







1、HashMap底层数据结构
JDK1.7的底层是 数组+链表;
JDK1.8之后 数组 + 链表 + 红黑树;
数组特点:具有随机访问的特点,能达到O(1)的时间复杂度,数组查询快,增删比较麻烦;
链表特点:与数组恰恰相反,链表的时间复杂度达到O(n),只能顺着节点依次的找下去,增删比较快,查询比较慢;
都知道 Map 是以键值对的形式存储的 num(key,value),key值不可以重复,假设下载有两个key一样被hash(key)作为同一个下标 i ,这是数组下标 i 只可以保存一个元素,此时链表就发挥作用了,加入链表来解决hash冲突,两个key会用next连接起来,当key被连接成一个链表时,每次只能从第一个Node开始寻找,查询就会很低,为了解决这个问题 JDK1.8之后引入了 红黑树 数据结构来解决这个问题。
1.1、为什么HashMap的负载因子是0.75
在HashMap中有个默认的 DEFAULT_LOAD_FACTOR 负载因子为 0.75;
假设我们将负载因子设置为1,那么HashMap的容量需要全部装满,才会允许扩容,HashMap的容量如果全部装满再扩容会伴随着大量的hash冲突,这时候put和get操作效率就回低下。
如果将负载因子设置为0.5,这时HashMap的容量达到50%就会进行扩容,这样虽然减少了hash冲突概率,但是会存在一半空间还没有被用到就扩容,会造成空间利用率低。
既然0.5和1都不行那么就取中间数0.75,显然不是这样的,而是根据一个数学公式(牛顿二项式)推理出一个数字,是0.693,而0.75是为了后期使用时为了方便计算而做出的。
HashMap的put操作(添加):
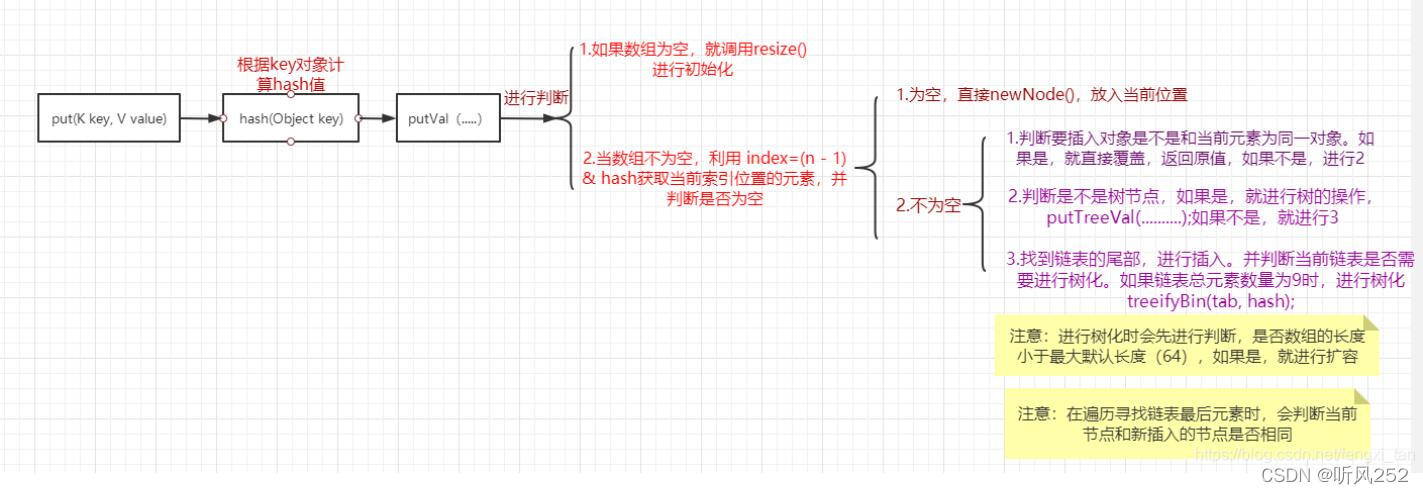 代码:
代码:
//put操作
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//计算key对象的hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//进行与操作
}
//具体添加细节
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; //创建数组
Node<K,V> p; //新节点
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //对数组进行初始化
if ((p = tab[i = (n - 1) & hash]) == null) //(n - 1) & hash 求数组的下标,判断是否有元素。没有
tab[i] = newNode(hash, key, value, n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1179
1179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









