







转载:http://blog.csdn.net/cjf_iceking/article/details/7951481
插入排序的算法复杂度为O(n2),但如果序列为正序可提高到O(n),而且直接插入排序算法比较简单,希尔排序利用这两点得到了一种改进后的插入排序。
一. 算法描述
希尔排序:将无序数组分割为若干个子序列,子序列不是逐段分割的,而是相隔特定的增量的子序列,对各个子序列进行插入排序;然后再选择一个更小的增量,再将数组分割为多个子序列进行排序......最后选择增量为1,即使用直接插入排序,使最终数组成为有序。
增量的选择:在每趟的排序过程都有一个增量,至少满足一个规则 增量关系 d[1] > d[2] > d[3] >..> d[t] = 1 (t趟排序);根据增量序列的选取其时间复杂度也会有变化,这个不少论文进行了研究,在此处就不再深究;
本文采用首选增量为n/2,以此递推,每次增量为原先的1/2,直到增量为1;
下图详细讲解了一次希尔排序的过程:(使用希尔增量)
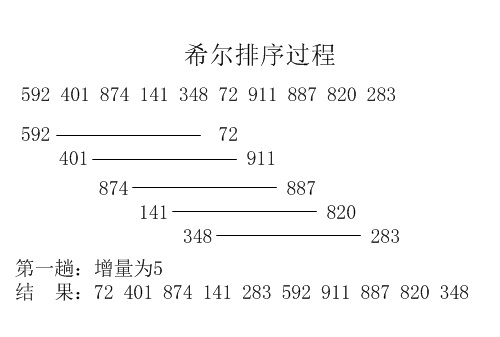

二. 算法分析
平均时间复杂度:希尔排序的时间复杂度和其增量序列有关系,这涉及到数学上尚未解决的难题;不过在某些序列中复杂度可以为O(n1.3);
空间复杂度:O(1)
稳定性:不稳定
三. 算法实现
- /********************************************************
- *函数名称:ShellInsert
- *参数说明:pDataArray 无序数组;
- * d 增量大小
- * iDataNum为无序数据个数
- *说明: 希尔按增量d的插入排序
- *********************************************************/
- void ShellInsert(int* pDataArray, int d, int iDataNum)
- {
- for (int i = d; i < iDataNum; i += 1) //从第2个数据开始插入
- {
- int j = i - d;
- int temp = pDataArray[i]; //记录要插入的数据
- while (j >= 0 && pDataArray[j] > temp) //从后向前,找到比其小的数的位置
- {
- pDataArray[j+d] = pDataArray[j]; //向后挪动
- j -= d;
- }
- if (j != i - d) //存在比其小的数
- pDataArray[j+d] = temp;
- }
- }
- /********************************************************
- *函数名称:ShellSort
- *参数说明:pDataArray 无序数组;
- * iDataNum为无序数据个数
- *说明: 希尔排序
- *********************************************************/
- void ShellSort(int* pDataArray, int iDataNum)
- {
- int d = iDataNum / 2; //初始增量设为数组长度的一半
- while(d >= 1)
- {
- ShellInsert(pDataArray, d, iDataNum);
- d = d / 2; //每次增量变为上次的二分之一
- }
- }
Sedgewick增量的增量排序
地址:http://blog.csdn.net/ottocho/article/details/5292513
希尔排序(Shell Sort)又叫做缩小增量排序(diminishing increment sort),是一种很优秀的排序法,算法本身不难理解,也很容易实现,而且它的速度很快。
插入排序(Insertion Sort)的一个重要的特点是,如果原始数据的大部分元素已经排序,那么插入排序的速度很快(因为需要移动的元素很少)。从这个事实我们可以想到,如果原始数据只有很少元素,那么排序的速度也很快。
希尔排序就是基于这两点对插入排序作出了改进。
增量数列的选择对希尔排序的性能有着极大的影响。[Mark Allen Weiss]指出,最好的增量序列是 Sedgewick提出的 (1, 5, 19, 41, 109,...),该序列的项来自 9 * 4^i - 9 * 2^i + 1 和 4^i - 3 * 2^i + 1 这两个算式。
下面是一个使用 Sedgewick增量 的希尔排序的完整C语言程序:
- /* kikistar.com - 使用 Sedgewick增量 的 Shell Sort 程序 */
- #include <stdio.h>
- #include <stdlib.h>
- #include <math.h>
- #define MAX 1000000 //这里设定要对多少个元素排序
- void shellsort(int A[], int N, int *);
- void printarray(int A[]);
- int main()
- {
- int i, s[MAX];
- int *sed;
- int sedgewick[] = { // Sedgewick增量
- 1073643521, 603906049, 268386305, 150958081, 67084289,
- 37730305, 16764929, 9427969, 4188161, 2354689,
- 1045505, 587521, 260609, 146305, 64769,
- 36289, 16001, 8929, 3905, 2161,
- 929, 505, 209, 109, 41,
- 19, 5, 1, 0 }; //用 0 标记终点
- for (sed = sedgewick; *sed > MAX; sed++) // 增量必须小于元素个数
- /* void */;
- for (i = 0; i < MAX; i++)
- s[i] = 1+(int) ((float)MAX*rand()/(RAND_MAX+1.0));
- printf("before :");
- printarray(s);
- shellsort(s, MAX, sed);
- printf("after :");
- printarray(s);
- return 0;
- }
- /* Shell Sort: 把增量序列放在数组里 */
- void shellsort(int v[], int n, int *sed)
- {
- int i, j, temp;
- int *gap;
- for (gap = sed; *gap > 0; gap++)
- for (i = *gap; i < n; i++)
- for (j = i - *gap; j>=0 && v[j]>v[j + *gap]; j -= *gap) {
- temp = v[j];
- v[j] = v[j + *gap];
- v[j + *gap] = temp;
- }
- }
- void printarray(int a[])
- {
- int i;
- for (i = 0; i < MAX; i++)
- printf(" %d", a[i]);
- printf("/n");
- }
在Linux下可以这样测试程序的运行时间:
$ time ./a.out >/dev/null
real 0m2.603s
user 0m2.549s
sys 0m0.019s
上面是在我的机器里,把 MAX 设定为 1000000 时的运行时间。
Sedgewick增量可用像下面那样的程序求得。
/* 计算 Sedgewick增量 的程序 */
- #include <stdio.h>
- #include <stdlib.h>
- #include <math.h>
- #define wick 100
- void insertsort(int A[], int N);
- void printarray(int A[], int from, int to);
- int main()
- {
- int i, j;
- int sedge[wick];
- i = -1;
- do {
- ++i;
- sedge[i] = 9 * pow(4,i) - 9 * pow(2,i) + 1;
- printf("sedge[%d] = %d/n", i, sedge[i]);
- } while (sedge[i] > 0);
- printf("/n");
- j = 1;
- do {
- ++j; // j = 0 和 j = 1 时该算式的解小于0,所以从 j = 2 开始取值。
- sedge[j+i-2] = pow(4,j) - 3 * pow(2, j) + 1;
- printf("sedge[%d] = %d/n", j+i-2, sedge[j+i-2]);
- } while (sedge[j+i-2] > 0);
- printf("/n");
- printarray(sedge, 0, j+i-2);
- insertsort(sedge, j+i-2);
- printarray(sedge, 0, j+i-2);
- return 0;
- }
- void printarray(int a[], int from, int to)
- {
- int i;
- for (i = from; i < to; i++)
- printf("%d, ", a[i]);
- printf("/n/n");
- }
- /* 从大到小排序 */
- void insertsort(int A[], int n)
- {
- int i, j, key;
- for (j = 1; j < n; j++)
- {
- key = A[j];
- i = j - 1;
- while (i >= 0 && A[i] < key)
- {
- A[i+1] = A[i];
- --i;
- }
- A[i+1] = key;
- }
- }
由于用了 math.h,用 GCC 编译时注意要加上 -lm 参数。
$ gcc -Wall sedgewick.c -lm
本例代码关于希尔排序的实现:首先选取一个增量的选取方法,然后按照增量的选取规则,每次循环的对数据按照增量的间隔进行插入排序式的排序,其本质就是对独立子数组进行插入排序。 希尔排序:希尔排序的运行时间主要依赖于增量序列的选取,以上例子代码中使用的增量是Shell建议的 h1 = [Length/2]; h2 = [h1/2] ....但是这个增量的选取并不好,而且效率最坏的情况为O(n^2);下边列举一种增量的选取: (1) Hibbard的增量选取法:1、3、7 ... 2^k-1...;因为这种增量的选取方法,没有公因子,据证明效率为O(N^(3/2));但是也有说经过大量的运行这种增量选取的效率为O(N^(5/4));但都比shell增量效率要高; (2)Sedgewick提出的另一种增量选取:9*4^i-9*2^i + 1或是4^i - 3*4^i + 1;通过这两种选取增量的方法可以实现shell排序平均效率猜想为O(N^(7/6)),已经比Hibbard 的方法效率高了。 关于希尔排序:希尔排序的性能在实践中是完全可以接受的,即使对于数以万计的N仍然是这样,由于编程简单的特点,使得shell排序对应大量的数据输入的常用算法。















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









