







在C中,默认的基础数据类型均为signed,现在我们以char为例,说明(signed) char与unsigned char之间的区别
首先在内存中,char与unsigned char没有什么不同, 都是一个字节,唯一的区别是,char的最高位为符号位,因此char能表示-128~127,unsigned char没有符号位,因此能表示0~255,这个好理解,8个bit,最多256种情况,因此无论如何都能表示256个数字。
在实际使用过程种有什么区别呢?
主要是符号位,但是在普通的赋值,读写文件和网络字节流都没什么区别,反正就是一个字节,不管最高位是什么,最终的读取结果都一样,只是你怎么理解最高位而已,在屏幕上面的显示可能不一样。
但是我们却发现在表示byte时,都用unsigned char,这是为什么呢?
首先我们通常意义上理解,byte没有什么符号位之说,更重要的是如果将byte的值赋给int,long等数据类型时,系统会做一些额外的工作。如果是 char,那么系统认为最高位是符号位,而int可能是16或者32位,那么会对最高位进行扩展(注意,赋给unsigned int也会扩展)而如果是 unsigned char,那么不会扩展。
首先在内存中,char与unsigned char没有什么不同, 都是一个字节,唯一的区别是,char的最高位为符号位,因此char能表示-128~127,unsigned char没有符号位,因此能表示0~255,这个好理解,8个bit,最多256种情况,因此无论如何都能表示256个数字。
在实际使用过程种有什么区别呢?
主要是符号位,但是在普通的赋值,读写文件和网络字节流都没什么区别,反正就是一个字节,不管最高位是什么,最终的读取结果都一样,只是你怎么理解最高位而已,在屏幕上面的显示可能不一样。
但是我们却发现在表示byte时,都用unsigned char,这是为什么呢?
首先我们通常意义上理解,byte没有什么符号位之说,更重要的是如果将byte的值赋给int,long等数据类型时,系统会做一些额外的工作。如果是 char,那么系统认为最高位是符号位,而int可能是16或者32位,那么会对最高位进行扩展(注意,赋给unsigned int也会扩展)而如果是 unsigned char,那么不会扩展。
这就是二者的最大区别。

这里又想起另外一个问题:数字1和字符1在计算机实际储存的值
如果都是一个字节,那么数字1实际存储的是0x01,字符'1'实际存储的是0x31。
上一段代码,这段代码的功能是将unsigned char类型字符串的内容以其真实内存数据形式存储到另外一个字符串里
static const char hex_chars[] = "0123456789ABCDEF";
CString convert_hex(unsigned char *md/*字符串*/,int nLen/*转义多少个字符*/)
{
CString strSha1(_T(""));
unsigned int c = 0;
// 查看unsigned char占几个字节
// 实际占1个字节,8位
int nByte = sizeof(unsigned char);
for (int i = 0; i < nLen; i++)
{
// 查看md一个字节里的信息
unsigned int x = 0;
x = md[i];
x = md[i] >> 4;// 右移,干掉4位,左边高位补0000
c = (md[i] >> 4) & 0x0f;
strSha1 += hex_chars[c];
strSha1 += hex_chars[md[i] & 0x0f];
}
return strSha1;
}
void OnBnClickedButton2()
{
unsigned char org[] = "123456789abcdf我爱你二进制";
CString str;
int i=1;
i = i <<4;// 左移 执行完这行i的值为16
str=convert_hex(org,20);
OutputDebugString(str);
}
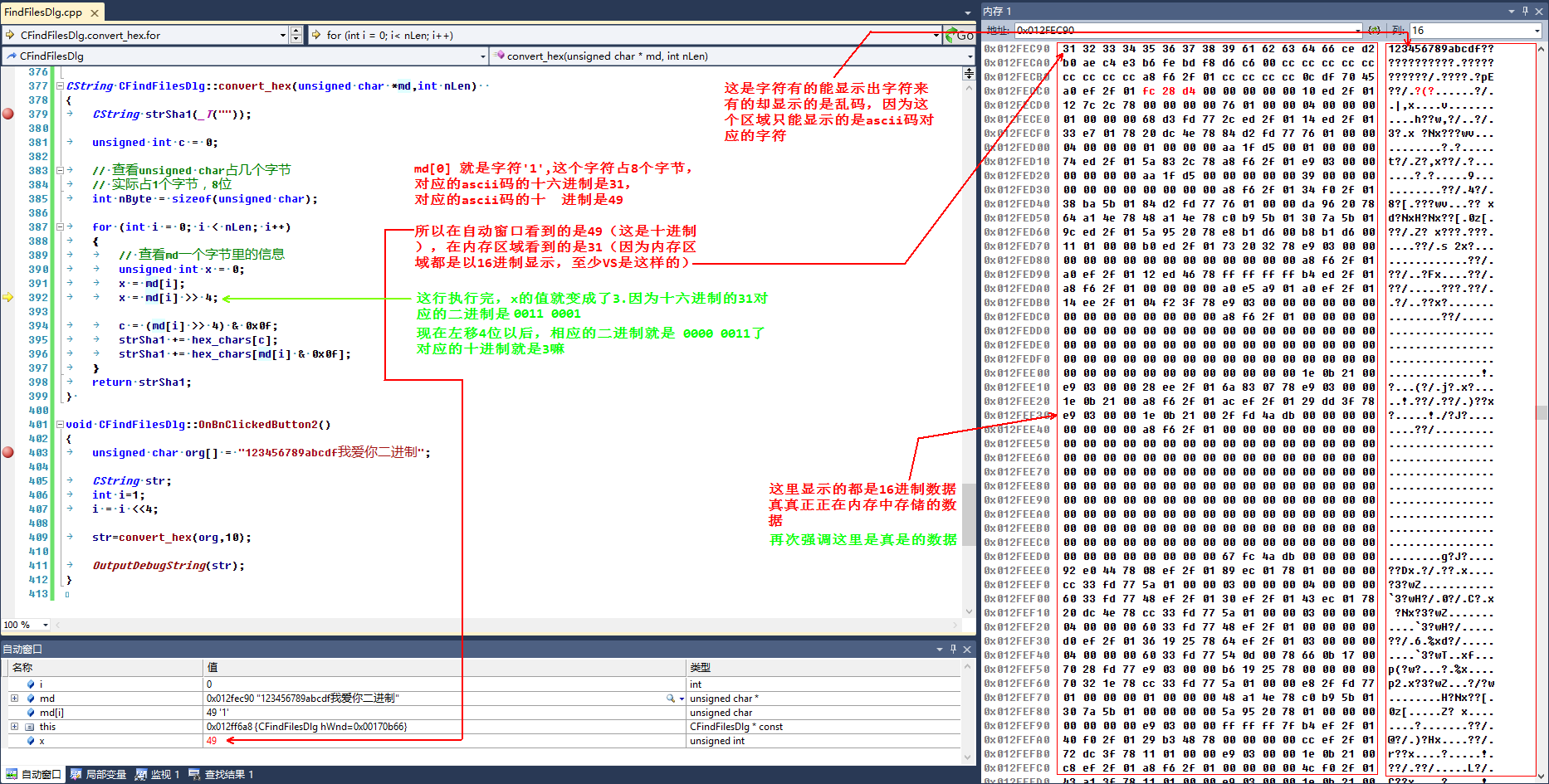
最终得到的结果如下
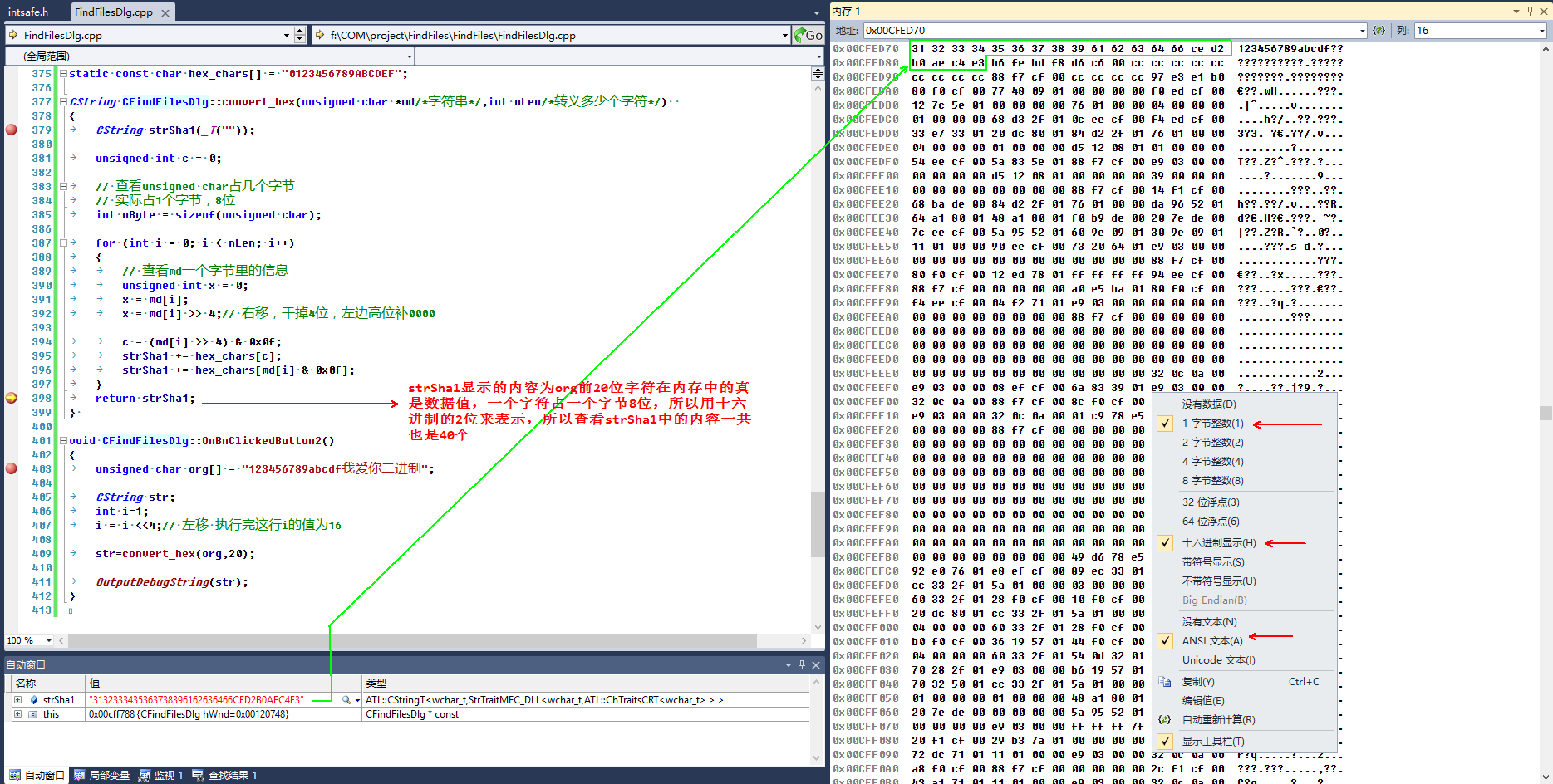
最终表明事实胜于雄辩















 4108
4108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









