









 本文介绍如何使用PowerBI进行简单的页面数据爬取,以豆瓣Top250电影排行榜为例,详细说明了分析URL规律、网页结构、获取数据、构建爬虫函数及页码列表的过程。
本文介绍如何使用PowerBI进行简单的页面数据爬取,以豆瓣Top250电影排行榜为例,详细说明了分析URL规律、网页结构、获取数据、构建爬虫函数及页码列表的过程。
对于简单的页面数据爬取,其实使用PowerBI就可以可视化直接实现了,不需要另外写爬虫程序。本文以爬取豆瓣Top250电影排行榜示例说明下操作的基本过程。
一、分析URL规律及网页结构
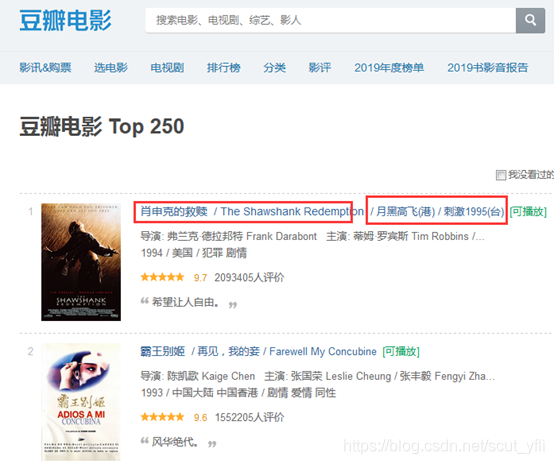
打开豆瓣电影Top 250 页面:https://movie.douban.com/top250
观察每页有25部电影,总共10页
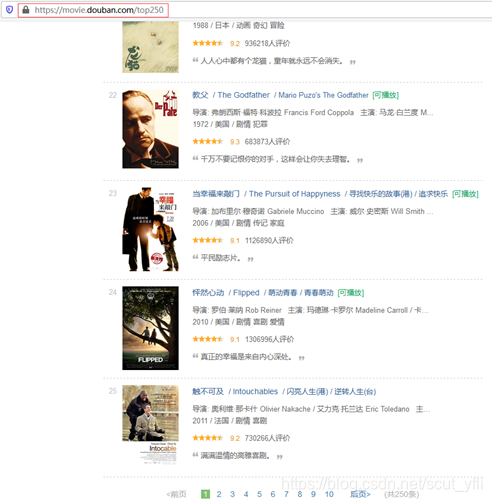
观察第二页开始,URL的变化
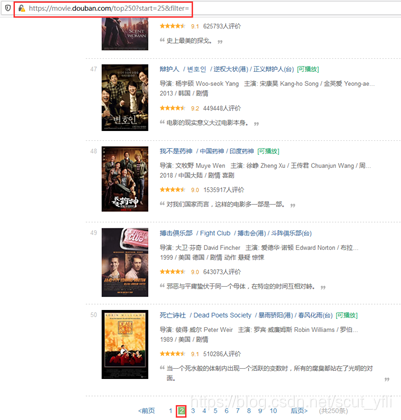
第二页https://movie.douban.com/top250?start=25&filter=
第三页https://movie.douban.com/top250?start=50&filter=
……
每一页请求的URL带上参数start=25*(页数-1)即可
二、获取数据示例
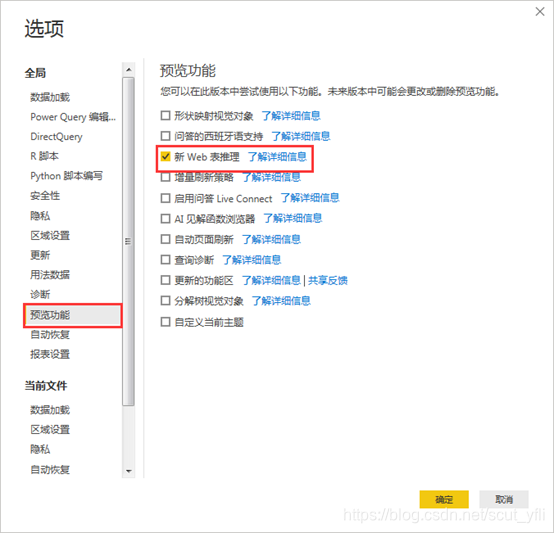
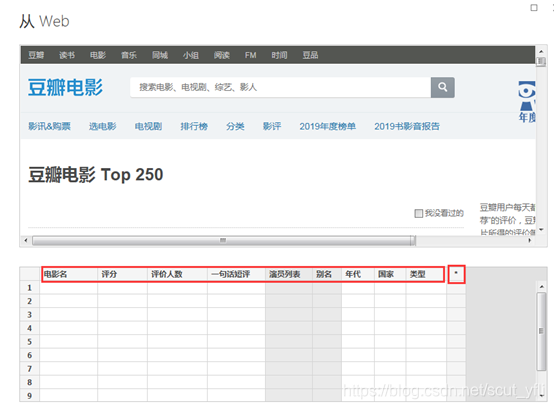
首先需设置预览功能:打开文件—选项,勾选新web表推理
输入URL地址https://movie.douban.com/top250?start=0&filter=
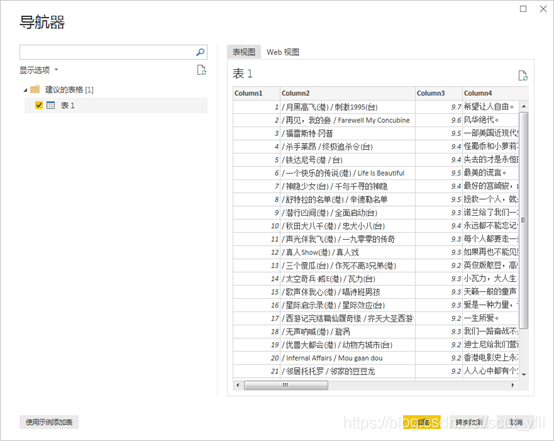
PowerBI已经初步识别了页面的数据
但是发现识别的数据不太准确,需要修改,点击“使用示例添加表”进去手动识别调整
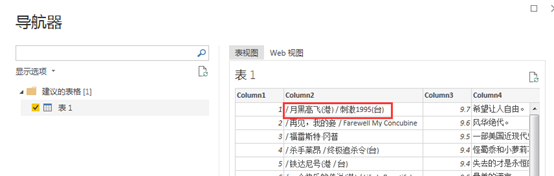
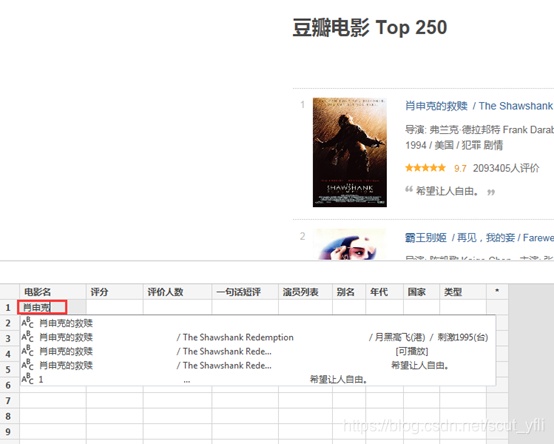
比如我们发现PowerBI自动识别的第2列“电影名”不对,只识别了其中一部分
新增我们需要爬取的列
在单元格输入我们需要爬取的类型,PowerBI就会自动识别
输入完后,发现第二行不是应是霸王别姬,但是没有识别出来。
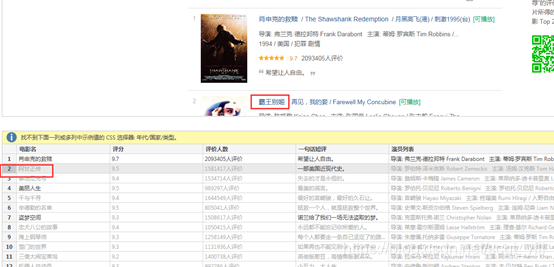
插入第二行,帮助系统识别规律。
同理,检查其他行、列。
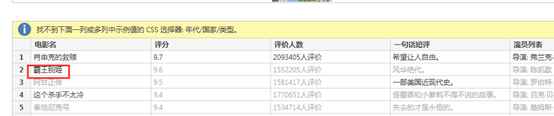
注意到界面一直提示“找不到下面一列或多列示例值得CSS选择器:年代/国家/类型”
相关数据PowerBI提取不出来,原因是想要的这个数据,并不能用CSS表达式选择得出来
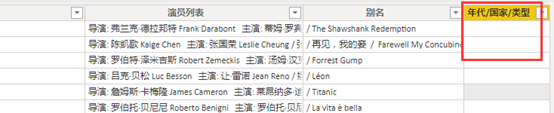
使用火狐浏览器检查下,并不能提取到CSS表达式。因此这类问题只能另想办法了,比如扩大范围抓取了,后续再做数据整理。
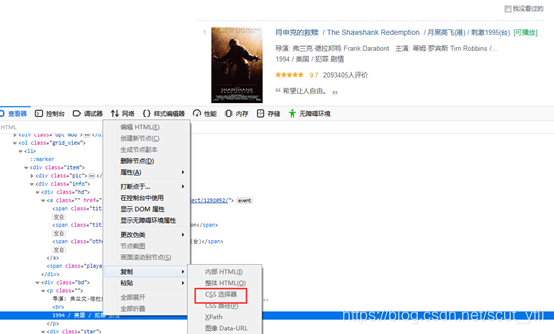
三、构建爬虫函数
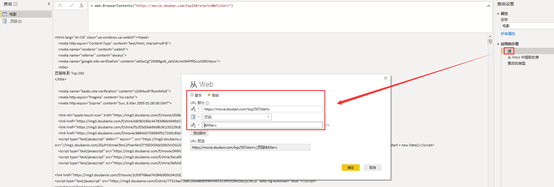
进去Power Query后台,对查询新建页码参数
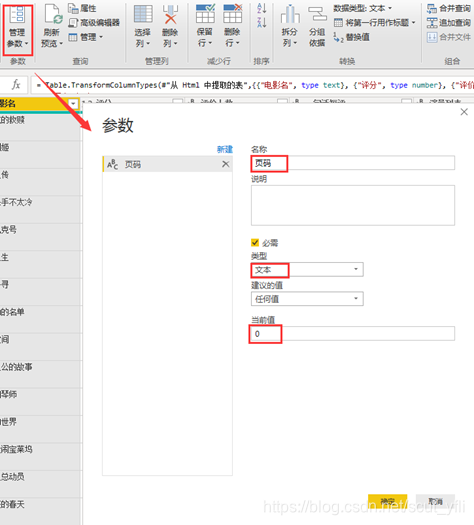
将页码参数插入URL
设置源,将URL拆分成三段,为:
https://movie.douban.com/top250?start=
页面
&filter=
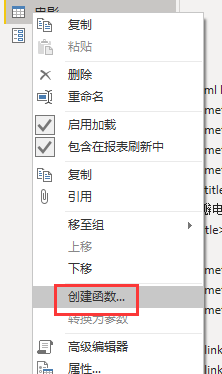
创建函数:对电影查询,右键创建函数

四、构建页码列表
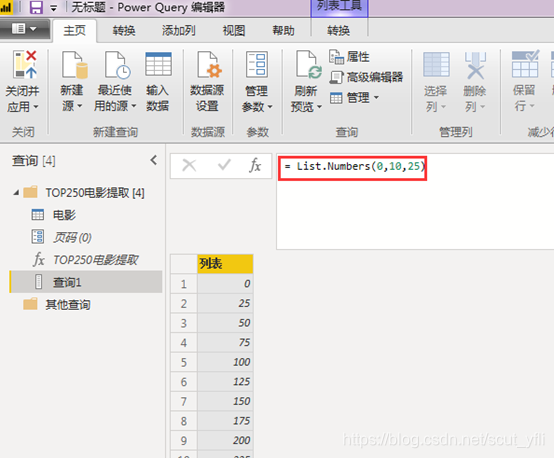
新建空白查询,使用List.Numbers(0,10,25)创建等差数列
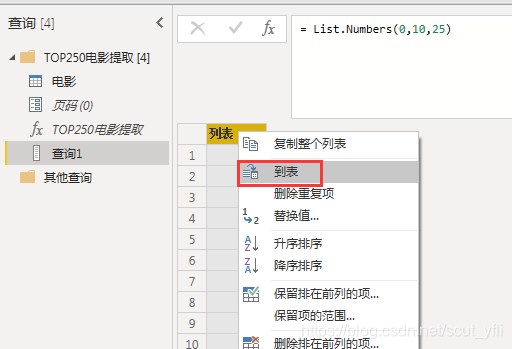
将List转换为表,并修改类型为文本
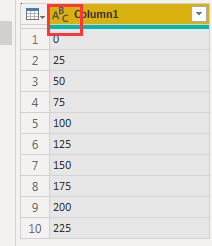
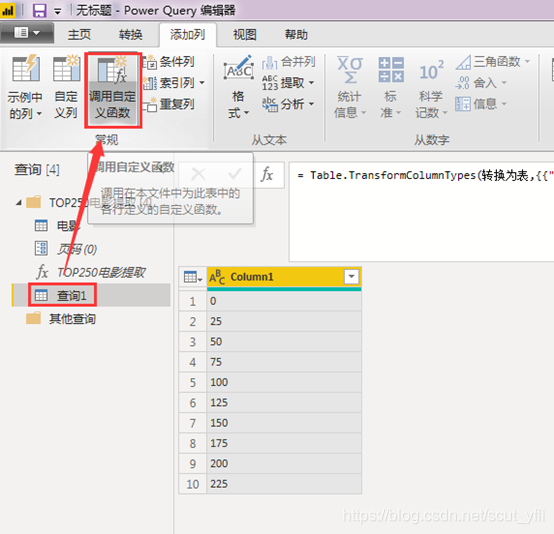
五、调用自定义函数
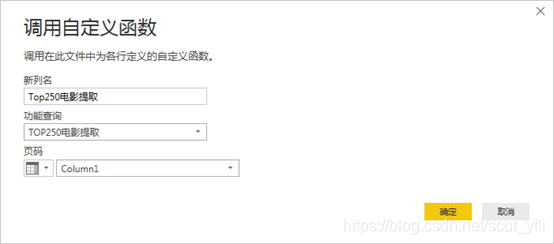
对新建的查询调用自定义函数
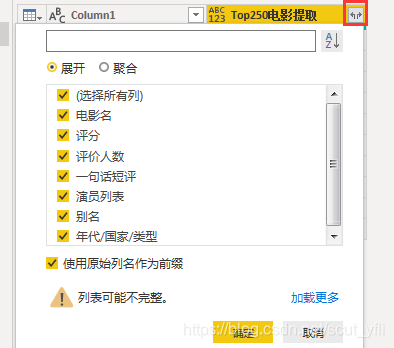
展开列,即得到需要的数据

添加索引列,处理下排名
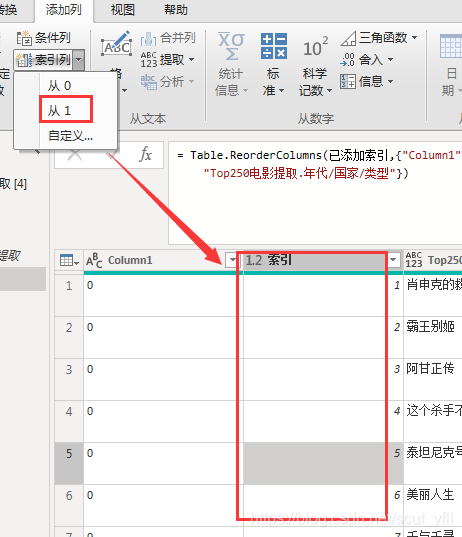
至此Top250电影数据爬取完毕




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











