









基于urllib和re,爬取豆瓣电影新片榜
前言
此篇文章中介绍如何使用urllib库和re模块,爬取豆瓣电影新片榜。
正文
1、梳理需求
- 百度搜索-豆瓣电影-排行榜-豆瓣新片榜
- 提取数据为:电影名称、上映时间主演
2、静态数据抓取实现步骤
-
查看所抓取数据在响应内容中是否存在
右键->查看网页源码->搜索所抓数据关键字,确定抓取的内容是静态数据
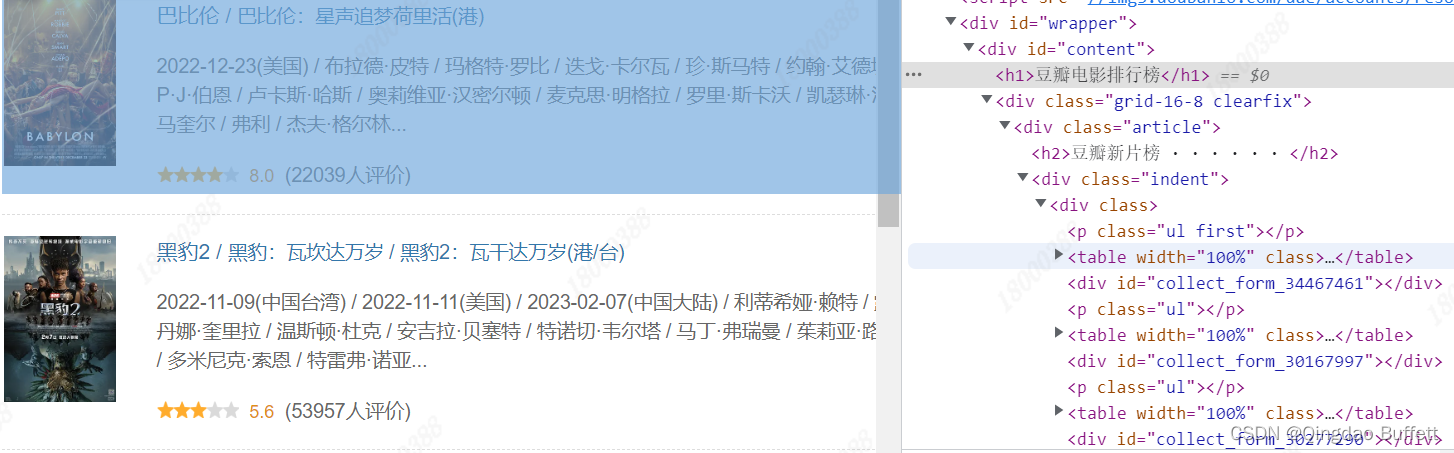
-
查找并分析url地址规律
https://movie.douban.com/chart,可以直接使用

-
编写正则表达式
<p class="ul.*?</p>.*?<tr class="item">.*?title="(.*?)">.*?<p class="pl">(.*?)</p>.*?</table>
如何编写请参考【Python学习笔记(四)】正则表达式re模块的使用,需要爬取的数据改写为(.*?) -
发请求获取响应内容
使用urllib.request 模块 -
解析响应内容,终端打印
3、根据静态数据抓取的步骤,定义爬虫类的结构
class XxxSpider:
def __init__(self):
”“” 定义爬虫常用变量 “”“
def get_html(self, url):
”“” 获取相应内容函数 “”“
def parse_html(self):
”“” 解析提取数据的函数 “”“
def handle_html(self, list):
”“” 数据处理函数 “”“
def run(self):
”“” 程序入口函数 “”“
4、具体代码的实现
class DoubanSpider:
"""
猫眼电影国内热榜前10名抓取
"""
def __init__(self):
self.url = 'https://movie.douban.com/chart' # 定义url地址
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'} # 重构请求头
self.times = 0 # 初始化爬取数据次数
def get_html(self, url):
"""
function: 获取相应内容函数
in: url:url地址
out: html:通过url地址获取的响应内容
return: None
others: Gets Corresponding Content Function
"""
req = request.Request(url=url, headers=self.headers) # 构造请求对象
res = request.urlopen(req) # 获取响应对象
html = res.read().decode() # 获取响应内容
self.parse_html(html) # 直接调用解析函数进行数据提取
def parse_html(self, html):
"""
function: 解析提取数据的函数
in: None
out: None
return: int >0 ok, <0 some wrong
others: None
"""
regex = '<p class="ul.*?</p>.*?<tr class="item">.*?title="(.*?)">.*?<p class="pl">(.*?)</p>.*?</table>' # 定义正则表达式
pattern = re.compile(regex, re.S) # 创建正则表达式的编译对象
r_list = pattern.findall(html) # 使用re.findall()方法
self.handle_html(r_list) # 直接调用数据处理函数
def handle_html(self, list):
"""
function: 数据处理函数
in: list
out: None
return: terminal print
others: Data Handle Function
"""
dic = {} # 初始化字典
for r in list:
dic["name"] = r[0].strip() # 字典name赋值,去空格
dic["time&star"] = r[1].strip() # 字典time&star赋值,去空格
self.times += 1 # 每执行一次 +1
print(dic) # 终端打印字典
print("数据爬取成功,共爬取{}条数据".format(self.times)) # 终端打印提示信息
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Entry Function
"""
url = self.url # url地址
self.get_html(url) # 调用get_html()方法
if __name__ == '__main__':
spider = DoubanSpider() # 爬虫类实例化
spider.run() # 执行入口函数
5、代码的实现效果

















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











