






1. GTID 基于事务ID复制
master配置
修改配置文件
#vim /etc/my.cnf
[mysqld]
validate_password=off
log-bin
server-id=1
gtid_mode=ON
enforce_gtid_consistency=1
授权远程账户
mysql> grant replication slave,super,reload on *.* to slave@'%' identified by '123';
slave配置
修改配置文件
# vim /etc/my.cnf
[mysqld]
validate_password=off
log-bin
server-id=2
gtid_mode=ON
enforce_gtid_consistency=1
重启master和slave上的mysql
继续配置slave
# mysql -u root -p123
mysql > change master to master_host='master',master_user='slave',master_password='123',master_auto_position=1;
// master_host='master'中的master指的是master的ip,master_user='slave'的slave是master中创建的slave角色
mysql > start slave; //启动slave角色
mysql > show slave status\G //查看状态
测试
1.只要slave状态中i/o进程和sql进程为YES,基本可以确定成功
2.主服务器上写入数据,在从服务器上查看,如果能在从上看到数据,则成功!
2. 基于二进制日志binlog复制
- master和slave配置得开启binlog,server-id
修改配置文件
#vim /etc/my.cnf
[mysqld]
log-bin
server-id=1 #主从server-id不能相同
- master上创建slave用户,给slave权限
- slave配置master并开启slave
mysql > change master to master_host='master',master_user='slave',master_password='123456',master_log_file='mysql-bin.000210',master_log_pos=89133130;
// master_log_file为比对的主库中哪个二进制日志,master_log_pos为二进制日志的位置。
// master_log_pos在主数据库上使用show master status\G;查看
mysql > start slave; //启动slave角色
mysql > show slave status\G //查看状态
3.怎么给有数据的数据库做主从
场景1:在公司里面,数据库有数据的时候再做主从
场景2:公司数据库主从断了一段时间,主数据库的binlog日志设置了过期时间为三天,从库读不到主库的binlog了
在这两个场景中,从库必须得先同步主库的数据,再开启主从了
同步数据可以直接把主数据库的data目录拷贝到从数据库的data中
[root@36de6601af87 /]# rsync -av root@192.168.0.81:/usr/local/mysql/data/ /data/
拷贝完成之后会出现三个问题:
mysql > change master to master_host='master',master_user='slave',master_password='123456',master_log_file='mysql-bin.000210',master_log_pos=89133130;
// master_log_file为比对的主库中哪个二进制日志,master_log_pos为二进制日志的位置。
mysql > start slave; //启动slave角色
mysql > show slave status\G //查看状态
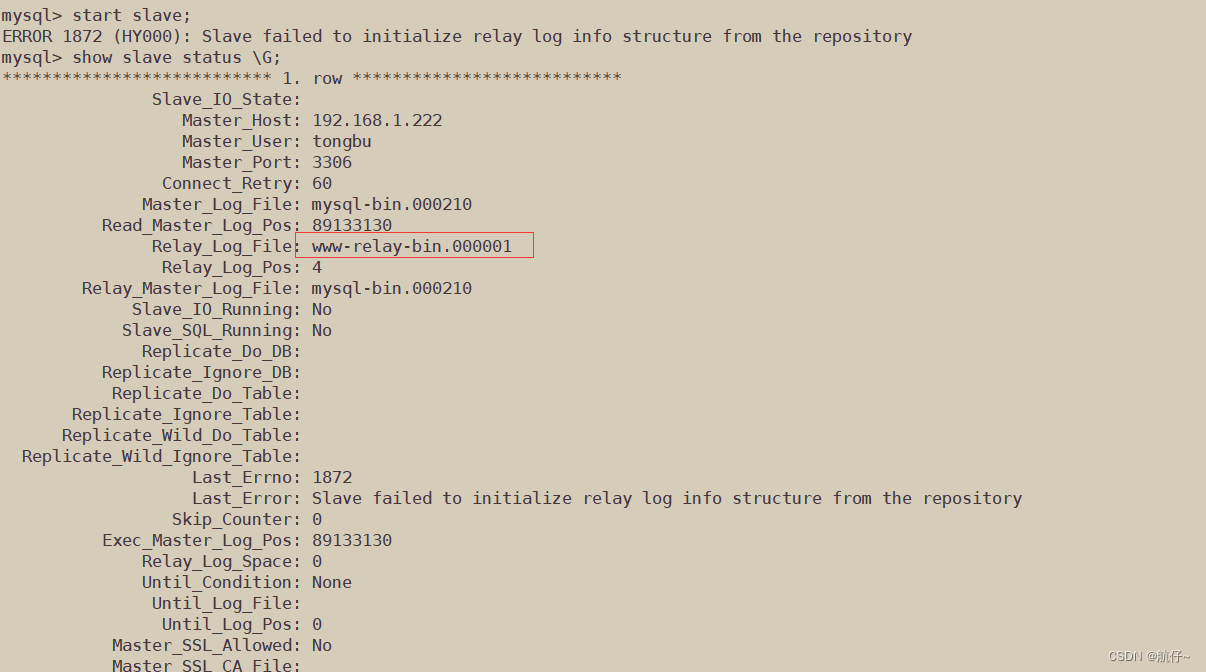
报错1:中继日志不匹配
因为我备份了从数据库的数据,可以看到它原来的结构里面是没有www-relay-bin.000001的,说明它使用了主数据库的中继日志,而在重启从服务器的时候,是会生成自己的中继日志的,所以要把主服务器拷过来的中继日志全部删除掉
- 中继日志错误按我的方法同步(rsync)是一定会报的,建议报一个错误处理一个错误,而不是知道中继日志会报错提前删除,这可能会导致服务启不来,我试过,反而有点弄巧成拙了。
我这边主库上的中继日志是www-relay-bin*,所以我删除的是www*
再重置slave并开启,已经没有这个错误了,出现了新的错误
报错2:uuid重复

参考本文下面问题1,解决
报错3:数据库两边不一致错误

出现这个错误的原因是,在主从同步的过程中,主数据库一直在写内容,每秒位置点可能更改几十条,导致位置点根本定位不准。而在我们数据差不多同步过去之后,先去忽略这个报错,参考问题3,之后主从同步完成,完成之后再去navicat同步两数据库,这是为了保障两数据库数据一样,防止主数据库对该数据更改从数据库没有改数据而报错导致主从同步断开。
问题1:mysql server uuid重复问题,因为克隆 导致记录uuid的文件内容没有发生任何变化
# 直接修改文件/var/lib/mysql/auto.cnf 内的uuid
使用命令 # uuidgen 生成全新uuid直接替换文件内的旧uuid即可
问题2:1236错误 : gtid不一致错误(很多错误都能归于它,即使没报1236错误)
报错形式:

Last_IO_ Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log:
'The slave is connecting using CHANGE NASTER TO MASTER_AUTO_POSITTON = 1, but the
master has purged binarylogs containing GTIDs that the slave requires.Replicate
the missing transactions from elsewhere,or provision a new slave from
backup.Consider increasing the master's binary log expiration period.
The GTID set sent by the slave is '',
and the missing transactions are '130fc529-a688-1lec-9793-000c2922001e:1-2'.'
解决方案:把主从的gtid同步
主库执行:查看master gtid_purged
mysql> show global variables like '%gtid%';
或
mysql> show master status\G;
找到gtid_purged的值
从库执行:更新gtid与主库一致
mysql> stop slave;
Query OK, 0 rows affected (0.18 sec)
#重置slave和master,既然gtid不同则肯定change master了,需要重置才能更改gtid否则会报gtid不为空
mysql> reset slave;
Query OK, 0 rows affected (1.29 sec)
mysql> reset master;
Query OK, 0 rows affected (1.18 sec)
# 重新设置gtid
mysql> set @@global.gtid_purged='主库的GITD值';
Query OK, 0 rows affected (2.12 sec)
#这步貌似可以不做
mysql> change master to master_host='主库ip',master_user='主库定义的slave名',master_password='主库定义的slave密码',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (5.55 sec)
mysql> start slave;
Query OK, 0 rows affected (0.40 sec)
# 查看状态,IO与SQL都为yes则成功
mysql> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Queueing master event to the relay log
Master_Host: xxx
Master_User: xxx
Master_Port: xxx
Connect_Retry: 60
Master_Log_File: mysql-bin.002188
Read_Master_Log_Pos: 4925243
Relay_Log_File: mysql-relay.000002
Relay_Log_Pos: 117539
Relay_Master_Log_File: mysql-bin.002188
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: xxx
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:xxx
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 117489
Relay_Log_Space: 4925493
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 73626
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: xxx
Master_UUID: xxx
Master_Info_File: /data02/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: System lock
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: xxx
Executed_Gtid_Set: GTID值
Auto_Position: 1
1 row in set (0.45 sec)
提前说明,问题3和问题4直接使用问题2的解决方案就可解决,解决完在看其中的原理就理解了。
问题2.5:1236错误:binlog不一致报错
报错形式:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'binlog truncated in the middle of event; consider out of diskspace on master; the first event 'mysql-bin.000129' at 100000, the last event read from './mysql-bin.000129' at 100000, the last byte read from './mysql-bin.000129' at 100019.'

同样的1236报错,但是与gtid的描述完全不同。它描述的字面意思是binlog日志严重损坏或者主数据库磁盘空间不足,我尝试了很多方法比如gpt说的修复binlog都没有用,我联想之前那个gtid同样的1236报错,于是我用了同样的手段处理,最后成功了
主库执行
mysql> show master status\G;
*************************** 1. row ***************************
File: mysql-bin.000129
Position: 2102378
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)
其中File为binlog日志名称,Position为位置点
从库执行
mysql> stop slave;
Query OK, 0 rows affected (0.18 sec)
#重置slave和master,既然gtid不同则肯定change master了,需要重置才能更改gtid否则会报gtid不为空
mysql> reset slave;
Query OK, 0 rows affected (1.29 sec)
mysql> reset master;
Query OK, 0 rows affected (1.18 sec)
#重新定义master master_log_file为binlog日志名称,master_log_pos为位置点
mysql> change master to master_host='主库ip',master_user='主库定义的slave名',master_password='主库定义的slave密码',master_log_file='mysql-bin.000129',master_log_pos=200019;
Query OK, 0 rows affected, 2 warnings (5.55 sec)
mysql> start slave;
Query OK, 0 rows affected (0.40 sec)
注:在企业中,每分钟binlog的位置点都可能改变上万次,我们只需填入最近的一次位置点,之后还有报错不是1236的参考问题3,在配置文件中加slave-skip-errors=all解决
还有一个说明就是:我们不用怕填入最近的一次位置点之后,之前的位置点的数据从库就都丢了。据我实测,之前的位置点有添加表的操作,而我更新为最近的位置点之后,添加的那些表也同步过来了。
问题3:mysql进行主从复制时,主库更改导致从库出错误,解决方案
报错形式:
Error 'Can't drop database 'db1'; database doesn't exist' on query. Default database: 'db1'. Query: 'drop database db1'
解决方案:
#解决方法1:
如果确定出错的事务可以忽略不处理,可以通过配置文件跳过该出错事务
vim /etc/my.cnf
[mysqld]
slave-skip-errors=1062,1146,2341 #跳过指定错误类型
#或者
slave-skip-errors=all #跳过所有错误
思考为啥会报错:主库删除了从库没有的库导致报错(在主从复制的时候修改主库的报错也是同理),而从库完全可以不要做此操作,我们可以修改配置文件跳过错误从而gtid跳到同一个节点,当然也可以直接修改gtid
修改完配置文件后记得重启数据库,当主从同步完成后,千万记得把slave-skip-errors=all给注释掉再重启
#解决方法2:
修改从库的gtid跟主库的一致,参考问题2
问题4:中继日志错误
报错形式:
mysql> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
解决方案:
解决方案1:中继日志错误,删除所有的日志即可启动,但删除日志之后就会报gtid不一致错误。再解决gtid。
解决方案2:直接同步gtid,因为gtid的tid代表的就是同步位置,位置同步就不会报这个错误。所以问题3同理,直接同步gtid也能解决问题。
问题5:server-id相同错误
报错形式:
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave
have equal MySQL server ids; these ids must be different for replication to work
(or the --replicate-same-server-id option must be used on slave but this does not
always make sense; please check the manual before using it).
解决方案:
这应该是最简单的bug了,一般主从使用了相同的id会报这个bug只需把/etc/my.cnf中的server-id修改为不同的值即可。
或者是在做互为主从的时候,主从搞混了(修改了/etc/hosts),让自己的机器做自己的机器的slave,当然会报这个bug。查看/etc/hosts文件,记住只能是其他机器为slave。
问题6:Slave_IO_Running: Connecting
这类问题一律是change master to(定于master节点)的时候数据输入问题,一段时间后应该会直接Slave_IO_Running: No,附带密码错误等提示就知道为啥错了
# 首先停掉slave,要不然后面得报错
mysql> stop slave;
Query OK, 0 rows affected (0.18 sec)
# 重置slave和master
mysql> reset slave;
Query OK, 0 rows affected (1.29 sec)
mysql> reset master;
Query OK, 0 rows affected (1.18 sec)
# 重新change to master节点信息
mysql> change master to master_host='主库ip',master_user='主库定义的slave名',master_password='主库定义的slave密码',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (5.55 sec)
# 启动slave
mysql> start slave;
#查看slave状态
mysql> show slave status\G;
修复数据库(初始化数据库,有重要数据记得先备份)
rm -rf /var/lib/mysql
systemctl restart mysqld
# 修复数据库密码什么的都会重置

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









