









-
RDD
RDD:是弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变,可分区、里面的元素可并行计算的集合。
优点:
a. 编译时类型安全:编译时就能检查出类型错误;
b. 面向对象的编程风格:直接通过类名点的方式来操作数据;
缺点:
a. 序列化和反序列化的性能开销:无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化;
b. GC (垃圾回收)的性能开销,频繁的创建和销毁对象,势必会增加GC(程序进行GC时,所有任务都是暂停); -
DataFrame
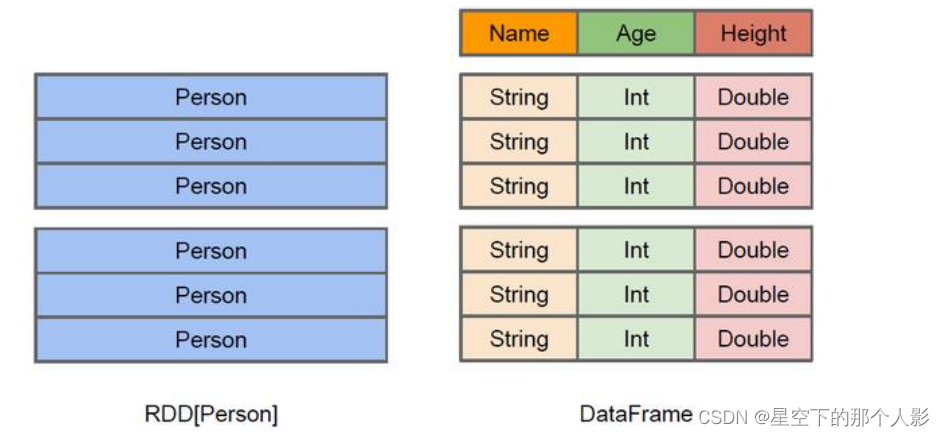
DataFrame 以 RDD 为基础的分布式数据集。
DataFrame 引入了 schema 和 off-heap
schema : RDD 每一行的数据,结构都是一样的,这个结构就存储在 schema 中。Spark 通过 schema 就能够读懂数据,因此在通信和IO时就只需要序列化和反序列化数据,而结构的部分就可以省略了。
off-heap:JVM堆以外的内存,这些内存直接受操作系统管理(而不是 JVM )。spark 能够以二进制的形式序列化数据到 off-heap 中,当要操作数据时,就直接操作 off-heap 内存。由于 spark 理解 schema,所以知道该如何操作。
DataFrame 不受 JVM 的限制,也就不受 GC 的困扰了。
通过对 schema 和 off-heap,DataFrame 解决了 RDD 的缺点,却丢了 RDD 的优点,DataFrame 不是类型安全的,API也不是面向对象风格的。 -
DataSet
DataSet 结合了 RDD 和 DataFrame 的优点, 并带来一个新的概念 Encoder。
当序列化数据时,Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。
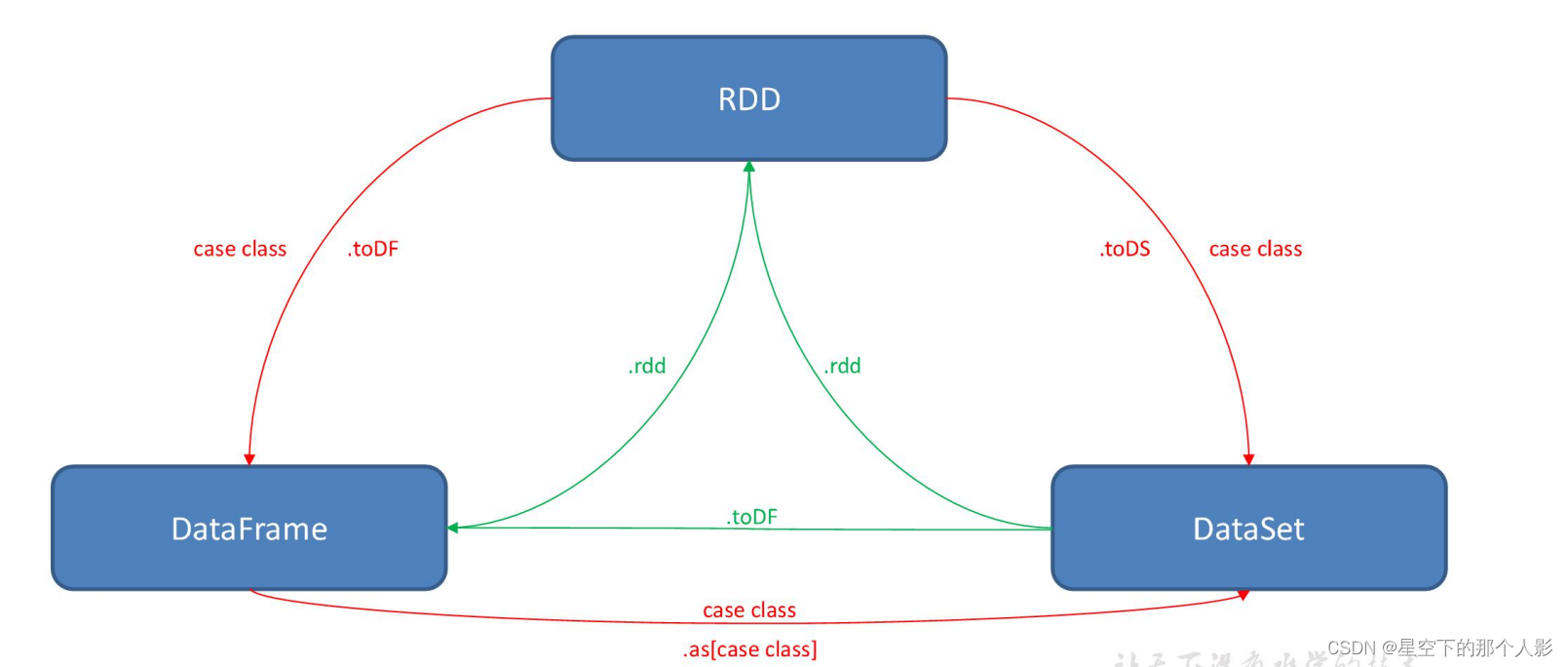
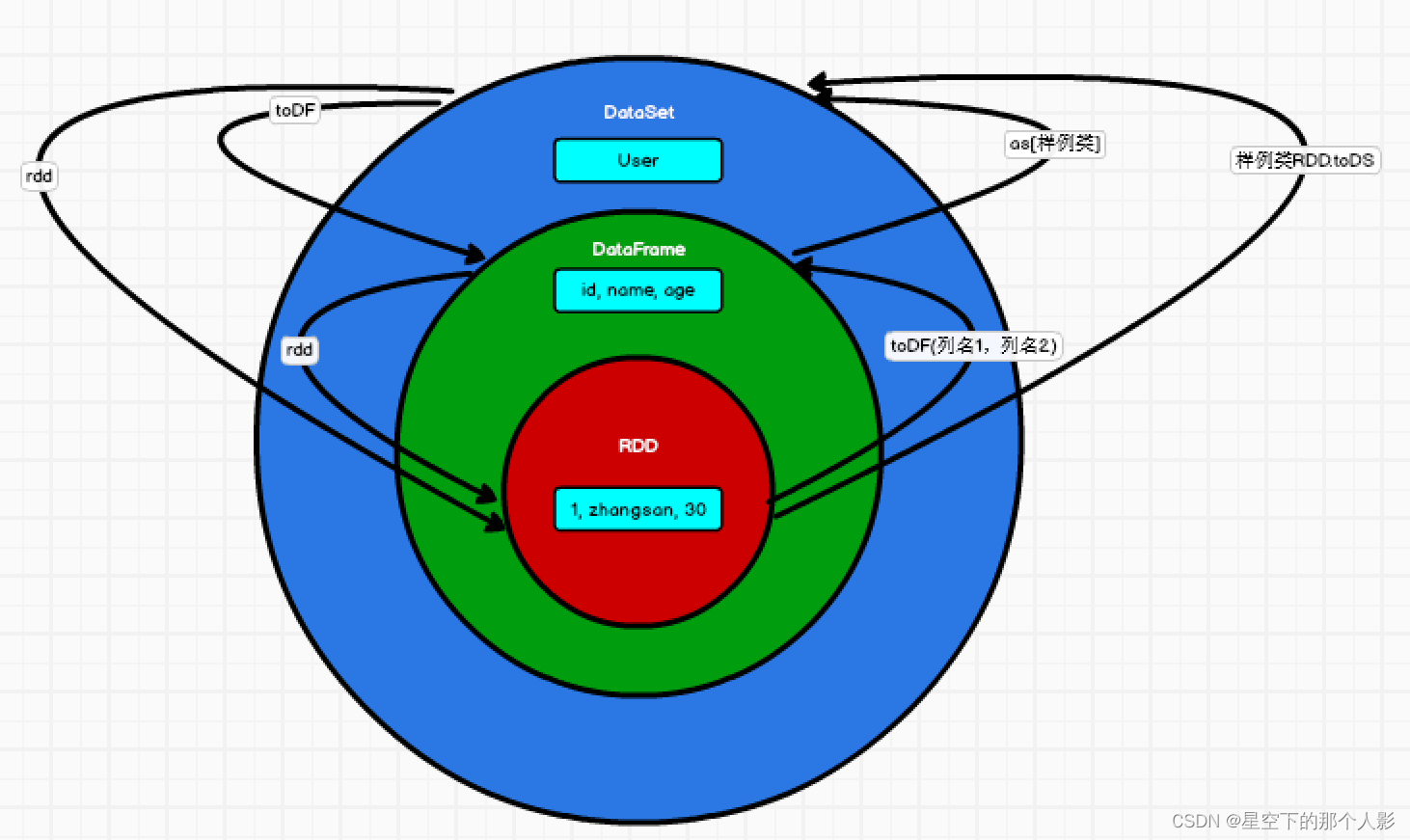
三者之间的转换:















07-14
 6860
6860
6860
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









