







三. 不错的数据来源
目录[-]
用意: 搞推荐系统或者数据挖掘的, 对数据要绝对的敏感和熟悉, 并且热爱你的数据. 分析数据既要用统计分析那一套,又要熟悉业务发掘有趣的特征(feature). 后者有意思的多,但是因为我业务做的不多,还不太熟悉, 跪求大牛们分析业务经历. 听豆瓣上的大神"懒惰啊我"说过,有一个Nokia的比赛,有一个团队直接用陀螺仪参数就发现了性别分布,因为男生手机都放在 口袋里, 而女生往往放在包里面. 不知道记错没有.
下面主要讲些统计分析或者简单的内容分析, 说说我自己的总结, 这个话题以后可以常说.
这部分不涉及Mahout的内容,主要是使用Python和Linux命令简单处理数据. 不感兴趣的朋友可以直接跳到最后面看看一些不错的数据集推荐.
一. 前期数据分析的三个阶段
1. 打开你的数据,读懂每一行的含义
数据的行数
item和user的数量
rate的评分方式,是boolean还是1-5分或者其它.
数据稀疏还是稠密 sparse or dense
3. 找到合适的存储方式存储,DenseVector还是SparseVector
二. 数据分析实例
现在国内的数据还比较少, 感谢下百度,提供了一些不错的数据.
百度举办的电影推荐系统算法创新大赛提供的用户数据. http://pan.baidu.com/s/1y15w4
1. 读懂你的数据, 知道每一行的含义.
一共有五个文件:
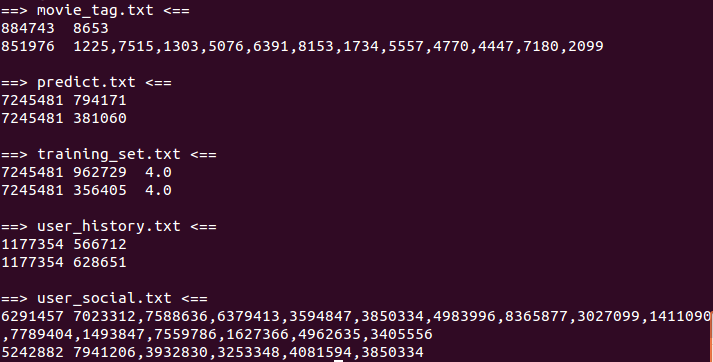
movie_tag.txt 每行表示一个有效数据项, 下面类似. 每行由电影id以及tag的id, 用"\t"隔开; tag用","隔开.
training_set.txt 每行表示用户id, 电影id, 评分, 用"\t"隔开.
user_social.txt 每行表示用户id和用户关注的好友id集合; 好友id集合用","隔开.
predict.txt 每行表示用户id和电影id
user_history.txt 每行表示用户id和用户看过的电影id.
数据如下图所示: head -n 2 *.txt
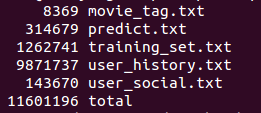
行数分析: wc -l *.txt
用户(总数,平均值,标准差)=( 9722 129.884900226 223.778624272 )
电影(总数,平均值,标准差)=( 7889 160.063506148 360.171047305 )
评分范围=( 1.0 5.0 )
简要分析:
由数据可见,用户数量和电影数量在10000左右级别, 由于电影更少一些,使用item-based较合适;当然,由于用户和电影数量差距不大,最终还是要用实验来证明一下两者的性能优异.
另外:两者标准差分别为223与336可见, 基本可以判定数据为稀疏矩阵.
[比较: 我使用了movieLens上的1M数据集进行对比, 运行结果如下]
http://www.grouplens.org/datasets/movielens/
用户(总数,平均值,标准差)=( 6040 165.597516556 192.731072529 )
电影(总数,平均值,标准差)=( 3706 269.889098759 383.996019743 )
评分范围=( 1.0 5.0 )
评价: 平均值更大, 数据更加致密一些. 每个用户和电影的数据推荐效果应该也会更好一些.
[吐槽点: 你给了id不给电影和标签的真实名称,看着一堆id, 推荐一大堆数字有个毛兴趣啊. 但是movieLens给出了电影名称,以后还是使用movieLens来作为预测数据更加有兴趣一些.]
Python代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
<strong>
# -*- coding: utf-8 -*-
'''
Created on 2 Nov, 2013
@author: cool
'''
import
math
#return user_num, movie_num, movie_mean, movie_variant
def
countData(filename):
user_count
=
{}
#the number of movie about every user
movie_count
=
{}
#the number of user about every movie
max
=
-
100
min
=
100
#Assuming no duplicate data
for
line
in
open
(filename):
(user, movie, rating)
=
line.split(
"\t"
)
#(user, movie, rating, xx) = line.split("::")
rating
=
float
(rating.replace(r
"\r\r\n"
, ""))
#print rating
user_count.setdefault(user,
0
)
user_count[user]
+
=
1
movie_count.setdefault(movie,
0
)
movie_count[movie]
+
=
1
if
(
max
< rating):
max
=
rating
if
(
min
> rating):
min
=
rating
uSum
=
sum
([user_count[user]
for
user
in
user_count])
uSqSum
=
sum
([user_count[user]
*
*
2
for
user
in
user_count])
user_mean
=
float
(uSum)
/
len
(user_count)
user_variant
=
math.sqrt(
float
(uSqSum)
/
len
(user_count)
-
user_mean
*
*
2
)
mSum
=
sum
([movie_count[movie]
for
movie
in
movie_count])
mSqSum
=
sum
([movie_count[movie]
*
*
2
for
movie
in
movie_count])
movie_mean
=
float
(mSum)
/
len
(movie_count)
movie_variant
=
math.sqrt(
float
(mSqSum)
/
len
(movie_count)
-
movie_mean
*
*
2
)
return
len
(user_count),
len
(movie_count), user_mean, user_variant, movie_mean, movie_variant,
min
,
max
if
__name__
=
=
'__main__'
:
(user_count, movie_count, user_mean, user_variant, movie_mean, movie_variant,
min
,
max
) \
=
countData(
"../data/baidu/training_set.txt"
)
#(user_count, movie_count, user_mean, user_variant, movie_mean, movie_variant, min, max) \
# = countData("../data/baidu/ratings.dat")
print
"用户(总数,平均值,标准差)=("
, user_count, user_mean, user_variant,
")"
print
"电影(总数,平均值,标准差)=("
, movie_count, movie_mean, movie_variant,
")"
print
"评分范围=("
,
min
,
max
,
")"
<
/
strong>
|
三. 不错的数据来源
已有 0 人发表留言,猛击->> 这里<<-参与讨论















 1542
1542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









