









C#:
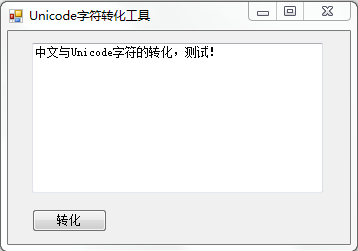
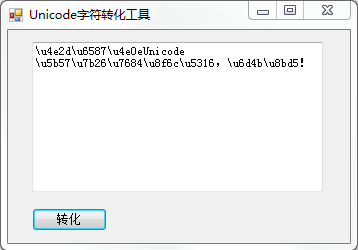
示例:
private void button1_Click(object sender, EventArgs e)
{
String value = textBox1.Text;
if (value.Contains("\\u"))
value = UnicodeConverter.ToChinese(value); // Unicode字符转化为中文
else value = UnicodeConverter.ToUnicode(textBox1.Text); // 中文转化为Unicode字符
textBox1.Text = value;
}using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace UnicodeStringTool
{
/// <summary>
/// 此类用于实现Unicode字符与中文字符的相互转换
/// </summary>
class UnicodeConverter
{
/// <summary>
/// 将中文字符串转化为Unicode串
/// </summary>
public static String ToUnicode(String str)
{
String tmp = "";
foreach (char C in str)
{
if (isChinese(C)) tmp += "\\u" + ToString(C, 16); // 将中文字符转化为Unicode串
else tmp += C;
}
return tmp;
}
/// <summary>
/// 将Unicode串转化为中文字符串
/// </summary>
public static String ToChinese(String str)
{
String tmp = str;
Regex regex = new Regex("\\\\u[0-9a-fA-F]{4}", RegexOptions.IgnoreCase);
MatchCollection collection = regex.Matches(tmp);
foreach (Match match in collection)
{
String hexStr = match.Value.Substring("\\u".Length); // 获取16进制串
String C = ToChar(match.Value, 16).ToString();
tmp = tmp.Replace(match.Value, C);
}
return tmp;
}
// 相关功能函数
// -----------------------------------------------------------------
// 判断字符C是否是中文字符
public static bool isChinese(char C)
{
// 中文字符范围
return 0x4e00 <= C && C <= 0x9fbb;
}
// 将数值num转化为radix进制表示的字符串, 2 <= radix <= 36
public static String ToString(int num, int radix = 10)
{
String Str = "";
while (num > 0)
{
int remainder = num % radix; // 取余数
num = num / radix; // 取商
Str = ToChar(remainder) + Str; // 将各位余数,依次转化为对应进制字符
}
return Str;
}
// 将数值n转化为字符,0 <= n <= 35,依次转化为字符0-9a-z;
// 最大可表示36进制数
public static char ToChar(int n)
{
n = n % 36;
if (n < 10) n += '0';
else n += 'a' - 10;
return (char)n;
}
// 将字符0-9a-z依次转化为数值0-35
public static int ToInt(char C)
{
if (C > '9') return C - 'a' + 10;
else return C - '0';
}
// 将字符串radix进制的串str转化为字符
public static char ToChar(String str, int radix)
{
int n = 0;
foreach (char C in str)
{
n = n * radix + ToInt(C);
}
return (char)n;
}
// -----------------------------------------------------------------
}
}
java:
\u55\u5b57\u7b26
U字符
/** ChineseCharacterTransform.java: ----- 2016-9-20 下午3:49:51 wangzhongyuan */
public class ChineseCharacterTransform
{
public static void main(String[] args)
{
String str = "U字符";
String Ustr = to_U_Str(str);
System.out.println(Ustr); // 转化为U字符
Ustr = "\\u55\\u5b57\\u7b26";
System.out.println(UStr_2_Str(Ustr)); // 转化为表示的文本
}
/* 将字符串转化为\\u形式的字符串,如: "U字符" -> "\\u55\\u5b57\\u7b26" ;U字符为字符串中每个字符的16进制信息 */
public static String to_U_Str(String str)
{
String tmp = "";
for (char C : str.toCharArray())
// 获取所有字符
tmp += "\\u" + Integer.toHexString(C); // 将每个字符的的值,转化为16进制字符串
return tmp;
}
/* 将U字符转化为其表示的字符串, 如: "\\u55\\u5b57\\u7b26" -> "U字符" ;按\\u分割,依次转化为对应字符*/
public static String UStr_2_Str(String Ustr0)
{
String Ustr = Ustr0;
int S = 0, E = 0;
String C = "", Value = "";
while (Ustr.contains("\\u"))
{
S = Ustr.indexOf("\\u") + "\\u".length();
E = Ustr.indexOf("\\u", S);
if (E == -1) E = Ustr.length();
if (E > S)
{
C = Ustr.substring(S, E);
if (C.length() > 4) C = C.substring(0, 4);
Value = (char) Integer.parseInt(C, 16) + "";
Ustr = Ustr.replace("\\u" + C, Value);
}
}
return Ustr;
}
}















 1242
1242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









