







我现在遇到的场景:有n多个数据库,其中有的是单库分表的,有的是单库单表,现在要在一个服务上集成所有的库,多数据源是必不可少的,但是单库分表的多数据源还是第一次遇到,sharding-jdbc是一个优秀的分表中间件,如果大家不知道sharding-jdbc怎么使用的话,可以自行了解,网上的资料很多, 今天我们就是用它来完成我们的需求
- 搭建mybatis plus的多数据源配置
- 集成sharding-jdbc的jar
- 完成sharding-jdbc的多数据源配置
- 结果展示
1. 搭建mybatis的多数据源配置
加载mybatis plus的maven配置 我是用的版本是3.0.7
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis.version}</version>
</dependency>
然后在我们的yaml文件中配置上我们连接数据库的连接,例如:
xxx.datasource.url=jdbc:mysql://xxx:3306/xxx?useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&zeroDateTimeBehavior=convertToNull
xxx.datasource.username=root
xxx.datasource.password=xxx
xxx.datasource.driverClassName=com.mysql.jdbc.Driver
2. 集成sharding-jdbc的jar
配置maven 我是的版本是4.0.0
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
3. 完成sharding-jdbc的多数据源配置
@Configuration
@MapperScan(basePackages = "com.xxx.xxx.dao.community", sqlSessionFactoryRef = "shardingSqlSessionFactory")
public class ShardingDataSourceConfig {
@Value("${xxx.datasource.url}")
private String url;
@Value("${xxx.datasource.username}")
private String user;
@Value("${xxx.datasource.password}")
private String password;
@Value("${xxx.datasource.driverClassName}")
private String driverClass;
@Autowired
private PaginationInterceptor paginationInterceptor;
@Bean(name = "communityDataSource")
public DataSource dataSource() throws SQLException {
return mybatisDataSource();
}
//分表算法
@Resource
private MyPreciseShardingAlgorithm myPreciseShardingAlgorithm;
private DataSource mybatisDataSource() throws SQLException {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
/* 配置初始化大小、最小、最大 */
dataSource.setInitialSize(1);
dataSource.setMinIdle(1);
dataSource.setMaxActive(20);
/* 配置获取连接等待超时的时间 */
dataSource.setMaxWait(60000);
/* 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 */
dataSource.setTimeBetweenEvictionRunsMillis(60000);
/* 配置一个连接在池中最小生存的时间,单位是毫秒 */
dataSource.setMinEvictableIdleTimeMillis(300000);
dataSource.setTestWhileIdle(true);
dataSource.setTestOnBorrow(false);
dataSource.setTestOnReturn(false);
/* 打开PSCache,并且指定每个连接上PSCache的大小。
如果用Oracle,则把poolPreparedStatements配置为true,
mysql可以配置为false。分库分表较多的数据库,建议配置为false */
dataSource.setPoolPreparedStatements(false);
dataSource.setMaxPoolPreparedStatementPerConnectionSize(20);
/* 配置监控统计拦截的filters */
dataSource.setFilters("stat,wall");
return dataSource;
}
//创建数据源,需要把分库的库都传递进去
//@Bean("dataSource")
@Bean("dataSource")
public DataSource dataSource(@Qualifier("xxxDataSource") DataSource xxx) throws SQLException {
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
dataSourceMap.put("xxx", xxx);
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
//如果有多个数据表需要分表,依次添加到这里
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
// shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
Properties p = new Properties();
p.setProperty("sql.show", Boolean.TRUE.toString());
// 获取数据源对象
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, p);
return dataSource;
}
// 创建SessionFactory
@Bean(name = "shardingSqlSessionFactory")
public SqlSessionFactory shardingSqlSessionFactory(@Qualifier("dataSource") DataSource dataSource) throws Exception {
MybatisSqlSessionFactoryBean sessionFactory = new MybatisSqlSessionFactoryBean();
sessionFactory.setDataSource(dataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/xxx/*.xml"));
sessionFactory.setPlugins(new Interceptor[]{paginationInterceptor});
return sessionFactory.getObject();
}
// 创建事务管理器
@Bean("shardingTransactionManger")
public DataSourceTransactionManager shardingTransactionManger(@Qualifier("dataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
// 创建SqlSessionTemplate
@Bean(name = "shardingSqlSessionTemplate")
public SqlSessionTemplate shardingSqlSessionTemplate(@Qualifier("shardingSqlSessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
private TableRuleConfiguration getOrderTableRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration("aaa","bbb.aaa_$->{0..99}");
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("aaa_id",myPreciseShardingAlgorithm));
return result;
}
}
我来解释一下关键部分的代码
TableRuleConfiguration result = new TableRuleConfiguration("aaa","bbb.aaa_$->{0..9}");
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("aaa_id",myPreciseShardingAlgorithm));
这是sharding-jdbc配置的关键所在,“aaa”,“bbb.aaa_$->{0…99}”: aaa表示分表的逻辑名称,bbb表示数据库,{0…99}这段代码的表示aaa_0至aaa_9十个表,aaa_id 表示分片键,myPreciseShardingAlgorithm是我自己实现的分片算法
#实现sharding-jdbc的精确分片算法的接口
public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {
return shardingValue.getLogicTableName()+"_"+shardingValue.getValue() % 10 + "";
}
}
从shardingValue中可以获取到逻辑表名称和aaa_id,算法可以自己去实现,体现sharding-jdbc很灵活
4. 结果展示
结果日志打印出来了,我这里可以从其他表获取所有的分片键,所以用到了分片算法,相对来说,快了一下,但是如果没有用到分片键,就要全表扫描了
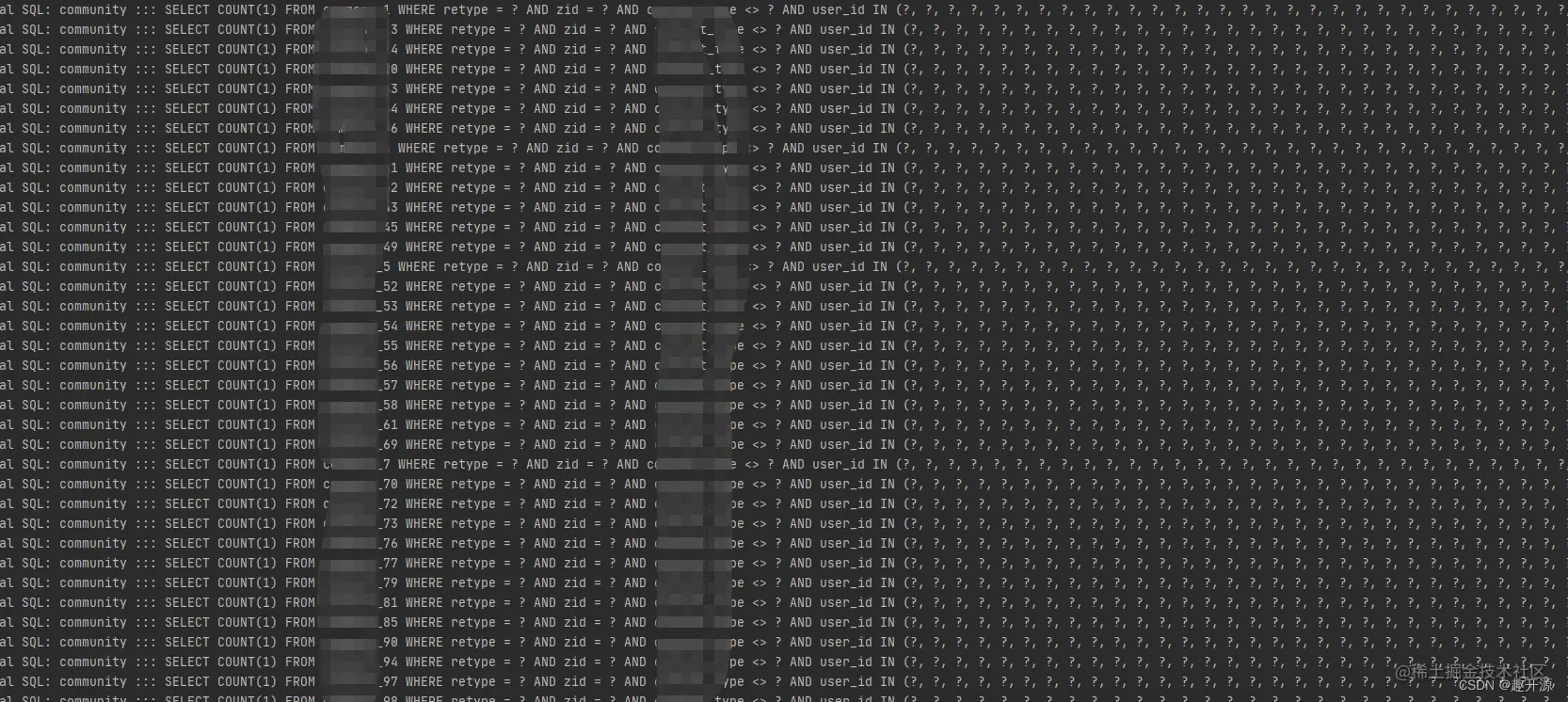
希望可以帮助到跟我遇到同样问题的同学,这个方式肯定没问题,如果有问题,可以给我留言















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









