







Webkit CSS引擎分析
浏览器CSS模块负责CSS脚本解析,并为每个element计算出样式。CSS模块虽小,计算量大,设计不好往往成为浏览器性能的瓶颈。CSS模块在实现上有几个特点:CSS对象众多(颗粒小而多),计算频繁(为每个element计算样式)。这些特性决定了webkit在实现CSS引擎上采取的设计,算法。如何高效的计算样式是浏览器内核的重点也是难点。
- 前端工程师可能更关注:
- 能被浏览器高效执行的CSS脚本
- 浏览器内核工程师可能更关注:
- CSS内部数据的组织
- 计算样式
- 思考
- 总结
高效执行的CSS脚本
我这里仅从webkit执行的性能上来讲高效的CSS,不涉及CSS设计问题。
- 使用id selector非常的高效。在使用id selector的时候需要注意一点:因为id是唯一的,所以不需要既指定id又指定tagName。例如:
- Bad
- p#id1 {color:red;}
- Good
- #id1 {color:red;}
- 使用class selector的策略与id selector一样。在内核实现上,id selector与class selector的匹配并没有多大的区别。如果同一个class需要赋予不同的css,你可以这样做
- Bad
- p.class1 {color:red;}
- div.class1 {color:black;}
- Good
- p-class1{color:red;}
- div-class1{color:black;}
当然这样会造成网页中的className增多。具体您决定怎么取舍。
有时要选择的node比较深时,我们可以采取如下写法:
- Bad
- div > div > div > p {color:red;}
- Good
- p-class{color:red;}
ChildSelector的匹配比较的慢。 - 不到万不得已,不要使用attribute selector。例如:p[att1="val1"]。这样的匹配非常慢。更不要这样写:p[id="id1"]。这样将id selector退化成attribute selector。
- Bad
- p[id="id1"]{color:red;}
- p[class="class1"]{color:red;}
- Good
- #id1{color:red;}
- .class1{color:red;}
- 依赖继承。如果某些属性可以继承,那么自然没有必要在写一遍。
- 其他的selector在内核实现上很难做出优化,所以如果可以的话尽量不用。
Webkit CSS模块实现
这里我更多的希望分享我实际开发CSS中所碰到的一些问题,透过这些问题来看webkit的设计也许更有体会。
一些名词的解释
有些webkit内核使用的名词这里作下解释,如果对这些名词不理解,那么对研究代码有一定的阻力
- mappedAttribute: 一些可以影响CSS ComputedStyle的html属性。
举个例子:<p align="middle">paragraph</p>那么属性align="middle"就叫做mappedAttribute。一般大家都知道每个Element有个inlineStyleDeclaration,实际上还有个隐含的Declaration叫MappedStyleDeclaration.他的优先级比普通的CSS高,比inlineStyle要低。 - renderStyle:这就是大家熟悉的ComputedStyle在webkit中的表示。
- bloom filter:一种算法。没接触过的可以网上搜索。
CSS内部数据的组织
这里不想画一些css对象的继承图。对象继承图可以参考这篇文章。并且我假设读者已经熟知CSS相关规范,概念。
解析完CSS脚本后,会生成CSSStyleSheetList,他保存在Document对象上。为了更快的计算样式,必须对这些CSSStyleSheetList进行重新组织。(思考,你能直接从CSSStyleSheetList上计算样式吗?)
计算样式就是从CSSStyleSheetList中找出所有匹配相应元素的property-value对。匹配会通过CSSSelector来验证,同时需要满足层叠规则。
一种简单但效率偏低的组织方式,暂且称之为数组模型。将所有的declaration中的property组织成一个大的数组。数组中的每一项纪录了这个property的selector,property的值,权重(层叠规则)。例如:
- <style>
- p > a{color:red; background-color:black;}
- a {color:yellow}
- div{margin:1px;}
- </style>
- 重新组织之后的数组数据为(weight我只是表示了他们之间的相对大小,并非实际值。):
- selector property weight
- 1, a color:yellow 1
- 2, p > a color:red 2
- 3, p > a background-color:black 2
- 4, div margin:1px 3
可以看到每一个property成为数组的一项。相同的tagName在数组中的位置相邻,譬如selector a 和selector p > a在数组中相邻。所有的property以selector的tagName顺序存放。有了这样的数组组织,你可以想想了,该如何计算样式呢? 一种高效的组织方式,暂且称之为hash模型。
webkit使用CSSRuleSet对象来组织这些数据。CSSRuleSet是这样一个对象:他内部有4个hash表,分别为idRules, classRules, tagNameRules, universalRules。
这些hash表的定义是这样的:HashMap<String*, CSSRuleDataList*>
CSSRuleDataList是一个list,其总每一项为CSSRuleData。
CSSRuleData保存了一个css的styleRule,以及这个styleRule的selector的specificity(可以理解成权值)。在CSSRuleData的constructor中会计算selector的bloom filter值。
下图为一个粗略的图示,我并没有完整的画出各个类的定义,但已经可以帮助我们理解这些类的关系: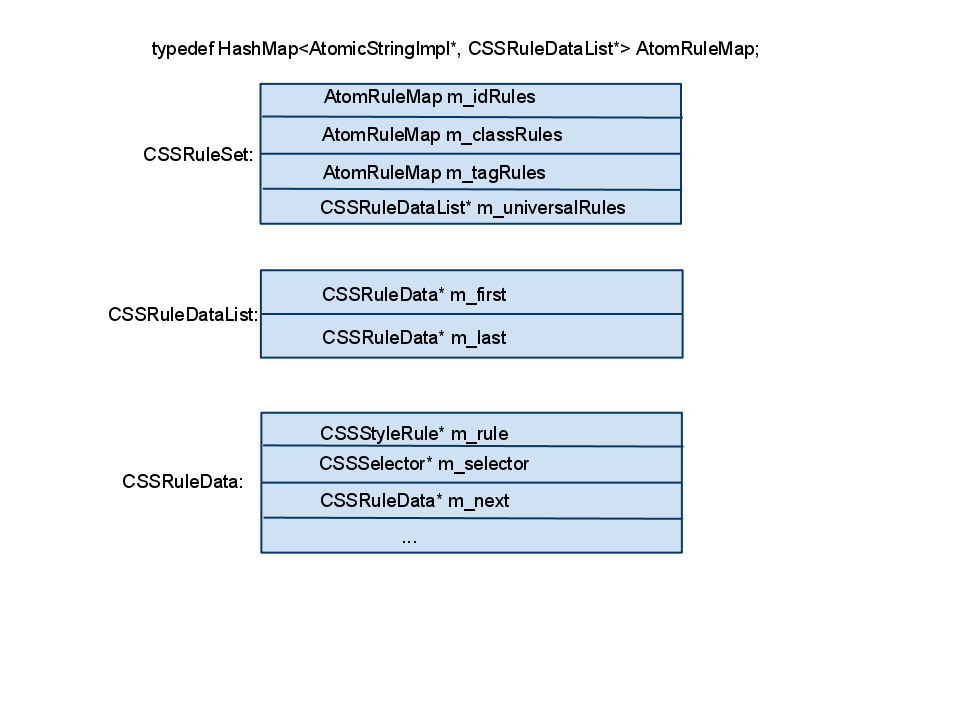
- 将default stylesheet, userstylesheet, authorstylesheet存放在不同的CSSRuleSet上。而数组模型会将所有的stylesheet组织到一个数组中。不要小瞧这步动作,这已经让我眼前一亮,他关系到后面的匹配算法部分。
- 每个CSSRuleSet将所有的stylerule分别组织到idRules, classRules, tagNameRules, universalRules。譬如:
- #id1{color:red;} -->存放在idRules中。
- .class1{color:red;} -->存放在classRules中。
- .class1{color:red;} -->同上。
- p{color:red;} -->在tagNameRules中。
- *{color:red;} -->在universalRules中。
- 内核在在当前所有的stylesheet都已经请求结束,CSS parser结束之后进行组织数据这个动作。
计算样式
样式的计算如果设计的不当,直接影响浏览器内核的性能,所以这里的算法值得大家仔细的分析。
- 将default stylesheet, user stylesheet, author stylesheet组织成一个大的数组之后。要匹配一个标签,譬如:
- <p><a href="#">link</a></p>
- 计算标签a的样式:
因为数组的tagName是顺序的,所以可以使用二分查找法,找到a的开始位置和结束位置,此时为1-->3. - 针对数组的每一项进行check selector,如果check selector成功,存放在结果数组中。
- 将匹配的结果存放在结果数组中的时候,需要判断结果数组中是否已经有了该property,如果已经存在则需要比较这两个property的权值,如果新的property权重大于老的,那么需要替换数组中的这一项。
- 对数组中所有tagName为universaltagName进行匹配。重复2-3。
总结:可以看到该算法需要匹配所有tagName相同的项,以及所有universaltagName。在checkselector成功之后插入结果数组中,还需要判断是否已经存在了该property。
还有一个更严重的问题,该算法在checkselector的时候,没有保存匹配的selector的相关信息,为以后的局部更新带来了非常多的不确定性问题,导致局部排版无法判断是否需要重排。对比webkit存在非常多的动作来将不确定的因素确定化,来优化排版所需要的动作。
Vector<const RuleData*, 32> m_matchedRules;
- 首先判断该element是否存在可以共享的renderStyle。是否可以共享的条件较多,这里不详述,粗略的可以参看这里。但这个策略非常非常棒,网页中能共享的标签非常多,所以能极大的提升执行效率!如果能共享,那就不需要执行匹配算法了,执行效率自然非常高。
我在对www.sina.com.cn的测试中, 17864次计算样式,有4764次共享。将近27%的计算样式的过程不需要进行,意味着此处性能提高约27%左右!该网站共有9686个node,3412个element。 - 依次匹配default StyleSheet , user StyleSheet, author StyleSheet,并将结果存放在结果数组中。并记录各种stylesheet匹配结果在结果数组中的起始位置。
- 每一个StyleSheet匹配的算法:
- 如果该Element有id属性,那么从CSSRuleSet的id hash table中取出相应的CSSRuleDataList
- 依次测试CSSRuleDataList中的每一项CSSRuleData。这里首先会利用bloom filter算法过滤掉不符合条件的CSSStyleRule。
- 在check selector过程中,如果匹配成功将其加入到结果数组中。
- 根据权值对结果数组进行排序。
- 如果该Element有class属性,那么从CSSRuleSet的class hash table中取出相应的CSSRuleDataList。重复执行步骤2-->步骤4
- 根据Element的tagName,从CSSRuleSet种取出tagName对应的CSSRuleDataList,重复步骤2-->步骤4.
- 对所有universaltagName的CSSRuleDataList重复步骤2-->步骤4.
上述步骤生成结果数组的算法流程图如下:

- 得到了所有匹配的stylerule之后,需要根据这个结果生成renderstyle。算法步骤如下图,请看图的时候注意两个问题:
- 如何体现层叠规则中不同样式表的权重。
- 如何体现同一个样式表中相同的property,相同的权重,后面的覆盖前面的。
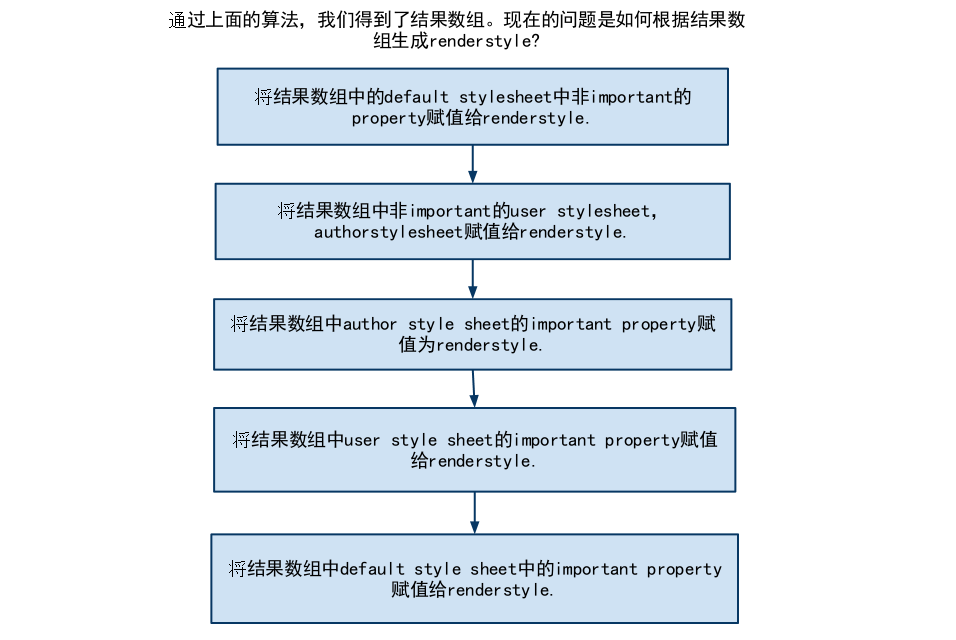
一些思考题
在这一篇文档中实在很难将一个内核模块的所有问题阐述清楚,所以我这里列举一些问题供大家讨论学习。这些问题也是我在实际工具做所碰到一些具体问题,没有实际开发过CSS模块很难体会到这些问题,而且webkit对这些问题处理的很好,给了我很多启发。
- 如果style标签写在了body区域,webkit在解析完这个style标签如何做呢?style标签写在了body区域好吗?
- :hover伪类在CSS应用很广泛,想想浏览器内核该怎么做?需要在一个element收到hover状态的时候,重新计算css吗?
- CSS对象粒度小但数目大,大到CSSStyleSheetList,小到一个CSSValue都要使用CSS对象来表示。而CSS文档又比较大,这样内存会不会碎片太多?
- CSS对象粒度小但数目大,重复分配释放除了碎片大,也很花费时间,想想有什么好办法吗?考虑自己管理CSS对象的内存?
- CSS对象粒度小但数目大,这些小粒度对象能共享吗?设计模式里有个Flyweight模式,CSS里有很好体现。
- 一个Element的class属性或者id属性变了,需要重新计算renderstyle以看是否需要重排这个Element。我们知道有sibling selector
p.class1 + a那是不是这个改变了属性的Element的所有兄弟都需要重新计算renderstyle或者说重新排版呢? - 有:first-child伪类,那是不是意味着往父亲节点中插入一个头结点,所有的孩子都需要重排呢?因为他们可能有:first-child selector。webkit怎么做呢?
- css value中有个值为inherit,表示使用他的parent的属性值。如果他的parent的属性值变了呢,孩子的值如何更新?
- 这篇文章对bloom filter算法在css中应用讲的不多,但这也确实对CSS check selector进行了不少的优化。有兴趣的读者可以参考以下三点去看webkit源码:
- 在生成CSSRuleData对象的时候,有bloom filter数据生成。
- 在parse html的时候,每个element的beginParsingChildren事件中会更新bloom filter。
- 在matchRulesForList的时候,方法fastRejectSelector就是过滤发生的地方。
- computedStyle记录了每个Element的所有的property的值,浏览器排版引擎会非常频繁的从computedStyle中取出某个property的值,将computedStyle设计成一个数组可以吗?webkit使用renderStyle这个对象来表示computedStyle,这个对象在设计上有什么优点?重点应关注两点:
- 这个对象比数组的形式节省了非常多的内存。
- 这个对象比数组的形式节省了非常多的检索时间。
总结
CSS引擎做的事情非常少(解析和计算样式),往往被大家忽略,但要设计出灵活高效的CSS引擎确实不易。通过剖析webkit CSS的实现,经常有些设计的亮点让我激动很久,所以不要忽略webkit css模块,他会给你惊喜!















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









