







最近弄了一个用户发表评论的功能,用户上传了评论,再文章下可以看到自己的评论,但作为社会主义接班人,践行社会主义核心价值观,所以给评论敏感词过滤的功能不可少,在网上找了资料,发现已经有非常成熟的解决方案。
常用的方案用这么两种
全文搜索,逐个匹配。这种听起来就不够高大上,在数据量大的情况下,会有效率问题,文末有比较
DFA算法-确定有限状态自动机
DFA算法介绍
DFA是一种计算模型,数据源是一个有限个集合,通过当前状态和事件来确定下一个状态,即 状态+事件=下一状态,由此逐步构建一个有向图,其中的节点就是状态,所以在DFA算法中只有查找和判断,没有复杂的计算,从而提高算法效率
实现逻辑
构造数据结构
将敏感词转换成树结构,举例敏感词有着这么几个 ['日本鬼子','日本人','日本男人'],那么数据结构如下(图片引用参考文章)
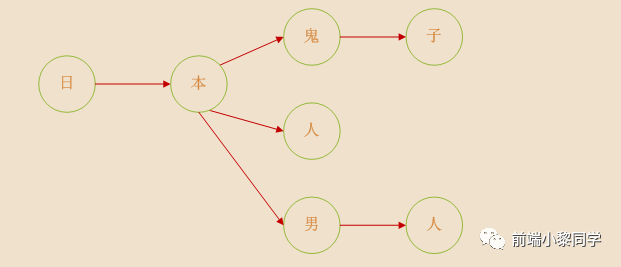
每个文字是一个节点,连续的节点组成一个词,日本人对应的就是中间的那条链,我们可以使用对象或者map来构建树,这里的栗子采用map构建节点,每个节点中有个状态标识,用来表示当前节点是不是最后一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









