






ApacheJMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试但后来扩展到其他测试领域。 它可以用于测试静态和动态资源例如静态文件、Java小服务程序、CGI脚本、Java 对象、数据库, FTP服务器, 等等。JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来在不同压力类别下测试它们的强度和分析整体性能。另外,JMeter能够对应用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。为了最大限度的灵活性,JMeter允许使用正则表达式创建断言。
1. 下载JMeter
官方网站下载最新版本: http://jmeter.apache.org/download_jmeter.cgi ,目前最新版是Apache JMeter 2.9
使用JMeter依赖jdk,建议安装jdk 1.6版本
Linux下安装jdk参考文章:http://www.linuxeye.com/linuxrumen/Linux-install-JDK.html
Windowns下安装jdk同Linux下安装类似,这里就不介绍了。
2. 启动JMeter
这里就在win下进行,图形界面较为方便
在目录apache-jmeter-2.9\bin 下可以见到一个jmeter.bat文件,双击此文件,即看到JMeter控制面板。
3. 运行预准备
现在来对LinuxEye进行压力测试,压力测试对象为随机的几个网页链接,这几个链接是写在一个文本文件中的,在压力测试的时候会随机读取。
1) 建立一个线程组,如下图
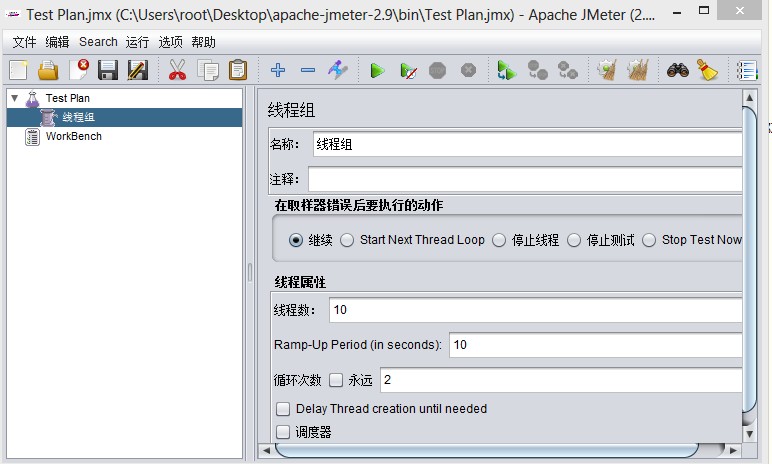
为什么要建立线程组?原因很简单,因为我们要模拟多个线程(用户)来访问LinuxEye。
线程属性部分中,线程数是启动多少个线程,我这里填写的是10,Ramp-Up Period (in seconds)表示线程之间间隔多少时间允许,单位是秒,比如如果填写10,那么10/10=1表示10个线程间每隔1秒钟请求网站。
循环次数:60个线程运行完毕算是一次,循环次数就是这样的一个请求过程运行多少次,我这里测试就填写的是2.
每次修改一个设置后,别忘记了保存一下。
2) 设置请求服务器、压力链接等信息
接下来很自然的是,我们要测试的网站地址是什么?链接是什么?所以现在我们就来设置这些信息。
右键点击我们刚创建的线程组,在弹出的菜单中,选择添加->Sampler->Http请求,弹出如下图界面:
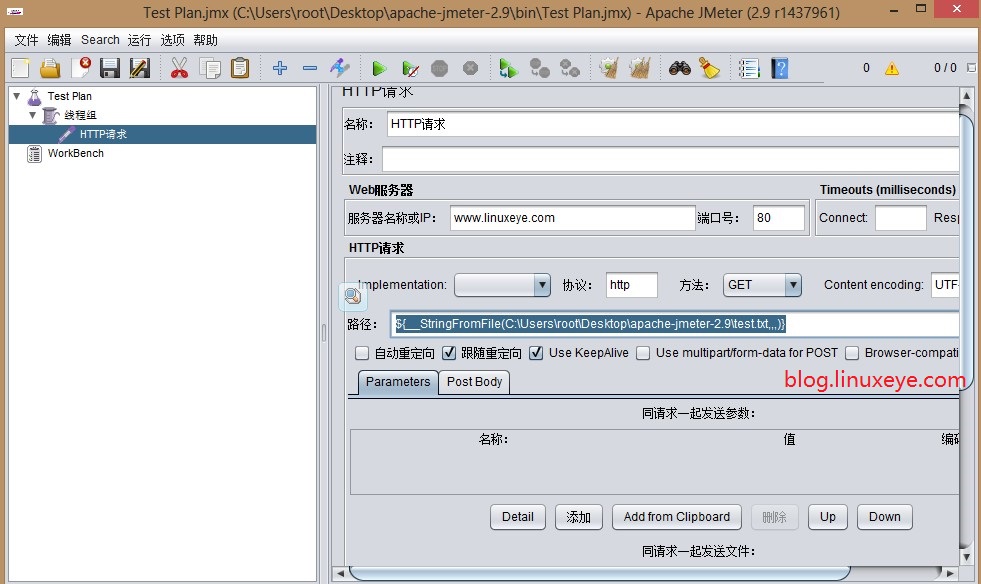
路径:
假如你只是对一个链接进行压力测试,直接填写一个链接就ok,比如 http://www.linuxeye.com,但是大多数情况下都不是这样的,我们这里需要多个链接,就如同刚开始讲到的那样,我们要将多个链接保存到一个文本文件中,然后随机读取进行压力测试。我们可以这么做,如图:
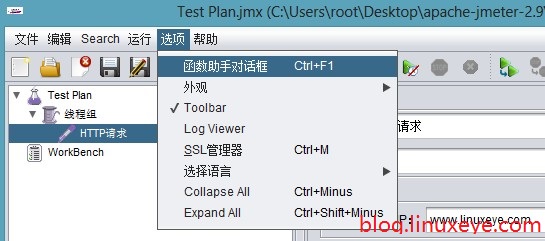
在选择一个功能下拉列表中选择_StringFromFile,然后在本机新建一个测试文件C:\Users\root\Desktop\apache-jmeter-2.9\test.txt,在第一行(你也可以不在第一行)的值中填写测试文件的路径,如下图:
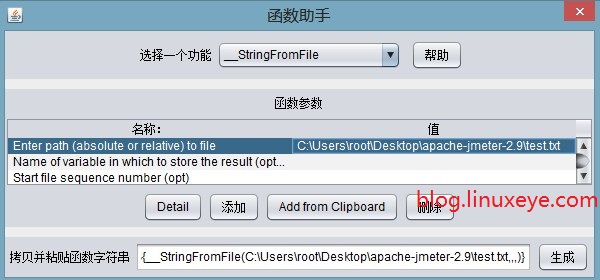
然后点击“生成”按钮,在生成按钮的左边文本框中将生成一个字符串如:
${__StringFromFile(C:\Users\root\Desktop\apache-jmeter-2.9\test.txt,,,)}
在test.txt测试文件中,我们每行写一个URL链接,如下格式:
/command
/linuxrumen
/program
/jianzhan
/command/cat.html
/command/chmod.html
/command/lsattr.html
注意,每行前面并没有http://www.linuxeye.com这样的信息,因为我们在前面已经填写了服务器地址为www.linuxeye.com,这里就没必要再为每个url填写这个相同前缀了;另外,上面的url格式也只是个例子,表示域名后的部分。
这样一来,当我们并非请求的时候,就会从test.txt中随机选择url来进行压力测试。
另外值得注意的一个地方是,如果参数中有中文的情况,运行的时候可能会出现乱码,这个时候就需要注意你在Jmeter中的编码设置与你要请求的网页编码是一致的。
路径文本框下面的选项,可以按默认的就成,Use multipart/form-data for HTTP POST是当请求中有附件的情况,一般情况下都不用选中的。
3) 查看运行结果
鼠标右键点击线程组,在弹出的菜单中选择添加->监听器->用表格查询结果,如下图:
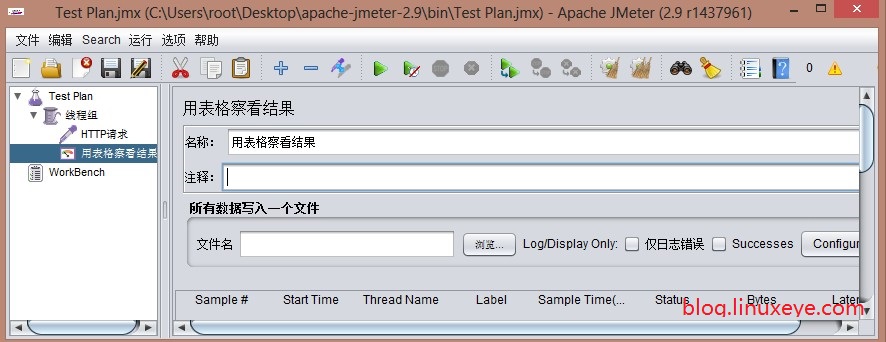
4. 运行
当然,在运行前,请把所有修改都保存好
运行后的结果表格如下:

各属性如下:
Sample:每个请求的序号
Start Time:每个请求开始时间
Thread Name:每个线程的名称
Label:Http请求名称
Sample Time:每个请求所花时间,单位毫秒
Status:请求状态,如果为勾则表示成功,如果为叉表示失败。
Bytes:请求的字节数
如果Status为叉,那很显然请求是失败了,但如果是勾,也并不能认为请求就一定完全成功了,因为还得看Bytes的字节数是否是所请求网页的正常大小值,如果不是则说明发生了丢包现象,也不是完全成功。
在下面还有几个参数:
样本数目:也就是上面所说的请求个数,成功的情况下等于你设定的并发数目乘以循环次数。
平均:每个线程请求的平均时间
最新样本:表示服务器响应最后一个请求的时间
偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布(这个我不是很理解)。
术语:
1、线程组:测试里每个任务都要线程去处理,所有我们后来的任务必须在线程组下面创建。可以在“Test Plan(鼠标右击) -> 添加 ->Threads(Users) -> 线程组”来建立它,然后在线程组面板里有几个输入栏:线程数、Ramp-Up Period(in seconds)、循环次数,其中Ramp-Up Period(in seconds)表示在这时间内创建完所有的线程。如有8个线程,Ramp-Up = 200秒,那么线程的启动时间间隔为200/8=25秒,这样的好处是:一开始不会对服务器有太大的负载。
2、取样器(Sampler):可以认为所有的测试任务都由取样器承担,有很多种,如:HTTP请求。
3、断言:对取样器返回的请求结果给出判断是否正确。
4、monitor:它的功能是对取样器的请求结果显示、统计一些数据(吞吐量、KB/S……)等。
badboy + jmeter并发性能测试
今天下班时公司安排了一个同事来对项目做集群性能测试,怀着对性能测试的好奇心,下班后没有着急离开,而是等待
那位同事的到来,然后在旁边学习了下如何使用Badboy和jmeter做性能测试。
1. 软件介绍
1.1 Badboy
Badboy,第一眼看见这个单词,以为是坏孩子的意思,后来一想,它是专门用来给项目找茬来的,取名为Badboy
倒是平添了几分可爱,呵呵。
Badboy是用来录制操作过程的,它录制的结果是被jmeter做并发测试的素材使用。
Badboy首页:http://www.badboy.com.au/
1.2 Apache jmeter
Jmeter是Apache下的一个完全基于JAVA开发的测试工具, 可以很方便的用来进行并发测试。
Jmeter首页:http://jakarta.apache.org/jmeter/
2. 使用过程
2.1 录制操作
(1)打开badboy进行登录的录制工作。(我们来看下163邮箱的登录并发性能如何,嘿嘿。)

(2)点击登录,然后结束录制,将录制的过程保存下来,保存成jmeter能够使用的格式,Script.jmx:

2.2 测试并发
(1)运行Apache Jmeter,文件à打开 ,然后选择刚才保存的录制文件 Script.jmx
(2)设置模拟并发的线程数量

(3)添加感兴趣的监听类型

(4)点击 运行à启动,开始执行并发登录163邮箱操作。

2.3 分析结果


理解 JMeter 聚合报告(Aggregate Report)
Aggregate Report 是 JMeter 常用的一个 Listener,中文被翻译为“聚合报告”。今天再次有同行问到这个报告中的各项数据表示什么意思,顺便在这里公布一下,以备大家查阅。
如果大家都是做Web应用的性能测试,例如只有一个登录的请求,那么在Aggregate Report中,会显示一行数据,共有10个字段,含义分别如下。
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
| 90%响应时间是什么意思?这个值在进行性能分析时有什么作用?本文争取用最简洁的文字来解答这个问题,并引申出“描述性统计”方法在性能测试结果分析中的应用。
为什么要有90%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事务响应时间是不够的。为什么这么说?你可以试着想想,是否平均事务响应时间满足了性能需求就表示系统的性能已经满足了绝大多数用户的要求? 假如有两组测试结果,响应时间分别是 {1,3,5,10,16} 和 {5,6,7,8,9},它们的平均值都是7,你认为哪次测试的结果更理想? 假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信? 为了解答上面的疑问,我们先来看一张表:
在上面这个表中包含了几个不同的列,其含义如下: CmdID 测试时被请求的页面 NUM 响应成功的请求数量 MEAN 所有成功的请求的响应时间的平均值 STD DEV 标准差(这个值的作用将在下一篇文章中重点介绍) MIN 响应时间的最小值 50 th(60/70/80/90/95 th) 如果把响应时间从小到大顺序排序,那么50%的请求的响应时间在这个范围之内。后面的60/70/80/90/95 th 也是同样的含义 MAX 响应时间的最大值 我想看完了上面的这个表和各列的解释,不用多说大家也可以明白我的意思了。我把结论性的东西整理一下: 1. 90%用户响应时间在 LoadRunner中是可以设置的,你可以改为80%或95%; 2. 对于这个表,LoadRunner中是没有直接提供的,你可以把LR中的原始数据导出到Excel中,并使用Excel中的PERCENTILE函数很简单的算出不同百分比用户请求的响应时间分布情况; 3. 从上面的表中来看,对于Home Page来说,平均事务响应时间(MEAN)只同70%用户响应时间相一致。也就是说假如我们确定Home Page的响应时间应该在5秒内,那么从平均事务响应时间来看是满足的,但是实际上有10-20%的用户请求的响应时间是大于这个值的;对于Page 1也是一样,假如我们确定对于Page 1 的请求应该在3秒内得到响应,虽然平均事务响应时间是满足要求的,但是实际上有20-30%的用户请求的响应时间是超过了我们的要求的; 4. 你可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的; 5. 如果你想使用这种方法来评估系统的性能,一个推荐的做法是尽可能让你的测试场景运行的时间长一些,因为当你获得的测试数据越多,这个响应时间的分布曲线就越接近真实情况; 6. 在确定性能需求时,你可以用平均事务响应时间来衡量系统的性能,也可以用90%或95%用户响应时间来作为度量标准,它们并不冲突。实际上,在定义某些系统的性能需求时,一定范围内的请求失败也是可以被接受的; 7. 上面提到的这些内容其实是与工具无关的,只要你可以得到原始的响应时间记录,无论是使用LoadRunner还是JMeter或者OpenSTA,你都可以用这些方法和思路来评估你的系统的性能。
事实上,在性能测试领域中还有更多的东西是目前的商业测试工具或者开源测试工具都没有专门讲述的——换句话说,性能测试仅仅有工具是不够的。我们还需要更多其他领域的知识,例如数学和统计学,来帮助我们更好的分析性能数据,找到隐藏在那些数据之下的真相。 |

Note:关于 50% 和 90% 并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
Jmeter中的几个重要测试指标释义
Aggregate Report 是
如果大家都是做Web应用的性能测试,例如只有一个登录的请求,那么在AggregateReport中,会显示一行数据,共有10个字段,含义分别如下。
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 TransactionController 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
Note:关于 50% 和 90% 并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了Transaction Controller 时,也可以表示类似
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
一、基本概念
1.测试计划是使用
2.线程组:代表一定数量的并发用户,它可以用来模拟并发用户发送请求。实际的请求内容在Sampler中定义,它被线程组包含。可以在“测试计划->添加->线程组”来建立它,然后在线程组面板里有几个输入栏:线程数、Ramp-UpPeriod(in seconds)、循环次数,其中Ramp-Up Period(inseconds)表示在这时间内创建完所有的线程。如有8个线程,Ramp-Up =200秒,那么线程的启动时间间隔为200/8=25秒,这样的好处是:一开始不会对服务器有太大的负载。线程组是为模拟并发负载而设计。
3、取样器(Sampler):模拟各种请求。所有实际的测试任务都由取样器承担,存在很多种请求。如:HTTP、ftp请求等等。
4、监听器:负责收集测试结果,同时也被告知了结果显示的方式。功能是对取样器的请求结果显示、统计一些数据(吞吐量、KB/S……)等。
6、断言:用于来判断请求响应的结果是否如用户所期望,是否正确。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
7、定时器:负责定义请求(线程)之间的延迟间隔,模拟对服务器的连续请求。
5、逻辑控制器:允许自定义JMeter发送请求的行为逻辑,它与Sampler结合使用可以模拟复杂的请求序列。
8. 配置元件维护Sampler需要的配置信息,并根据实际的需要会修改请求的内容。
9. 前置处理器和后置处理器负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。
二、Jmeter报告(转载)
http://www.cnblogs.com/jackei/archive/2006/11/13/558720.html
1、Aggregate Report 解析
Aggregate Report 是
如果大家都是做Web应用的性能测试,例如只有一个登录的请求,那么在AggregateReport中,会显示一行数据,共有10个字段,含义分别如下。
Label:每个
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 TransactionController 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
Note:关于 50% 和 90% 并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction perSecond 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
基本知识:
1、吞吐量:是指在没有帧丢失的情况下,设备能够接受的最大速率。
2、存储的最小单位是字节Byte,对于存储单位,有以下几个单位,GB、MB和KB,那么这三者之间的换算关系是:1GB=1024MB,1MB=1024KB,1KB=1024Bytes。
Bit :“位”,称为bit,也就是比特,有的时候也称为位。一个字节为8位二进制表示。
Byte:“字节”,一个字节就是8比特。
3、Mbps (million bits per second 兆位/秒)代表每秒传输1,000,000比特。该缩写用来描述数据传输速度。例如:4Mbps=每秒钟传输4M比特。
数据传输速率的单位,字母b(bit)是比特和字母 B (Byte)是字节。
4、吞吐量与带宽的区分:吞吐量和带宽是很容易搞混的一个词,两者的单位都是Mbps.先让我们来看两者对应的英语,吞吐量:throughput; 带宽: Max net bitrate。当我们讨论通信链路的带宽时,一般是指链路上每秒所能传送的比特数。我们可以说以太网的带宽是10Mbps。但是,我们需要区分链路上的可用带宽(带宽)与实际链路中每秒所能传送的比特数(吞吐量)。我们倾向于用“吞吐量”一次来表示一个系统的测试性能。这样,因为实现受各种低效率因素的影响,所以由一段带宽为10Mbps的链路连接的一对节点可能只达到2Mbps的吞吐量。这样就意味着,一个主机上的应用能够以2Mbps的速度向另外的一个主机发送数据。
5、方差和标准差都是用来描述一组数据的波动性的(集中还是分散),标准差的平方就是方差。方差越大,数据的波动越大。
三.利用BadBoy生成测试计划(测试脚本)
badBoy可以非常容易的生成web的测试脚本。类似与LoadRunner的使用,输入站点的URL,点击Record开始录制。File–> Export to
四.一个简单的测试示例思路(目前自己思路,不断改进)
a. 需要的“测试脚本”,对应web的应用使用badboy生成测试脚本。直接导入Jmeter,进行配置。
b.如图
TestPlan :是整个Jmeter测试执行的容器。
ThreadGroup :模拟请求,定义线程数、Ramp-Up Period、循环次数。
Step1 :循环控制器 ,控制Sample的执行次数。
Sample取样器 :决定进行那种类型的测试,如http、ftp等。
监听器 :图形结果、聚合报告。
定时器 :Random类型,定义线程请求的延迟。
c.聚合报告的解释
Label :各个模拟测试的名称
#Samples :各个测试的样本总数
Average :每个请求的平均响应时间
Median :中值,即50%请求的平均响应时间
90%Line :90%请求的响应时间
Min :最小响应时间 ,Max :最大的响应时间
Error% :错误响应的概率。即无法响应的概率。
ThroughPut :吞吐量 -- 默认情况下表示每秒完成的请求数(Request per Second)。
KB/Sec :每秒从服务器端接收到的数据量。
五.Jmeter常见问题(转载)http://www.51testing.com/?uid-128005-action-viewspace-itemid-84094
说明:这些问答是从网上转载的,自己修改了其中的一些内容,如果大家兴趣,可以将大家在使用Jmeter的时候碰到的问题写下来,我们一起补充到这个问答里面,共同努力完善jmeter的资料。
1.
向服务器提交请求;从服务器取回请求返回的结果。
2.
JMeter可以用于测试静态或者动态资源的性能(文件、Servlets、Perl脚本、java对象、数据库和查询、ftp服务器或者其他的资源)。JMeter用于模拟在服务器、网络或者其他对象上附加高负载以测试他们提供服务的受压能力,或者分析他们提供的服务在不同负载条件下的总性能情况。你可以用JMeter提供的图形化界面分析性能指标或者在高负载情况下测试服务器/脚本/对象的行为。
3. 怎样能看到jmeter提供的脚本范例?
在\JMeter\jakarta-jmeter-2.0.3\xdocs\demos目录下。
4. 怎样设置并发用户数?
选中可视化界面中左边树的Test
5.
Jmeter在运行时,右上角有个单选框大小的小框框,运行是该框框为绿色,运行完毕后,该框框为白色。
6. User Parameters的作用是什么?
提高脚本可用性
7. 在result里会出现彩色字体的http response code,说明什么呢?
Http responsecode是http返回值,彩色字体较引人注目,可以使用户迅速关注。象绿色的302就说明在这一步骤中,返回值取自本机的catch,而不是server。
8. 怎样计算Ramp-up period时间?
Ramp-up period是指每个请求发生的总时间间隔,单位是秒。如果Number of Threads设置为5,而Ramp-upperiod是10,那么每个请求之间的间隔就是10/5,也就是2秒。Ramp-upperiod设置为0,就是同时并发请求。
9. Get和Post的区别?
他们是http协议的2种不同实现方式。Get是指server从RequestURL取得所需参数。从result中的request中可以看到,get可以看到参数,但是post是主动向server发送参数,所以一般看不到这些参数的。
10. 哪些原因可能导致error的产生?
a. Http错误,包括不响应,结果找不到,数据错误等等;
b.
11. 为什么Aggregate Report结果中的Total值不是真正的总和?
JMeter给结果中total的定义是并不完全指总和,为了方便使用,它的值表现了所在列的代表值,比如min值,它的total就是所在列的最小值。下图就是total在各列所表示的意思。
12.
不是,Thread Number仅仅是指并发数,如果需要实现多个不同用户并发,我们应该采用其它方法,比如通过在jmeter外建立csv文件的方法来实现。
13. 同时并发请求时,若需要模拟不同的用户同时向不同的server并发请求,怎样实现呢?
方法很灵活,我们可以将不同的server在thread里面预先写好。或者预先将固定的变量值写入csv文件,这样还可以方便修改。然后将文件添加到UserParameters。
14. User Parameter中的DUMMY是什么意思?
当其具体内容是${__CSVRead(${__property(user.dir)}${FILENAME},next())}时用来模拟读文件的下一行。
15. 当测试对象在多server间跳转时,应该怎样处理?
程序运行时,有些http和隐函数会携带另外的server IP,我们可以从他们的返回值中获取。
16. 为何测试对象是http和https混杂出现?
Https是加密协议,为了安全,一般不推荐使用http,但是有些地方,使用https过于复杂或者较难实现,会采用http协议。
17. Http和https的默认端口是什么?
Apache server (Http)的默认端口是80;
SSL (Https)的默认端口是443。
18. 为何在run时,有些页面失败,但是最后不影响结果?
原因较多,值得提及的一种是因为主流页面与它不存在依赖关系,所以即使这样的页面出错,也不会影响运行得到正常结果,但是这样会影响到测试的结果以及分析结果。
19. 为什么脚本刚开始运行就有错误,其后来的脚本还可运行?
在ThreadGroup中有相关设置,如果选择了continue,即使前面的脚本出现错误,整个thread仍会运行直到结束。选择StopThread会结束当前thread;选择Stop Test则会结束全部的thread。推荐选项是StopThread。
20. 在Regular expression_rExtractor会看到Template的值是$1$,这个值是什么意思呢?
$1$是指取第一个()里面的值。如果Regularexpression_r的数值有多个,用这种方法可以避免不必要的麻烦。
21. Regular expression_r中的(.*)是什么意思?
那是一个正则表达式(regularexpression_r)。’.’等同于sql语言中的’?’,表示可有可无。’*’表示0个或多个。’()’表示需要取值。(.*)表达任意长度的字符串。
22. 在读取Regular expression_r时要注意什么?
一定要保证所取数值的绝对唯一性。
23. 怎样才能判断什么样的情况需要添加Regular expression_r Extractor?
检查Http Request中的SendParameters,如果有某个参数是其前一个page中所没有给出的,就要到原文件中查找,并添加Regularexpression_r Extractor到其前一page的http request中。
24. 在自动获取的脚本中有时会出现空的http request,是什么意思呢?
是因为在获取脚本时有些错误,是脚本工具原因。在run时这种错误不参与运行的。
25. 在运行结果中为何有rate为N/A的情况出现?
可能因为JMeter自身问题造成,再次运行可以得到正确结果。
26. 常用http错误代码有哪些?
400无法解析此请求。
403禁止访问:访问被拒绝。
404找不到文件或目录。
405用于访问该页的HTTP动作未被许可。
410文件已删除。
500服务器内部错误。
501标题值指定的配置没有执行。
502 Web服务器作为网关或代理服务器时收到无效的响应。
27. Http request中的Send Parameters是指什么?
是指code中写定的值和自定义变量中得到的值,就是在运行页面时需要的参数。
28. Parameters在页面中是不断传递的么?
是的。参数再产生后会在页面中一直传递到所需页面。所以我们可以在动态参数产生时捕获它,也可以在所需页面的上一页面捕获。(但是这样可能有错误,最好在产生页面获取)
29. 在使用JMeter测试时,是完全模拟用户操作么?造成的结果也和用户操作完全相同么?
是的。JMeter完全模拟用户操作,所以操作记录会全部写入DB.在运行失败时,可能会产生错误数据,这就取决于脚本检查是否严谨,否则错误数据也会进入DB,给程序运行带来很多麻烦。
六.Jmeter测试心得(转载)http://www.javaeye.com/topic/211216
企业应用开发过程中,性能测试是很重要的一个环节,在这个环节中Apache的JMeter以它开源、100%纯Java、操作方便等优点发挥着很大的作用。
经过一段时间的使用,多少有些心得和技巧,拿出来共享,希望能有些帮助。
1、制作测试脚本:
手工制作测试脚本,需要你知道请求的url和携带的参数等等,太花费时间,
所以可以用badboy工具录制脚本。这个工具虽然不是开源的,但是却可以用来免费的录制成.jmx的脚本,使用起来很方便。
官方网站是:http://www.badboy.com.au/
2、出现乱码了?
在用JMeter发行HTTPRequest时,在请求参数中有中文时,发现存储到DB中后,相应的字段是乱码,
明明在参数后面的Encode选项中打了V。后来发现badboy录制脚本的时候并没有记录编码方式,所以修改脚本,
在Content encoding中设置正确的编码方式就不会出现乱码了。
3、JMeter的妙用---准备测试数据:
要求性能测试开始前,先准备5W条数据。当然可以通过直接修改DB,但是如果这5W条数据涉及到很多表的关联,
甚至还要通过存储过程的处理怎么办,直接修改DB很容易出现错误的数据,要是在客户的机器上弄错,可就闯祸了。
这时候想到了JMeter,它本来是用来模拟大量用户并发请求的,现在用它来批量的生成数据吧。
如果要求每条数据都不同,就要修改脚本,使用JMeter的函数来动态产生数据,比较常用的是CSVRead函数,
记不住名的话Ctrl+F可以呼唤出函数助手。使用这个函数的时候需要注意几点,首先是csv文件的编码格式,
使用ansi没有问题,使用unicode时会使读取的第一行数据出现错误;
${__CSVRead(data.txt,0)}---读取本行的第一列值
${__CSVRead(data.txt,1)}${__CSVRead(data.txt,next)}---读取本行的第二列值,并把行标移动到下一行
试验证明JMeter应该做好了同步,在多线程环境下上面的调用方法没有问题;
最后,修改JMeter的线程数会加快数据生成的速度,原理是当并发线程在20左右的时候会达到最大的吞吐量(request/分),
所以应该设定线程数20左右。
4、JMeter中debug方法:
JMeter提供了log函数输出log,但是有时候并不好用,比如我想输出某个函数的返回值看是不是正确的,
${__log(${__CSVRead(data.txt,1)})}这样的写法是错误的,JMeter会抛出异常,该怎么办呢?
答案是巧用监听器(Listener)来输出想看到的数据,结果显示为树的那个监听器,
它可以让你查看每个sampler的请求数据和响应数据,在请求数据中就有你想看到的信息。
5、常用的功能:
?使用HTTP Cookie Manager或URL重写实现同一线程内的多个请求共享Session。
?把Login的请求放到只执行一次的控制器中,那么即使循环多次,Login也只请求一次。
?如果想让多个线程在同一时刻同时请求,那么用Synchronizing Timer来做集合点。
?为了节省系统资源,使用非窗口模式运行JMeter(jmeter
?如果模拟并发用户过多,比如200线程,那么可以分散到多台机器上运行Jmeter(比如4台电脑,每台50线程)
更多功能请参照使用手册
中文手册(未完成)http://wiki.javascud.org/pages/viewpage.action?pageId=5566
6、在winnt系统上,使用perfmon来帮助Jmeter采集服务器的系统资源数据,可以配置log输出这些数据作为性能瓶颈分析时使用。
七.置信区间 http://java.chinaitlab.com/tools/355421.html
对数据进行更科学的分析,确定测试结果。类似于Jmeter聚合报告的90%Line给出的参考,而不能仅仅参考均值。
记:熟悉Jmeter使用之后,自己更应该关注的是“测试实践”,以及通过怎么样的方法改进性能。
求并发用户数公式
在实际的性能测试工作中,测试人员一般比较关心的是业务并发用户数,也就是从业务的角度关注应该设置多少个并发数比较合理。
下面找一个典型的上班签到系统,早上8点上班,7点半到8点的30分钟的时间里用户会登录签到系统进行签到。公司员工为1000人,平均每个员上登录签到系统的时长为5分钟。可以用下面的方法计算。
C=1000*5/30=166.7
C表示平均并发用户数,那么对这个签到系统每秒的平均并发用户数为166
当然,在性能测试上,任何公式都不是严谨的,最重要的是对系统做出有效正确的分析。
并发用户数、吞吐量、思考时间的计算公式
二、软件性能的几个主要术语1、响应时间:对请求作出响应所需要的时间。在所有加载的用户稳定运行后,目标系统平均

网络传输时间:N1+N2+N3+N4
应用服务器处理时间:A1+A3
数据库服务器处理时间:A2
响应时间=N1+A1+N2+A2+N3+A3+N4
2、并发用户数的计算公式
系统用户数:系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是2000个,那么这个数量,就是系统用户数
同时在线用户数:在一定的时间范围内,最大的同时在线用户数量
平均并发用户数的计算:
C=nL / T
其中C是平均的并发用户数,n是平均每天访问用户数,L是一天内用户从登录到退出的平均时间(操作平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:
C^ 约等于 C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论
3、吞吐量的计算公式
指单位时间内系统处理用户的请求数
从业务角度看,吞吐量可以用:请求数/秒、页面数/秒、人数/天或处理业务数/小时等单位来衡量
从网络角度看,吞吐量可以用:字节/秒 来衡量
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力
以不同方式表达的吞吐量可以说明不同层次的问题,例如,以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈;已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈。
当没有遇到性能瓶颈的时候,吞吐量与虚拟用户数之间存在一定的联系,可以采用以下公式计算:F=VU * R / T
其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间
4、性能计数器
是描述服务器或操作系统性能的一些数据指标,如使用内存数、进程时间,在性能测试中发挥着“监控和分析”的作用,尤其是在分析统统可扩展性、进行新能瓶颈定位时有着非常关键的作用。
资源利用率:指系统各种资源的使用情况,如cpu占用率为68%,内存占用率为55%,一般使用“资源实际使用/总的资源可用量”形成资源利用率。
5、思考时间的计算公式
ThinkTime,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,而在做新能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
在吞吐量这个公式中F=VU * R /T说明吞吐量F是VU数量、每个用户发出的请求数R和时间T的函数,而其中的R又可以用时间T和用户思考时间TS来计算:R = T /TS
下面给出一个计算思考时间的一般步骤:
A、 首先计算出系统的并发用户数
C=nL / T F=R×C
B、 统计出系统平均的吞吐量
F=VU * R / T R×C = VU * R / T
C、 统计出平均每个用户发出的请求数量
R=u*C*T/VU
D、根据公式计算出思考时间
TS=T/R
示例1:
计算机系统的总体性能标准是吞吐量和响应时间。
吞吐量是对单位时间内完成的工作量的量度。示例包括:
响应时间是提交请求和返回该请求的响应之间使用的时间。示例包括:
这些度量之间的关系很复杂。有时可能以响应时间为代价而得到较高的吞吐量,而有时候又要以吞吐量为代价得到较好的响应时间。在其他情况下,一个单独的更改可能对两者都有提高。可接受的性能基于合理的吞吐量与合理的响应时间相结合。
通常,平均响应时间越短,系统吞吐量越大;平均响应时间越长,系统吞吐量越小。但是,系统吞吐量越大,未必平均响应时间越短。因为在某些情况(例如,不增加任何硬件配置)吞吐量的增大,有时会把平均响应时间作为牺牲,来换取一段时间处理更多的请求。
举个例子:一个理发店,只有一个理发师、一把理发椅子、一张方便客人等待的长凳。理发师一次只能处理一个客户,其他等待的用户显得很不耐烦,外面打算进来理发的人也放弃了在这家店理发的打算……
有一天,理发师有钱了,他多买了2把理发椅子。这样他可以同时给3个人理发:当其中一个人理到一定阶段需要调整或定型的时候,他就转向另外一个客户为其服务,依次类推。这样,他发现一天内他可以理的人数比以前增多了,但是还会有一些后来的客户抱怨等待时间太长。(吞吐量大了,但平均响应时间却长了)
后来,理发师招了2名学徒帮他一起干活。他发现这样一来每天的理发效率增加了将近2倍,而且客户的等待时间也明显减少。但是成本增多了,理发用具、洗发水、发工资,这让他觉得开个理发店也要精打细算。(平均响应时间短了,吞吐量也大了,但是成本却高了)
示例2:
我们可以利用“门”的概念来理解这里面的偏差!
首先,我们假设如下的情况:
共有5个人;
有1扇门;
一个人通过这扇门需要花费1秒的时间;
此时,这扇门的吞吐量为1人/秒。5个人通过这扇门的平均响应时间为(1+2+3+4+5)/5=3秒。
如何才能提高人的通过效率呢?即,如何才能提高门的吞吐量呢?
有两种方法:
(1)减小通过门的时间;
(2)增加门的数量
例如,
(1)将一个人通过门的时间减小为0.5秒,门的吞吐量变成了2人/秒;
(2)增加一个门,门的吞吐量也变成了2人/秒
结果是:
(1)5个人通过改善通过时间的门的平均响应时间为(0.5+1+1.5+2+2.5)/5=1.5秒;
(2)5个人通过两扇门的平均响应时间为(1+1+2+2+3)/5=1.8秒
此时,你可以发现,软件开发员改进软件处理并发交易请求的方法有两个,第一种是提高单个请求的处理速率,第二种是增加处理请求的线程的数量;或者是两种方法的组合。但是,不同方法的使用并不代表吞吐量得到了提高,而同时软件典型交易的平均响应时间也获得了相同值的改善。
因此,在性能测试以吞吐量为检测指标的时候,不光要评估吞吐量是否符合了性能指标的要求,同时也必须考虑响应时间是否符合性能指标的要求。
假设,在测试前,规定了吞吐量为大于25笔交易/秒,平均响应时间为小于5秒,在测试后,若实际吞吐量等于27笔交易/秒,不能仅凭这个27笔交易/秒就确定该软件的性能符合要求了,还要看平均响应时间是否符合要求。这时的平均响应时间可能大于5秒。
而如果测试前,规定了在线人数为10000,平均响应时间为小于5秒,在测试后,仅凭实际平均响应时间等于4秒就可以判断该软件的性能符合要求。















 1767
1767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









