






红杉资本的AI峰会上提到:2024年大模型最重要的关注点在于可靠性和健壮性,这意味着大模型应用正在从大玩具逐步转变成解决关键业务问题的系统组件。

在上一篇文章 提示工程、RAG和微调 - 哪个才是大模型应用优化的最佳路径? 中,我提到了一个对于大模型应用工程化非常重要的主题,就是如何验证大模型应用的性能,质量和用户体验。由于大模型本身的不确定性,传统测试手段对于大模型应用的验证往往无从下手。在实际应用中,大模型应用的落地失败往往都源于在研发过程中缺少有效可靠的验证系统,这也是为什么大多数大模型应用一直停留在DEMO阶段而止步不前。
在AISE和SmartCode的开发过程中,我们遇到了同样的问题。无论是采用提示工程制作的新提示词,还是在微调过程中所生成的训练数据和训练结果,我们都需要一种量化可评估的方式来确保最终交付的特性可以达到一定的成功率。如果将未经验证的特性发布给用户,那么很可能出现在客户现场出现不可控的生成结果,影响用户的使用体验。
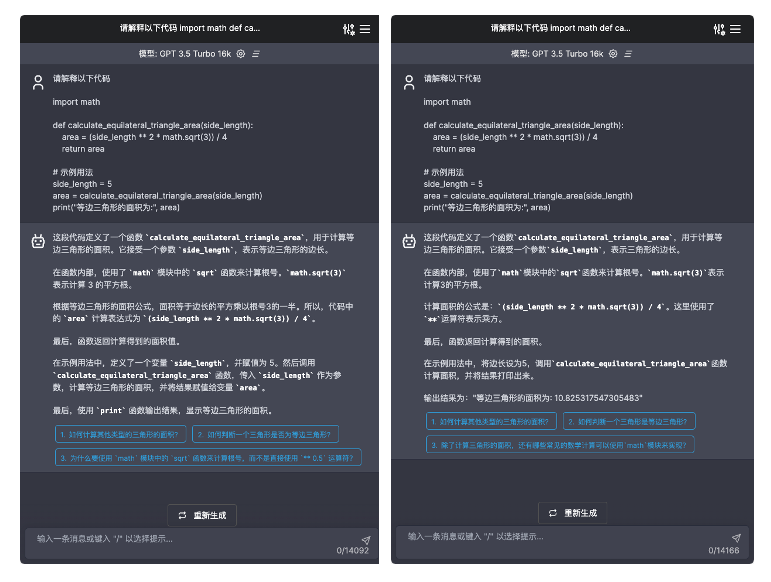
下面是一个很典型的实例:
这里我使用了完全一样的提示词:请解释以下代码 {{code}},以及完全一样的被解释的代码块
但是模型给出了不尽相同的结果,特别是下面这一段
左边:根据等边三角形的面积公式,面积等于边长的平方乘以根号3的一半。所以,代码中的
area计算表达式为(side_length ** 2 * math.sqrt(3)) / 4。右边:计算面积的公式是:
(side_length ** 2 * math.sqrt(3)) / 4。这里使用了**运算符表示乘方。
同样的输入,却有不同的输出,而含义上其实一致。在传统软件测试下,我们是无法判断这两个测试结果到底哪个是正确的。而实际上,对于大模型应用而言,这两个结果其实都对。
作者简介

本文转译自:Hanmel Husain 的博客 “Your AI Product Needs Evals”
原文链接:https://hamel.dev/blog/posts/evals/
我对原文进行了阅读转译,意味着这并不是一篇翻译文章,而是我根据自己的理解重新编写并补充了自己的理解和经验,同时保留了原文的主要观点。
原作者简介:在2017年到2022年,Hanmel Husain 在 GitHub 任职机器学习工程师期间,主导了2个重要项目,分别是 CodeSearchNet 和 Machine Learning Ops。其中 CodeSearchNet 可以被认为是 GitHub Copilot 的前身,这个项目主要对代码语义搜索进行了研究,并且训练了专门用于代码语义搜索的AI模型。
迭代的频率决定了成功的机率
在软件工程/敏捷开发中,任务迭代的频率和节奏决定了一个团队乃至一个产品的成功,对于大模型应用的研发来说,更是如此。传统软件是基于规则的,我们尚可通过穷举法来覆盖足够多的可测试场景,也可以通过预设的逻辑推导软件应用的行为,但对于大模型应用,以上的例子已经说明这两个做法都是不可行的。我们唯一的手段只有,通过实际使用结果来验证应用的质量。
为了达到这个目的,我们需要构建一个流程和工具链,能够支撑我们尽量快速的完成以下流程的迭代:
使用测试集验证质量
使用日志和监控数据检视应用状态,定位和调试问题
通过提示工程,RAG或者微调的方式改进系统
发布新版本
很多AI应用开发团队都非常重视第3点而忽视了前2点,这造成了很多的AI应用一直停留在DEMO阶段,一旦投入生产使用就会出现各种异常情况。一个AI是否能够构建出可靠的测试集和应用状态检视机制,其实决定了这个团队所产出的AI产品是否能够具备投入生产使用的基本条件。
如果小米su7都没有经过任何路试的话,你敢买吗?
(开个玩笑:小米su7很棒)
其实,传统软件工程实践对于我们改进大模型应用一样有效,我们必须在开发后面紧跟测试环节。这种机制必须在项目的一开始就构建好。以下,我们用一个真实的AI应用开发过程作为案例,分析并展示如何构建这样一个系统,我们不会对整个项目的细节进行介绍,而主要关注验证环节。
背景:AI应用开发案例 Lucy - 房产中介AI助理项目
Rechat https://rechat.com 是一个基于大模型构建的AI房产中介助理SaaS应用,可以帮助房产中介们完成各种琐碎的任务,包括:管理合同,搜索房屋记录,制作市场推广素材,管理看房时间表等等。Rechat的目标是让中介代理们可以使用一个统一的入口完成所有这些事情,避免在不同的工具间不停的切来切去。
Lucy(露西)是Rechat中提供的智能个人助理,采用对话式交互界面提供Rechat里面的各种功能。在开发Lucy的早期阶段,开发团队使用提示工程的方式快速实现了很多的功能。但是随着Lucy需要处理的场景越来越多,问题也越来越多,比如:
解决一个问题会引发其他问题的出现,就好像打地鼠游戏,bug此起彼伏
AI行为的可见性很差,我们很难判断问题的根源到底是系统代码、提示词还是RAG系统
因为问题越来越多,我们用的提示词也越来越复杂,开始用各种提示词片段来试图堵住各种系统漏洞
这种状况造成了Lucy的用户体验持续变差,已经开始影响整个系统的推广。
如何系统化的改进大模型应用?
为了打破这个恶性循环,我们为lucy的开发团队设计了以下的 大模型应用持续交付 流程。
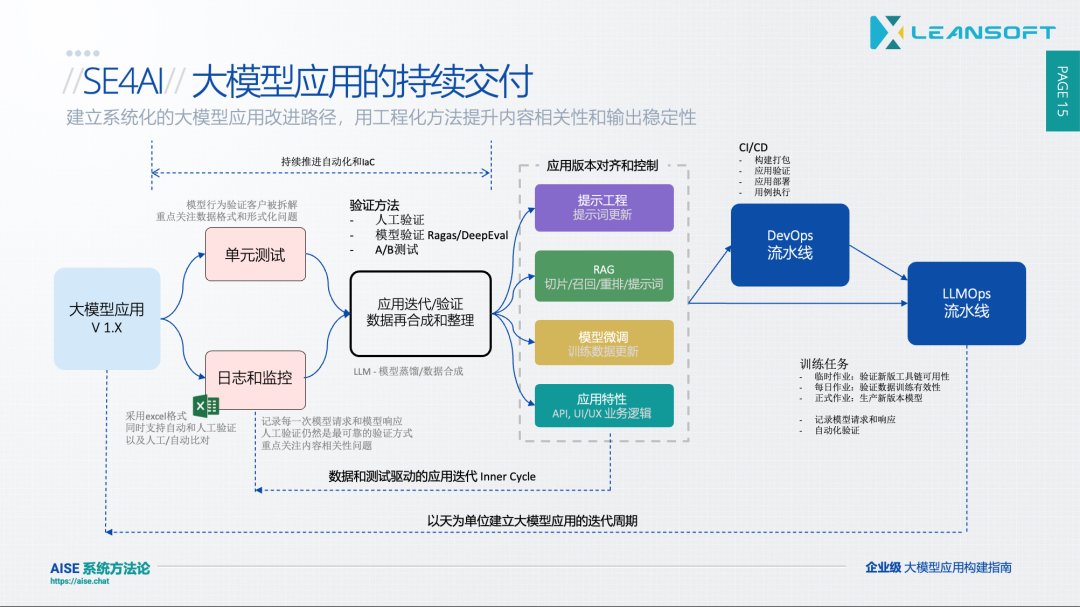
备注:此图是在原图基础上增加了我自己的理解重新设计的。
让我们对上图的几个关键环节逐个解释
三层测试金字塔
为了能够构建稳定和系统化的验证能力,我们需要围绕 “应用迭代/验证” 构建一个三层测试金字塔
第一层:单元测试
第二层:模型和人工验证(包括对日志和监控的检视)
第三层:A/B 测试能力
与传统软件的测试金字塔一样,第一层的单元测试成本最低,层级越高意味着成本越高。同时,低层级的单元测试需要更加频繁的执行,最好是在每次代码变更时都可以在IDE中执行。第二层的验证过程应该以一种固定的频率执行,最后的第三层我们则只会在正式的产品版本上引导用户来完成。
在上图中间部分,单元测试紧随应用迭代过程,需要开发人员尽量密集的执行。同时在右侧的LLMOps流水线中,我们通过临时作业和每日作业来支持第二层测试的自动执行。
大模型应用的单元测试
与传统的单元测试一样,我们使用通用的测试框架,比如:pytest/mocha/junit来驱动这些测试,并且使用 assertion(验证条件)来判断测试结果。编写这些测试的核心重点是将测试粒度尽量缩小,以便让这些测试能够迅速的执行并且得到结果。如果你想不到应该测试些什么,那么看一下应用运行日志其实是最好的起点,因为从这些日志可以非常客观的记录问题,帮助你定位那些可能出现的错误。当然,你也可以让大模型本身帮助你来进行头脑风暴。
单元测试需要从非常小的粒度上来验证你的应用状态,所以你需要学会将特性拆分成非常细小的场景。在Lucy场景下,搜索房产信息是一个很重要的特性,用户可能会这样提问:请帮我搜索在加州圣何塞附近的3个卧室的房产信息,价格不超过200万美金。大模型会根据用户的问题生成发送给CRM系统的数据查询语句,因此我们的单元测试可以对以下场景进行验证。
提示词 | 验证条件 |
请返回符合用户请求的一条房产信息 | len(listing_array) == 1 |
请返回符合用户条件的多条房产信息 | len(listing_array) > 1 |
如果没有符合条件的房产信息,不要返回任何数据 | len(listing_array) == 0 |
其实这些测试和传统测试类似,只过不过我们将测试输入改成了对大模型的提示词;但是,通过重复运行这样的标准化测试集,我们可以确保我们的系统一直处于可控的行为之下;不用担心开发人员不小心更新了某些逻辑而造成用户体验问题。
当然,还有一些更加通用的测试,可以完全使用传统方式编写。比如下面这个验证不能出现用户ID的测试代码。这是一个更加通用的测试,应该更加频繁的运行,确保系统不会暴露那些不应该暴露的敏感信息。
const noExposedUUID = message => {
// Remove all text within double curly braces
const sanitizedComment = message.comment.replace(/\{\{.*?\}\}/g, '')
// Search for exposed UUIDs
const regexp = /[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}/ig
const matches = Array.from(sanitizedComment.matchAll(regexp))
expect(matches.length, 'Exposed UUIDs').to.equal(0, 'Exposed UUIDs found')
}说明:在我们发送给大模型的提示词中明确说明不要从CRM系统获取UUID,针对这样的明确的规则要求,完全可以通过以上的硬性规则代码进行验证。
在Rechat应用中有几百个类似的单元测试,我们还在持续的根据日志中所发现的报错信息不停的增加这样的检查点,这些日志都来自用户的实际使用场景。这种迭代方式帮助我们可以很快的解决用户问题,同时确保类似的问题不会再次出现。对于引入了提示工程,RAG和微调实践的大模型应用,很多场景会变得非常不可控;引入单元测试可以帮助我们让这些不可控的部分隔离开,帮助我们更快的定位问题并提高我们的迭代速度和频率。
使用大模型生成测试用例
为了达到较高的测试覆盖率,我们需要编写/生成大量的测试场景。这个时候大模型就可以派上用场了,我们经常会编写一些内部提示词来生成大量的测试场景(我们称之为数据合成)。具体做法也很简单,以下这个示例就可以很容易的说明问题。
编写50条不同的指令,供房地产经纪人指导其助手在其客户关系管理系统(CRM)中创建联系人。联系人的详细信息可以包括姓名、电话、电子邮件、伴侣姓名、生日、标签、公司、地址和工作。
对于每条指令,你需要生成第二条指令,用于查找创建的联系人。
以下是输出示例,请严格按照这个格式输出指令,不要输出任何其他内容
[
["创建一个联系人,姓名:约翰 (johndoe@apple.com)",
"请问约翰的邮件地址是什么?"]
]下图是使用集成在IDEA开发工具中的集成的AISE对话窗口执行以上提示词的过程
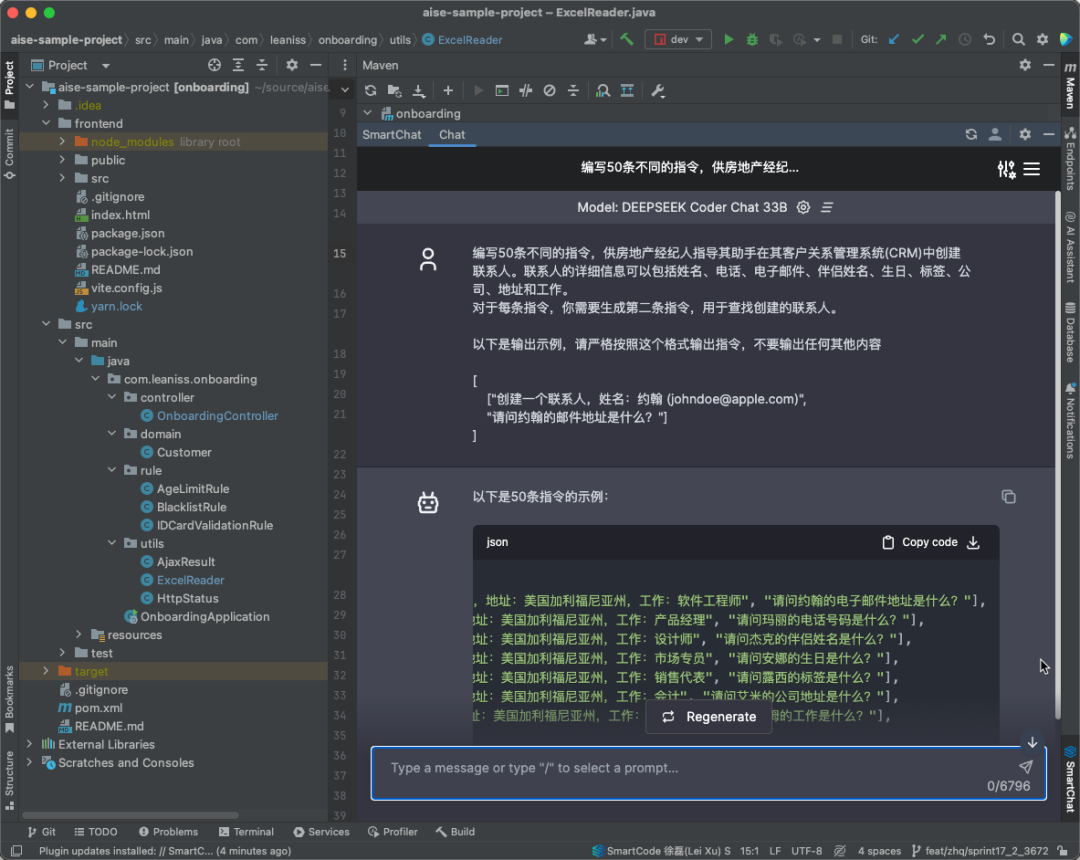
以下是生成的数据示例
[
["创建一个联系人,姓名:约翰,电话:1234567890,电子邮件:johndoe@apple.com,伴侣姓名:玛丽,生日:1990-01-01,标签:朋友,公司:苹果,地址:美国加利福尼亚州,工作:软件工程师", "请问约翰的电子邮件地址是什么?"],
["创建一个联系人,姓名:玛丽,电话:0987654321,电子邮件:mary@apple.com,伴侣姓名:约翰,生日:1991-02-02,标签:家人,公司:苹果,地址:美国加利福尼亚州,工作:产品经理", "请问玛丽的电话号码是什么?"],
["创建一个联系人,姓名:杰克,电话:1357924680,电子邮件:jack@apple.com,伴侣姓名:安娜,生日:1992-03-03,标签:同事,公司:苹果,地址:美国加利福尼亚州,工作:设计师", "请问杰克的伴侣姓名是什么?"],
["创建一个联系人,姓名:安娜,电话:2468135790,电子邮件:anna@apple.com,伴侣姓名:杰克,生日:1993-04-04,标签:同事,公司:苹果,地址:美国加利福尼亚州,工作:市场专员", "请问安娜的生日是什么?"],
["创建一个联系人,姓名:露西,电话:1234567890,电子邮件:lucy@apple.com,伴侣姓名:艾米,生日:1994-05-05,标签:朋友,公司:苹果,地址:美国加利福尼亚州,工作:销售代表", "请问露西的标签是什么?"],
["创建一个联系人,姓名:艾米,电话:0987654321,电子邮件:emma@apple.com,伴侣姓名:露西,生日:1995-06-06,标签:家人,公司:苹果,地址:美国加利福尼亚州,工作:会计", "请问艾米的公司地址是什么?"],
["创建一个联系人,姓名:汤姆,电话:1357924680,电子邮件:tom@apple.com,伴侣姓名:苏珊,生日:1996-07-07,标签:同事,公司:苹果,地址:美国加利福尼亚州,工作:人力资源", "请问汤姆的工作是什么?"]
]另外,我们再编写一段单元测试代码读取以上数据,发送给Rechat系统的API,然后通过另外一个API发送查询信息,最后验证返回的结果是否为1。通过这种方法,我们可以快速的构建大量的测试来验证系统的可靠性。同时,我们还会持续监控系统日志,找出那些没有包含进去的边界条件,持续补充到我们的测试集中。这里面最关键的是,我们需要在测试这个环节创造尽量复杂的场景,以便确保用户在使用过程中不会超出我们可预见的范围。
当然,这些测试并不需要依赖生产环境的数据,稍微动一动脑子再加上大模型的辅助,你可以很快的制造/合成出大量的边界场景。如果你发现系统在你设计/合成的数据上已经会出现一些无法处理的情况,那么恭喜你,你的测试集的覆盖率已经达到一个比较好的状态了。毕竟,大模型本身的头脑风暴能力很多时候比你的用户还要更厉害。
最后一点很重要,不要追求这些测试100%通过,因为我们面对的是一个不确定性系统,因此我们的测试也只需要达到一个可接受的通过率就够了,至于具体是多少,还是需要你自己在实践中去逐步探索。
自动频繁的运行单元测试
有很多办法可以自动的运行单元测试,Rechat团队使用CI流水线来运行这些测试集并且自动的收集测试结果。我们同时还会使用可视化的仪表盘来检视测试的改进情况,如下图:
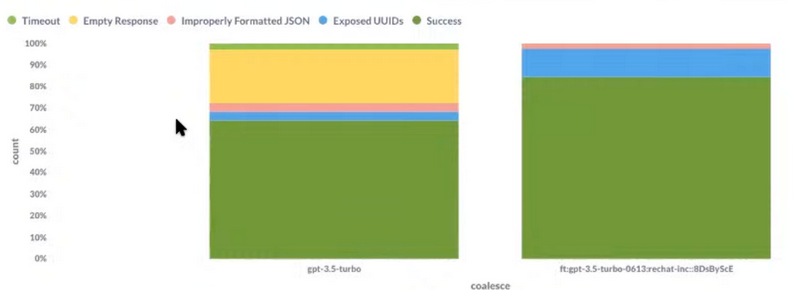
你会注意到上图中的黄色部分在后续的版本中大幅减少(用户ID暴露问题),这样我们可以非常直观的看到系统的改进。
人工和模型验证
在单元测试的基础上,我们还需要一层更加复杂的验证方法,这一层的验证往往无法通过一个简单assertion达成,而必须要引入人工测试和模型测试。但是要实现这一层测试,你首先需要解决日志和监控问题;因为这一层测试需要关注更加真实的用户场景。
日志和监控是每一个软件系统都必须内置的基础能力,在大模型的场景下,这些日志会帮助你跟踪所有发送给模型的请求以及模型的输出。查看日志有很多中方式,在Rechat团队,我们使用 Langsmith 来管理日志,LangSmith的日志和跟踪功能非常好用,提供用户友好的界面来查看日志内容,并且可以通过playground来逐条查看日志,同时在支持在这些日志上进行各种实验。很多时候,日志检视需要我们同时查看代码,因为Rechat团队同时使用 LangChain 作为开发框架,使得我们可以很容易的在日志和代码之间进行对应。
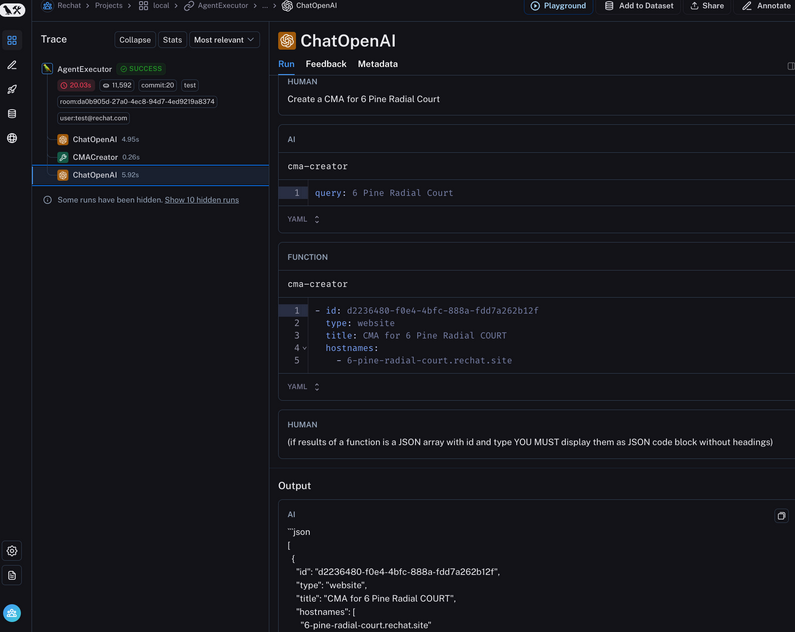
在实际开发中,查看和定位日志内容是一件很繁琐的工作,因为日志往往会分散在各种地方。因此,一个高效工程团队的首要工作就是让开发人员可以很容易的获取到日志。在Lucy的开发过程中,我们需要同时参考很多系统的日志才能正确的理解AI的行为,包括主进程,CRM,数据库等等。构建一个可以让开发人员汇集所有这些数据的内部工具变得非常重要。在Lucy系统中,我们聚合了以下这些信息协助开发者快速做出判断:
当前的请求来自哪个系统模块/特性
当前的日志是真实的用户请求还是测试数据,或者AI合成的数据
允许用户针对这些属性进行灵活的过滤
在每个可能的地方添加链接,允许开发人员快速跳转到对应的系统的特性位置
下面的截图是我们在Rechat系统中构建的一个内部工具,专门用于逐条处理系统日志
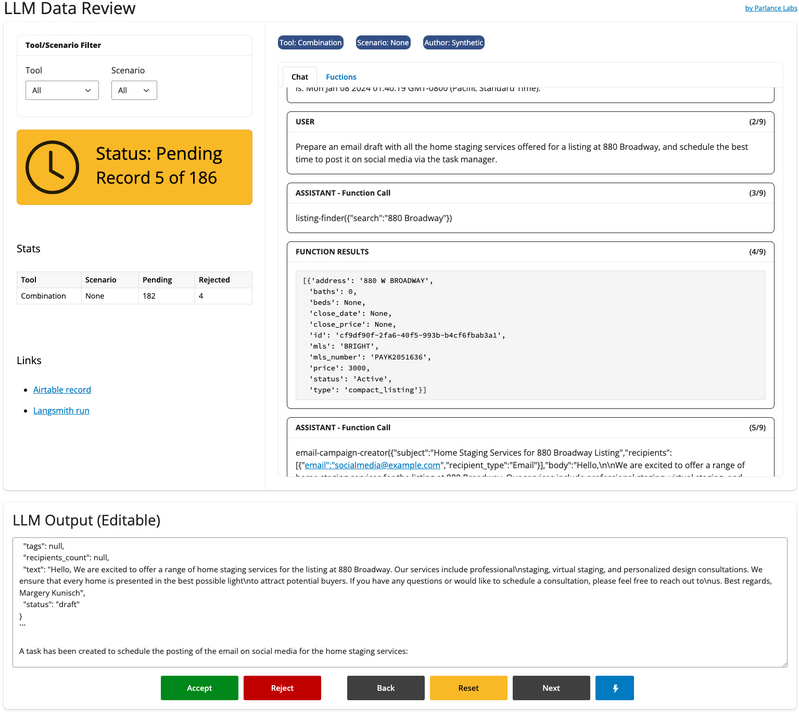
这些经过检视的日志数据非常有价值,很多时候我们会将大模型的数据输出进行人工调整,然后将这些数据直接加入下一个迭代的微调数据集,这些经过精细化人工调整的高质量数据其实是真正推动微调质量提升的关键点。
在进行了以上工作之后,很重要的一点还是测试,在将所有这些人工修改的数据推送到LLMOps流水线自动执行之前,一定要通过单元测试验证这些数据,否则第二天你可能就会到一个训练失败的微调模型。
到底要检视多少数据?
这是一个经常被问到的问题。现实的情况是,在开始阶段你需要检视每一条数据;即使到了后期,所有测试用例中的数据以及合成的数据都应该由人工进行检视。这个工作量确实很大,但是天下没有免费的午餐。
对于日志和监控数据,可以指定采样规则检视部分数据。
让大模型来检视数据
很多厂商会宣称可以自动的完成所有的数据检视,不需要人工介入;不要相信这样的市场宣传,因为100%的自动检视大模型生成结果是不可能的,对于一个不确定答案的生成系统提供一个确定性的验证系统,这本身就是一个悖论。
但是,我们完全可以利用大模型来一定程度上协助我们来完成这个检视工作,特别是使用一个更高阶的模型GPT-4去验证相对低阶模型的生成结果,比如:GPT3.5或者国内的一些大模型。这就是所谓的用魔法打败魔法。你需要牢记的是,人永远是最高阶的检视者,因为现有的模型在推理能力上还达不到人类的程度。
结合大模型和人工两种模式来验证是当前最可行,也是最可靠的验证方式。以下的Excel文件就是这样一个示例,其中包含了几列数据,各有各的用途
Model response: 这是模型的输出内容(来自日志)
Model crtique/outcome: 这是使用另外一个更高阶模型,配合特殊编写的提示词生成的检视结果
后面的几列则来人工验证
Agreement: 标识当前数据是否通过

持续的使用这种方式,并且借助Excel内置的统计功能,我们可以很容易的看到进展并且设定目标;比如下图就可以看到在3轮版本迭代中通过率的提升的情况。
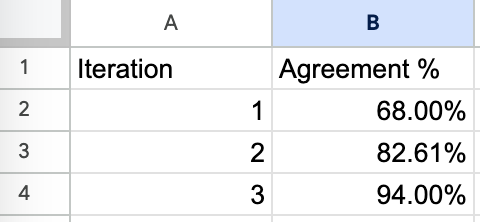
这里的几点建议:
使用你能找到最高阶的模型来生成模型检视信息;这样做可能会比较耗时费钱,但是在这个节点上的任何投入其实对于生产环境的质量提升都是巨大的。
用来生成模型检视信息的提示词也需要持续优化,不好的提示词可能会直接影响你的检视效果。
人工检视过程除了关注应用本身的生成效果之外,也要同时关注上述的模型检视信息的质量,并持续优化这个提示词
这里在分享一个小技巧:以上由模型生成的检视信息,其实也可以用来作为进一步微调的数据来源。
A/B测试
大模型应用的A/B测试和传统应用没有本质区别,当你建立了完善的日志和监视系统后,正确的评估A/B测试结果可以有效的帮助你判断新特性的用户体验。
RAG系统测试
RAG在整个AI系统中的作用越来越重要,对于RAG系统的评估需要一套独立的体系,我会另外写一篇文章来分析和说明这个话题。
微调数据生成/合成
在构建了完善的验证和日志检视机制之后,你会发现构建高质量微调数据这个问题也迎刃而解。实际上,微调工作中99%的精力都是在准备高质量的微调数据。
首先需要明确的是,微调的目标是调整模型的行为,模式,输出格式,风格;而不是为模型添加数据。有关这一点,可以参考 提示工程、RAG和微调 - 哪个才是大模型应用优化的最佳路径?
实际上,那些用来生成测试数据的提示词基本上可以直接拉过来生成微调数据,当然你不能直接使用这些数据,因为微调训练数据和验证数据是需要严格区分的,不然验证数据无法起到应有的验证目的,这就好像在让大模型做开卷考试一样。
我把以上用来生成测试数据的提示词也放在这里作为参考,但是一定记得不要用同一套数据做微调和验证。
编写50条不同的指令,供房地产经纪人指导其助手在其客户关系管理系统(CRM)中创建联系人。联系人的详细信息可以包括姓名、电话、电子邮件、伴侣姓名、生日、标签、公司、地址和工作。
对于每条指令,你需要生成第二条指令,用于查找创建的联系人。
以下是输出示例,请严格按照这个格式输出指令,不要输出任何其他内容
[
["创建一个联系人,姓名:约翰 (johndoe@apple.com)",
"请问约翰的邮件地址是什么?"]
]结论
验证系统的构建是推动你的产品的成长飞轮的重要一环,只有具备了有效的验证系统,这个飞轮才能形成闭环,才能真的从一个DEMO变成可以实际使用的系统。在经过了1年多的AISE和SmartCode开发之后,我在阅读 Hamel Husain 的这篇博客的时候感触颇深,真心希望这些经验可以帮助正在开发大模型应用的开发者和企业找到正确工程化方法,构建出更加优质的AI应用。
这里对文章的一些关键点再小结一下:
让开发人员尽可能简单的获取所有数据
越简单的工具越有效,不要迷信那些厂商的工具,很多时候你只需要自己写个几十行的脚本
检视数据是艰苦的,但这是通向高质量AI应用的唯一路径
不要依赖通用的验证系统,AI系统的场景决定了通用系统无法解决问题,你需要构建自己的工具链
多写测试并尽可能频繁的运行这些测试
用魔法打败魔法,借用大模型本身就可以快速构建你自己的验证系统和数据,包括
生成测试案例代码和测试数据
生成和合成数据
用大模型来检视数据
验证系统本身就是最好的训练数据生成系统
长按下图关注【数字共生】,让我们一起学习和智能体共同进化
如果您希望和我直接交流,可以在公众号后台回复:徐磊,加我的个人微信,
非常感谢。

最后列出我参与编写和翻译的几本书籍,感谢大家的支持。


















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









