b
2
∣
w
∣
s.t.
y
i
(
w
T
x
i
+
b
)
≥
1
i
=
1
,
2
,
⋯
,
N
\begin{aligned} \underset{w, b}{\max} \frac{2}{\mid w \mid} \\ \text { s.t. } \quad y_{i}\left(w^{T} x_{i}+b\right) \geq 1 & \quad i=1,2, \cdots, N \end{aligned}
w,bmax∣w∣2 s.t. yi(wTxi+b)≥1i=1,2,⋯,N
对向量的取模操作可以转化为向量内积的形式,同时取倒数,将最大值问题变成求最小值的问题,得到最后的模型如下:
min
w
,
b
1
2
w
T
w
s.t.
y
i
(
w
T
x
i
+
b
)
≥
1
i
=
1
,
2
,
⋯
,
N
\begin{aligned} \underset{w, b}{\min} \frac{1}{2} w^Tw \\ \text { s.t. } \quad y_{i}\left(w^{T} x_{i}+b\right) \geq 1 & \quad i=1,2, \cdots, N \end{aligned}
w,bmin21wTw s.t. yi(wTxi+b)≥1i=1,2,⋯,N
对偶模型
对原模型用拉格朗日乘子法转换一下:
(1)使用拉格朗日乘子法,即在后面加上 N 个拉格朗日乘子的条件,得到对应的拉格朗日函数
(2)拉格朗日函数对
w
w
w 求偏导数并令其为零
(3)得到
w
w
w 的解析解
(4)拉格朗日函数对
b
b
b 求偏导数并令其为零
(5)得到新的条件
L
(
w
,
b
,
λ
)
=
1
2
w
T
w
+
∑
i
=
1
N
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
(
1
)
∂
L
∂
w
=
w
−
∑
i
=
1
N
λ
i
y
i
x
i
=
0
(
2
)
w
=
∑
i
=
1
N
λ
i
y
i
x
i
(
3
)
∂
L
∂
b
=
−
∑
i
=
1
N
λ
i
y
i
=
0
(
4
)
∑
i
=
1
N
λ
i
y
i
=
0
(
5
)
\begin{aligned} L(w, b, \lambda) &=\frac{1}{2} w^{T} w+\sum_{i=1}^{N} \lambda_{i}\left(1-y_{i}\left(w^{T} x_{i}+b\right)\right) & (1)\\ \frac{\partial L}{\partial w} &=w-\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i}=0 & (2)\\ w &=\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i} & (3)\\ \frac{\partial L}{\partial b} &=-\sum_{i=1}^{N} \lambda_{i} y_{i}=0& (4) \\ \sum_{i=1}^{N} \lambda_{i} y_{i} &=0 & (5) \end{aligned}
L(w,b,λ)∂w∂Lw∂b∂Li=1∑Nλiyi=21wTw+i=1∑Nλi(1−yi(wTxi+b))=w−i=1∑Nλiyixi=0=i=1∑Nλiyixi=−i=1∑Nλiyi=0=0(1)(2)(3)(4)(5)
将上面
w
、
b
w、b
w、b 的解析解带回到拉格朗日函数:
(1)拉格朗日函数
(2)展开括号
(3)观察(2)式最后一项,必定为零,再带入
w
w
w 的解析解
(4)化简整理得到
L
(
w
,
b
,
λ
)
=
1
2
w
T
w
+
∑
i
=
1
N
λ
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
(
1
)
L
(
λ
)
=
1
2
w
T
w
+
∑
i
=
1
N
λ
i
−
∑
i
=
1
N
λ
i
y
i
w
T
x
i
−
∑
i
=
1
N
λ
i
y
i
b
(
2
)
=
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
+
∑
i
=
1
N
λ
i
−
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
(
3
)
=
∑
i
=
1
N
−
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
(
4
)
\begin{aligned} L(w, b, \lambda) &=\frac{1}{2} w^{T} w+\sum_{i=1}^{N} \lambda_{i}\left(1-y_{i}\left(w^{T} x_{i}+b\right)\right) & (1)\\ L(\lambda) &=\frac{1}{2} w^{T} w+\sum_{i=1}^{N} \lambda_{i}-\sum_{i=1}^{N} \lambda_{i} y_{i} w^{T} x_{i}-\sum_{i=1}^{N} \lambda_{i} y_{i} b & (2)\\ &=\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j}+\sum_{i=1}^{N} \lambda_{i}-\sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j} & (3)\\ &=\sum_{i=1}^{N}-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j} & (4) \end{aligned}
L(w,b,λ)L(λ)=21wTw+i=1∑Nλi(1−yi(wTxi+b))=21wTw+i=1∑Nλi−i=1∑NλiyiwTxi−i=1∑Nλiyib=21i=1∑Nj=1∑NλiλjyiyjxiTxj+i=1∑Nλi−i=1∑Nj=1∑NλiλjyiyjxiTxj=i=1∑N−21i=1∑Nj=1∑NλiλjyiyjxiTxj(1)(2)(3)(4)
(1)原始问题
(2)使用拉格朗日乘子法转换
(3)转换为对偶问题,要想使得原始问题与对偶问题等价,需要引入 KKT 条件
(4)带入拉格朗日函数
min
w
,
b
1
2
w
T
w
s.t.
y
(
w
T
x
+
b
)
≥
1
(
1
)
⇒
min
w
,
b
max
λ
L
(
w
,
b
,
λ
)
s.t.
λ
≥
0
(
2
)
⇒
max
λ
min
w
,
b
L
(
w
,
b
,
λ
)
s.t.
λ
≥
0
(
3
)
⇒
max
λ
L
(
λ
)
s.t.
λ
≥
0
(
4
)
\begin{aligned} & \min _{w, b} \frac{1}{2} w^{T} w \quad \text { s.t. } y\left(w^{T} x+b\right) \geq 1 & (1)\\ \Rightarrow & \min _{w, b} \max _{\lambda} L(w, b, \lambda) \quad \text { s.t. } \lambda \geq 0 & (2)\\ \Rightarrow & \max _{\lambda} \min _{w, b} L(w, b, \lambda) \quad \text { s.t. } \lambda \geq 0 & (3)\\ \Rightarrow & \max _{\lambda} L(\lambda) \quad \text { s.t. } \lambda \geq 0 & (4) \end{aligned}
⇒⇒⇒w,bmin21wTw s.t. y(wTx+b)≥1w,bminλmaxL(w,b,λ) s.t. λ≥0λmaxw,bminL(w,b,λ) s.t. λ≥0λmaxL(λ) s.t. λ≥0(1)(2)(3)(4)
KKT(Karush-Kuhn-Tucker)条件2
前面在推导原始问题的对偶问题中,使得两个问题等价的条件被称为 KKT 条件(Karush–Kuhn–Tucker conditions)。
对偶问题需满足的 KKT 条件如下:
{
∇
w
,
b
L
(
w
,
b
,
λ
)
=
0
λ
i
≥
0
y
i
(
w
T
x
i
+
b
)
−
1
≥
0
λ
i
(
y
i
(
w
T
x
i
+
b
)
−
1
)
=
0
\left\{\begin{aligned} \nabla_{w, b} L(w, b, \lambda) &=0 \\ \lambda_{i} & \geq 0 \\ y_{i}\left(w^{T} x_{i}+b\right)-1 & \geq 0 \\ \lambda_{i}\left(y_{i}\left(w^{T} x_{i}+b\right)-1\right) &=0 \end{aligned}\right.
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧∇w,bL(w,b,λ)λiyi(wTxi+b)−1λi(yi(wTxi+b)−1)=0≥0≥0=0
由上面 KKT 条件可以看出,对于任意一个样本点,其
λ
=
0
λ = 0
λ=0 或者
y
(
w
x
+
b
)
=
1
y(wx + b) = 1
y(wx+b)=1,为前者时,其对最后的函数结果没有影响,即我们可以忽略这些样本点。当为后者时,该样本点在两个最大间隔超平面内(图2-2中的虚线),被称为支持向量,这也是支持向量机名字的由来,最后的模型只与这些支持向量有关。
经过运用拉格朗日乘子法后,得到了原模型的拉格朗日对偶模型并且需要满足如上所示的 KKT 条件:
max
λ
∑
i
=
1
N
λ
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
s.t.
∑
i
=
1
N
λ
i
y
i
=
0
λ
i
≥
0
i
=
1
,
2
,
⋯
,
N
\begin{aligned} & \underset{\lambda}{\max} \sum_{i=1}^{N} \lambda_{i}-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j} \\ \text { s.t. } & \sum_{i=1}^{N} \lambda_{i} y_{i}=0 \quad \lambda_{i} \geq 0 \quad i=1,2, \cdots, N \end{aligned}
s.t. λmaxi=1∑Nλi−21i=1∑Nj=1∑NλiλjyiyjxiTxji=1∑Nλiyi=0λi≥0i=1,2,⋯,N
三、算法步骤
由上面的模型可以看出这是一个二次规划问题3(Quadratic programming),能够通过一些特殊的方法来求解,例如内点法(Interior Point)等等,后面有机会再来介绍求解方法。下面介绍一种专门用于支持向量机优化问题的算法——序列最小优化算法4(Sequential minimal optimization/SMO)。
SMO 算法的思路在笔者看来有点类似前面讲到的坐标下降算法,既然需要优化的参数过多,那就一次优化一个。在 SMO 中则是一次选择两个待优化变量,其余的当作常量,求解上面的对偶问题的极值,更新变量直至收敛。
算法推导
注意这里的下标
a
、
b
a、b
a、b 即为上面描述的两个待优化变量的下标值,其中下标
b
b
b 与偏移量
b
b
b 不是同一个值,这里没有合适的字母表示了,所以用了
a
、
b
a、b
a、b,切勿与偏移量
b
b
b 混淆
定义一些符号来方便表述,为后面推导做准备:
(1)两个样本点的点积用
K
a
b
K_{ab}
Kab 来表示,后面一节会介绍 SVM 中的一个很重要的特征——核函数,这里的 K 即代表的 Kernal
(2)用核函数来表示决策边界
(3)、(4)用
v
a
v_a
va 来表示去除了下标为
a
、
b
a、b
a、b 的样本点和偏移量
K
a
b
=
x
a
T
x
b
(
1
)
f
(
x
a
)
=
w
T
x
a
+
b
=
∑
i
=
0
N
λ
i
y
i
x
i
T
x
a
+
b
=
∑
i
=
0
N
λ
i
y
i
K
i
a
+
b
(
2
)
v
a
=
f
(
x
a
)
−
λ
a
y
a
K
a
a
−
λ
b
y
b
K
a
b
−
b
(
3
)
v
b
=
f
(
x
b
)
−
λ
a
y
a
K
a
b
−
λ
b
y
b
K
b
b
−
b
(
4
)
\begin{aligned} K_{a b} &=x_{a}^{T} x_{b} & (1)\\ f\left(x_{a}\right) &=w^{T} x_{a}+b \\ &=\sum_{i=0}^{N} \lambda_{i} y_{i} x_{i}^{T} x_{a}+b \\ &=\sum_{i=0}^{N} \lambda_{i} y_{i} K_{i a}+b & (2)\\ v_{a} &=f\left(x_{a}\right)-\lambda_{a} y_{a} K_{a a}-\lambda_{b} y_{b} K_{a b}-b & (3)\\ v_{b} &=f\left(x_{b}\right)-\lambda_{a} y_{a} K_{a b}-\lambda_{b} y_{b} K_{b b}-b & (4) \end{aligned}
Kabf(xa)vavb=xaTxb=wTxa+b=i=0∑NλiyixiTxa+b=i=0∑NλiyiKia+b=f(xa)−λayaKaa−λbybKab−b=f(xb)−λayaKab−λbybKbb−b(1)(2)(3)(4)
计算表达式,为后面推导做准备:
(1)计算下面表达式
(2)带入
f
(
x
)
f(x)
f(x)
(3)化简消去偏移量
b
b
b
(4)将括号展开
(5)移项后得到只包含
λ
a
λ_a
λa 的结果
(6)同上得到只包含
λ
b
λ_b
λb 的结果
λ
a
y
a
v
a
=
λ
a
y
a
(
f
(
x
a
)
−
λ
a
y
a
K
a
a
−
λ
b
y
b
K
a
b
−
b
)
(
1
)
=
λ
a
y
a
(
∑
i
=
0
N
λ
i
y
i
K
i
a
+
b
−
λ
a
y
a
K
a
a
−
λ
b
y
b
K
a
b
−
b
)
(
2
)
=
λ
a
y
a
(
∑
i
=
0
N
λ
i
y
i
K
i
a
−
λ
a
y
a
K
a
a
−
λ
b
y
b
K
a
b
)
(
3
)
=
∑
i
=
0
N
λ
i
λ
a
y
i
y
a
K
i
a
−
λ
a
λ
a
y
a
y
a
K
a
a
−
λ
a
λ
b
y
a
y
b
K
a
b
(
4
)
∑
i
=
0
N
λ
i
λ
a
y
i
y
a
K
i
a
=
λ
a
y
a
v
a
+
λ
a
λ
a
y
a
y
a
K
a
a
+
λ
a
λ
b
y
a
y
b
K
a
b
(
5
)
∑
i
=
0
N
λ
i
λ
b
y
i
y
b
K
i
b
=
λ
b
y
b
v
b
+
λ
a
λ
b
y
a
y
b
K
a
b
+
λ
b
λ
b
y
b
y
b
K
b
b
(
6
)
\begin{aligned} \lambda_{a} y_{a} v_{a} &=\lambda_{a} y_{a}\left(f\left(x_{a}\right)-\lambda_{a} y_{a} K_{a a}-\lambda_{b} y_{b} K_{a b}-b\right) & (1)\\ &=\lambda_{a} y_{a}\left(\sum_{i=0}^{N} \lambda_{i} y_{i} K_{i a}+b-\lambda_{a} y_{a} K_{a a}-\lambda_{b} y_{b} K_{a b}-b\right) & (2)\\ &=\lambda_{a} y_{a}\left(\sum_{i=0}^{N} \lambda_{i} y_{i} K_{i a}-\lambda_{a} y_{a} K_{a a}-\lambda_{b} y_{b} K_{a b}\right) & (3)\\ &=\sum_{i=0}^{N} \lambda_{i} \lambda_{a} y_{i} y_{a} K_{i a}-\lambda_{a} \lambda_{a} y_{a} y_{a} K_{a a}-\lambda_{a} \lambda_{b} y_{a} y_{b} K_{a b} & (4)\\ \sum_{i=0}^{N} \lambda_{i} \lambda_{a} y_{i} y_{a} K_{i a} &=\lambda_{a} y_{a} v_{a}+\lambda_{a} \lambda_{a} y_{a} y_{a} K_{a a}+\lambda_{a} \lambda_{b} y_{a} y_{b} K_{a b} & (5)\\ \sum_{i=0}^{N} \lambda_{i} \lambda_{b} y_{i} y_{b} K_{i b} &=\lambda_{b} y_{b} v_{b}+\lambda_{a} \lambda_{b} y_{a} y_{b} K_{a b}+\lambda_{b} \lambda_{b} y_{b} y_{b} K_{b b} & (6) \end{aligned}
λayavai=0∑NλiλayiyaKiai=0∑NλiλbyiybKib=λaya(f(xa)−λayaKaa−λbybKab−b)=λaya(i=0∑NλiyiKia+b−λayaKaa−λbybKab−b)=λaya(i=0∑NλiyiKia−λayaKaa−λbybKab)=i=0∑NλiλayiyaKia−λaλayayaKaa−λaλbyaybKab=λayava+λaλayayaKaa+λaλbyaybKab=λbybvb+λaλbyaybKab+λbλbybybKbb(1)(2)(3)(4)(5)(6)
将多个变量的问题转换为两个变量的问题:
(1)原拉格朗日函数
(2)将上面的结果带入函数中,由于只有下标为
a
、
b
a、b
a、b 的两个变量,只需要处理包含这两个变量的项、其他的项统一用常数 C 来表示
L
(
λ
)
=
∑
i
=
0
N
λ
i
−
1
2
∑
i
=
0
N
∑
j
=
0
N
λ
i
λ
j
y
i
y
j
x
i
T
x
j
(
1
)
L
(
λ
a
,
λ
b
)
=
λ
a
+
λ
b
−
1
2
λ
a
2
K
a
a
−
1
2
λ
b
2
K
b
b
−
λ
a
λ
b
y
a
y
b
K
a
b
−
λ
a
y
a
v
a
−
λ
b
y
b
v
b
−
C
(
2
)
\begin{aligned} L(\lambda) &=\sum_{i=0}^{N} \lambda_{i}-\frac{1}{2} \sum_{i=0}^{N} \sum_{j=0}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j} & (1)\\ L\left(\lambda_{a}, \lambda_{b}\right) &=\lambda_{a}+\lambda_{b}-\frac{1}{2} \lambda_{a}^{2} K_{a a}-\frac{1}{2} \lambda_{b}^{2} K_{b b}-\lambda_{a} \lambda_{b} y_{a} y_{b} K_{a b}-\lambda_{a} y_{a} v_{a}-\lambda_{b} y_{b} v_{b}-C & (2) \end{aligned}
L(λ)L(λa,λb)=i=0∑Nλi−21i=0∑Nj=0∑NλiλjyiyjxiTxj=λa+λb−21λa2Kaa−21λb2Kbb−λaλbyaybKab−λayava−λbybvb−C(1)(2)
定义符号为后面的推导做准备:
(1)原问题的条件
(2)只处理下标为
a
、
b
a、b
a、b 的两个变量,其他用常量 c 表示(注意这里为 c,切勿与式 3-3 中的 C 混淆)
(3)移项后两边同时乘以
y
a
y_a
ya
(4)、(5)定义符号简化书写
(6)带入符号后
λ
a
λ_a
λa 的表达式
∑
i
=
0
N
λ
i
y
i
=
0
(
1
)
λ
a
y
a
+
λ
b
y
b
=
c
(
2
)
λ
a
=
c
y
a
−
λ
b
y
a
y
b
(
3
)
γ
=
c
y
a
(
4
)
s
=
y
a
y
b
(
5
)
λ
a
=
γ
−
λ
b
s
(
6
)
\begin{aligned} \sum_{i=0}^{N} \lambda_{i} y_{i} &=0 & (1)\\ \lambda_{a} y_{a}+\lambda_{b} y_{b} &=c & (2)\\ \lambda_{a} &=c y_{a}-\lambda_{b} y_{a} y_{b} & (3)\\ \gamma &=c y_{a} & (4)\\ s &=y_{a} y_{b} & (5)\\ \lambda_{a} &=\gamma-\lambda_{b} s & (6) \end{aligned}
i=0∑Nλiyiλaya+λbybλaγsλa=0=c=cya−λbyayb=cya=yayb=γ−λbs(1)(2)(3)(4)(5)(6)
将两个变量的问题转换为单变量的问题:
(1)将上面得到的
λ
a
λ_a
λa 的表达式带入拉格朗日函数,得到只有
λ
b
λ_b
λb 为变量的函数
(2)拉格朗日函数对
λ
b
λ_b
λb 求偏导数
(3)注意到 s 的平方必然为 1,化简后得到
(4)合并同类项,整理后得到
(5)另偏导数为零,求得
λ
b
λ_b
λb 的解
(6)合并同类项,整理后得到
L
(
λ
b
)
=
γ
−
λ
b
s
+
λ
b
−
1
2
(
γ
−
λ
b
s
)
2
K
a
a
−
1
2
λ
b
2
K
b
b
−
(
γ
−
λ
b
s
)
λ
b
s
K
a
b
−
(
γ
−
λ
b
s
)
y
a
v
a
−
λ
b
y
b
v
b
−
C
(
1
)
∂
L
∂
λ
b
=
−
s
+
1
+
s
γ
K
a
a
−
s
2
K
a
a
λ
b
−
K
b
b
λ
b
−
s
γ
K
a
b
+
2
s
2
K
a
b
λ
b
+
y
a
s
v
a
−
y
b
v
b
(
2
)
=
−
s
+
1
+
s
γ
K
a
a
−
K
a
a
λ
b
−
K
b
b
λ
b
−
s
γ
K
a
b
+
2
K
a
b
λ
b
+
y
b
v
a
−
y
b
v
b
(
3
)
=
(
2
K
a
b
−
K
a
a
−
K
b
b
)
λ
b
−
s
+
1
+
s
γ
K
a
a
−
s
γ
K
a
b
+
y
b
v
a
−
y
b
v
b
=
0
(
4
)
λ
b
=
1
−
s
+
s
γ
K
a
a
−
s
γ
K
a
b
+
y
b
v
a
−
y
b
v
b
K
a
a
+
K
b
b
−
2
K
a
b
(
5
)
=
y
b
(
y
b
−
y
a
+
y
a
γ
(
K
a
a
−
K
a
b
)
+
v
a
−
v
b
)
K
a
a
+
K
b
b
−
2
K
a
b
(
6
)
\begin{aligned} L\left(\lambda_{b}\right) &=\gamma-\lambda_{b} s+\lambda_{b}-\frac{1}{2}\left(\gamma-\lambda_{b} s\right)^{2} K_{a a}-\frac{1}{2} \lambda_{b}^{2} K_{b b}-\left(\gamma-\lambda_{b} s\right) \lambda_{b} s K_{a b}-\left(\gamma-\lambda_{b} s\right) y_{a} v_{a}-\lambda_{b} y_{b} v_{b}-C & (1)\\ \frac{\partial L}{\partial \lambda_{b}} &=-s+1+s \gamma K_{a a}-s^{2} K_{a a} \lambda_{b}-K_{b b} \lambda_{b}-s \gamma K_{a b}+2 s^{2} K_{a b} \lambda_{b}+y_{a} s v_{a}-y_{b} v_{b} & (2)\\ &=-s+1+s \gamma K_{a a}-K_{a a} \lambda_{b}-K_{b b} \lambda_{b}-s \gamma K_{a b}+2 K_{a b} \lambda_{b}+y_{b} v_{a}-y_{b} v_{b} & (3)\\ &=\left(2 K_{a b}-K_{a a}-K_{b b}\right) \lambda_{b}-s+1+s \gamma K_{a a}-s \gamma K_{a b}+y_{b} v_{a}-y_{b} v_{b}=0 & (4)\\ \lambda_{b} &=\frac{1-s+s \gamma K_{a a}-s \gamma K_{a b}+y_{b} v_{a}-y_{b} v_{b}}{K_{a a}+K_{b b}-2 K_{a b}} & (5)\\ &=\frac{y_{b}\left(y_{b}-y_{a}+y_{a} \gamma\left(K_{a a}-K_{a b}\right)+v_{a}-v_{b}\right)}{K_{a a}+K_{b b}-2 K_{a b}} & (6) \end{aligned}
L(λb)∂λb∂Lλb=γ−λbs+λb−21(γ−λbs)2Kaa−21λb2Kbb−(γ−λbs)λbsKab−(γ−λbs)yava−λbybvb−C=−s+1+sγKaa−s2Kaaλb−Kbbλb−sγKab+2s2Kabλb+yasva−ybvb=−s+1+sγKaa−Kaaλb−Kbbλb−sγKab+2Kabλb+ybva−ybvb=(2Kab−Kaa−Kbb)λb−s+1+sγKaa−sγKab+ybva−ybvb=0=Kaa+Kbb−2Kab1−s+sγKaa−sγKab+ybva−ybvb=Kaa+Kbb−2Kabyb(yb−ya+yaγ(Kaa−Kab)+va−vb)(1)(2)(3)(4)(5)(6)
推导变量
λ
b
λ_b
λb 的更新公式:
(1)
γ
γ
γ 的表达式
(2)带入
γ
γ
γ
(3)展开括号并带入
v
v
v
(4)合并同类项
(5)化简
(6)预测值与实际值之差记为 E
(7)分母表示为 K
(8)带入 E、K 后得到
λ
b
λ_b
λb 变量的更新公式
γ
=
λ
a
old
+
y
a
y
b
λ
b
old
(
1
)
λ
b
new
=
y
b
(
y
b
−
y
a
+
y
a
(
λ
a
old
+
y
a
y
b
λ
b
old
)
(
K
a
a
−
K
a
b
)
+
v
a
−
v
b
)
K
a
a
+
K
b
b
−
2
K
a
b
(
2
)
=
y
b
(
y
b
−
y
a
+
y
a
λ
a
old
K
a
a
+
y
b
λ
b
old
K
a
a
−
y
a
λ
a
old
K
a
b
−
y
b
λ
b
old
K
a
b
+
f
(
x
a
)
−
y
a
λ
a
K
a
a
−
y
b
λ
b
K
a
b
−
b
−
f
(
x
b
)
+
y
a
λ
a
K
a
b
+
y
b
λ
b
K
b
b
+
b
)
K
a
a
+
K
b
b
−
2
K
a
b
(
3
)
=
y
b
(
y
b
−
y
a
+
y
b
λ
b
old
(
K
a
a
+
K
b
b
−
2
K
a
b
)
+
f
(
x
a
)
−
f
(
x
b
)
)
K
a
a
+
K
b
b
−
2
K
a
b
(
4
)
=
λ
b
old
+
y
b
(
f
(
x
a
)
−
y
a
−
(
f
(
x
b
)
−
y
b
)
)
K
a
a
+
K
b
b
−
2
K
a
b
(
5
)
E
=
f
(
x
)
−
y
(
6
)
K
=
K
a
a
+
K
b
b
−
2
K
a
b
(
7
)
λ
b
new
=
λ
b
old
+
y
b
(
E
a
−
E
b
)
K
(
8
)
\begin{aligned} \gamma &=\lambda_{a}^{\text {old }}+y_{a} y_{b} \lambda_{b}^{\text {old }} & (1) \\ \lambda_{b}^{\text {new }} &=\frac{y_{b}\left(y_{b}-y_{a}+y_{a}\left(\lambda_{a}^{\text {old }}+y_{a} y_{b} \lambda_{b}^{\text {old }}\right)\left(K_{a a}-K_{a b}\right)+v_{a}-v_{b}\right)}{K_{a a}+K_{b b}-2 K_{a b}} & (2) \\ &=\frac{y_{b}\left(y_{b}-y_{a}+y_{a} \lambda_{a}^{\text {old }} K_{a a}+y_{b} \lambda_{b}^{\text {old }} K_{a a}-y_{a} \lambda_{a}^{\text {old }} K_{a b}-y_{b} \lambda_{b}^{\text {old }} K_{a b}+f\left(x_{a}\right)-y_{a} \lambda_{a} K_{a a}-y_{b} \lambda_{b} K_{a b}-b-f\left(x_{b}\right)+y_{a} \lambda_{a} K_{a b}+y_{b} \lambda_{b} K_{b b}+b\right)}{K_{a a}+K_{b b}-2 K_{a b}} & (3) \\ &=\frac{y_{b}\left(y_{b}-y_{a}+y_{b} \lambda_{b}^{\text {old }}\left(K_{a a}+K_{b b}-2 K_{a b}\right)+f\left(x_{a}\right)-f\left(x_{b}\right)\right)}{K_{a a}+K_{b b}-2 K_{a b}} & (4) \\ &=\lambda_{b}^{\text {old }}+\frac{y_{b}\left(f\left(x_{a}\right)-y_{a}-\left(f\left(x_{b}\right)-y_{b}\right)\right)}{K_{a a}+K_{b b}-2 K_{a b}} & (5) \\ E &=f(x)-y & (6) \\ K &=K_{a a}+K_{b b}-2 K_{a b} & (7) \\ \lambda_{b}^{\text {new }} &=\lambda_{b}^{\text {old }}+\frac{y_{b}\left(E_{a}-E_{b}\right)}{K} & (8) \end{aligned}
γλbnew EKλbnew =λaold +yaybλbold =Kaa+Kbb−2Kabyb(yb−ya+ya(λaold +yaybλbold )(Kaa−Kab)+va−vb)=Kaa+Kbb−2Kabyb(yb−ya+yaλaold Kaa+ybλbold Kaa−yaλaold Kab−ybλbold Kab+f(xa)−yaλaKaa−ybλbKab−b−f(xb)+yaλaKab+ybλbKbb+b)=Kaa+Kbb−2Kabyb(yb−ya+ybλbold (Kaa+Kbb−2Kab)+f(xa)−f(xb))=λbold +Kaa+Kbb−2Kabyb(f(xa)−ya−(f(xb)−yb))=f(x)−y=Kaa+Kbb−2Kab=λbold +Kyb(Ea−Eb)(1)(2)(3)(4)(5)(6)(7)(8)
推导变量
λ
a
λ_a
λa 的更新公式:
(1)由式 3-4 中的(2)式,更新前更新后该条件不变
(2)两边同时乘以
y
a
y_a
ya 后移项
(3)合并同类项
y
a
λ
a
new
+
y
b
λ
b
new
=
c
=
y
a
λ
a
old
+
y
b
λ
b
old
(
1
)
λ
a
new
=
λ
a
old
+
y
a
y
b
λ
b
old
−
y
a
y
b
λ
b
new
(
2
)
=
λ
a
old
+
y
a
y
b
(
λ
b
old
−
λ
b
new
)
(
3
)
\begin{aligned} y_{a} \lambda_{a}^{\text {new }}+y_{b} \lambda_{b}^{\text {new }} &=c=y_{a} \lambda_{a}^{\text {old }}+y_{b} \lambda_{b}^{\text {old }} & (1)\\ \lambda_{a}^{\text {new }} &=\lambda_{a}^{\text {old }}+y_{a} y_{b} \lambda_{b}^{\text {old }}-y_{a} y_{b} \lambda_{b}^{\text {new }} & (2)\\ &=\lambda_{a}^{\text {old }}+y_{a} y_{b}\left(\lambda_{b}^{\text {old }}-\lambda_{b}^{\text {new }}\right) & (3) \end{aligned}
yaλanew +ybλbnew λanew =c=yaλaold +ybλbold =λaold +yaybλbold −yaybλbnew =λaold +yayb(λbold −λbnew )(1)(2)(3)
变量
λ
b
λ_b
λb 的限制条件:
(1)、(2)所有
λ
λ
λ 都需要大于等于零
(3)分情况讨论
λ
b
λ_b
λb 的限制条件
(4)综合(1)式得到最终变量
λ
b
λ_b
λb 的限制条件
λ
b
new
≥
0
(
1
)
λ
a
new
=
λ
a
old
+
y
a
y
b
(
λ
b
old
−
λ
b
new
)
≥
0
(
2
)
⇒
{
λ
b
new
≤
λ
a
old
+
λ
b
old
,
y
a
y
b
=
+
1
λ
b
new
≥
λ
b
old
−
λ
a
old
,
y
a
y
b
=
−
1
(
3
)
⇒
{
0
≤
λ
b
new
≤
λ
a
old
+
λ
b
old
,
y
a
y
b
=
+
1
max
(
0
,
λ
b
old
−
λ
a
old
)
≤
λ
b
new
≤
+
∞
,
y
a
y
b
=
−
1
(
4
)
\begin{aligned} &\lambda_{b}^{\text {new }} \geq 0 & (1)\\ &\lambda_{a}^{\text {new }}=\lambda_{a}^{\text {old }}+y_{a} y_{b}\left(\lambda_{b}^{\text {old }}-\lambda_{b}^{\text {new }}\right) \geq 0 & (2)\\ &\Rightarrow \left\{\begin{aligned} \lambda_{b}^{\text {new }} \leq \lambda_{a}^{\text {old }}+\lambda_{b}^{\text {old }}, \quad y_{a} y_{b}=+1 \\ \lambda_{b}^{\text {new }} \geq \lambda_{b}^{\text {old }}-\lambda_{a}^{\text {old }}, \quad y_{a} y_{b}=-1 \end{aligned}\right. & (3)\\ &\Rightarrow \left\{\begin{aligned} 0 \leq \lambda_{b}^{\text {new }} \leq \lambda_{a}^{\text {old }}+\lambda_{b}^{\text {old }}, \quad y_{a} y_{b}=+1 \\ \max \left(0, \lambda_{b}^{\text {old }}-\lambda_{a}^{\text {old }}\right) \leq \lambda_{b}^{\text {new }} \leq+\infty, \quad y_{a} y_{b}=-1 \end{aligned}\right. & (4) \end{aligned}
λbnew ≥0λanew =λaold +yayb(λbold −λbnew )≥0⇒{λbnew ≤λaold +λbold ,yayb=+1λbnew ≥λbold −λaold ,yayb=−1⇒{0≤λbnew ≤λaold +λbold ,yayb=+1max(0,λbold −λaold )≤λbnew ≤+∞,yayb=−1(1)(2)(3)(4)
偏移量 b 的计算:
(1)定义集合 S 为所有
λ
λ
λ 大于零的元素,即所有支持向量点对应的拉格朗日乘子
(2)偏移量
b
b
b 的计算公式即
y
−
w
x
y - wx
y−wx,选取任意一个支持向量点进行计算
(3)更具鲁棒性的做法为计算所有支持向量点的结果取平均值
S
=
{
i
∣
λ
i
>
0
,
i
=
1
,
2
,
⋯
,
N
}
(
1
)
b
=
y
s
−
w
T
x
s
(
s
∈
S
)
(
2
)
b
=
1
∣
S
∣
∑
s
∈
S
(
y
s
−
∑
i
∈
S
λ
i
y
i
x
i
T
x
s
)
(
3
)
\begin{aligned} S &=\left\{i \mid \lambda_{i}>0, i=1,2, \cdots, N\right\} & (1)\\ b &=y_{s}-w^{T} x_{s} \quad(s \in S) & (2)\\ b &=\frac{1}{|S|} \sum_{s \in S}\left(y_{s}-\sum_{i \in S} \lambda_{i} y_{i} x_{i}^{T} x_{s}\right) & (3) \end{aligned}
Sbb={i∣λi>0,i=1,2,⋯,N}=ys−wTxs(s∈S)=∣S∣1s∈S∑(ys−i∈S∑λiyixiTxs)(1)(2)(3)
算法具体步骤
1、初始化拉格朗日乘子向量、权重向量、偏移量
2、初始化误差向量
3、选取两个待优化的拉格朗日乘子参数
4、按照式 3-6 中的(8)式更新
λ
b
λ_b
λb
5、检查
λ
b
λ_b
λb 的上下界,超过上界取上界,低于下界则取下界
6、按照式 3-7 中的(3)式更新
λ
a
λ_a
λa
7、重新计算偏移量
b
b
b、权重向量
w
w
w 和误差向量 E
8、重复 3~7 直至所有拉格朗日乘子满足 KKT 条件或者代价函数没有明显的变化
待优化参数的选择
根据 John C. Platt 的论文《Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines》5 ,给出了一个启发式的选择参数方法:第一个参数选择不满足 KKT 条件的拉格朗日乘子参数,第二个参数则选择使得 | E a − E b | |E_a - E_b| |Ea−Eb|最大的拉格朗日乘子参数。
四、原理证明
任一点到超平面的距离
假设
x
0
x_0
x0 为任意点,
x
t
x_t
xt 为
x
0
x_0
x0 到超平面
w
x
+
b
=
0
wx + b = 0
wx+b=0 的投影:
(1)
x
0
x
t
x_0x_t
x0xt 表示
x
0
x_0
x0 到
x
t
x_t
xt 的向量,
w
w
w 为超平面的法向量,其方向与
x
0
x
t
x_0x_t
x0xt 一致,所以夹角为零
(2)
cos
0
=
1
\cos 0 = 1
cos0=1
(3)计算两个向量的内积,将
x
0
x
t
x_0x_t
x0xt 写成向量差的形式
(4)展开括号
(5)由于
x
t
x_t
xt 是超平面上的点,所以
w
x
+
b
=
0
wx + b = 0
wx+b=0
(6)化简得到
(7)由(2)式与(6)式得
(8)求得任一点到超平面的距离
∣
w
⋅
x
0
x
t
∣
=
∣
∣
w
∣
⋅
∣
x
0
x
t
∣
⋅
cos
0
∘
∣
(
1
)
=
∣
w
∣
⋅
∣
x
0
x
t
∣
(
2
)
w
⋅
x
0
x
t
=
w
⋅
(
x
0
−
x
t
)
(
3
)
=
w
⋅
x
0
−
w
⋅
x
t
(
4
)
=
w
⋅
x
0
−
(
−
b
)
(
5
)
=
w
⋅
x
0
+
b
(
6
)
∣
w
⋅
x
0
+
b
∣
=
∣
w
∣
⋅
∣
x
0
x
t
∣
(
7
)
∣
x
0
x
t
∣
=
∣
w
⋅
x
0
+
b
∣
∣
w
∣
(
8
)
\begin{aligned} \left|w \cdot x_{0} x_{t}\right| &=|| w|\cdot| x_{0} x_{t}\left|\cdot \cos 0^{\circ}\right| & (1)\\ &=|w| \cdot\left|x_{0} x_{t}\right| & (2)\\ w \cdot x_{0} x_{t} &=w \cdot\left(x_{0}-x_{t}\right) & (3)\\ &=w \cdot x_{0}-w \cdot x_{t} & (4)\\ &=w \cdot x_{0}-(-b) & (5)\\ &=w \cdot x_{0}+b & (6)\\ \left|w \cdot x_{0}+b\right| &=|w| \cdot\left|x_{0} x_{t}\right| & (7)\\ \left|x_{0} x_{t}\right| &=\frac{\left|w \cdot x_{0}+b\right|}{|w|} & (8) \end{aligned}
∣w⋅x0xt∣w⋅x0xt∣w⋅x0+b∣∣x0xt∣=∣∣w∣⋅∣x0xt∣⋅cos0∘∣=∣w∣⋅∣x0xt∣=w⋅(x0−xt)=w⋅x0−w⋅xt=w⋅x0−(−b)=w⋅x0+b=∣w∣⋅∣x0xt∣=∣w∣∣w⋅x0+b∣(1)(2)(3)(4)(5)(6)(7)(8)
| x 0 x t | |x_0x_t| |x0xt|即为点到超平面的距离,既得证。
两个超平面的间距
两个平行的超平面之间的距离等于点到两个超平面的距离之差的绝对值。根据式 2-3 的限制条件,下面分两种情况讨论:
(1)当
w
x
+
b
wx + b
wx+b 大于等于 1 时,其内部的绝对值可以去掉
(2)化简后得到结果
(3)当
w
x
+
b
wx + b
wx+b 小于等于 -1 时,其内部的绝对值可以去掉
(4)化简后得到结果
∣
∣
w
T
x
+
b
+
1
∣
∣
w
∣
−
∣
w
T
x
+
b
−
1
∣
∣
w
∣
∣
=
∣
w
T
x
+
b
+
1
∣
w
∣
−
w
T
x
+
b
−
1
∣
w
∣
∣
(
1
)
=
2
∣
w
∣
(
2
)
∣
∣
w
T
x
+
b
+
1
∣
∣
w
∣
−
∣
w
T
x
+
b
−
1
∣
∣
w
∣
∣
=
∣
−
w
T
x
−
b
−
1
∣
w
∣
−
−
w
T
x
−
b
+
1
∣
w
∣
∣
(
3
)
=
2
∣
w
∣
(
4
)
\begin{aligned} \left|\frac{\left|w^{T} x+b+1\right|}{|w|}-\frac{\left|w^{T} x+b-1\right|}{|w|}\right| &=\left|\frac{w^{T} x+b+1}{|w|}-\frac{w^{T} x+b-1}{|w|}\right| & (1)\\ &=\frac{2}{|w|} & (2)\\ \left|\frac{\left|w^{T} x+b+1\right|}{|w|}-\frac{\left|w^{T} x+b-1\right|}{|w|}\right| &=\left|\frac{-w^{T} x-b-1}{|w|}-\frac{-w^{T} x-b+1}{|w|}\right| & (3)\\ &=\frac{2}{|w|} & (4) \end{aligned}
∣∣∣∣∣∣w∣∣∣wTx+b+1∣∣−∣w∣∣∣wTx+b−1∣∣∣∣∣∣∣∣∣∣∣∣∣w∣∣∣wTx+b+1∣∣−∣w∣∣∣wTx+b−1∣∣∣∣∣∣∣=∣∣∣∣∣w∣wTx+b+1−∣w∣wTx+b−1∣∣∣∣=∣w∣2=∣∣∣∣∣w∣−wTx−b−1−∣w∣−wTx−b+1∣∣∣∣=∣w∣2(1)(2)(3)(4)
综合上面两种情况得到两个超平面的距离公式,既得证。
五、代码实现
使用 Python 实现
import numpy as np
class SMO:
"""
硬间隔支持向量机
序列最小优化算法实现(Sequential minimal optimization/SMO)
"""
def __init__(self, X, y):
# 训练样本特征矩阵(N * p)
self.X = X
# 训练样本标签向量(N * 1)
self.y = y
# 拉格朗日乘子向量(N * 1)
self.alpha = np.zeros(X.shape[0])
# 误差向量,默认为负的标签向量(N * 1)
self.errors = -y
# 偏移量
self.b = 0
# 权重向量(p * 1)
self.w = np.zeros(X.shape[1])
# 代价值
self.cost = -np.inf
def fit(self, tol = 1e-6):
"""
算法来自 John C. Platt 的论文
https://www.microsoft.com/en-us/research/uploads/prod/1998/04/sequential-minimal-optimization.pdf
"""
# 更新变化次数
numChanged = 0
# 是否检查全部
examineAll = True
while numChanged > 0 or examineAll:
numChanged = 0
if examineAll:
for idx in range(X.shape[0]):
numChanged += self.update(idx)
else:
for idx in range(X.shape[0]):
if self.alpha[idx] <= 0:
continue
numChanged += self.update(idx)
if examineAll:
examineAll = False
elif numChanged == 0:
examineAll = True
# 计算代价值
cost = self.calcCost()
# 当代价值的变化小于容许的范围时结束算法
if cost - self.cost <= tol:
break
self.cost = cost
def update(self, idx):
"""
对下标为 idx 的拉格朗日乘子进行更新
"""
X = self.X
y = self.y
alpha = self.alpha
# 检查当前拉格朗日乘子是否满足KKT条件,满足条件则直接返回 0
if self.checkKKT(idx):
return 0
if len(alpha[(alpha != 0)]) > 1:
# 按照|E1 - E2|最大的原则寻找第二个待优化的拉格朗日乘子的下标
jdx = self.selectJdx(idx)
# 对下标为 idx、jdx 的拉格朗日乘子进行更新,当成功更新时直接返回 1
if self.updateAlpha(idx, jdx):
return 1
# 当未更新成功时,遍历不为零的拉格朗日乘子进行更新
for jdx in range(X.shape[0]):
if alpha[jdx] == 0:
continue
# 对下标为 idx、jdx 的拉格朗日乘子进行更新,当成功更新时直接返回 1
if self.updateAlpha(idx, jdx):
return 1
# 当依然没有没有更新成功时,遍历为零的拉格朗日乘子进行更新
for jdx in range(X.shape[0]):
if alpha[jdx] != 0:
continue
# 对下标为 idx、jdx 的拉格朗日乘子进行更新,当成功更新时直接返回 1
if self.updateAlpha(idx, jdx):
return 1
# 依然没有更新时返回 0
return 0
def selectJdx(self, idx):
"""
寻找第二个待优化的拉格朗日乘子的下标
"""
errors = self.errors
if errors[idx] > 0:
# 当误差项大于零时,选择误差向量中最小值的下标
return np.argmin(errors)
elif errors[idx] < 0:
# 当误差项小于零时,选择误差向量中最大值的下标
return np.argmax(errors)
else:
# 当误差项等于零时,选择误差向量中最大值和最小值的绝对值最大的下标
minJdx = np.argmin(errors)
maxJdx = np.argmax(errors)
if max(np.abs(errors[minJdx]), np.abs(errors[maxJdx])) - errors[minJdx]:
return minJdx
else:
return maxJdx
def calcB(self):
"""
计算偏移量
分别计算每一个拉格朗日乘子不为零对应的偏移量后取其平均值
"""
X = self.X
y = self.y
alpha = self.alpha
alpha_gt = alpha[alpha > 0]
# 拉格朗日乘子向量中不为零的数量
alpha_gt_len = len(alpha_gt)
# 全部为零时直接返回 0
if alpha_gt_len == 0:
return 0
# b = y - Wx,具体算法请参考文章中的说明
X_gt = X[alpha > 0]
y_gt = y[alpha > 0]
alpha_gt_y = np.array(np.multiply(alpha_gt, y_gt)).reshape(-1, 1)
s = np.sum(np.multiply(alpha_gt_y, X_gt), axis=0)
return np.sum(y_gt - X_gt.dot(s)) / alpha_gt_len
def calcCost(self):
"""
计算代价值
按照文章中的算法计算即可
"""
X = self.X
y = self.y
alpha = self.alpha
cost = 0
for idx in range(X.shape[0]):
for jdx in range(X.shape[0]):
cost = cost + (y[idx] * y[jdx] * X[idx].dot(X[jdx]) * alpha[idx] * alpha[jdx])
return np.sum(alpha) - cost / 2
def checkKKT(self, idx):
"""
检查下标为 idx 的拉格朗日乘子是否满足 KKT 条件
1. alpha >= 0
2. y * f(x) - 1 >= 0
3. alpha * (y * f(x) - 1) = 0
"""
y = self.y
errors = self.errors
alpha = self.alpha
r = errors[idx] * y[idx]
if (alpha[idx] > 0 and r == 0) or (alpha[idx] == 0 and r >= 0):
return True
return False
def calcE(self):
"""
计算误差向量
E = f(x) - y
"""
X = self.X
y = self.y
alpha = self.alpha
alpha_y = np.array(np.multiply(alpha, y)).reshape(-1, 1)
errors = X.dot(X.T).dot(alpha_y).T[0] + b - y
return errors
def calcU(self, idx, jdx):
"""
计算拉格朗日乘子上界,使两个待优化的拉格朗日乘子同时大于等于0
按照文章中的算法计算即可
"""
y = self.y
alpha = self.alpha
if y[idx] * y[jdx] == 1:
return 0
else:
return max(0.0, alpha[jdx] - alpha[idx])
def calcV(self, idx, jdx):
"""
计算拉格朗日乘子下界,使两个待优化的拉格朗日乘子同时大于等于0
按照文章中的算法计算即可
"""
y = self.y
alpha = self.alpha
if y[idx] * y[jdx] == 1:
return alpha[jdx] + alpha[idx]
else:
return np.inf
def updateAlpha(self, idx, jdx):
"""
对下标为 idx、jdx 的拉格朗日乘子进行更新
按照文章中的算法计算即可
"""
if idx == jdx:
return False
X = self.X
y = self.y
alpha = self.alpha
errors = self.errors
# idx 的误差项
Ei = errors[idx]
# jdx 的误差项
Ej = errors[jdx]
Kii = X[idx].dot(X[idx])
Kjj = X[jdx].dot(X[jdx])
Kij = X[idx].dot(X[jdx])
# 计算 K
K = Kii + Kjj - 2 * Kij
oldAlphaIdx = alpha[idx]
oldAlphaJdx = alpha[jdx]
# 计算 jdx 的新拉格朗日乘子
newAlphaJdx = oldAlphaJdx + y[jdx] * (Ei - Ej) / K
U = self.calcU(idx, jdx)
V = self.calcV(idx, jdx)
if newAlphaJdx < U:
# 当新值超过上界时,修改其为上界
newAlphaJdx = U
if newAlphaJdx > V:
# 当新值低于下界时,修改其为下界
newAlphaJdx = V
if oldAlphaJdx == newAlphaJdx:
# 当新值与旧值相等时,判断为未更新,直接返回
return False
# 计算 idx 的新拉格朗日乘子
newAlphaIdx = oldAlphaIdx + y[idx] * y[jdx] * (oldAlphaJdx - newAlphaJdx)
# 重新计算偏移量
self.b = self.calcB()
# 更新权重向量
self.w = self.w + y[idx] * (newAlphaIdx - oldAlphaIdx) * X[idx] + y[jdx] * (newAlphaJdx - oldAlphaJdx) * X[jdx]
# 更新拉格朗日乘子向量
alpha[idx] = newAlphaIdx
alpha[jdx] = newAlphaJdx
# 重新计算误差向量
self.errors = self.calcE()
return True
smo = SMO(X, y)
smo.fit()
print("w", smo.w, "b", smo.b)
六、第三方库实现
scikit-learn6 实现
from sklearn.svm import SVC
svc = SVC(kernel = "linear")
# 拟合数据
svc.fit(X, y)
# 权重系数
w = svc.coef_
# 截距
b = svc.intercept_
print("w", w, "b", b)
七、动画演示
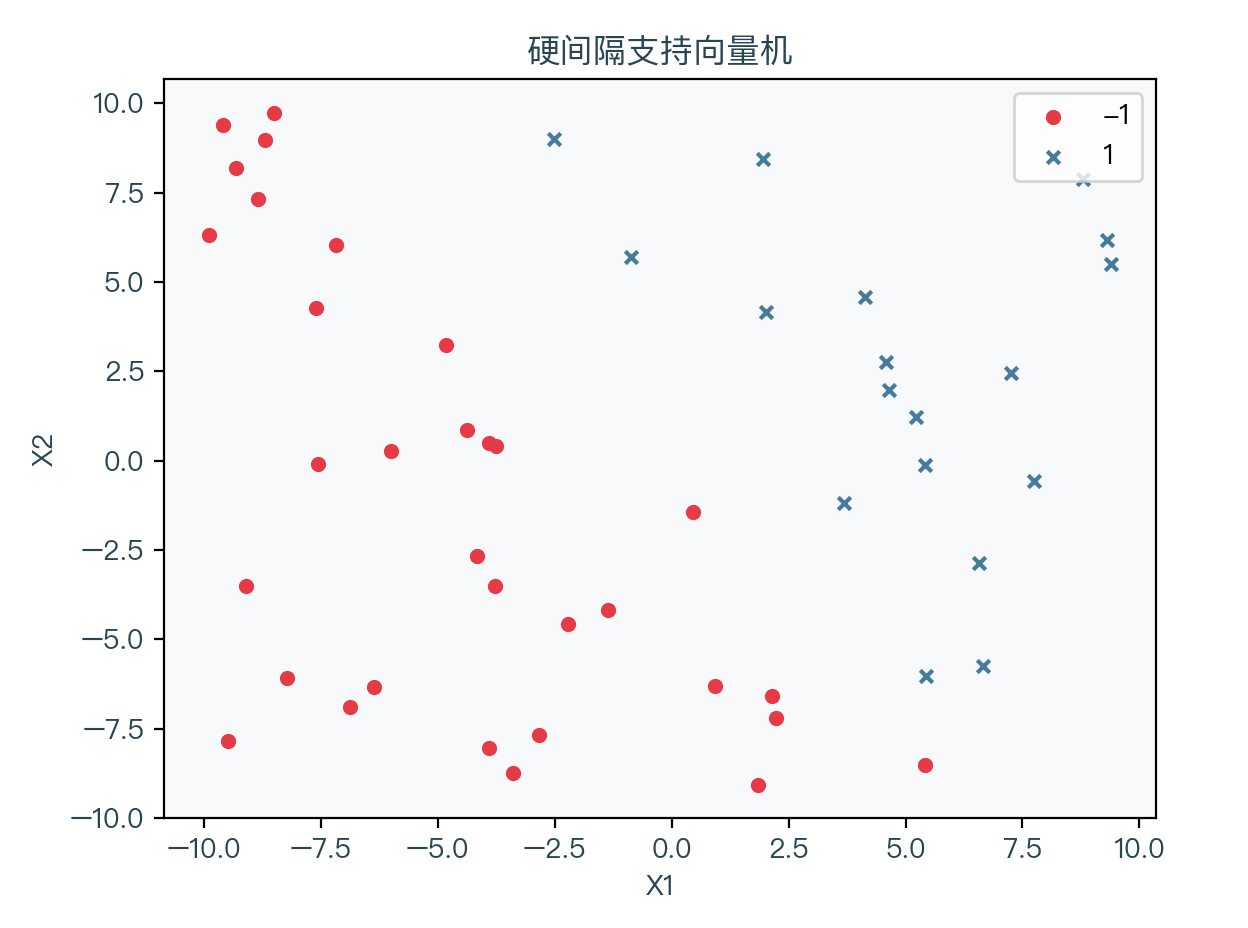
下图展示了一个线性可分的数据集,其中红色表示标签值为 -1 的样本点,蓝色代表标签值为 1 的样本点:
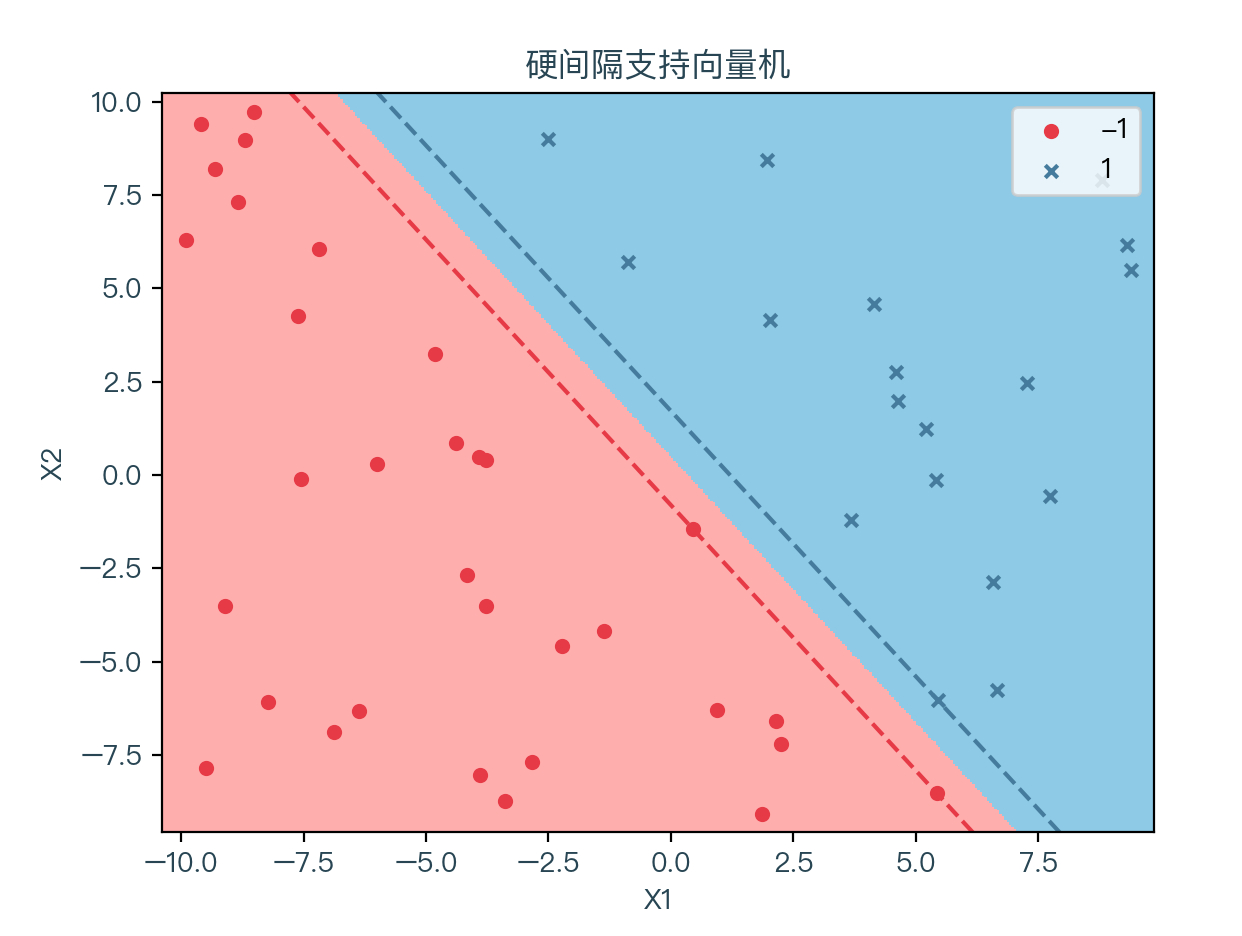
下图展示了通过支持向量机拟合数据后的结果,其中浅红色的区域为预测值为 -1 的部分,浅蓝色的区域则为预测值为 1 的部分。两条虚线分别为 wx + b = 1 和 wx + b = -1,可以看到图中的支持向量一共有三个,分布在两条虚线上,符合前面说的支持向量机的特性。
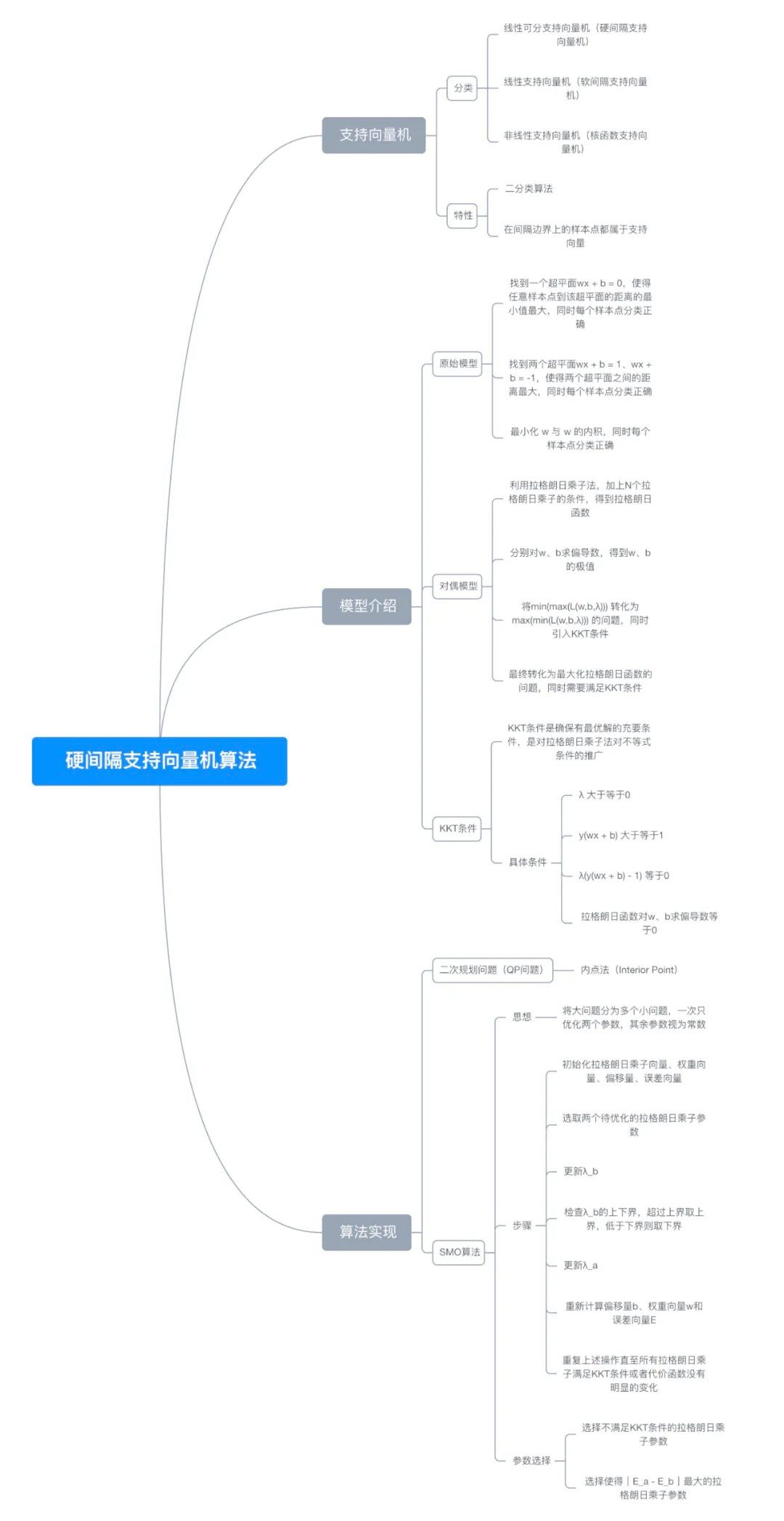
八、思维导图
九、参考文献
- https://en.wikipedia.org/wiki/Support-vector_machine
- https://en.wikipedia.org/wiki/Karush%E2%80%93Kuhn%E2%80%93Tucker_conditions
- https://en.wikipedia.org/wiki/Quadratic_programming
- https://en.wikipedia.org/wiki/Sequential_minimal_optimization
- https://www.microsoft.com/en-us/research/uploads/prod/1998/04/sequential-minimal-optimization.pdf
- https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
完整演示请点击这里
注:本文力求准确并通俗易懂,但由于笔者也是初学者,水平有限,如文中存在错误或遗漏之处,恳请读者通过留言的方式批评指正
本文首发于——AI导图,欢迎关注















 8651
8651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









