







全文在用户账号(ubuntu)下操作,有些命令行需要加 sudo,如果是在 root 身份下运行,忽略 sudo
环境准备
一共有三台Linux服务器,将搭建1个master,2个slave的集群。
配置hosts
在每一台主机的hosts中添加内网地址和命名
使用ifconfig查看内网地址(slave1为例)

sudo vi /etc/hosts
# 添加
10.8.4.7 master
10.8.4.48 slave1
10.8.4.3 slave2
注释掉
#127.0.0.1 localhost.localdomain VM-4-7-ubuntu
#127.0.0.1 localhost
配置之后ping一下用户名看是否生效
ping master
ping slave1
ping slave2
同时将各服务器的hostname也修改成对应的用户名
sudo vi /etc/hostname
#修改成
master
SSH免密登陆
使三台机器之间相互访问的时候可以免密
安装Openssh server
sudo apt-get install openssh-server
在所有机器上都生成私钥和公钥
ssh-keygen -t rsa #一路回车
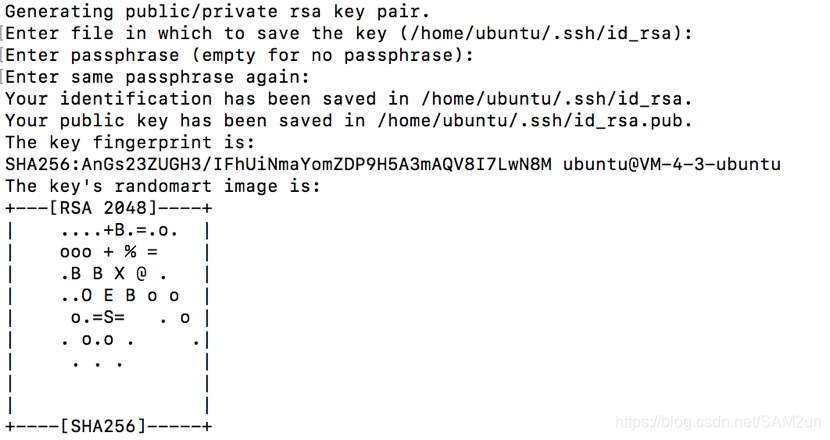
每个机子上的id_rsa.pub(公钥)发给master节点,用scp来传输公钥。
# 在slave1上
scp ~/.ssh/id_rsa.pub spark@master:~/.ssh/id_rsa.pub.slave1
# 在slave2上
scp ~/.ssh/id_rsa.pub ubuntu@master:~/.ssh/id_rsa.pub.slave2
如果出现如下错误:Permission denied, please try again
sudo vi /etc/ssh/sshd_config
# 是否包含类似如下配置:
PermitRootLogin no
# 或者
PermitRootLogin prohibit-password
# 修改为
PermitRootLogin yes
重启sshd服务
service sshd restart
或者是因为权限的原因,可以修改权限或者传到别的文件中

# 修改权限
chmod 777 ~/.ssh/id_rsa.pub
或者新建temp 文件夹
mkdir ~/temp

这样就把id_rsa.pub文件传到temp中再复制到.ssh中
scp ~/.ssh/id_rsa.pub ubuntu@master:~/temp/id_rsa.pub.slave1
cp ~/temp/id_rsa.pub.slave1 ~/.ssh/
在master上,将所有公钥加到authorized_keys(用于认证的公钥)中
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
用scp将authorized_keys发给每台slave
scp ~/.ssh/authorized_keys spark@slave1:~/.ssh/
scp ~/.ssh/authorized_keys spark@slave2:~/.ssh/
在每台机器上验证SSH免密
ssh master
ssh slave1
ssh slave2
安装JAVA
使用java -version查看java版本,如果没有就按照提示安装
- 以下为安装默认版本
sudo apt-get update
sudo apt-get install default-jre
sudo apt-get install default-jdk
sudo update-alternatives --config java
修改环境变量 /etc/profile,注意将home路径替换成你的
sudo vi /etc/profile
#添加
export WORK_SPACE=/home/spark/workspace/
export JAVA_HOME=$WORK_SPACE/jdk1.7.0_75
export JRE_HOME=/home/spark/work/jdk1.7.0_75/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
查看是否生效
$ source /etc/profile #生效环境变量
$ java -version
如果打印出如下版本信息,则说明安装成功

- 如果想安装特定版本,按照以下步骤
安装 Scala
使用scala -version查看scala版本,如果没有就按照提示安装
- 以下为安装默认版本
sudo apt-get install scala
查看是否生效

- 如果想安装特定版本,按照以下步骤
下载scala压缩包,官网下载地址
解压
$ sudo mkdir /usr/local/scala
$ sudo tar zxvf scala-2.11.6.tgz -C /usr/local/scala
再次修改环境变量sudo vi /etc/profile,添加以下内容:
export SCALA_HOME=/usr/local/scala-2.11.6
export PATH=$PATH:$SCALA_HOME/bin
查看是否生效
$ source /etc/profile #生效环境变量
$ scala -version
如果打印出如下版本信息,则说明安装成功
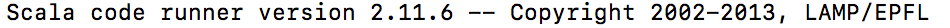
安装配置 Hadoop
只用在master上安装配置好hadoop后,再分发给其他机器,也可以选择在各个机器上都安装配置好。
下载解压
从官网下载 hadoop2.9.2 版本,下载地址
选择下载最新的稳定版本,即下载 “stable” 下的 hadoop-2.x.y.tar.gz ,这是编译好的,其他包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
同样在/usr/local/中解压
sudo tar -zxf hadoop-2.9.2.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.9.2/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
配置 Hadoop
cd /usr/local/hadoop/etc/hadoop进入hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml
- 在slaves中配置节点的ip或者host
$ vi slaves # 添加如下内容
master
slave1
slave2
- 修改core-site.xml
$ mkdir /usr/local/hadoop/tmp # 创建tmp文件夹
$ vi core-site.xml # 添加如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
- 修改hdfs-site.xml
$ mkdir /usr/local/hadoop/dfs # 创建dfs文件夹
$ mkdir /usr/local/hadoop/dfs/name
$ mkdir /usr/local/hadoop/dfs/data
$ vi hdfs-site.xml # 添加如下内容
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
- 修改mapred-site.xml
$ vi mapred-site.xml # 添加如下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改yarn-site.xml
$ vi yarn-site.xml # 添加如下内容
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
- 将配置好的hadoop文件夹分发给slave1和slave2
scp -r /usr/local/hadoop ubuntu@slave1:/usr/local/
scp -r /usr/local/hadoop ubuntu@slave2:/usr/local/
安装完毕
启动 Hadoop
在master上启动hadoop
cd /usr/local/hadoop #进入hadoop目录
bin/hadoop namenode -format #格式化namenode
sbin/start-dfs.sh #启动dfs
sbin/start-yarn.sh #启动yarn
可以在sbin中查看脚本文件

格式化文件时要注意的问题
java.io.IOException: Cannot remove current directory: /usr/local/hadoop/dfs/name/current at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:350)
不要随便格式化,重新格式化HDFS的时候
dfs.name.dir、dfs.data.dir、hadoop.tmp.dir所指定的目录删除
也就是将/usr/local/hadoop/dfs和tmp中的文件删除,或者修改权限
chown –R hadoop:hadoop /usr/local/hadoop/tmp
sudo chmod -R a+w /usr/local/hadoop
验证 Hadoop 是否安装成功
通过jps命令查看各个节点是否正常启动进程
$ jps # master
14914 NameNode
5061 Jps
15469 ResourceManager
15293 SecondaryNameNode
$ jps # slave
14914 NameNode
5061 Jps
15469 ResourceManager
15293 SecondaryNameNode
浏览器访问 http://master:8088(本http://62.234.202.151:8088)
为了避免黑客的攻击,可以在yarn-site.xml 文件修改默认的端口
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:1408</value>
</property>
访问http://master:1408
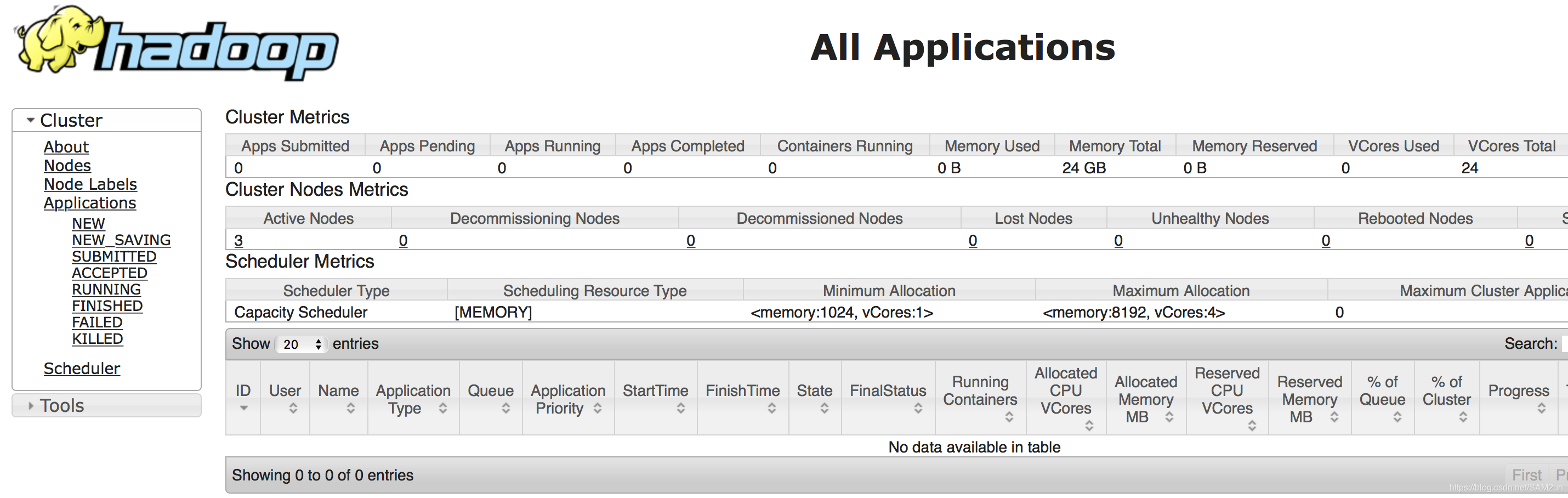
可以看到Aclive Nodes有三个














 2094
2094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









