







MVCC - 多版本并发控制
MVCC,全称 Multi-Version Concurrency Control,即多版本并发控制。通过维持一个数据的多个版本,来控制并发。
一、MVCC 概述
1、三种并发场景
读-读:不存在任何问题,也不需要并发控制。读-写:有并发问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读。写-写:有并发问题,可能会存在更新丢失、更新覆盖的问题。
2、当前读 & 快照读
-
当前读:读取的是记录的最新版本,读取时要加锁,保证其他并发事务不能修改当前记录。(如共享锁和排他锁)
-
快照读:读取的可能是记录的历史版本,读取时不加锁。
注意:
快照读在MySQL的串行隔离级别下会上升为当前读,即使是select操作也会加锁。
3、MVCC的作用
MVCC就是为了不采用悲观锁这样性能不佳的形式去解决读-写的并发问题,而提出的解决方案。
- 可以做到读操作不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能(解决了
读-写并发问题) - 可以解决
脏读,幻读,不可重复读等事务隔离问题,但不能解决更新丢失的问题(仍存在写-写并发问题)
4、结合MVCC处理并发问题
因为有了MVCC,所以我们可以形成两个组合:
-
MVCC + 悲观锁:MVCC解决
读-写的并发问题,悲观锁解决写-写的并发问题 -
MVCC + 乐观锁:MVCC解决
读-写的并发问题,乐观锁解决写-写的并发问题
这种组合的方式,可以最大程度的提高数据库并发性能,并解决数据库的并发问题。
二、MVCC 实现原理
MVCC 在 MySQL 中的具体实现是由 隐式字段 + Undo Log + Read View 完成的。
1、隐式字段
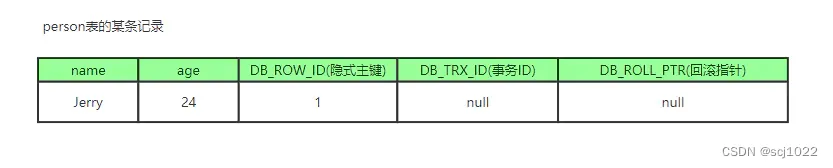
数据库中的每行记录,除了我们自定义的字段外,还有数据库隐式定义的一些字段:
| 名称 | 字段 | 占用 | 作用 |
|---|---|---|---|
| 隐式主键 | DB_ROW_ID | 6 byte | 如果数据表没有主键,InnoDB会自动根据 DB_ROW_ID 产生一个聚簇索引。 |
| 事务ID | DB_TRX_ID | 6 byte | 记录 创建这条记录 或 最后一次修改这条记录 的事务ID(即最新的事务ID) |
| 回滚指针 | DB_ROLL_PTR | 7 byte | 指向这条记录的上一个版本(存储于rollback segment里) |
2、回滚日志 Undo Log
MVCC 使用到的快照存储在 undo log 中,该日志通过回滚指针把一个数据行(Record)的所有快照连接起来。
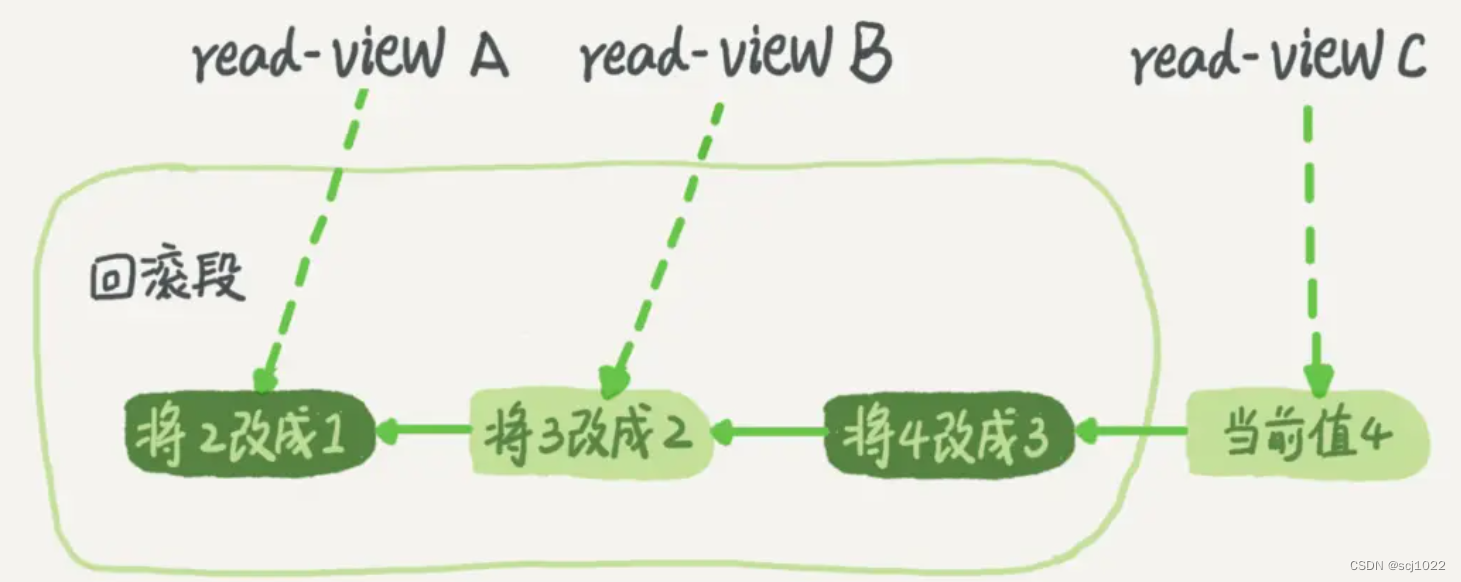
如何获取一条记录的历史版本呢?
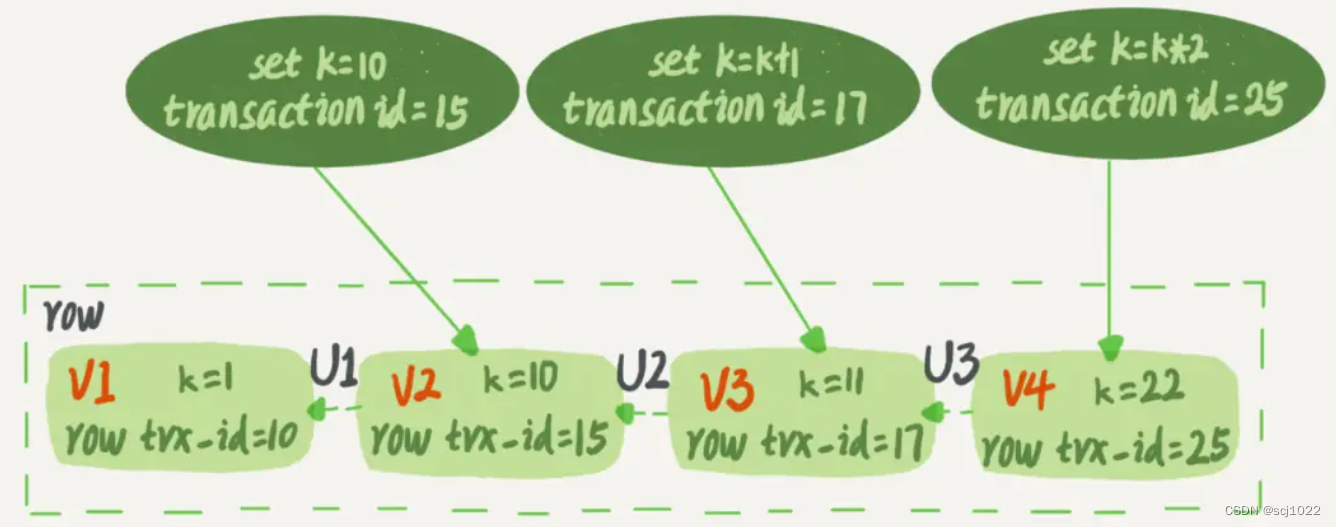
虚线框里是同一行数据的4个版本,图中的三个虚线箭头U1、U2、U3就是undo log。
- V1、V2、V3并不是物理上真实存在的,而是每次需要的时候,根据
当前版本V4和undo log计算出来的。
3、一致性视图 Read View
上一节说到,多个事务对同一行记录进行更新会产生多个历史版本,这些历史版本可以通过 当前版本 和 undo log 计算出来。
但是,如果一个事务要想查询某条行记录,需要读取哪个版本的行记录呢?这时就需要根据 Read View 来进行判断了。
1)什么时候生成?
不同的隔离级别下,生成Read View的时机也是不一样的(MVCC主要解决 RC 和 RR 两种隔离级别)
- 可重复读(RR):
当前事务第一次select时,创建Read View,之后事务里的其他查询都共用这个Read View。 - 读已提交(RC):
每一个select执行之前,都会重新创建一个新的Read View。
2)可见性判断
如何通过 Read View 判断当前事务能够看到哪个版本的数据呢?
- 获取行记录的最新事务ID(即
DB_TRX_ID) - 根据 Read View 的
可见性算法判断可见性。 - 若不符合可见性,就通过
回滚指针取出上一版本的事务ID再进行判断- 遍历版本链的
事务ID(从链首到链尾,从最新的版本开始判断),直到找到符合可见性的事务ID。
- 遍历版本链的
- 符合可见性的
事务ID所在的版本,就是当前事务能看见的最新版本。
3)可见性算法(属性)
// MySQL源码分析
class ReadView {
trx_id_t m_creator_trx_id; // 当前事务:创建该Read View的事务id
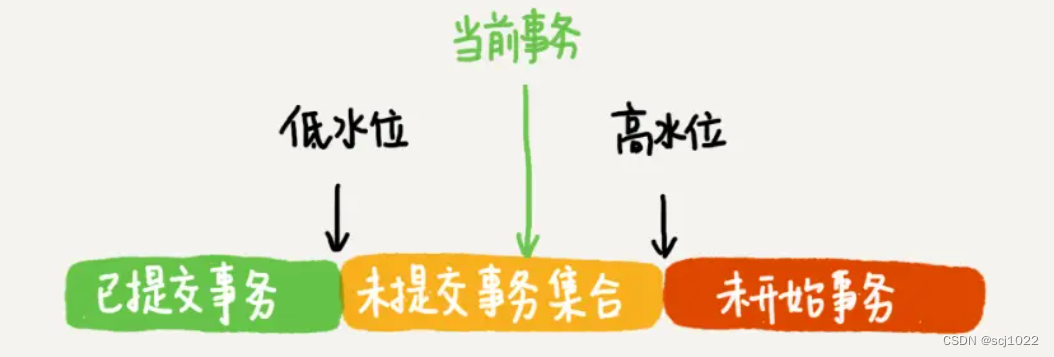
ids_t m_ids; // 未提交事务集合:创建视图时,活跃的事务id列表(活跃 即 未提交)
trx_id_t m_up_limit_id; // 低水位:未提交事务集合中,最小的事务id
trx_id_t m_low_limit_id; // 高水位:当前系统里面已经创建过的事务ID的最大值加1
// 判断事务是否可见的方法
bool changes_visible() {}
// ...
}
4)可见性算法(实现)
在ReadView中, 有一个changes_visible()方法,用于判断某个事务的版本对当前事务是否可见:
// 该函数的作用,就是根据Read View,判断当前事务能否看到这个版本。
// 使用该函数时,将「要访问版本的事务id」传给参数 trx_id_t id
bool changes_visible(trx_id_t id, const table_name_t & name) const
MY_ATTRIBUTE((warn_unused_result))
{
ut_ad(id > 0);
// 事务id < 低水位:要访问版本的事务 在 当前事务生成Read View时 已提交【可见】
// 事务id = 当前事务id:当前事务 在访问它 自己修改过的记录(可见)
if (id < m_up_limit_id || id == m_creator_trx_id) {
return(true);
}
check_trx_id_sanity(id, name);
// 事务id >= 高水位:要访问版本的事务 在 当前事务生成Read View时 未开始【不可见】
if (id >= m_low_limit_id) {
return(false);
}
// 低水位 <= 事务id < 高水位 && 活跃事务id列表为空(即没有未提交的事务了)
// 说明当前事务生成Read View时,要访问版本的事务已经提交了【可见】
else if (m_ids.empty()) {
return(true);
}
// 低水位 <= 事务id < 高水位 && 活跃事务id列表不为空(还有未提交的事务)
// 获取活跃事务id列表 m_ids
const ids_t::value_type* p = m_ids.data();
// 二分查找判断 事务id 是否在 m_ids 中
// 如果在,说明未提交【不可见】
// 如果不在,则已提交【可见】
return (!std::binary_search(p, p + m_ids.size(), id));
}
5)可见性算法(小结)
一个数据版本,对于一个事务 Read View 来说,除了 自己的更新总是可见 以外,有三种情况:
- 事务id < 低水位,事务已提交【可见】
- 事务id >= 高水位,事务未开始【不可见】
- 低水位 <= 事务id < 高水位,看是否属于 活跃事务id列表
- 属于:事务未提交【不可见】
- 不属于:事务已提交【可见】
4、举例说明(版本链)
向 persion 表插入一条新记录
事务1:将插入记录的name修改为Tom
- 事务1开始,数据库先对这一行加 写锁/排他锁。
- 将该行数据拷贝到
undo log中,作为旧记录(即在undo log中有当前行的拷贝副本) - 修改这一行的name为Tom,并修改
事务ID为 当前事务的ID(默认从1开始,之后递增) 回滚指针指向 上一个版本(即拷贝到undo log中的副本记录)- 事务提交,释放锁
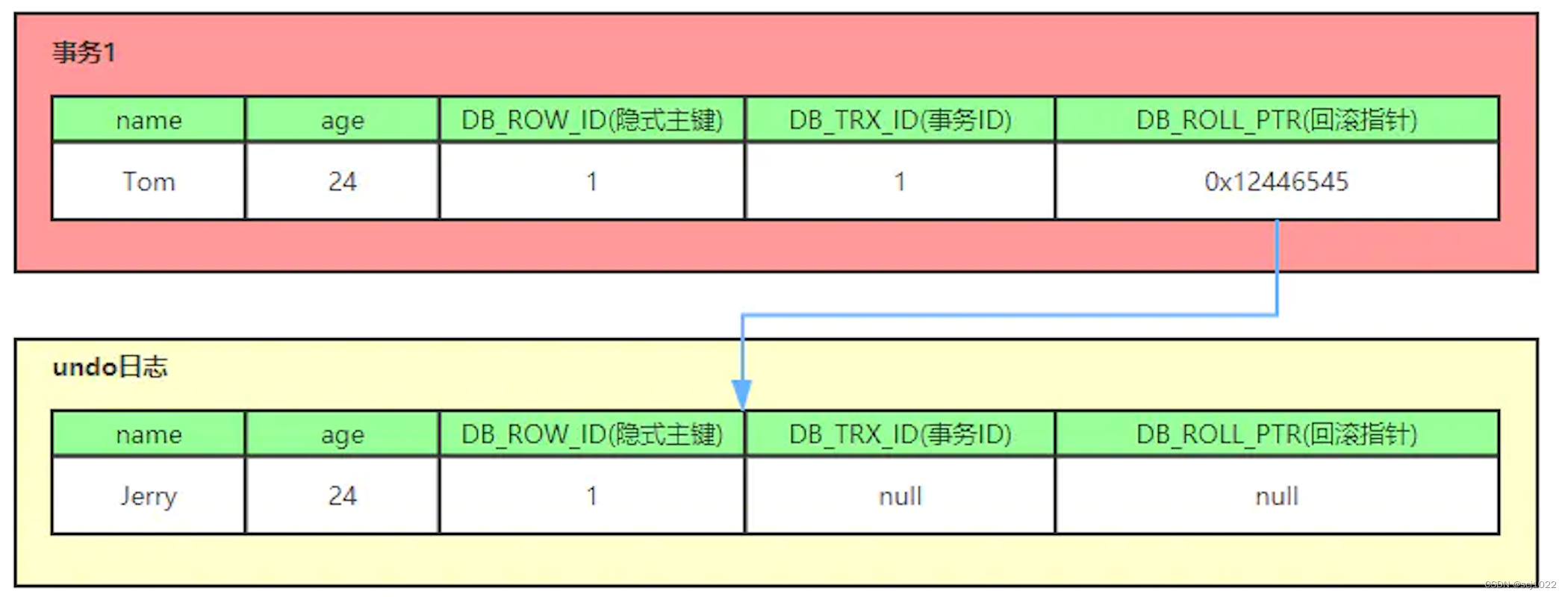
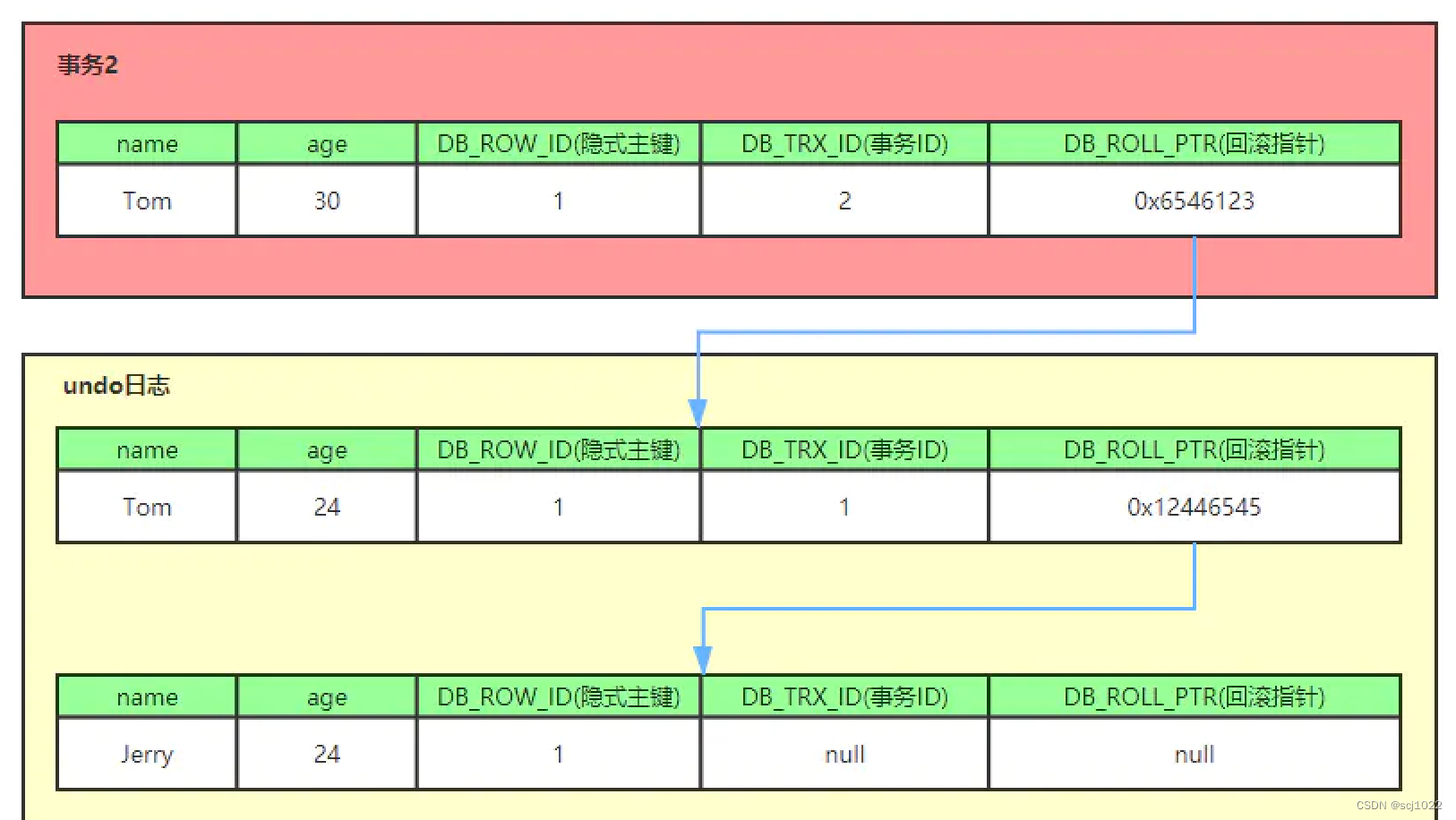
事务2:将插入记录的age修改为30
-
事务2开始,数据库先对这一行加 写锁/排他锁。
-
将该行数据拷贝到undo log中,作为旧记录,
此时发现该行记录已经有undo log了,于是将新产生的log作为链表表头(新表头),指向已存在的undo log(旧表头)
-
修改这一行的age为30,并修改
事务ID为 当前事务的ID(从1自增到2) -
回滚指针指向 上一个版本(即事务ID为1的版本) -
事务提交,释放锁
三、MVCC 与 可重复读 RR
insert into t (id, k) values (1,1), (2,2);

先说结论:事务A查到 k=1,事务B查到 k=3。下面我们来分析一下。
1、事务的启动时机
首先,我们需要注意的是事务的启动时机:
start transaction:开启一个事务,在执行第一个操作InnoDB表的语句(第一个快照读语句),事务才真正启动。start transaction with consistent snapshot:立即启动一个事务,创建一个持续整个事务的一致性快照。
然后,我们看一下图中的案例:
- 事务A:在一个只读事务中查询,并且时间顺序上是在事务B的查询之后。
- 事务B:在更新之后查询,并且时间顺序上是在事务C的更新提交之后。
- 事务C:没有显式地使用begin/commit,表示这个update语句本身就是一个事务,语句完成的时候会自动提交。
2、事务A读取流程
这里,我们不妨做如下假设:
- 事务A开始前,系统里面只有一个活跃事务,事务ID是99;
- 事务A、B、C的事务ID分别是100、101、102,且当前系统里只有这四个事务;
- 三个事务开始前,(1,1)这一行数据的 事务ID 是90。
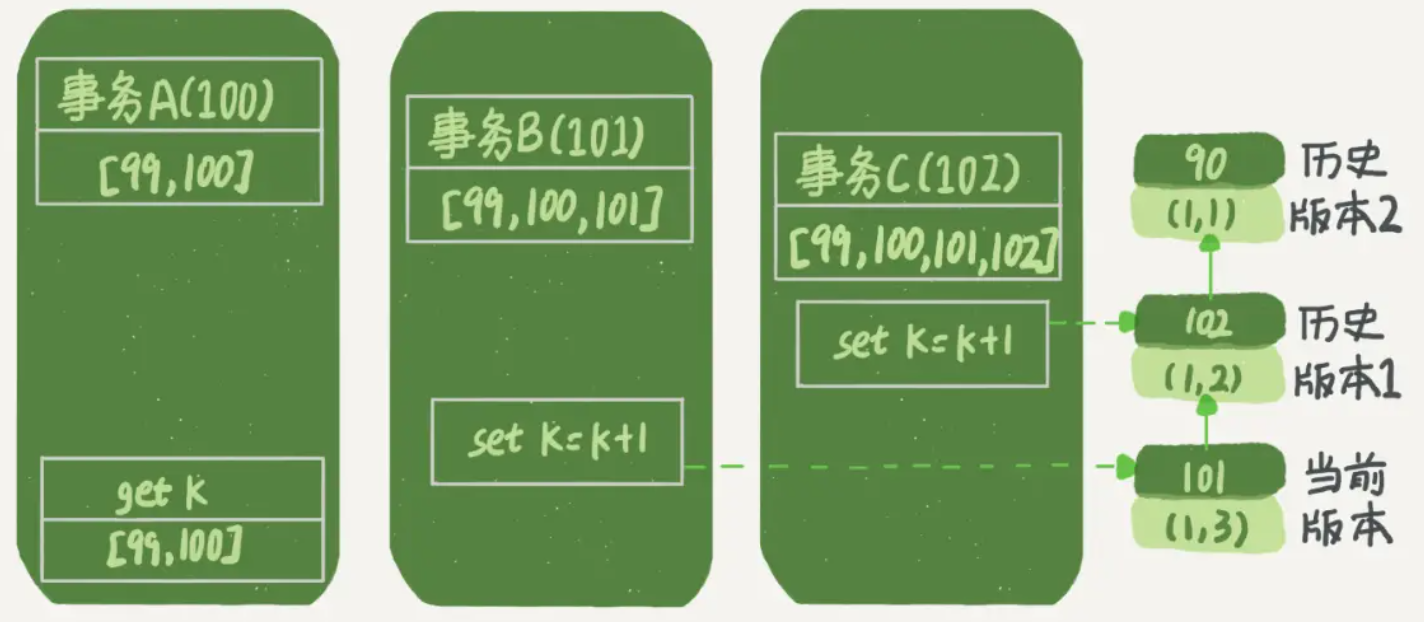
事务A的流程分析:
- 事务A开启事务,活跃数组 [99,100],低水位99,高水位101(此时 事务B 和 事务C 还没开始)
- 事务A读取数据(读数据都是从最新版本读起的)
- 先找到最新版本 (1,3),事务id = 101,等于高水位,处于红色区域,不可见;
- 接着找到上一个版本 (1,2),事务id = 102,比高水位大,处于红色区域,不可见;
- 再找到上一个版本 (1,1),事务id = 90,比低水位小,处于绿色区域,可见。
虽然期间这一行数据被修改过,但是事务A不论在什么时候查询,看到这行数据的结果都是一致的,都是1。
3、更新前 要 当前读
疑问:事务B的视图数组是先生成的,之后事务C才提交,不是应该看不见 (1,2) 吗,怎么能算出 (1,3) 来?
原因:更新数据之前,会先通过当前读读取数据的最新值,然后再写。
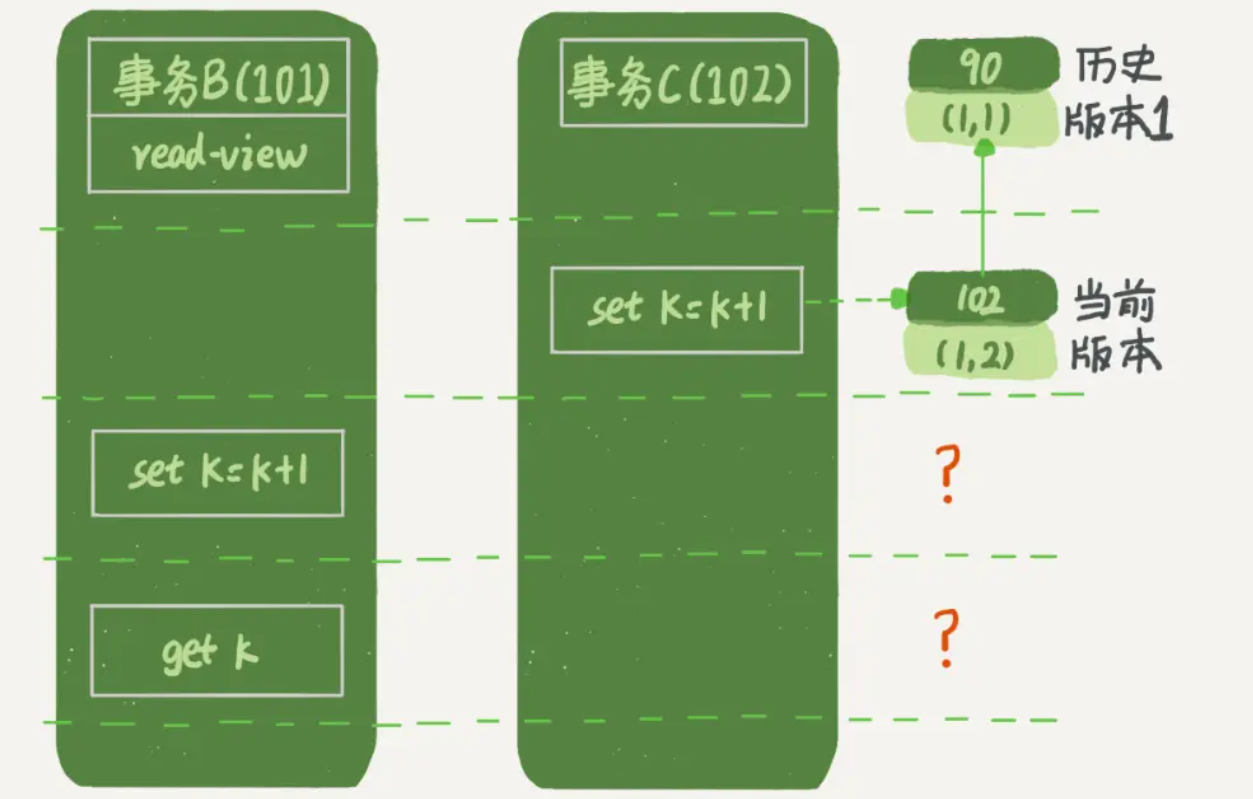
事务B的流程分析:
- 事务B开启事务,活跃数组 [99,100,101],低水位99,高水位102(此时 事务A 已开始未提交,事务C 还没开始)
- 事务B更新数据,先通过
当前读拿到数据 (1,2) ,然后更新为 (1,3),而 (1,3) 这个版本的事务ID 是 101。 - 事务B查询数据(快照读),最新版本(1,3)的事务ID和自己一致,可以直接使用,所以查询到k=3。
4、当前读 遇上 行锁
假设事务C不是马上提交的,而是变成了下面的事务C’,会怎么样呢?

事务C’ 的不同是,更新后并没有马上提交,在它提交前,事务B的更新语句先发起了。
- 虽然事务C’ 还没提交,但是 (1,2) 这个版本也已经生成了,并且是当前的最新版本。
- 事务C’ 没提交,也就是说 (1,2) 这个版本上的写锁还没释放。
- 事务B 是当前读,必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务C’ 释放锁才能继续。
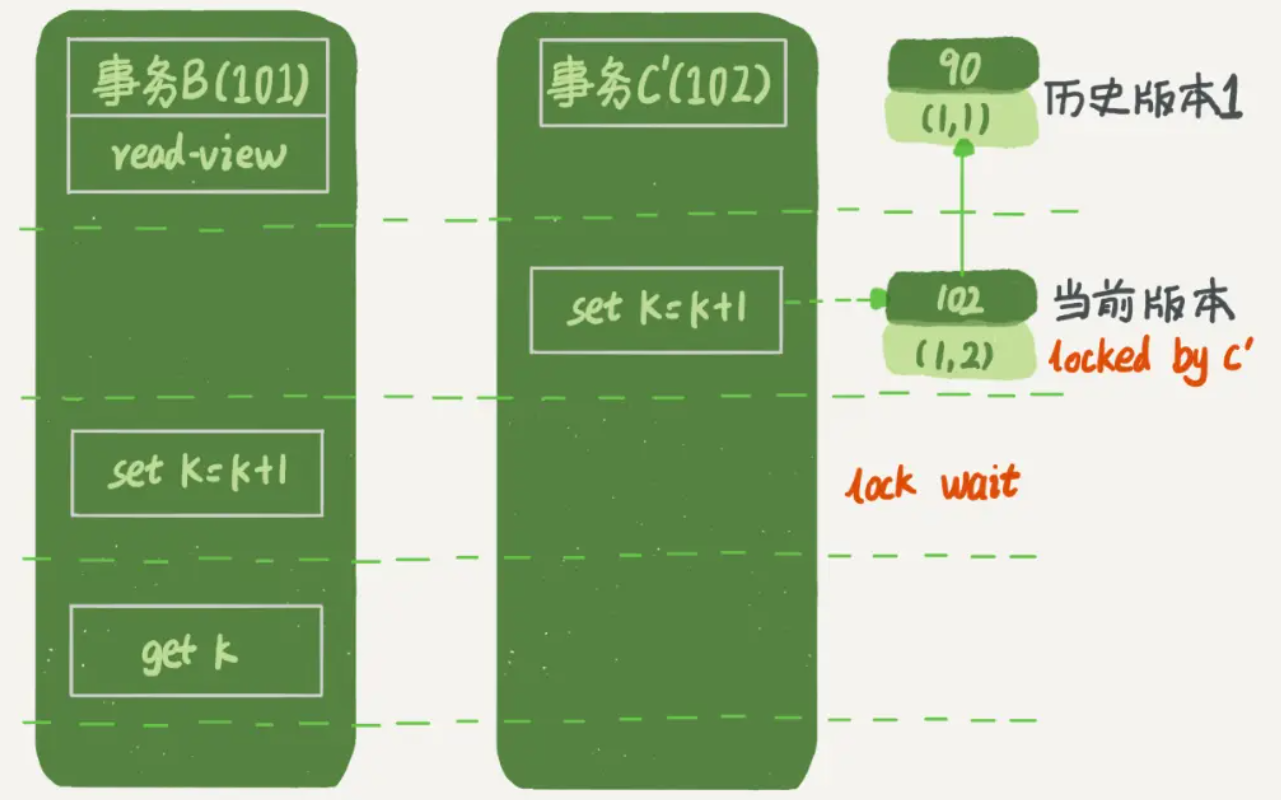
5、小结
现在我们总结一下,事务的可重复读的能力是怎么实现的?
-
事务
第一次查询数据时,会创建Read View,之后事务里的其他查询都共用这个Read View。 -
事务
更新数据时,会先用当前读查询最新的数据,然后进行更新。当前读需要加锁,如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
四、MVCC 与 读已提交 RC
1、Read View 创建时机
读已提交 和 可重复读 的逻辑类似,它们最主要的区别是 Read View 生成的时机:
- 可重复读:
当前事务第一次select时,创建Read View,之后事务里的其他查询都共用这个Read View。 - 读已提交:
每一个select执行之前,都会重新创建一个新的Read View。
2、事务A 读取流程
我们再看一下,在读已提交隔离级别下,事务A和事务B的查询语句查到的k,分别应该是多少呢?
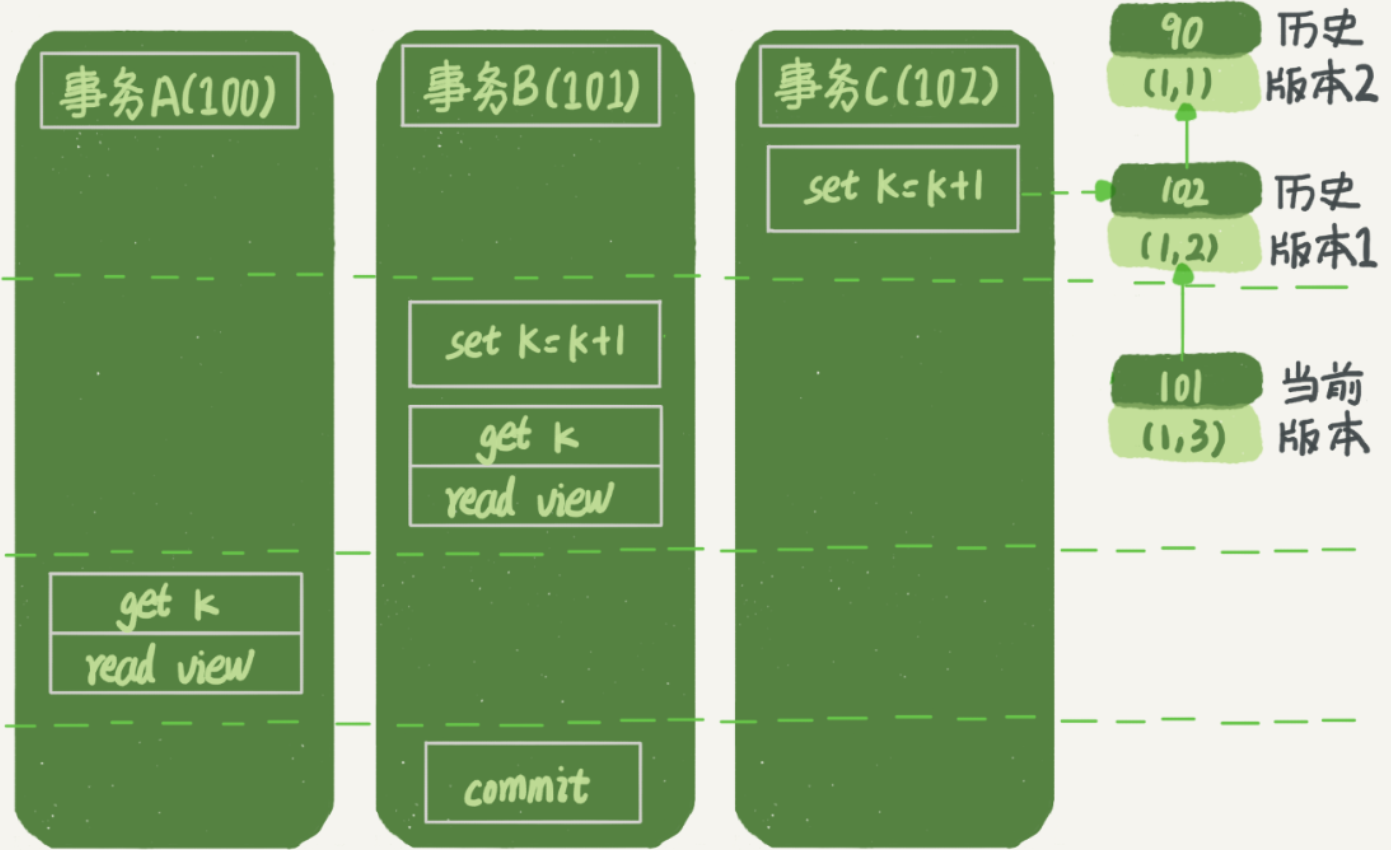
- 对于
可重复读级别,事务A使用的一直是最开始创建的Read View(此时事务B和事务C还未开始) - 对于
读已提交级别,事务A在执行查询之前,又会创建一个新的Read View,此时的执行流程:
事务A的流程分析:
- 事务A开启事务,创建一个Read View,活跃数组 [99,100],低水位99,高水位101(此时 事务B 和 事务C 还没开始)
- 事务A读取数据:
- 查询要创建一个新的Read View:活跃数组 [99,100,101],低水位99,高水位103(事务B开始了未结束,事务C已结束)
- 先找到最新版本 (1,3),事务id = 101,介于低水位和高水位之间 & 属于活跃事务ID列表【不可见】
- 接着找到上一个版本 (1,2),事务ID = 102,介于低水位和高水位之间 & 不属于活跃事务ID列表【可见】
因此事务A的查询结果变为 k=2,事务B的查询结果还是 k=3。
五、MVCC 与 幻读
1、案例
insert into student (id,name) values (1,'张三');
| 事务A | 事务B |
|---|---|
start transaction with consistent snapshot; | |
select * from student where id >= 1; | |
start transaction with consistent snapshot;insert into student (id,name) values (2,'李四');insert into student (id,name) values (3,'王五');commit; | |
select * from student where id >= 1; | |
commit; |
假设:
- 事务A 和 事物B 开始之前,(1,‘张三’) 这行数据的 事务id=10
- 事务A 的 事务id = 20,事务B 的 事务id = 30
2、案例分析 - 可重复读
可重复读级别,不会重新生成 ReadView,用的还是原来的:活跃事务数组 [20],低水位 20 ,高水位21(事务B还没开始)
- id为2、3的数据,事务id=30,大于高水位【不可见】
- id为1的数据,事务id=10,低于低水位【可见】
结论:在可重复读级别,快照读不存在幻读问题。
3、案例分析 - 读已提交
读已提交级别,会重新生成 ReadView:活跃事务数组 [20] ,低水位 20 ,高水位31(事务B已经结束)
- id为2、3的数据,事务id=30,介于低水位和高水位之间 & 不在视图数组中【可见】
- id为1的数据,事务id=10,低于低水位【可见】
结论:在读已提交级别,快照读也存在幻读问题。
4、结论
- 在
可重复读级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在当前读下才会出现。 - 在
读已提交级别下,快照读也存在幻读的问题。
















 2724
2724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











