






大年初五迎财神,祝大家和我们一起财源滚滚!
今天讨论个话题,因为我们发现蒸馏后的效果总是...或者不总是很理想,但是受限于某些条件我们又不得不蒸馏。
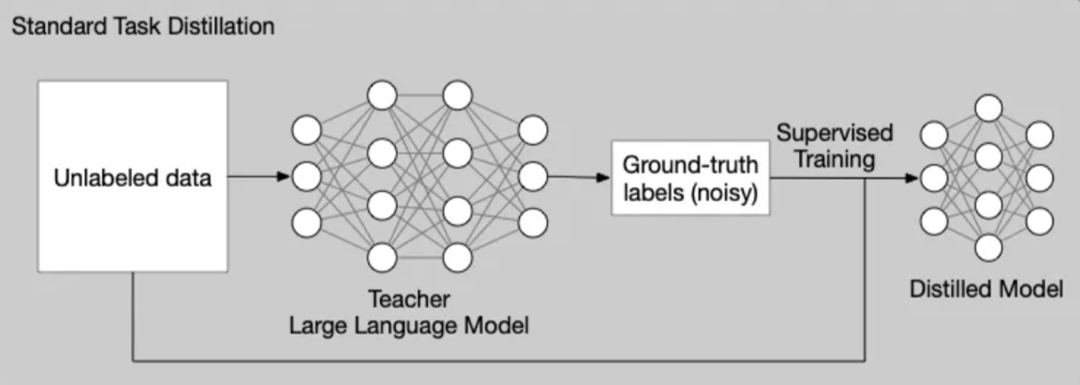
知识蒸馏是一种非常有效的模型压缩技术,其核心思想是将大型教师模型学到的知识迁移到较小的学生模型中。
可能的应用场景和研究方向:
多阶段蒸馏:
将大型模型的知识分阶段蒸馏到多个学生模型中,以获取不同粒度和层次的知识。
自适应蒸馏:
根据下游任务的特点,自适应地调整蒸馏过程,以获得最优的性能。
联邦蒸馏:
在联邦学习的框架下进行知识蒸馏,保护数据隐私的同时提高模型性能。
然而,在实际应用中,我们经常会遇到蒸馏后的模型性能不如预期的情况。这其中的原因是多方面的,下面我们来逐一分析:
1. 教师模型的选择
模型质量:
教师模型的质量直接影响学生模型的性能。如果教师模型本身存在过拟合或欠拟合等问题,那么蒸馏出来的学生模型也会继承这些问题。
模型复杂度:
教师模型过于复杂,学生模型难以完全学习其知识。
任务适配性:
教师模型和学生模型所针对的任务不完全一致,也会影响蒸馏效果。
2. 蒸馏方法的选择
损失函数的设计:
损失函数的设计直接影响学生模型的学习目标。如果损失函数设计不合理,学生模型可能无法有效地学习教师模型的知识。
温度参数的设置:
温度参数是知识蒸馏中的一个重要超参数,其值过大或过小都会影响蒸馏效果。
蒸馏目标的选择:
蒸馏目标可以是教师模型的输出概率、中间层特征等。不同的蒸馏目标会产生不同的蒸馏效果。
3. 学生模型的结构
模型容量:
学生模型的容量过小,无法完全承载教师模型的知识。
模型架构:
学生模型的架构与教师模型的架构差异过大,不利于知识的迁移。
4. 训练过程中的问题
过拟合:
学生模型容易过拟合教师模型的输出,导致泛化性能下降。
训练不充分:
学生模型的训练时间不足,无法充分学习教师模型的知识。
5. 其他因素
数据集的不平衡:
训练数据的不平衡会影响模型的性能。
硬件资源的限制:
硬件资源的限制可能导致训练过程不稳定,影响蒸馏效果。
那么如何改善蒸馏后的模型性能呢?(以下都是理论上,实际操作就是个既要又要还要的过程)
精心选择教师模型:
选择一个性能稳定、泛化能力强的教师模型。
优化蒸馏损失函数:
设计一个合适的损失函数,平衡教师模型和学生模型之间的差异。
调整温度参数:
通过实验找到最合适的温度参数。
逐步增加蒸馏目标:
从简单的蒸馏目标开始,逐渐增加蒸馏目标的复杂度。
正则化:
使用适当的正则化方法来防止过拟合。
数据增强:
通过数据增强来增加训练数据的多样性。
另外一个话题是我发现其实但是蒸馏这个词其实不贴切,分馏这个词可能更靠谱一些。只不过因为历史原因或者简化的原因大家都讲蒸馏。这俩有啥区别呢。
将知识蒸馏(Knowledge Distillation)与分馏(Fractional Distillation)进行类比,确实能从另一个角度来理解知识蒸馏的过程。
为什么说“蒸馏”不如“分馏”更贴切?
分馏过程的精细性:
分馏过程是将沸点不同的液体混合物分离成纯净组分的过程。在这个过程中,不同沸点的成分在分馏柱中多次气化、冷凝,最终得到纯度较高的不同馏分。这与知识蒸馏中,将大型模型的“知识”逐步转移到小型模型的过程非常相似。大型模型可以看作是包含多种“知识”的混合物,通过蒸馏,我们可以将其中特定的“知识”提取出来,并浓缩到小型模型中。
知识的层次性:
大型模型学习到的知识可以看作是不同层次的。通过分馏,我们可以将这些知识按照不同的“沸点”进行分离,即提取不同层次的知识。例如,我们可以将模型学到的浅层特征(如词向量)和深层特征(如语义信息)分别提取出来,再分别蒸馏到不同的学生模型中。
为什么知识蒸馏不直接称为“分馏”?
历史原因:
知识蒸馏这个术语已经广泛使用,且其含义在机器学习领域已经得到了普遍认可。
概念差异:
虽然两者在过程上有相似之处,但知识蒸馏和分馏在本质上还是有区别的。分馏是一个物理过程,而知识蒸馏是一个信息处理过程。
知识的抽象性:
与物质的分馏不同,知识的“蒸馏”过程更加抽象,涉及到模型架构、损失函数、优化算法等多个方面的设计。
将知识蒸馏比喻为分馏,有助于我们更直观地理解这个过程。 分馏强调了知识蒸馏中知识的分离和提纯,以及不同层次知识的处理。然而,由于历史原因和概念上的差异,知识蒸馏这个术语已经深入人心。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









