









XPath是XML路径语言,它是用来确定xml文档中所部分位置的语言。
xml文档(爬虫抓取下来的html也属于xml)是由一系列节点构成的数,例如:
<html>
<body>
<div >
<p>Hello world<p>
<a href="/home">Click here</a>
</div>
</body>
</html>一、xml文档的节点类型
xml文档的节点类型常见有以下几种:
根节点:文档的最底层节点
元素节点: 一个元素的开始标签、结束标签,以及开始标签和结束标签之间的全部内容整体称为元素节点,如示例中的html、body、div、p、a
属性节点:元素节点中的属性为属性节点,属性节点包括属性名和属性值两个部分,如示例中的href属性名,/home属性值
文本节点:标签间的文本内容,如示例中的Hello world、Click here
节点之间存在几种关系:
父子:如示例中的,body是html的子节点,p和a是div的子节点。反过来,div是p和a的父节点
兄弟:p和a为兄弟节点
祖先/子孙:body、div、p、a都是html的子孙节点;反过来html是body、div、p、a的祖先节点
二、Xpath的常用语法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
XPath路径包括一个或多个步骤组成,每个步骤之间使用“/”分割。
Xpath的常用语法如下:
/ 选中文档的根
. 选中当前节点
.. 选中当前节点的父节点
ELEMENT 选中子节点中所有ELEMENT元素节点
//ELEMENT 选中后代节点中所有ELEMENT元素节点
* 选中所有元素子节点
text() 选中所有文本子节点
@ATTR 选中名为ATTR的属性节点
@* 选中所有属性节点
[谓语] 通过谓语来查找某个特定节点或包含报个特定值的节点
三、Xpath使用实例
示例HTML文档
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: Image 1 <br/><img src='image1.jpg' /></a>
<a href='image2.html'>Name: Image 2 <br/><img src='image2.jpg' /></a>
<a href='image3.html'>Name: Image 3 <br/><img src='image3.jpg' /></a>
<a href='image4.html'>Name: Image 4 <br/><img src='image4.jpg' /></a>
<a href='image5.html'>Name: Image 5 <br/><img src='image5.jpg' /></a>
</div>
</body>
</html>使用python的scrapy库进行测试(与后续爬虫处理保持一致)
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
body = '''<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: Image 1 <br/><img src='image1.jpg' /></a>
<a href='image2.html'>Name: Image 2 <br/><img src='image2.jpg' /></a>
<a href='image3.html'>Name: Image 3 <br/><img src='image3.jpg' /></a>
<a href='image4.html'>Name: Image 4 <br/><img src='image4.jpg' /></a>
<a href='image5.html'>Name: Image 5 <br/><img src='image5.jpg' /></a>
</div>
</body>
</html>'''
response = HtmlResponse(url='http://www.example.com', body=body, encoding='utf8')
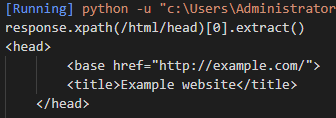
(1)从根节点开始找到head元素节点(绝对路径)
Xpath表达式:/html/head
(2)选择文档中所有div元素节点下的所有a元素节点
Xpath表达式://div/a

(3)选择body后代中的所有img
Xpath表达式:/html/body//img

(4)选择所有a元素节点的文本
Xpath表达式://a/text()

(5)选中div元素节点的所有子孙节点
Xpath表达式:/html/body/div//*

(6)选择div孙节点中的所有img元素节点
Xpath表达式://div/*/img

(7)选中所有img元素节点的src 属性
Xpath表达式://img/@src

(8)选中所有的href 属性
Xpath表达式://@href

(9)选择第一个a元素节点下的img元素节点的所有属性
Xpath表达式://a[1]/img/@*

(10)相对路径使用
sel = response.xpath('//a')[0]
定位到:<a href='image1.html'>Name: Image 1 <br/><img src='image1.jpg' /></a>
sel.xpath('.//img')
定位到:<img src='image1.jpg' />
(11)选中所有a元素节点中的第3 个
Xpath表达式://a[3]

(12)使用last函数,选中所有a元素节点中的最后1 个
Xpath表达式://a[last()]

(13)使用position函数,选中所有a元素节点中的前3 个
Xpath表达式://a[position()<=3]

(14)选中所有含有id属性的div
Xpath表达式://div[@id]
(15)选中所有含有id属性且值为"images"的div
Xpath表达式://div[@id="images"]

四、Xpath函数
Xpath还提供了许多函数,如数字、字符串、时间、日期、统计等。前面介绍了函数position()、last()。这里再介绍下string、contains函数
string(arg):返回参数的字符串值
text='<a href="#">Click here to go to the <strong>Next Page</strong></a>'
sel = Selector(text=text)
print(sel.xpath('/html/body/a//text()').extract())
print(sel.xpath('string(/html/body/a)').extract())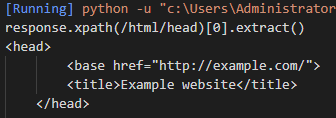
contains(str1, str2):判断str1中是否包含str2,返回布尔值
text ='<div><p class="small info">hello world</p><p class="normal info">hello scrapy</p></div>'
sel = Selector(text=text)
print(sel.xpath('//p[contains(@class, "small")]'))
print(sel.xpath('//p[contains(@class, "info")]'))


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











