






1.当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
2.java是由什么演变而来的?
是由C演变而来的。
3.Hashtable和HashMap 的区别?
主要区别在于HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步
4. 数组有没有length()这个方法? String有没有length()这个方法?String 有length()方法,而数组没有length()这个方法,但数组有length的属性。
5.三个statement的用法,区别
statement对象作为最基本的数据操作对象,可以应用于几乎所有的数据库,但是由于运行时使用的是字符串连接技术,所以存在安全隐患。
preparedstatement:叫做预编译的对象,在语句执行之前,向数据库发送类似于公式一样的模板,其中使用了替换变量,从而提高了数据存储的安全性,但这个数据操作对象不是效率最高的。可以应用于绝大多数数据库。
callablestatement:效率和安全性最高的数据操作对象,但是兼容性是最差的。因为这个对象是用来调用数据库当中的存储过程的,不是所有的数据库都支持存储过程。
6.什么是session,什么是cookie?
Session是由应用服务器维持的一个服务器端的存储空间,用户在连接服务器时,会由服务器生成一个唯一的SessionID,用该SessionID为标识符来存取服务器端的Session存储空间。而SessionID这一数据则是保存到客户端,用Cookie保存的,用户提交页面时,会将这一SessionID提交到服务器端,来存取Session数据。这一过程,是不用开发人员干预的。所以一旦客户端禁用Cookie,那么Session也会失效。
Cookie是客户端的存储空间,由浏览器来维持。
区别:
(1)cookie数据存放在客户的浏览器上,session数据放在服务器上
(2)cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
(3)session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
(4)单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能超过3K。
(5)所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
7.servlet的生命周期
从Tomcat处理用户请求,我们可以清晰的看到容器Servlet的生命周期管理过程:
1、客户发出请求—>Web 服务器转发到Web容器Tomcat;
2、Tomcat主线程对转发来用户的请求做出响应创建两个对象:HttpServletRequest和HttpServletResponse;
3、从请求中的URL中找到正确Servlet,Tomcat为其创建或者分配一个线程,同时把2创建的两个对象传递给该线程;
4、Tomcat调用Servlet的servic()方法,根据请求参数的不同调用doGet()或者doPost()方法;
5、假设是HTTP GET请求,doGet()方法生成静态页面,并组合到响应对象里;
6、Servlet线程结束,Tomcat将响应对象转换为HTTP响应发回给客户,同时删除请求和响应对象。
从该过程中,我们可以理解Servlet的生命周期:Servlet类加载(对应3步);Servlet实例化(对应3步);调用init方法(对应3步);调用service()方法(对应4、5步);调用destroy()方法(对应6步)。
8.jsp的架构模型
(Model1)jsp+javabean (Model2)jsp+servlet+javabean
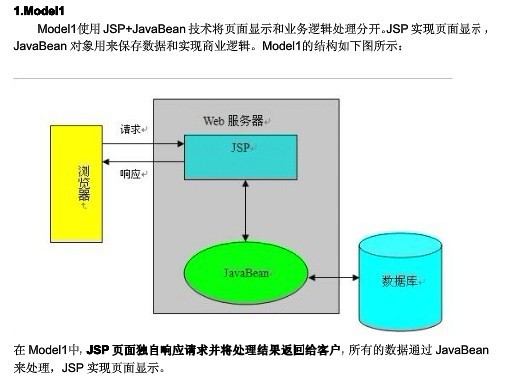

注意一点:Model1中,是jsp页面独自响应请求并将处理结果返回客户,jsp既要负责业务流程控制,又要负责提供表示层数据,同时充当视图和控制器,而Model2是由Servlet来接受请求,创建jsp页面需要使用的javabean对象,根据用户请求选择合适的jsp页面返回给用户,在jsp页面中没有处理逻辑,它仅负责检索原先由Servlet创建的javabean对象,从Servlet中提取动态内容插入到静态模板中。
9.jsp的执行过程和生命周期
JSP 的执行过程
(1) 客户端发出Request (请求);
(2) JSP Container 将JSP转译成Servlet的源代码;
(3) 将产生的Servlet 的源代码经过编译后,并加载到内存并进行实例化;
(4) 把结果Response (响应)至客户端。
在执行 JSP 网页时,通常可分为两个时期:转译时期(Translation Time)和请求时期(Request Time)
转译时期:JSP网页转译成Servlet类。
请求时期:Servlet类执行后,响应结果至客户端。
注:
转译期间主要做了两件事情:将JSP网页转译为 Servlet 源代码(.java),此段称为转译时
期(Translation time);将Servlet源代码(.java)编译成 Servlet 类(.class),此段称为编译时期(Compilation time)。
生命周期
1、转换 验证JSP页面,没有出现错误,就创建一个包含servlet类的java文件;
2、编译 把java文件编译成类(.class)文件 并报告语法错误
3、加载和实例化 编译成功则将servlet类加载到内存中,并对其进行实例化;
4、jspInit() 执行一次初始化;
5、jspService() 进行请求处理;
6、jspDestroy() JSP引擎从服务器中删除servlet实例时,会调用jspDestroy();
JSP的生命周期将分为三个阶段:
◆装载和实例化:服务端为JSP页面查找已有的实现类,如果没找到则创建新的JSP页面的实现类,然后把这个类载入JVM。在实现类装载完成之后,JVM将创建这个类的一个实例。这一步会在装载后立刻执行,或者在第一次请求时执行。
◆初始化:初始化JSP页面对象。如果你希望在初始化期间执行某些代码,那么你可以向页面中增加一个初始化方法(method),在初始化的时候就会调用该方法。
◆请求处理:由页面对象响应客户端的请求。需要注意的是,单个对象实例将处理所有的请求。在执行完处理之后,服务器将一个响应(response)返回给客户端。这个响应完全是由HTML标签和其他数据构成的,并不会把任何Java源码返回给客户端。
◆生命周期终止:服务器不再把客户端的请求发给JSP。在所有的请求处理完成之后,会释放掉这个类的所有实例。一般这种情况会发生在服务器关闭的时候,但是也有其他的可能性,比如服务器需要保存资源、检测到有JSP文件更新,或者由于其他某些原因需要终止实例等情况。如果想让代码执行清除工作,那么可以实现一个方法,并且在这个类实例释放之前调用该方法。本章随后一节“处理JSP的初始化和终止”将对此加以讨论。
10.简单介绍下DWR框架,并说一下它的实现原理?
DWR(Direct Web Remoting)是一个WEB远程调用框架,利用这个框架可以让AJAX开发变得很简单.利用DWR可以在客户端利用JavaScript直接调用服务端的Java方法并返回值给JavaScript就好像直接本地客户端调用一样(DWR根据Java类来动态生成JavaScrip代码).
原理:
DWR的实现原理是通过反射,将java翻译成javascript,然后利用回调机制,从而实现了javascript调用Java代码
DWR真正的巧妙之处是,在用户配置了要向客户机公开的服务之后,它使用反射来生成JavaScript对象,以便 Web页面能够使用这些对象来访问该服务。然后Web页面只需接合到生成的JavaScript对象,就像它们是直接使用服务一样;DWR无缝地处理所有有关Ajax和请求定位的琐碎细节。
11.比较AJAX与DWR的区别
2.Dwr是一种框架,并且它是基于Ajax的基础之上,所以Ajax的功能Dwr也具有了,能够在javascript直接调用java方法,实现局部刷新,也可以说Dwr是对Ajax的Java封装。
相比之下,二者的优缺点是ajax配置少但js代码多,而dwr配置多js代码却少。
12.java集合:数组Collection、List、Set、Map的比较
数组
数组和其它容器的区别主要有三方面:效率,类型,和保存基本类型的能力.在Java中,数组是一种效率很高的存储和随机访问对象引用序列的方式.数组是一 个简单的线性序列,因此访问速度很快,但也损失了其它一些特性.创建一个数组对象后,大小就固定了,如果空间不够,通常是再创建一个数组,然后把旧数组中 的所有引用移到新数组中.数组可可以保存基本类型,容器不行.
容器类不以具体的类型来处理对象,而是将所有的对象都以Object类型来处理,所以我们可以只创建一个容器,任意的Java对象都可以放进去.容器类可 以使用包装类(Integer,Double等),以便把基本类型放入其中. List Set Map 都可以自动调整容量,数组不能.
Collection表示一组对象,这些对象也称为collection的元素。一些 collection允许有重复的元素,而另一些则不允许。一些collection是有序的,而另一些则是无序的。JDK中不提供此接口的任何直接实 现,它提供更具体的子接口(如 Set 和 List)实现.
Map 将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射一个值.Map 接口提供三种collection视图,允许以键集、值集合或键值映射关系集的形式查看某个映射的内容。某些映射实现可明确保证其顺序,如 TreeMap(有序) 类;某些映射实现则不保证顺序,如 HashMap(无序) 类。Map可以像数组那样扩展成多维数组,只要把每个值也做成一个Map就行了.
Collection和Map是Java容器中的两种基本类型. 区别在于容器中每个位置保存的元素个数.Collection每个位置只能保存一个元素,包括List和Set.其中List以进入的顺序保存一组元素; 而Set中的元素不能重复.ArrayList是一种List,HashSet是一种Set,将元素添加入任意Collection都可以使用add() 方法.Map保存的是健值对.使用put()为Map添加元素,它需要一个健和一个值作参数.
ArrayList和LinkedList都实现了List接口,ArrayList底层由数组支持LinkedList由双向链表支持,因此,如果经常在表中插入或删除元素LinkedList比较适合,如果经常查询ArrayList比较适合.
Set的实现有TreeSet,HashSet,LinkedHashSet,HashSet查询速度最快,LinkedHashSet保持元素插入次序,TreeSet基于TreeMap,生成一个总是处于排序状态的Set.
Collection<--List<--Vector
Collection<--List<--ArrayList
Collection<--List<--LinkedList
Collection<--Set<--HashSet
Collection<--Set<--HashSet<--LinkedHashSet
Collection<--Set<--SortedSet<--TreeSet
Vector : 基于Array的List,其实就是封装了Array所不具备的一些功能方便我们使用,它不可能走入Array的限制。性能也就不可能超越Array。所以,在可能的情况下,我们要多运用Array。另外很重要的一点就是Vector“sychronized”的,这个也是Vector和ArrayList的唯一的区别。
ArrayList:同Vector一样是一个基于Array上的链表,但是不同的是ArrayList不是同步的。所以在性能上要比Vector优越一些,但是当运行到多线程环境中时,可需要自己在管理线程的同步问题。
LinkedList:LinkedList不同于前面两种List,它不是基于Array的,所以不受Array性能的限制。它每一个节点(Node)都包含两方面的内容:1.节点本身的数据(data);2.下一个节点的信息(nextNode)。所以当对LinkedList做添加,删除动作的时候就不用像基于Array的List一样,必须进行大量的数据移动。只要更改nextNode的相关信息就可以实现了。这就是LinkedList的优势。
List总结:
1. 所有的List中只能容纳单个不同类型的对象组成的表,而不是Key-Value键值对。例如:[ tom,1,c ];
2. 所有的List中可以有相同的元素,例如Vector中可以有 [ tom,koo,too,koo ];
3. 所有的List中可以有null元素,例如[ tom,null,1 ];
4. 基于Array的List(Vector,ArrayList)适合查询,而LinkedList(链表)适合添加,删除操作。
HashSet:虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在HashMap的基础上来实现的,这个就是Set和List的根本区别。HashSet的存储方式是把HashMap中的Key作为Set的对应存储项。看看HashSet的add(Object obj)方法的实现就可以一目了然了。
public boolean add(Object obj)
{
return map.put(obj, PRESENT) == null;
}
这个也是为什么在Set中不能像在List中一样有重复的项的根本原因,因为HashMap的key是不能有重复的。
LinkedHashSet:HashSet的一个子类,一个链表。
TreeSet:SortedSet的子类,它不同于HashSet的根本就是TreeSet是有序的。它是通过SortedMap来实现的。
Set总结:
1. Set实现的基础是Map(HashMap);
2. Set中的元素是不能重复的,如果使用add(Object obj)方法添加已经存在的对象,则会覆盖前面的对象;















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









