






1.JPA的实体生命周期:
JPA的实体有以下4中生命周期状态:
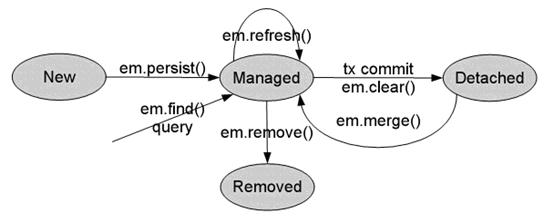
(1).New:瞬时对象,尚未有id,还未和Persistence Context建立关联的对象。
(2).Managed:持久化受管对象,有id值,已经和Persistence Context建立了关联的对象。
(3).Datached:游离态离线对象,有id值,但没有和Persistence Context建立关联的对象。
(4).Removed:删除的对象,有id值,尚且和Persistence Context有关联,但是已经准备好从数据库中删除。
四种状态总结:
状态名 作为java对象存在 在实体管理器中存在 在数据库存在
New yes no no
Managed yes yes yes
Detached no no no
Removed yes yes no
2.JPA实体状态的切换:
JPA实体的四种状态之间可以进行切换,具体如下:
3.容器管理和应用程序管理的EntityManager实体管理器:
在JPA中有两种管理实体管理器的方法:
(1).容器管理(Container-Manager)的实体管理器:
容器管理实体管理器,是由JavaEE容器所管理的实体管理器,通过PersistenceContext注入方式来生成实体管理器,具体代码如下:
@PersistenceContext(unitName=”持久化单元名称”)
Protected EntityManagerem;
(2).应用程序管理(Application-Manager)的实体管理器:
JPA不但可以在JavaEE容器中使用,也可以脱离JavaEE容器在JavaSE程序中使用,当JPA脱离了JavaEE服务器环境时,就需要通过应用程序来获取实体管理器,具体代码如下:
a. 代码方式:
//首先根据持久化单元创建实体管理器工厂
EntityManagerFactoryemf = Persistence.createEntityManagerFacotory(持久化策略文件中的持久化单元名称);
//通过实体管理器工厂创建实体管理器
EntityManager em= emf.createEntityManager();
b. 注解方式:
//将持久化单元注入实体管理器工厂中
@PersistenceUnit(持久化单元名称)
protected EntityManagerFactory emf;
protected EntityManager em = emf.createEntityManager();
注意:当持久化策略文件中只有一个持久化单元时,在注解中不用指定支持化单元名称。
4.JPA实体管理器的常用方法:
(1).find查找:相当于Hibernate中的get操作,如果一级缓存查找不到会立即去数据库查找,如果查找不到会返回null。
(2).getReference查找:相当于Hibernate中的load操作,如果一级缓存查找不到并不立即去数据库查找,而是去查找二级缓存,返回实体对象的代理,如果查找不到会抛出ObjectNotFindException。
(3).persist:使实体类从new状态或者removed转变到managed状态,并将数据保存到底层数据库中。
(4).remove:将实体变为removed状态,当实体管理器关闭或者刷新时,才会真正地删除数据。
(5).flush:将实体和底层数据库进行同步,当调用persist、merge或者remove方法时,更新并不会立刻同步到数据库中,直到容器决定刷新到数据库中时才会执行,可以调用flush强制刷新。
(6).createQuery:根据JPA QL定义查询对象。
(7).createNativeQuery:允许开发人员根据特定数据库的SQL语法来进行查询操作,只有JPA QL不能满足要求时才使用,不推荐使用,因为增加了程序可移植性。
(8).createNamedQuery:根据实体中标注的命名查询创建查询对象。
(9).merge:将一个detached的实体持久化到数据库中,并转换为managed状态。
5.JPA分页查询:
(1).为实体管理器创建的查询对象设置返回最大结果数:setMaxResults(int maxResult);
(2).为实体管理器创建的查询对象设置返回结果开始下标:setFirstResult(int firstResult);
6.JPA中调用存储过程:
注意:JPA中只能调用两种存储过程:1.无返回值的存储过程。2.返回值为ResultSet的存储过程(不能是out)。
实体管理器的createNativeQuery(”{call 存储过程名()}”);即可调用数据库的存储过程。
7.JPA的命名参数:
语法:“:参数名”。
例如:
Query query = entityManager.createQuery(”selectu from User u where u.name=:name”);
//设置查询中的命名参数
Query.setParameter(“name”, testName);
注意:不允许在同一个查询中使用两个相同名字的命名参数。
8.JPA的位置参数:
语法:“?位置参数索引”。
例如:
Query query = entityManager.createQuery(”selectu from User u where u.name=?1”);
//设置查询中的位置参数
Query.setParameter(1, testName);
注意:JPA中的位置参数索引值从1开始。
9.JPA的集合查询:
我们知道在SQL语句中,查找某元素是否在某个集合中时常用类似:in(a,b,c)的查询语句,在JDBC中我们常常需要将集合元素拼接成以逗号(“,”)分隔的字符串,在JPA中有两种方法可以方便地进行判断元素是否在集合中的查询:
(1).设置集合类型的参数:
查询对象的setParameter方法支持Object类型,因此可以传入一个集合类型的参数,如数组或者ArrayList等。
例如:
Query query = em.createQuery(“select * fromUsers where name in(?names)”);
query.setParameter(“name”, names);//names是一个name集合
(2).使用member of关键字:
例如:
Select t from Topic t where :option memberof t.options;
10.JPA的回调方法:
JPA中,实体类支持一些回调方法,可以通过如下的注解指定回调方法:
(1).@PrePersist:在persist方法调用后立刻发生,级联保存也会发生该事件,此时数据还没有真实插入数据库中。
(2).@PostPersist:数据已经插入进数据库中后触发。
(3).@PreRemove:在实体从数据库删除之前触发。级联删除也会触发该事件,此时数据还没有真实从数据库中删除。
(4).@PostRemove:在实体已经从数据库中删除后触发。
(5).@PreUpdate:在实体的状态同步到数据库之前触发,此时数据还没有真实更新到数据库中。
(6).@PostUpdate:在实体的状态同步到数据库后触发,同步在事务提交时发生。
(7).@PostLoad:在以下情况触发:
a.执行find或者getReference方法载入一个实体之后。
b.执行JPA QL查询之后。
c.refresh方法被调用之后。
11.事务管理特性:
事务所数据库的一个逻辑工作单元,包含一系列的操作,事务有四个特性,即ACID特性:
(1).Atomic(原子性):
事务中的各个操作不可分割,事务中所包含的操作被看作一个逻辑单元,这个逻辑单元中的操作要么全部成功,要么全部失败。
(2).Consistency(一致性):
一致性意味着,只有合法的数据才可以被写入数据库,如果数据有任何不符合,则事务应该将其回滚。
(3).Isolation(隔离性):
事务允许多个用户对同一个数据的并发访问,而不破坏数据的正确性和完整性。同时,并行事务的修改必须与其他并行事务的修改相互独立。按照比较严格隔离逻辑来讲,一个事务看到的数据要么是另外一个事务修改这些数据之前的状态,要么是一个事务已经修改完成的数据,决不能是其他事务正在修改的数据。
(4).Durability(持久性):
事务结束后,事务处理的结果必须能够得到持久化。
12.数据操作过程中可能会出现的3中不确定情况:
(1).脏读取:
一个事务读取了另一个并行事务未提交的数据。
(2).不可重复读:
一个事务再次读取之前曾经读过的数据时,发现该数据已经被另一个已提交的事务修改。
(3).幻读:
同一查询在同一事务中多次进行,由于其他事务提交所做的操作,使得每次返回不同的结果集,从而产生换读。
13.事务的隔离级别:
事务的隔离,是指数据库(或其他事务系统)通过某种机制,在并行的多个事务之间进行分割,使得每个事务在其执行过程中保持独立,如同当前只有一个事务在单独运行。为了避免12中3中不确定情况的发生,标准的SQL规范中定义了如下4中事务隔离级别:
(1).为提交读:
最低等级的事务隔离,仅仅保证了读取过程中不会读取到非法数据。
(2).已提交读:
该级别的事务隔离保证了一个事务不会读取到另一个并行事务已修改但未提交的数据,避免了脏读。大多数主流数据库默认的事务隔离等级是已提交读。
(3).重复读:
该级别的事务隔离避免了脏读和不可重复读,但是也意味着,一个事务部可能更新已经由另一个事务读取但未提交的数据。
(4).序列化:
最高等级的事务隔离,也提供了最严格的隔离机制,上面3种不确定情况都可以被避免。该级别将模拟事务的串行执行,逻辑上如同所有的事务都处于一个执行队列中,依次串行执行,而非并行执行。
4种事务隔离级别总结:
隔离等级 脏读 不可重复读 幻读
未提交读 可能 可能 可能
提交读 不可能 可能 可能
重复读 不可能 不可能 可能
序列化 不可能 不可能 不可能
9. JDBC事务和JTA事务:
JDBC事务:只能支持一个数据库,单数据源,一个由数据库本身来执行提交或回滚,单阶段提交,本地事务。JDBC事务由Connection管理,事务周期局限于Connection的生命周期之内。
JTA事务:JTA提供了跨Session的事务管理能力,支持多数据源的分布式事务,两阶段提交。JTA事务管理由JTA容器实现,JTA容器对当前加入事务的众多Connection进行调度,实现其事务性要求,JTA的事务周期可横跨多个JDBC Connection生命周期。
10. 事务的传播特性:
事务传播特性是用于指定当进行操作时,如何使用事务,JPA中有以下6种事务传播特性:
(1).Not Support:不支持,若当前事务有上下文,则挂起。
(2).Support:支持,若有事务,则使用事务,若无事务,则不使用事务。
(3).Required:需要,若有事务,则使用使用,若无事务,则创建新的事务。
(4).Required New:需要新事务,每次都会创建新的事务。
(5).Mandatory:必须有事务,若无事务,则将抛出异常。
(6).Never:必须不能有事务,若有事务,则会抛出异常。
16.锁的机制:
所谓锁,就是给选定的目标对象加上限制,使其无法被其他程序所修改,JPA支持两种锁机制:乐观锁和悲观锁。
(1).悲观锁:
对数据被外界修改持保守态度,在整个数据处理过程中,将数据处于锁定状态,悲观锁的实现,往往依靠数据库提供的锁机制。最常用的悲观锁是在查询时加上“for update“,用法如下:
Select * from user where name=”test” forupdate
在JPA中,可以通过给Query对象设置锁模式(query.setLockMode)来制定悲观锁的模式:
a.LockMode.NONE:无锁机制。
b.LockMode.WRITE:在insert和update时会自动加锁。
c.LockMode.READ:在读取记录时会自动加锁。
d.LockMode.UPGRADE:利用数据库的for update字句加锁。
(2).乐观锁:
相对于悲观锁,乐观锁机制采用较为宽松的加锁机制,悲观锁大多数情况下依靠数据库锁的机制实现,以保证操作最大程度的独占性,但是数据库的性能开销比较大。而乐观锁大多数基于数据版本(version)记录或者时间戳机制实现。
基于版本的乐观锁在读取数据时将数据的版本号一同读出,之后更新则对版本号加1,提交时对数据的版本与数据库中对应的版本进行比较,如果提交数据数据版本号打于数据库中当前版本号,则予以更新,否则认为是过期数据。乐观锁大大减小了数据库开销,提高了程序的性能。
JPA中可以在实体中使用@Version注解指定其使用乐观锁,JPA会在数据库对应的表中自动生成和维护一列版本号。
17.Spring集成JPA:
JPA不但可以在JavaEE环境中使用,也可以还JavaSE环境中使用,spring现在在java开发中应用非常广泛,Spring同样提供了对JPA的强大支持。Spring集成JPA的步骤如下:
(1).在MATE-INF下添加JPA的持久化策略文件,开发实体bean。
(2).为工程引入Spring支持。添加Spring相关依赖包和spring配置文件。
(3).在spring配置文件中加入JPA配置如下:
<bean id=”entityManagerFactory”
class=”org.springframework.orm.jpa.LocalEntityManagerFactoryBean”>
<propertyname=”persistenceUnitName” value=”持久化单元名称”/>
</bean>
<bean id=”transactionManager”
class=”org.springframework.orm.jpa.JpaTransactionManager”>
<propertyname=”entityManagerFactory” ref=” entityManagerFactory”/>
</bean>
<tx:annotation-driventransaction-manager=” transactionManager”/>
至此,Spring和JPA的简单集成完成。















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









