







昨天接到家里领导布置的一项任务,需要在微信公众号的后台,将文章列表的每一篇文章进行截屏保存,作为一名不太资深的程序猿,碰到这种问题的第一反应肯定是通过爬虫来解决,requests加BeautifulSoup的组合拳已经蓄势待发,但是立马发现一个问题,网站需要登录才能访问,并且网站是通过扫码登录,没有办法直接请求登录url获取用户token。转换思路,暗的不行我们就来明的,爬虫不行按键精灵总可以,于是立马想到了自动化测试工具selenium,经过简单测试后发现确实可行,话不多说,321上代码~
这里只用到两个第三方库,selenium和pathvalidate,自行pip安装即可,最新版本的selenium已经支持直接调用本机安装的浏览器,因此不需要再去下载浏览器驱动。pathvalidate库我们后面会用到,再说。经过简单的配置,运行程序即可调起浏览器。这里我的用的Edge,Chrome同理:
from selenium import webdriver
from selenium.webdriver.edge.service import Service as EdgeService
from webdriver_manager.microsoft import EdgeChromiumDriverManager
from pathvalidate import sanitize_filename
options = webdriver.EdgeOptions()
options.add_experimental_option('detach', True)
driver = webdriver.Edge(service=EdgeService(EdgeChromiumDriverManager().install()), options=options)直接跳转至微信公众号后台登录页面,由于微信公众号后台是通过扫码登录的,因此程序运行到这里需要等待扫码,因为扫码的手机不在我本人手上,如果用time.sleep等待会有一个尴尬的问题,设的时间长了,扫完了会在那里干等,设的时间短了,扫慢了就会出现异常,所以这里直接用了一个简单粗暴的办法,放一个input,等对方确认扫码完成跳转后,手动按下回车即可继续执行:
driver.get('https://mp.weixin.qq.com/')
input('完成扫码登录后按回车键确认:')登录完成之后,我们先观察一下跳转的url:
https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=924077534
以及在文章列表页面进行搜索后跳转的url:
显而易见,begin和count是分页参数,query是关键字,并且url里还惊现了token,这也太赤裸裸了吧,当然经过简单验证,只有这个token是没用的,你现在再点下上面的链接,还是得登录,微信公众号后台的验证机制应该是通过cookies+token来实现。但是我们还是得把这个token先取出来,直接从登录之后跳转的url中截取即可,要注意这个token不是定长的,一开始在这里踩了坑,如果这个token不对的话,即使登录了也无法正常跳转到搜索结果页面:
url = driver.current_url
token_index = url.index('token=')
token = url[token_index+6:]
print('token='+token)然后我们还需要自定义一个关键字变量,加上前面取到的token,就可以拼接成搜索结果页面的url,直接进行跳转:
key_word = '关键字'
driver.get('https://mp.weixin.qq.com/cgi-bin/appmsgpublish?sub=search&begin=0&count=10&query='+key_word+'&token='+token+'&lang=zh_CN')注意这里的begin=0表示从第0条记录开始,count=10表示每页显示10条,两个参数合在一起页面上就会跳到第1页。结合页面上的分页栏,我们可以看到这里前端工程师绝对偷懒了,没有每页显示条数的下拉框可以选。自己试验了一下把url里的参数改成count=100,结果发现也只返回了20条记录,好吧,后端工程师也偷懒了。因此这里就按默认的count=10处理,要显示第2页就是begin=10,第3页的话begin=20,以此类推一直到最后一页。因此,我们还要取得一个总页数作为变量,然后根据页数进行循环遍历每一页。
在页面上F12分析一下分页栏的html源码:
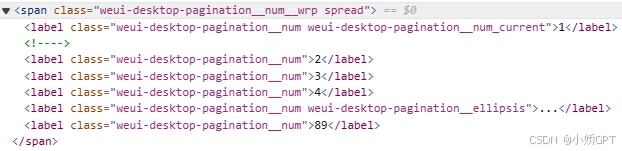
显然这里最后一个数字89就是我们要取的总页数。直接通过selenium的find_element和find_elements就可以轻松定位到相应标签,拿到数字后开始循环跳转:
pagination_bar = driver.find_element('class name', 'weui-desktop-pagination__nav')
page_numbers = pagination_bar.find_elements('tag name', 'label')
max_page_numbers = int(page_numbers[len(page_numbers)-1].text)
for i in range(max_page_numbers):
driver.get('https://mp.weixin.qq.com/cgi-bin/appmsgpublish?sub=search&begin='+str(i*10)+'&count=10&query='+key_word+'&token='+token+'&lang=zh_CN')接下来就是把每一页上的10篇文章进行截屏。再次F12分析html源码,可以看到每篇文章对应一个class="weui-desktop-block"的<div>:

继续find_elements,拿到结果后进行循环遍历每一个<div>。这里要注意的一点是weui-desktop-block这个样式在上一层的<div>里也有用到,所以每次find_elements后会出现11个<div>,我们只需手动过滤掉第一个就行:
target_div = driver.find_elements('class name', 'weui-desktop-block')
for idx, div in enumerate(target_div):
if idx == 0:
continue后面的事情就很简单了,我们只需要对每个<div>做个截屏,selenium已经内置screenshot方法,然后提取发表日期和文章标题,把文件按“发表日期 - 文章标题”格式命名。同理通过F12查看发表日期和文章标题对应的标签,再进行定位,这里不再赘述。最后有一些特殊处理,首先发表日期如果是当年的,页面上不会显示年份,因此我们手动补上,确保日期格式一致,以便于排序。其次,当文件名中含有特殊字符时是无法保存的,但是我们又无法一个个去查看哪些文章标题里包含哪些特殊字符,这里就用到了我们一开始提到的pathvalidate库,它的作用就是规范文件名称,把特殊字符转换为其他可用字符,直接sanitize_filename一下就好了。最后我们调用screenshot方法保存截图文件即可:
issue_date = div.find_element('class name', 'weui-desktop-mass__time').text
if '年' not in issue_date:
issue_date = '2024年' + issue_date
title_div = div.find_element('class name', 'weui-desktop-mass-appmsg__title')
title = title_div.find_element('tag name', 'span').text
issue_date = sanitize_filename(issue_date, '_')
title = sanitize_filename(title, '_')
res = div.screenshot('result/' + issue_date + ' - ' + title + '.png')
if res:
print('截图' + str(i * 10 + idx) + '保存成功')
else:
print('截图' + str(i * 10 + idx) + '保存失败')这里还有一个大坑,就是screenshot方法它在保存失败的时候是不会抛异常的,导致每次程序都正常运行,但是保存的截图数量跟文章总数总是差那么几个,最后查阅文档才得知它是会返回一个boolean类型来表示保存成功和失败,于是我们加上一个if判断输出保存结果,就能火速定位到哪一张图没保存成功,再进行排查,最后大功告成~
将近一百页的文章基本上一两分钟就运行完毕,一千来张张截图瞬间整整齐齐得躺在文件夹里,舒服。当然这里只截取搜结果页面的文章缩略图即可,如果要截全文,还需要在程序中操作进一步点击打开文章链接后再截全页。好了,这么奇葩的需求应该也不会有第二个人碰到了吧,如真有需要,完整代码在文章中均已列出,请自行提取。

















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









