






筛素数
如何求出从 1 ∼ n 1 \sim n 1∼n 中素数的个数
方法
1
1
1 暴力枚举 ------
O
(
n
2
)
O(n^2)
O(n2)
从
1
∼
n
1 \sim n
1∼n 遍历一遍,每一个数都去判断一下,这个数是否是素数,如果是
a
n
s
=
a
n
s
+
1
ans = ans +1
ans=ans+1 。时间复杂度
O
(
n
∗
n
1
/
2
)
O(n*n^{1/2})
O(n∗n1/2) 。
void get_primes(int n)
{
int ans = 0;
for (int i = 2; i <= n; i ++)
{
int f = 0;
//判断是否是质数
for (int j = 2; j <= i / j; j++)
{
if(i % j == 0)
{
f = 1;
break;
}
}
if(f == 0)ans++;//是质数的话ans++
}
printf("%d\n",ans);
}
很明显 O ( n 2 ) O(n^2) O(n2) 级别的复杂度,在一般的算法题中,只要 n n n 超过 1 e 5 1e5 1e5 基本上就要超时了,而且暴力枚举也不符合我们所谓筛素数的标题,那么怎么样才能叫做筛素数呢?
方法 2 2 2 朴素筛法 ------ O ( n ∗ l o g ( n ) ) O(n*log(n)) O(n∗log(n))
- 既然是筛法,那到底如何来筛呢?筛什么呢?
显然,我们要筛的是素数,也就是在 2 ∼ n 2 \sim n 2∼n 这么一个数表中,把合数全部去掉,那么留下来的或者说是我们筛出来的也就是我们要的素数了。
举个例子 当 n = 25 n = 25 n=25 时,我们先把从 1 1 1 ~ 25 25 25写在一个数表中
| 次数/数字 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 第零次 | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — | — |
| 第一次:筛 2 的倍数 | Y | — | N | — | N | — | N | — | N | — | N | — | N | — | N | — | N | — | N | — | N | — | N | — |
| 第二次:筛 3 的倍数 | Y | Y | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | — |
| 第三次:筛 4 的倍数 | Y | Y | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | — |
| 第四次:筛 5 的倍数 | Y | Y | N | Y | N | — | N | N | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | N |
| 第五次:筛 6 的倍数 | Y | Y | N | Y | N | — | N | N | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | N |
| 第六次:筛 7 的倍数 | Y | Y | N | Y | N | Y | N | N | N | — | N | — | N | N | N | — | N | — | N | N | N | — | N | N |
我们可以发现:
第一次筛的时候,把 1 1 1 ~ n n n 中 2 2 2 的倍数全部筛去
第二次筛的时候,把 1 1 1 ~ n n n 中 3 3 3 的倍数全部筛去
第三次筛的时候,把 1 1 1 ~ n n n 中 4 4 4 的倍数全部筛去
第四次筛的时候,把 1 1 1 ~ n n n 中 5 5 5 的倍数全部筛去
⋅ \cdot ⋅
⋅ \cdot ⋅
⋅ \cdot ⋅
第二十四次筛的时候,把 1 1 1 ~ n n n 中 25 25 25 的倍数全部筛去
我们可以发现,当轮到某个数 k k k 开始筛它的倍数的时候,同时 k k k 没有被前面的数筛掉,那么 k k k 就是一个质数,因为在 2 2 2 ~ k − 1 k - 1 k−1 中没有 k k k 的因子。
下图形象的体现我们筛质数的思想
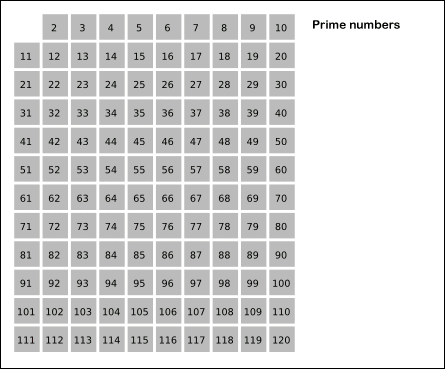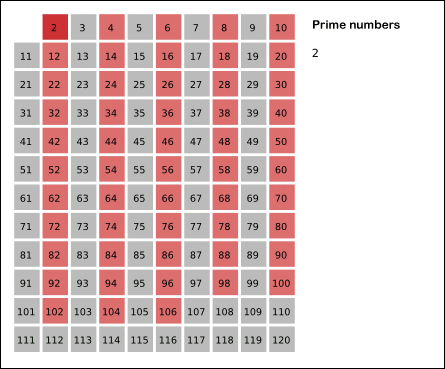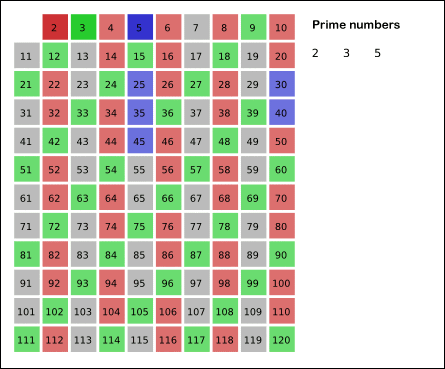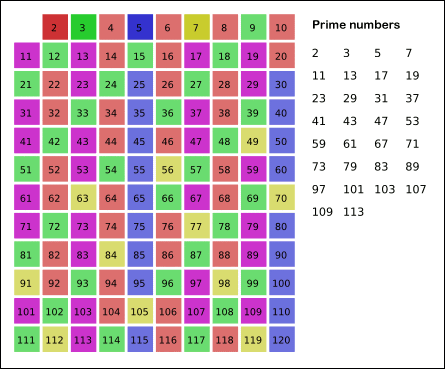
(动图出处: https://www.cnblogs.com/findwg/p/4901219.html)
接下来请看普通筛法的代码。
const int N = 1e6+10;
int primes[N];//用来存放素数
bool st[N];//用来判断某个数是否是素数 false 表示是质数 true 表示不是质数
void get_primes(int n)
{
int cnt = 0;//统计质数的个数
st[1] = true;//1 不是 质数
for (int i = 2; i <= n; i ++)
{
if(!st[i])primes[cnt++] = i;//如果轮到这个数开始筛了,并且这个数还没有被筛掉,那么这个数就是质数,把它放到primes里去
for (int j = i + i; j <= n; j += i)st[j] = true;//遍历一遍 i 的倍数,把它们都筛掉
}
int ans = 0;
for (int i = 1; i <= n; i ++)//遍历一遍 1 ~ n 如果是素数,ans++
ans += !st[i];
printf("%d\n", ans);
}
我们可以简单的来算一下按照朴素筛法来筛素数的一个时间复杂度。对于 n n n 来说,第一次筛 n 2 \frac{n}{2} 2n 个数,第二次筛 n 3 \frac{n}{3} 3n 个数 ··· 第 n n n 次筛 n n − 1 \frac{n}{n - 1} n−1n 个数。
那么总的时间是 n 2 + n 3 + ⋅ ⋅ ⋅ + n n − 1 \frac{n}{2} + \frac{n}{3} + \cdot\cdot\cdot + \frac{n}{n-1} 2n+3n+⋅⋅⋅+n−1n ,这就等于 n ∗ ( 1 2 + 1 3 + ⋅ ⋅ ⋅ + 1 n − 1 ) n * (\frac{1}{2} + \frac{1}{3} + \cdot\cdot\cdot + \frac{1}{n-1} ) n∗(21+31+⋅⋅⋅+n−11) ,那么这就是一个调和级数。当 lim n → ∞ \lim\limits_{n\rightarrow\infty} n→∞lim时 调和级数的值大概为 l n ( n ) + c ( 欧 拉 常 数 , c ≈ 0.577 ) ln(n) + c (欧拉常数,c \approx 0.577) ln(n)+c(欧拉常数,c≈0.577) (可直接拿来用的,详细证明可以看百度百科) 。
那么普通筛法的时间复杂度大概为 O ( n ∗ l n ( n ) ) O(n*ln(n)) O(n∗ln(n)) , l n ( n ) < l o g 2 ( n ) ln(n) < log_2(n) ln(n)<log2(n) ,所以 n = 1 e 9 n = 1e9 n=1e9 的时候 l n ( n ) ≈ 32 ln(n) \approx 32 ln(n)≈32,比起我们第一种筛法的 n ≈ 4 e 4 ∼ 5 e 4 \sqrt{n} \approx 4e4 \sim 5e4 n≈4e4∼5e4 要快得多。
方法 3 3 3 埃氏筛 ------ O ( n ∗ l o g ( l o g ( n ) ) ) O(n*log(log(n))) O(n∗log(log(n)))
埃拉托斯特尼筛法,简称埃氏筛。
埃氏筛的核心思想就是筛去 1 ∼ n 1 \sim n 1∼n 中所有质数的倍数。
埃氏筛与朴素筛法相比较,就是加了一个限制条件,我们在筛的时候,只需要筛所有素数的倍数即可。
举个简单的例子,轮到 2 2 2 筛的时候,它会把后面所有因子中 2 2 2 的数全部筛完,它会把 4 , 6 , 8 , 10 , 12 ⋅ ⋅ ⋅ n 4 ,6 ,8 ,10,12\cdot\cdot\cdot n 4,6,8,10,12⋅⋅⋅n全部筛掉,而当轮到 4 4 4 筛的时候,它又会筛到 8 , 12 8 ,12 8,12 。 很明显这一部分是重复计算的,所以埃氏筛的核心思想,就是去掉这重复筛的部分,只需要从所有的质数开始筛即可。
而之前说了,如果轮到当前这个数开始筛,并且当前这个数还没被筛过,那这个数就是个质数。
接下来这个是埃氏筛的代码
const int N = 1e6+10;
int primes[N];
bool st[N];
void get_primes(int n)
{
int cnt = 0;
st[1] = true;
for (int i = 2; i <= n; i ++)
{
if(!st[i])
{
primes[cnt++] = i;
for (int j = i + i; j <= n; j += i)st[j] = true;
//唯一改动的地方,把for循环筛合数,放到了if条件中,如果 i 是素数,才去往后筛合数
}
}
}
然后我们再来看一下埃氏筛的时间复杂度。
我们从需要算
(
1
2
+
1
3
+
⋅
⋅
⋅
+
1
n
−
1
)
(\frac{1}{2} + \frac{1}{3} + \cdot\cdot\cdot + \frac{1}{n-1} )
(21+31+⋅⋅⋅+n−11) 这个调和级数减少到了,只需要算这之中所有质数的调和级数即可。
根据质数定理可知
1
∼
n
1 \sim n
1∼n 之中大概有
n
l
n
(
n
)
\frac{n}{ln(n)}
ln(n)n 个质数
所以本来我们需要算 n n n 个数的调和级数,现在只需要算 n l n ( n ) \frac{n}{ln(n)} ln(n)n 个数的调和级数,所以时间复杂度大概在 O ( n ∗ l n ( n ) / l n ( n ) ) O(n*ln(n) / ln(n)) O(n∗ln(n)/ln(n)) 。但是这不等于它是一个 O ( n ) O(n) O(n) 的算法,因为其中的复杂度不能这样简单的计算,而埃氏筛的时间复杂度大概是 O ( n ∗ l o g ( l o g ( n ) ) ) O(n*log(log(n))) O(n∗log(log(n))) 级别,举个例子,当 n = 2 32 n = 2^{32} n=232时, l o g ( l o g ( n ) ) ) = 5 log(log(n))) = 5 log(log(n)))=5 。
ps:关于质数基本定理,这是某数学家证明的定理,具体步骤极其复杂,详细证明请百度百科
方法 4 4 4 线性筛 (欧拉筛) ------ O ( n ) O(n) O(n)
接下来我们要讲的一个筛法叫做线性筛,或者也叫欧拉筛。
根据上面的归纳,其实我们不难发现,为什么埃氏筛它不能算是线性的或者说是
O
(
n
)
O(n)
O(n) 的复杂度。
因为很明显,即使是你只筛去所有质数的倍数,那也会有很多数被你重复筛掉,比如 6 6 6 同时被 2 2 2 和 3 3 3 筛了两次, 10 10 10 同时被 2 2 2 和 5 5 5 筛了两次, 30 30 30 同时被 2 , 3 , 5 2 ,3,5 2,3,5 筛了三次,所以你仍旧有合数被筛去不止一次。
那么我们是否有办法让每个合数只被筛去一次呢?如果可以的话,那这样的筛法就是完全的线性了。当然,这是存在的。
根据唯一分解定理(传送门)可知,一个数可以被唯一地分解为若干个质数的乘积。
那么我们规定,每次在筛一个合数的时候,只用它最小的素因子去筛掉它,这样就能保证了,每个数只被筛一次。
思路就是这么简单,那么我们看看代码怎么去写。
const int N = 1e6+10;
int primes[N];
bool st[N];
void get_primes(int n)
{
int cnt = 0;
st[1] = true;
for (int i = 2; i <= n; i ++)
{
//------>
if(!st[i])primes[cnt++] = i;
for (int j = 0; primes[j] <= n / i; j ++)
{
st[primes[j] * i] = true;
if(i % primes[j] == 0)break;
}
//<------
}
}
我们可以看到其实改动的地方就只有箭头里面的内容,那么我们现在来分析,为什么这样就可以让每个合数都被它最小的质因子筛掉呢?
首先,我们知道
p
r
i
m
e
s
[
j
]
primes[j]
primes[j] (之后简称
p
j
p_j
pj)表示的是所有质数的一个集合。
我们分两种情况来考虑
1. i % p j = 0 i \% p_j = 0 i%pj=0 因为 j j j 是从 0 0 0 开始枚举,也就是说 p j p_j pj 一定是 i i i 的最小的质因子,又因为 p j p_j pj 本身是一个质数,或者说 p j p_j pj 一定也是 p j p_j pj 的最小的质因子,那么 p j p_j pj 一定是 p j ∗ i p_j * i pj∗i 的最小质因子。(此时我们就用 p j p_j pj 把 p j ∗ i p_j * i pj∗i 筛掉了)
2. i % p j ≠ 0 i \% p_j \not= 0 i%pj=0 同样因为 j j j 是从 0 0 0 开始枚举,又因为 i % p j ≠ 0 i \% p_j \not= 0 i%pj=0 ,也就是说 p j p_j pj 一定比 i i i 的最小的质因子还要小,而 p j p_j pj 本身是一个质数,那么 p j p_j pj 也一定是 p j ∗ i p_j * i pj∗i 的最小质因子。(此时我们也实现了用 p j ∗ i p_j * i pj∗i 的最小质因子 p j p_j pj ,把 p j ∗ i p_j * i pj∗i 筛掉了)
注意:我们每次筛的都是 p r i m e s [ j ] ∗ i primes[j] * i primes[j]∗i 这个数。
这就是欧拉筛的核心思想,可能会有点绕,这两种情况需要大家多读几遍,多体会一下。
接下来,我们再来分析 i f ( i % p r i m e s [ j ] = = 0 ) b r e a k ; if\ (i\ \%\ primes[j] == 0)break; if (i % primes[j]==0)break;
很显然,因为我们希望用合数的最小质因子去筛所有的合数,为了确保 p j p_j pj始终是 p j ∗ i p_j * i pj∗i 的最小质因子,当 i % p j = 0 i \% p_j = 0 i%pj=0 时,我们就不希望再去筛 i ∗ p j + 1 i * p_{ j + 1 } i∗pj+1,因为这样 i ∗ p j + 1 i * p_{ j + 1 } i∗pj+1 的最小质因子就一定不是 p j + 1 p_{ j + 1 } pj+1 ,很显然 p j p_j pj 是 i i i 的质因子,而 p j + 1 > p j p_{ j +1 } > p_j pj+1>pj,所以这样就会使得一个合数被反复筛去,而并没有达到我们所说的:每个合数只被它的最小质因子筛去。
然后我们再来分析这个 f o r for for循环 f o r ( i n t j = 0 ; p r i m e s [ j ] < = n / i ; j + + ) for\ (int \ \ \ j = 0;\ primes[j] <= n\ /\ i;\ j++) for (int j=0; primes[j]<=n / i; j++)
f o r for for循环从 0 0 0开始枚举 p r i m e s primes primes 数组中现有的所有的质数,因为我们是要筛的质数是 p j ∗ i p_j * i pj∗i 所以 p j ∗ i ≤ n p_j * i \le n pj∗i≤n,同样为了避免 p j ∗ i p_j * i pj∗i 溢出,所以我们写成 p r i m e s [ j ] < = n / i primes[j] <= n\ /\ i primes[j]<=n / i 。
这里有的同学说 从 0 0 0开始枚举 p r i m e s primes primes 数组中现有的所有的质数,需不需要加限制条件 j < c n t j<cnt j<cnt 。
答案是: j < c n t j < cnt j<cnt 没必要,因为你会发现 p r i m e s [ c n t − 1 ] = primes[cnt - 1] = primes[cnt−1]= 当前最大质数
如果 i i i 不是质数,根据唯一分解定理, i i i 可以被唯一地分解为若干个质数的乘积,那么当枚举 p j p_j pj 为 i i i 的最小质因数时,就会被 b r e a k break break 掉。
如果 i i i 是质数,那么 p r i m e s [ c n t − 1 ] = i primes[cnt - 1] = i primes[cnt−1]=i,当 j j j 枚举到 c n t − 1 cnt - 1 cnt−1时,循环也会跳出。
我们可以来看一下这个程序大致是怎样运行的


我们可以看到所有的合数,的的确确只被筛过一次。
最后我们再来简单地分析一下欧拉筛的时间复杂度,虽然看着是两层循环,但实际上,我们对于每个数只会通过它最小的质因子将它筛去,所以本质上只是将每个数都跑了一遍,所以它的时间复杂度就是 O ( n ) O(n) O(n) 。我们可以拿欧拉筛与埃氏筛进行比较一下,当 n = 1 e 9 n=1e9 n=1e9 时,欧拉筛大概比埃氏筛快 5 5 5 倍,当 n = 1 e 7 n=1e7 n=1e7时,欧拉筛大概比埃氏筛快 2 ∼ 3 2 \sim 3 2∼3 倍。
最后,欧拉筛基本上算是数论中最简单的算法,希望同学们能够继续加油,我也继续加油(doge)。















 3427
3427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









