




 文章介绍了图的基本概念,包括无向图、有向图、完全图、顶点的度等,并阐述了图的两种存储结构——邻接矩阵和邻接表。接着,通过一个实例展示了如何使用深度优先遍历(DFS)和广度优先遍历(BFS)遍历图,以解决实际问题,如文献引用关系的探索。
文章介绍了图的基本概念,包括无向图、有向图、完全图、顶点的度等,并阐述了图的两种存储结构——邻接矩阵和邻接表。接着,通过一个实例展示了如何使用深度优先遍历(DFS)和广度优先遍历(BFS)遍历图,以解决实际问题,如文献引用关系的探索。
图(Graph)
是由一个非空的顶点集合和一个描述顶点之间关系 即边(Edges)的有限集合组成的一种数据结构。
可以定义为G(V,E)
其中, G表示—个图,V是图G中顶点的集台,E是图G中边的集台。
图的相关术语
(1)无向图(mdigaph)。在一个图中,如果每条边都没有方向则称该图为无向图。
(2)有向图(digraph)。在一个图中,如果每条边都有方向称该图为有向图。
(3)无向完全图。在一个无向图中, 如果任意两项点都有一条直接边相连控图为无向完全图。
(4)有向完全图。在个有向图中, 如果任意两顶点之间都有方向互为相反的相连接。则称该图为有向完全 图
(5)顶点的度、入度、出度。
在无向图中:
一个项点拥有的边数,称为该项点的度。
在有向图中:
一个顶点拥有的弧头的数目,称为该项点的入度,记为ID(v);
一个顶点拥有的弧尾的数目,称为该顶点的出度,记为OD(v);
一个顶点度等于顶点的入度+出度,即TD(v)=ID(v)+ OD(v)。
(6)权。图的边或弧有时具有与它有关的数据信息,这个数据信息就称为权(Weight)。
(7)网(Network)。每条边都有与它相关的数,称为权,这些权可以表示从一个顶点到另一个顶点的距离
或耗费等信息。这种带权的图叫做网。
(8)路径、路径长度。观尽Vi到观息Vj间的路径是指项点序列
路径上边或弧的数目称为路径长度。
(9)回路或环。在一个路径中,若其第一个顶点和最后一个顶点是相同的, 则称该路
为一个回路或环。
(10)简单路径。若表示路径的顶点序列中的顶点各不相同,则称这样的路径为简单路
径。
(11)简单回路。除了第一个和最后一个顶点外,其余各顶点均不重复出现的回路为简
单回路。
(12)子图 对于图G=(V,E),G'=(V',E'), 若存在V'是V的子集,E'是E的子集,
则称G'和G的一个子图。
(13)连通图、连通分量。在无向图中,如果从一个顶点vi到另一个顶点vj有路径,则称顶点v:和Vj是连通
的。任意两顶点都是连通的图称为连通图。无向图的极大连通子图称为连通分量。
(14)强连通图、强连通分量。对于有向图来说,若图中任意一 对顶点vi和vj (i≠j)均有从一个顶点vi到 另一个顶点vj有路径,也有从Vj到Vi的路径,则称该有向图是强连通图。有向图的极大强连通子图 称为强连通分量。
(15)生成树。连通图G的一个子图如果是一棵包含G的所有顶点的树,则该子图称为G的生成(Spanning Tree)。在生成树中添加任意一条属于 原图中的边必定会产生回路,因为新添加的边使其所依附的两 个顶点之间有了第二条路径。若生成树中减少任意一条边,则必然成为非连通的。n个顶点的生成树 具有n-1条边。
图的存储结构
邻接矩阵
图的邻接矩阵(Adjacency Matrix) 存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
定义出邻接矩阵的存储结构
#define MaxVertexNum 100 //顶点数目的最大值
typedef char VertexType; //顶点的数据类型
typedef int EdgeType; //带权图中边上权值的数据类型
typedef struct{
VertexType Vex[MaxVertexNum]; //顶点表
EdgeType Edge[MaxVertexNum][MaxVertexNum]; //邻接矩阵,边表
int vexnum, arcnum; //图的当前顶点数和弧树
}MGraph;
邻接表
邻接表(Adjacency Lis) 是图的一种顺序存储与链式存储结合的存储方法。邻接表表
示法类似于树的孩子链表表示法。就是对于图G中的每个顶点vi,该方法将所有邻接于n
的顶点vj;连成一个单链表, 这个单链表就称为顶点Vi的邻接表。再将所有顶点的邻接表表
头放到数组中,就构成了图的邻接表。
图的邻接表存储结构定义如下:
#define MAXVEX 100 //图中顶点数目的最大值
type char VertexType; //顶点类型应由用户定义
typedef int EdgeType; //边上的权值类型应由用户定义
/*边表结点*/
typedef struct EdgeNode{
int adjvex; //该弧所指向的顶点的下标或者位置
EdgeType weight; //权值,对于非网图可以不需要
struct EdgeNode *next; //指向下一个邻接点
}EdgeNode;
/*顶点表结点*/
typedef struct VertexNode{
Vertex data; //顶点域,存储顶点信息
EdgeNode *firstedge //边表头指针
}VertexNode, AdjList[MAXVEX];
/*邻接表*/
typedef struct{
AdjList adjList;
int numVertexes, numEdges; //图中当前顶点数和边数
}
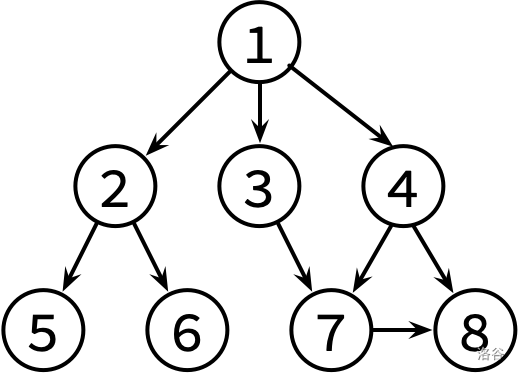
小K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考文献的话就不用再看它了)。
假设洛谷博客里面一共有 n(n≤105) 篇文章(编号为 1 到 n)以及 m(m≤106) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 X → Y 表示文章 X 有参考文献 Y。不保证编号为 1 的文章没有被其他文章引用。
#include<iostream> //头文件头文件头文件
#include<vector>
#include<queue>
#include<algorithm>
using namespace std;
struct edge{ //存边结构体
int u,v;
};
vector <int> e[100001]; //两个vector刚才已经详细讲过了
vector <edge> s;
bool vis1[100001]={0},vis2[100001]={0}; //标记数组
bool cmp(edge x,edge y){ //排序规则
if(x.v==y.v)
return x.u<y.u;
else return x.v<y.v;
}
void dfs(int x){ //深度优先遍历
vis1[x]=1;
cout<<x<<" ";
for(int i=0;i<e[x].size();i++){
int point=s[e[x][i]].v;
if(!vis1[point]){
dfs(point);
}
}
}
void bfs(int x){ //广度优先遍历
queue <int> q;
q.push(x);
cout<<x<<" ";
vis2[x]=1;
while(!q.empty()){
int fro=q.front();
for(int i=0;i<e[fro].size();i++){
int point=s[e[fro][i]].v;
if(!vis2[point]){
q.push(point);
cout<<point<<" ";
vis2[point]=1;
}
}
q.pop();
}
}
int main(){
int n,m; //输入,存边
cin>>n>>m;
for(int i=0;i<m;i++){
int uu,vv;
cin>>uu>>vv;
s.push_back((edge){uu,vv});
}
sort(s.begin(),s.end(),cmp); //排序
for(int i=0;i<m;i++)
e[s[i].u].push_back(i);
dfs(1); //从1号顶点开始深搜
cout<<endl;
bfs(1); //广搜亦同理
}
















 6009
6009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









