






问题发现
系统特征是每天晚上生产,随着时间,接口耗时(tp99)越来越高,但不会超过200ms,平均耗时在80ms左右,这个问题是一个非常大的隐患,好在系统还在灰度期间,流量不大,服务没有崩,但在1月7日放了4倍流量进来后,爆发了慢SQL,导致接口平均耗时从平时的80ms陡增到了平时400ms左右,高点在800ms,随着流量增加,必定拖垮服务。
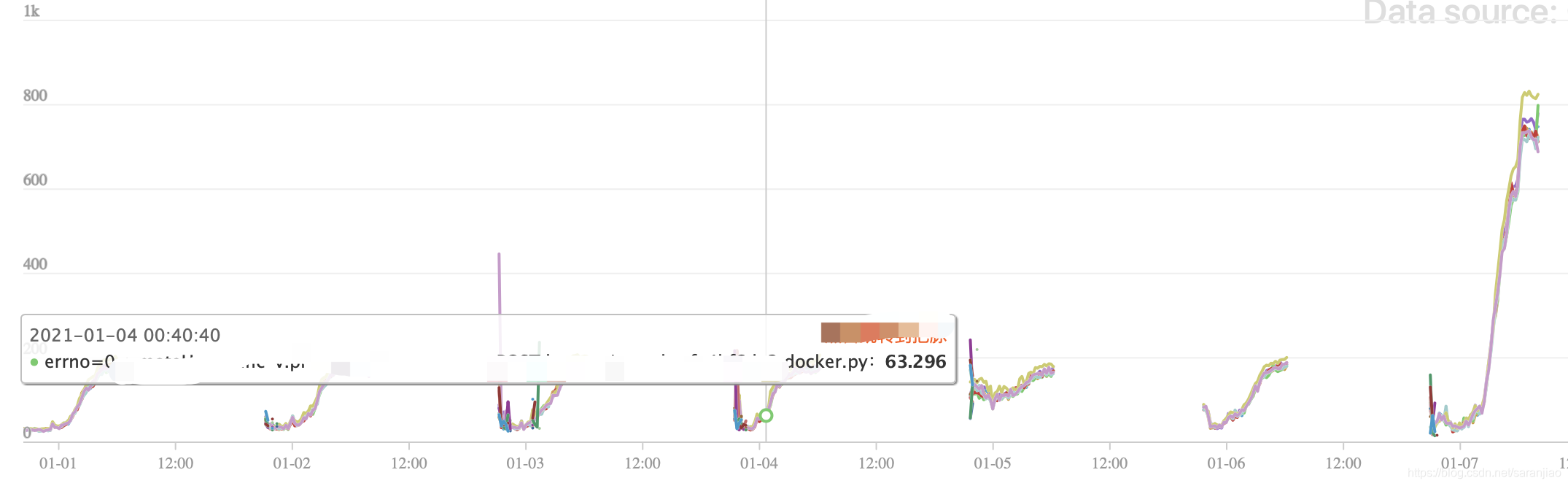
排查问题
跟踪代码发现,此处的list永远不会为null,因为Id字段数据库给了默认值,所以这是一个代码缺陷,导致每个请求都会去调用xxxService查库,每个请求都去扫描全表,并且频次非常高,list永远为null,sql的where条件永远为空

这个Service中sql的写法:
<if test="idList!= null and idList.size() > 0">
and id in
<foreach collection="idList.size" item="id" index="index" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
sql耗时:260ms

问题解决
定位问题是最难的,解决问题是容易的。由于没有出现功能缺陷,所以流量上去之后才爆发了问题,好在及时兜住。fix:过滤下为空字符串的值,让拦截起作用,即使没有return,idList也是有值的,sql查询会走where条件。
List<String> idList = lists.stream()
.filter(b->b.getId()!=null)
.filter(b->!"".equals(b.getId()))
.map(XXXBean::getId).collect(Collectors.toList());
if (CollectionUtils.isEmpty(idList)) {
return idList;
}
优化效果
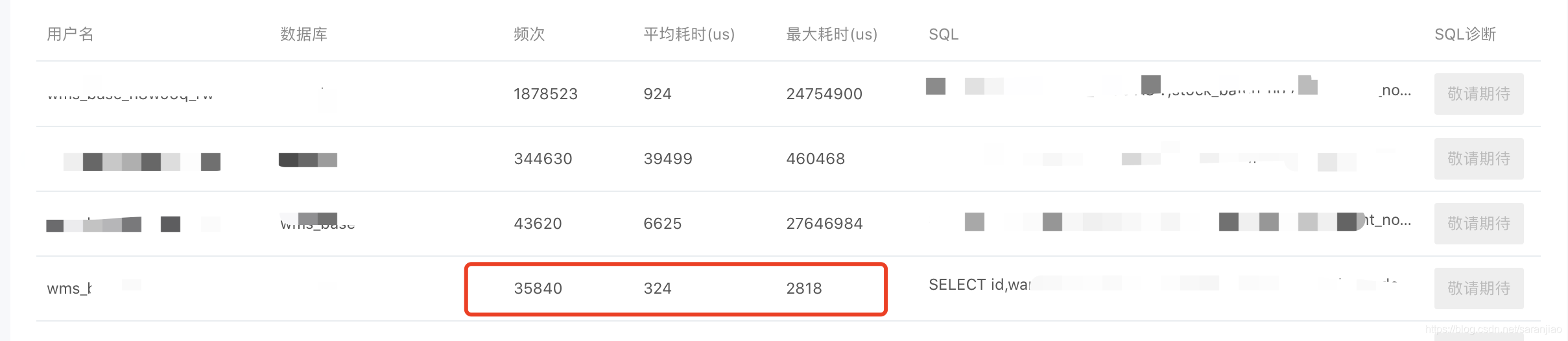
上线后的效果非常惊人,接口耗时瞬间降到了20ms

sql耗时:324us ,走了where条件sql耗时降到了微妙级别。
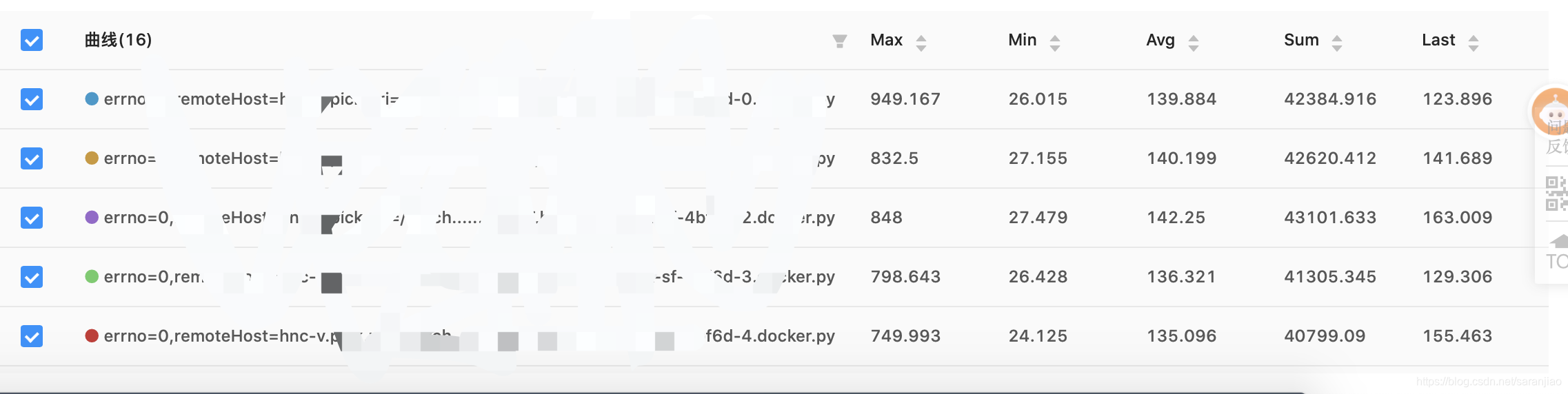
上线观察几分钟,tp99平均耗时瞬间下降:130ms左右
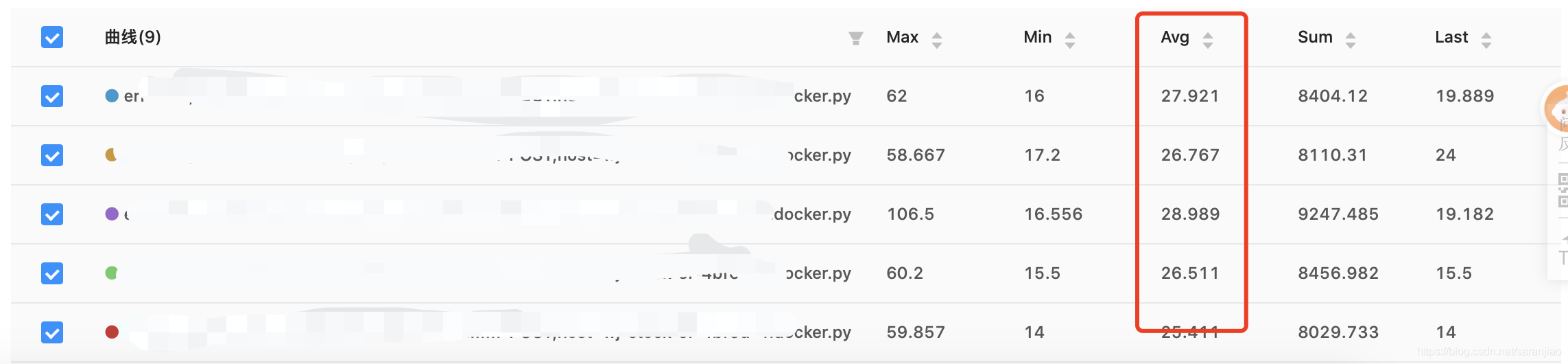
观察2小时,查看最近2小时的平均接口耗时:26ms左右
总结:
接口开发完,应该关注接口性能,每句sql应该考虑是否有慢查询的可能,关注tp99接口耗时。















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









