







一、web应用的性能分析
1、首先,确定整体瓶颈在哪
依据请求的流程,可大致分为 前端 -> 网络 -> 后端 三段。其中前端性能这里不做讨论,网络的话,测试性能的时候最好保持网络干扰最小。
2、其次,确定后端瓶颈在哪
后端处理一条请求时,大概会经过 应用程序 -> 中间件 -> 应用程序 -> 数据库 4段,其中中间件可能有也有可能没有。
3、最后,逐步分析每个地方的瓶颈
分析应用程序、中间件、数据库瓶颈时,重要原则就是:CPU -> 内存 -> 网络 -> 磁盘(性能最慢的设备会是瓶颈点)
1)应用程序瓶颈:
- CPU:应用程序运行在内存中,性能开销一般是CPU闲置导致,所以增加多线程提高CPU利用率是最快的提升性能的方法。
- 内存:减少链表等需要内存寻址的操作
- 网络:避免在for循环中建立网络连接,以及等待磁盘IO
- 磁盘:避免在for循环中等待磁盘IO
2)中间件瓶颈:
中间件大多为第三方产品,提高硬件设备性能是唯一的办法:建立集群(增加机器数量)、使用多核CPU、增加内存、使用千兆网卡和网线、使用固态硬盘等
3)数据库瓶颈:
- 磁盘:数据库的数据存在磁盘中,与磁盘进行IO交互是消耗性能最多的地方,减少磁盘访问可以最显著的提升效率(建立索引,优化sql,避免全盘扫描)
- 网络:如果数据库是独立部署的,网络传输是第二大消耗性能的地方,批量传输数据减少网络交互,分页技术减少返回数据都可以优化该处性能
二、Linux服务器性能分析—CPU
1、首先要确定CPU基础信息
使用lscpu命令查看 CPU配置信息。在 Linux 下,类似 lsxxx 这样的命令都是用来查看基本信息的,如 ls 查看当前目录文件信息,lscpu 就用来查看 CPU 信息,类似还有 lspci 查看 PCI 信息。
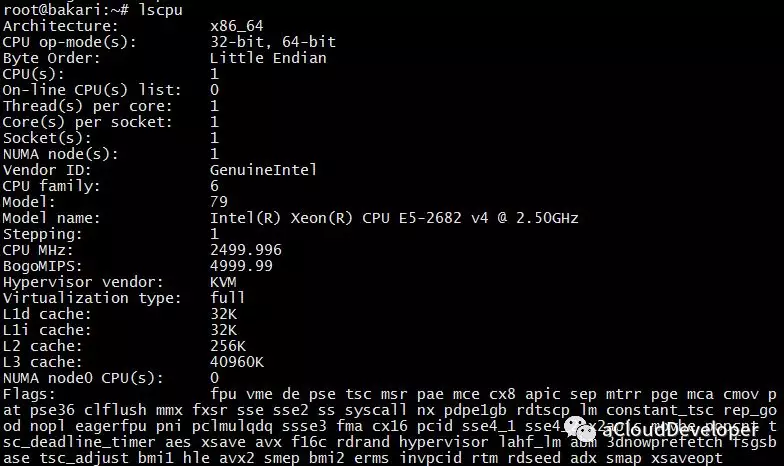
- Architecture: #架构
- CPU(s): #逻辑cpu颗数
- Thread(s) per core: #每个核心的线程数量
- Core(s) per socket: #每颗物理CPU的核数
- CPU socket(s): #物理CPU个数
- Vendor ID: #cpu厂商ID
- CPU family: #cpu系列
- Model: #型号
- Stepping: #步进
- CPU MHz: #cpu主频
- Virtualization: #cpu支持的虚拟化技术
- L1d cache: #一级缓存(google了下,这具体表示表示cpu的L1数据缓存)
- L1i cache: #一级缓存(具体为L1指令缓存)
- L2 cache: #二级缓存
2、计算cpu核数
- CPU总核数 =物理CPU个数 * 每颗物理CPU的核数 =2*4=8
- 总逻辑CPU数=物理CPU个数 * 每颗物理CPU的核数 * 超线程数* 复用比=2*4*2=16
一个核心就是一个物理线程,英特尔有个超线程技术可以把一个物理线程模拟出两个线程来用,充分发挥CPU性能。
3、CPU 使用情况分析
使用top命令查看cpu的使用情况

重点关注这么几个字段:
1)load average:三个数字分别表示最近 1 分钟,5 分钟和 15 分钟的负载,数值越大负载越重。一般要求不超过核数,比如对于单核情况要 < 1。如果机器长期处于高于核数的情况,说明机器 CPU 消耗严重了。
2)%Cpu(s):表示当前 CPU 的使用情况,如果要查看所有核(逻辑核)的使用情况,可以按下数字 “1” 查看。这里有几个参数,表示如下:
- us 用户空间占用 CPU 时间比例- sy 系统占用 CPU 时间比例- ni 用户空间改变过优先级的进程占用 CPU 时间比例- id CPU 空闲时间比- wa IO等待时间比(IO等待高时,可能是磁盘性能有问题了)- hi 硬件中断- si 软件中断- st steal time
3)每个进程的使用情况
这里可以罗列每个进程的使用情况,包括内存和 CPU 的,如果要看某个具体的进程,可以使用 top -p pid 查看。
三、Linux服务器性能分析—内存
1、使用free命令查看内存使用情况

这里存在一个计算公式, 还有个 shared 字段,这个是多进程的共享内存空间,不常用
MemTotal = used + free + buff/cache(单位 K)我们注意到 free 很小,buff/cache 却很大,这是 Linux 的内存设计决定的,Linux 的想法是内存闲着反正也是闲着,不如拿出来做系统缓存和缓冲区,提高数据读写的速率。但是当系统内存不足时,buff/cache 会让出部分来,非常灵活的操作。
2、内存使用情况分析
使用top 命令查看内存使用情况。运行时默认是按照 CPU 利用率进行排序的,如果要按照内存排序,该怎么操作呢?两种方法,一种直接按 “M”(相应的按 “P” 是 CPU),另外一种是在键入 top 之后,按下 “F”,然后选择要排序的字段,再按下 “s” 确认即可。

可以看到,我按照 “%MEM” 排序的结果。这个结果对于查看系统占用内存较多的哪些进程是比较有用的。
然后这里我们会重点关注几个地方,上面横排区,和前面几个命令一样可以查看系统内存信息,中间标注的横条部分,和内存相关的有三个字段:VIRT、RES、SHR。
- VIRT:virtual memory usage,进程占用的虚拟内存大小。
- RES:resident memory usage,进程常驻内存大小,也就是实际内存占用情况,一般我们看进程占用了多少内存,就是看的这个值。
- SHR:shared memory,共享内存大小,不常用。
参考文章:














 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









