






验证码常规破解有:
1.灰度及二值化:
def convert_img(img,threshold):
img = img.convert("L") # 处理灰度
pixels = img.load()
for x in range(img.width):
for y in range(img.height):##二值化
if pixels[x, y] > threshold:
pixels[x, y] = 255
else:
pixels[x, y] = 0
return img
2.去除孤立的噪点:
原理是找出某点的周围的八个点,设这八个点中是黑点的总数是m。若m小于一个阈值(如4个),则认为该点是孤立的点,应该移除。
def neighbor8filter(img, p):
pixels = img.load()
w, h = img.size
# remove edges
for x in range(w):
pixels[x, 0] = 255
pixels[x, h - 1] = 255
for y in range(h):
pixels[0, y] = 255
pixels[w - 1, y] = 255
for y in range(1, h - 1):
for x in range(1, w - 1):
if not pixels[x, y]:
count = 0
for m in range(x - 1, x + 2):
for n in range(y - 1, y + 2):
if not pixels[m, n]:
count = count + 1
if count <= p:
pixels[x, y] = 255
return img
3.去除较细的干扰线:
FLOODFILL(洪水填充 )算法
该原理是从一个点开始,找到与其相邻的所有像素点,标记为一个区域。找出所有这样的区域,然后把区域较小的当作干扰线除掉。
4.用pytesseract库直接识别:
pytesseract.image_to_string(img)
但是像下面带有很粗干扰线的验证码该如何破解
 图一 图一
|
 图二 图二
|
刚开始的时候,自己想到的方法是用tensor flow强行去学习出一个模型来判断,但是效果并不好。
原因有两个:
1是干扰太大,干扰曲线的位置随机,比如一个字母为F,若干扰线刚好从F的下方穿过,则很容易判断为E。
2是样本量不够,大概有只有3300个。
那么解决的办法也是从这两个原因入手,先考虑样本。样本是我从某滴上爬取下载下来的,然后拿去第三方付费的打码平台识别出具体的标签来。为了这3000多个标签,我花了20元了。为了止损,不考虑继续增加样本量。
那么只能考虑把干扰线去除。但是这类干扰线竟不是孤立的点,也不是很细的的干扰线,所有之前说的方法都不能用,那只能想其他办法了。发现所谓的八领域去孤点法或者洪水填充法,其实都是找到了干扰的一些规律,然后根据这些规律把他们去掉。只是这种规律比较常见,后来我们给他们起一个牛逼一点的名字罢了。
仔细观察发现,干扰线是一条很长的连贯的曲线。如果有程序能识别出这条连贯的曲线,不就可以把他给去掉了吗。首先,容易找出干扰曲线两端开始的点。如果能够顺着这两端的点往下找连贯的线行不行能不能找到这条完整的线呢?发现当干扰线跟字母交叉的时候,可能会把字母判断为干扰线从而顺着字母走,判断会失败。再看看这条线的特征,如果从干扰线两端出发,顺着斜率最小的方向移动,不就可以找到这条完整的干扰线了吗?
在具体实现中发现,这条曲线不是由点组成的,而是一条条很细的竖线组成的。比如在x轴为50的线上,该细线可能是由(50,20),(50,21)(50,22),(50,23)这四个点组成的竖线。真正的斜率找连贯线的方法还是有一定困难的。只能边做边探索
1.先进行灰度二值化处理:
import numpy as np
from PIL import Image
IMAGE_HEIGHT = 94##图片高度
IMAGE_WIDTH = 398##图片宽度
MAX_Y_COUNT=6###一条干扰竖线最多由6个点组成
threshold=150##灰度值分界值
def get_raw_arr(path):###灰度、二值化,返回ndarray
img=Image.open(path)
img = img.convert("L")
img_arr=np.array(img)
img_arr_tmp=np.zeros((IMAGE_HEIGHT, IMAGE_WIDTH,3))
for x in range(IMAGE_HEIGHT):
for y in range(IMAGE_WIDTH):
if (img_arr[x,y]>threshold):
img_arr_tmp[x,y]=np.array((255,255,255))
else:
img_arr_tmp[x,y]=np.array((0,0,0))
img_arr_tmp=img_arr_tmp.astype('uint8')
return img_arr_tmp
img_arr_raw=get_raw_arr(path)
Image.fromarray(img_arr_raw)
结果几乎没什么变化:
 图一 图一
|
 图二 图二
|
2.首次干扰线的去除:

如上图所示的,用红直线平行y轴移动,与干扰线会相交。其中有一部分相交有明显的特征:1.在某一个x坐标下,该相交的竖线只有一条连贯的直线。
2.该连贯的直线不会太粗,根据实际情况,定位最大由6个点组成。
#工具函数,返回数组,每个数组的元素是连续坐标组成的数组
#如输入 [1,2,3,6,7,8,12] 返回[[1,2,3],[6,7,8],[12]]
def get_group(tmp):
tmp=sorted(tmp)
ret=[]
tmp_list=list([tmp[0]])
last_small=tmp[0]
for i in tmp[1:]:
if i-last_small!=1:
ret.append(tmp_list)
tmp_list=list()
tmp_list.append(i)
else:
tmp_list.append(i)
last_small=i
ret.append(tmp_list)
return ret
def get_np_from_dict_list(dict_list):
img_arr=np.ones((IMAGE_HEIGHT, IMAGE_WIDTH,3))*255
for k,v in dict_list.items():
for i in v:
img_arr[i,k]=np.array((0,0,0))##
return img_arr.astype('uint8')
## dict_list1-dict_list2
def minus_dict_list(dict_list1,dict_list2):
dict_list1_copy=dict_list1.copy()
for k in dict_list2.keys():
if dict_list1_copy[k]==dict_list2[k]:
dict_list1_copy.pop(k)
else:
s1=set(dict_list1_copy[k])
s2=set(dict_list2[k])
if s2.issubset(s1):
dict_list1_copy[k]=list(s1-s2)
else:
raise RuntimeError('XXXXX')
return dict_list1_copy
#获取所有黑色点的坐标及相关数据变形结构
def get_hit(img_arr_tmp):
hit=[]###黑色坐标的点组成的数组
for x in range(IMAGE_WIDTH):
for y in range(IMAGE_HEIGHT):
if (img_arr_tmp[y,x]==np.array((0,0,0))).all():
hit.append([y,x])
hit_dict_list={}# 获取每个x轴坐标对应的y轴坐标
for i in hit:
key=i[1]
if key in hit_dict_list.keys():
hit_dict_list[key].append(i[0])
else:
hit_dict_list[key]=[i[0]]
hit_dict_group_count={}# 获取每个x轴坐标对应的组数
for i,j in hit_dict_list.items():
group=get_group(j)
hit_dict_group_count[i]=len(group)
return hit,hit_dict_list,hit_dict_group_count
#根据规律1获取干扰线的坐标
def get_interferA(hit,hit_dict_list,hit_dict_group_count):
interferA={}####y轴上有颜色的点少于MAX_Y_COUNT的线 且只有一组的点 的x坐标
for i in hit:
if (len(hit_dict_list[i[1]])<MAX_Y_COUNT)&(hit_dict_group_count[i[1]]==1):
key=i[1]
if key in interferA.keys():
interferA[key].append(i[0])
else:
interferA[key]=[i[0]]
return interferA
hit,hit_dict_list,hit_dict_group_count=get_hit(img_arr_raw)
interferA=get_interferA(hit,hit_dict_list,hit_dict_group_count)#获取干扰线坐标
hit_remove_interferA=minus_dict_list(hit_dict_list,interferA)#除去干扰线A后的坐标
Image.fromarray(get_np_from_dict_list(hit_remove_interferA))
首次去除干扰线后的图片如下:
 图一 图一
|
 图二 图二
|
3.再次干扰线的去除:
初次去除干扰线后,比原来的图片好很多了。但是干扰还是较大的,特别是图一中的C,很容易被识别出是E,这样的训练效果很难保证。
先来看看被去除的干扰线的图像(图中红色部分为第一次去除的干扰线),可以发现规律:
1.从x轴角度看,第一次去除的干扰线与剩下部分是交叉相隔,就像奇偶数那样。
2.找出干扰线末端的一条竖线,如图中竖线A,他已确定为干扰线上的一条竖线。沿着A往左移动,若下一条连续的竖线上的y坐标均值跟竖线A的均值相差不多,那么可以判断下一条竖线跟竖线A是连续的,也是
干扰线上的一个点。
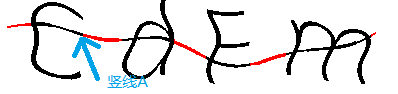 图一 图一
|
 图二 图二
|
#输入参数 hit_remove_interferA_Y:要继续判断的竖线组成的y坐标的数组 tmp_interfer_Y:已知干扰竖线组成的y坐标的数组
#筛选条件:1.竖线上的点小于MAX_Y_COUNT 2.均值相差小于3 3.满足上述条件的连续竖线只有一条
def get_interferB_segment(hit_remove_interferA_Y,tmp_interfer_Y):
ret=[]##下一个干扰竖线的y坐标组成的数组
hit_remove_interferA_Y_group=get_group(hit_remove_interferA_Y)
for i in hit_remove_interferA_Y_group:
if len(i)<MAX_Y_COUNT and (abs(np.array(i).mean()-np.array(tmp_interfer_Y).mean())<3):
ret.append(i)
if len(ret)==1:
return ret[0]
else:
print('return None, len(ret): ',len(ret))
return None
def get_interferB(interferA,hit_remove_interferA):
interferA_group=get_group(interferA.keys())
hit_remove_interferA_group=get_group(hit_remove_interferA.keys())
interferB={}
if len(hit_remove_interferA_group)==len(interferA_group):
left_to_right_filter_count=len(hit_remove_interferA_group)
right_to_left_filter_count=len(hit_remove_interferA_group)-1
else:
left_to_right_filter_count=len(hit_remove_interferA_group)
right_to_left_filter_count=len(hit_remove_interferA_group)
##从左到右
for idx in range(left_to_right_filter_count):
tmp_interferA_group=interferA_group[idx]
tmp_hit_remove_interferA_group=hit_remove_interferA_group[idx]
tmp_interfer_Y=interferA[tmp_interferA_group[-1]]
for i in tmp_hit_remove_interferA_group:
tmp_interfer_Y=get_interferB_segment(hit_remove_interferA[i],tmp_interfer_Y)
if tmp_interfer_Y==None:
break
else:
interferB[i]=tmp_interfer_Y
##从右到左
for idx in range(right_to_left_filter_count):
tmp_interferA_group=interferA_group[idx+1]
tmp_hit_remove_interferA_group=hit_remove_interferA_group[idx]
tmp_hit_remove_interferA_group=sorted(tmp_hit_remove_interferA_group,reverse=True)
tmp_interfer_Y=interferA[tmp_interferA_group[0]]
for i in tmp_hit_remove_interferA_group:
tmp_interfer_Y=get_interferB_segment(hit_remove_interferA[i],tmp_interfer_Y)
if tmp_interfer_Y==None:
break
else:
interferB[i]=tmp_interfer_Y
return interferB
interferB=get_interferB(interferA,hit_remove_interferA)
hit_remove_interferAB=minus_dict_list(hit_remove_interferA,interferB)
Image.fromarray(get_np_from_dict_list(hit_remove_interferAB))
再次去除干扰线的图片:
 图一 图一
|
 图二 图二
|
用机器学习获取模型:
图片识别较适合用深度学习的模型去训练的,由于自己在实践中很少有机会用深度学习的东西,所以也在此记录一下。
import os
captcha_list=[]##所有图片文件名
for file in os.listdir('./yanzhengma_preprocess/'):
captcha_list.append(file)
char_set = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
CHAR_SET_LEN=len(char_set)
#文字转为向量
def text2vec(text):
text=text.lower()
vector = np.zeros(4*CHAR_SET_LEN)
for i, c in enumerate(text):
idx = i * CHAR_SET_LEN + char_set.index(c)
vector[idx] = 1
return vector
#图片转为向量
def get_image_array(filename):
img=Image.open(filename)
pixels = img.load()
ret=np.zeros((94, 398))
for x in range(img.width):
for y in range(img.height):
if pixels[x, y] == (255, 255, 255):
ret[y, x] = 0#白色为0
else:
ret[y, x] = 1#黑色为1
ret=ret.astype('uint8')
return ret
#返回训练集和测试集
def load_image(num):
x_data,x_test=np.zeros((int(SAMPLE_NUM*0.9),IMAGE_HEIGHT,IMAGE_WIDTH)),np.zeros((int(SAMPLE_NUM*0.1),IMAGE_HEIGHT,IMAGE_WIDTH))
y_data,y_test=np.zeros((int(SAMPLE_NUM*0.9),CHAR_SET_LEN*4)),np.zeros((int(SAMPLE_NUM*0.1),CHAR_SET_LEN*4))
middle=int(num*0.9)#所有数据的90%为训练集
for idx,i in enumerate(captcha_list[0:middle]):
x_data[idx]=get_image_array('./yanzhengma_preprocess/'+i)
y_data[idx]=text2vec(i[:4])
for idx,i in enumerate(captcha_list[middle:num]):
x_test[idx]=get_image_array('./yanzhengma_preprocess/'+i)
y_test[idx]=text2vec(i[:4])
return [x_data,y_data ,x_test ,y_test]
SAMPLE_NUM=3380##数据量
x_data,y_data,x_test,y_test=load_image(SAMPLE_NUM)#### 有concate
模型代码:
from tensorflow import keras
inputs = keras.layers.Input(shape=(94, 398,1))
x = keras.layers.Conv2D(filters=3,kernel_size=(3,3),activation='relu')(inputs)
x = keras.layers.MaxPool2D(pool_size=(2,2))(x)
x = keras.layers.Conv2D(filters=3,kernel_size=(3,3),activation='relu')(x)
x = keras.layers.MaxPool2D(pool_size=(2,2))(x)
x = keras.layers.Conv2D(filters=3,kernel_size=(3,3),activation='relu')(x)
x = keras.layers.MaxPool2D(pool_size=(2,2))(x)
x = keras.layers.Flatten()(x)
x = keras.layers.Dense(512, activation='relu')(x)
predictions = [keras.layers.Dense(26, activation='softmax', name='c%d'%(i+1))(x) for i in range(4)]
predictions=keras.layers.Concatenate(axis=-1)(predictions)
model = keras.models.Model(inputs=inputs, outputs=predictions)
model.summary()
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
模型的结构:

训练代码:
x_data=x_data.reshape((int(SAMPLE_NUM*0.9), 94, 398,1))
x_test=x_test.reshape((int(SAMPLE_NUM*0.1), 94, 398,1))
history=model.fit(x_data, y_data,validation_data=(x_test,y_test), epochs=10,batch_size=32)
训练结果:

结论: 整个模型训练下来,最后的准确率大概能达到45%以上,由于验证码失败的成本不高,勉强可以拿来用了。要想进一步提高准确率,只能进一步增加训练数据集。
另外,对于带有干扰的验证码,最根本的办法找出干扰的规律,然后把干扰去除。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









