






分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
原贴:http://www.dbanotes.net/MT/mt-search.cgi
Matching entries matching “linux” from DBA notes
尽管是世界上最大的图片服务网站, Fotolog.com 在国内的名气并不是很响亮, 每当提到图片服务, 很多人第一个会想起 Flickr. 但实际上 Fotolog 也的确是很猛的, Alexa 上的排名一直在 Flickr 前面, 目前注册用户超过 1100 万. 而前不久也卖了一个好价钱, 9000 万美金. 算下来的话, 1 个注册用户大约 9 美金. Yupoo 的刘平阳可以偷着算算自己的网站如果卖给老外是怎样一个价格了.
在前不久的 MySQL Con 2007 上, Fotolog 的 DBA Farhan Mashraqi 披露了一些技术信息.(PPT下载)
与其他大多数 Web 2.0 公司普遍用 Linux 不同的是, Fotolog 的操作系统用的是 Solaris . Solaris X86 也是免费的, 估计是维护人员更熟悉 Solaris 的操作系统而作出的选择吧.
数据库当然是使用 MySQL. 有32 台之多, 最开始的存储引擎是 MyISAM ,后来转向 InnoDB. 对于 DB HA , 使用 DRBD (介绍),在 Solaris 上用 MySQL ,有个优化技巧是关于 time(2) 系统调用的,通过调用比 gethrestime() 更快的 gethrtime(3C) 来提高性能。可以通过设置 LD_PRELOAD (32位的平台) 或 LD_PRELOAD_64 来做到。详细信息可以参考Sun 站点上的这篇 MySQL 优化文章,很有参考价值。
存储也是值得一说的,Fotolog 用的是 SAN,还是比较贵的 SAN: 3Par. 这个产品可能绝大多数 DBA 是比较陌生的,该产品原来主打金融市场,现在也有很多 Web 公司使用,一个比较典型的客户代表是 MySpace。3Par 的最大的特点就是 Thin Provisioning。Thin Provisioning 这个词有的人翻译为"自动精简配置",在维基百科的定义:
Thin provisioningis a mechanism that applies to large-scale centralized computer disk storage systems, SANs, and storage virtualization systems. Thin provisioning allows space to be easily allocated to servers, on a just-enough and just-in-time basis.
说白了就是对空间分配能够做到"按需分配"。有些扯远了。
--EOF--
昨天晚上和 Laura 出去吃饭,吃过饭走回来,路蛮远的,慢慢忍不住了,人有三急,可路边找不到厕所。忍啊忍,来的时候记得路边有家小书店,书店里估计有厕所,走啊走,忍啊忍,总算看到书店了,进去假装买书,想用人家厕所还担心不给用,于是挑了一本书,然后(装作)随口问道 "有洗手间嘛?" 服务员一指: 前面就是。急匆匆进去,傻眼,真的是"洗手"间 -- 只能洗手。
同事 Z 早晨就在公司测试能不能把 Linux 的系统时间调整到 1970 年以前,问他为什么要这么做,他告诉我,周日在西湖边遇到了灵异事件:当他走到西湖某个点的时候,手机时间突然显示为 1912 年,而他的手机操作系统是 Linux 的,还说过了那个地点,时间就突然正常了。我说,时光倒流? 那你赶紧回那个点再测试一下? 他的回答:当时就想回去了,可考虑到民国史不熟,今天在网上学习一下再去。要不万一回到 1912 年咋办?
--EOF--
今天参加 AIX 的技术培训,听了一些关于 CPU 调度的算法,倒也都是些基本知识,回想讲课内容的时候倒让我想起 Linux Kernel 的 I/O Scheduler 来。
这篇 Choosing an I/O Scheduler for Red Hat Enterprise Linux 4 and the 2.6 Kernel 是必须的参考资料。相比 Linux 2.4 Kernel 的一种 IO 调度器,2.6 做了很多改进,共有四种 IO 调度器。
Deadline scheduler
Deadline scheduler 用 deadline 算法保证对于既定的 IO 请求以最小的延迟时间,从这一点理解,对于 DSS 应用应该会是很适合的。
Anticipatory scheduler
Anticipatory scheduler(as) 曾经一度是 Linux 2.6 Kernel 的 IO scheduler 。Anticipatory 的中文含义是"预料的, 预想的", 这个词的确揭示了这个算法的特点,简单的说,有个 IO 发生的时候,如果又有进程请求 IO 操作,则将产生一个默认的 6 毫秒猜测时间,猜测下一个 进程请求 IO 是要干什么的。这对于随即读取会造成比较大的延时,对数据库应用很糟糕,而对于 Web Server 等则会表现的不错。这个算法也可以简单理解为面向低速磁盘的,因为那个"猜测"实际上的目的是为了减少磁头移动时间。
Completely Fair Queuing
虽然这世界上没有完全公平的事情,但是并不妨碍开源爱好者们设计一个完全公平的 IO 调度算法。Completely Fair Queuing (cfq, 完全公平队列) 在 2.6.18 取代了 Anticipatory scheduler 成为 Linux Kernel 默认的 IO scheduler 。cfq 对每个进程维护一个 IO 队列,各个进程发来的 IO 请求会被 cfq 以轮循方式处理。也就是对每一个 IO 请求都是公平的。这使得 cfq 很适合离散读的应用(eg: OLTP DB)。我所知道的企业级 Linux 发行版中,SuSE Linux 好像是最先默认用 cfq 的.
NOOP
Noop 对于 IO 不那么操心,对所有的 IO请求都用 FIFO 队列形式处理,默认认为 IO 不会存在性能问题。这也使得 CPU 也不用那么操心。当然,对于复杂一点的应用类型,使用这个调度器,用户自己就会非常操心。
那么如果跑数据库应用,那个更好一些呢? 我们看Choosing an I/O Scheduler for Red Hat Enterprise Linux 4 and the 2.6 Kernel一文中的测试结果:
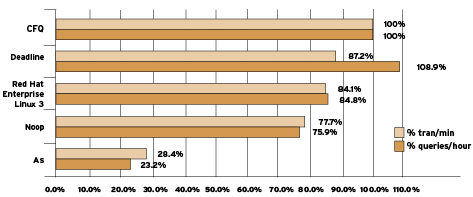
对于数据库应用, Anticipatory scheduler 的表现是最差的。Deadline 在 DSS 环境表现比 cfq 更好一点,而 cfq 综合来看表现更好一些。这也难怪 RHEL 4 默认的 IO 调度器设置为 cfq. 而 RHEL 4 比 RHEL 3,整体 IO 改进还是不小的。
哪一种方式更好? 很难说,每一种方式都有特定的应用对它是最适合的。就像上面的 as 好像表现比较差,如果是 CPU 密集型的应用呢?
Tip:
Q:如何确认当前用什么 IO 调度器?
A: 过滤 /var/log/boot.msg 文件, 查找 "io scheduler", 看到了么?
在 操作系统上可以查到的相关文档:
/usr/src/linux/Documentation/block/as-iosched.txt
/usr/src/linux/Documentation/block/deadline-iosched.txt
这篇文章应该只是一篇草稿...
--EOF--
![]()
上一篇 在 RHEL 5 上安装 Oracle 11g 还是比较粗糙的。对照官方手册 Oracle Database Installation Guide 11g Release 1 for Linux 还是遗漏了一些内容的。
关于 Oracle Inventory 用户组
图形界面起来后,先是判断 Oracle Inventory group 这个玩意儿(通过 oraInst.loc). 如果默认目录权限有问题,会有如下提示:
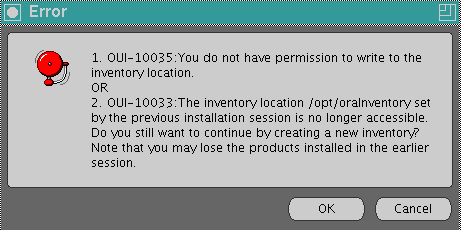
这个提示信息其实没什么,点击 OK 即可。然后会提示手工输入可替代 Inventory 地址。
OSASM 用户组
如果使用 ASM,则最好创建一个 OSASM 组:
# /usr/sbin/groupadd asadmin
创建实例前修改 Shell 限制
修改 /etc/security/limits.conf 文件. 添加内容如下:oracle soft nproc 2047oracle hard nproc 16384oracle soft nofile 1024oracle hard nofile 65536
修改(或创建) /etc/pam.d/login ,内容如下:
session required /lib/security/pam_limits.so
session required pam_limits.so
还差一步,修改 /etc/profile , 内容如下:
if [ $USER = "oracle" ]; then
if [ $SHELL = "/bin/ksh" ]; then
ulimit -p 16384
ulimit -n 65536
else
ulimit -u 16384 -n 65536
fi
fi
在 NFS 上跑 11g
mount nfs 文件系统上有几个参数是强制性的 : hard , rsize, wsize, actime=0(或者 noac). hard 方式是 10g 遗留下来的后遗症。
想到其他的再继续补充...
--EOF--
期待已久的 Oracle 11g 终于发布正式可以提供下载了。第一个发布的平台果然是 Linux 版本。几年前都是 Solaris 第一个。可见操作系统领域市场的变迁。
11g 的软件介质不小,单个文件,1.7G,这个文件是个大杂烩,包含了一大堆的组件。在 RHEL 5 上安装相对还是比较顺利。先需要看看我以前写的 10g 安装攻略。有时间的话,也不仿移步访问一下这篇:RHEL 上安装 Oracle 的注意事项
环境变量的变化
ORA_NLSxx 环境变量必须(?) 用 ORA_NLS10 ,以前在 10g 上还兼容的 ORA_NLS33 不能继续用的。
export ORA_NLS10=$ORACLE_HOME/nls/data
否则建库的时候会报告 ORA-12075 错误。
核心变量的设置
修改 /etc/sysctl.conf,追加如下内容:# First line:SEMMSL SEMMNS SEMOPM SEMMNI
kernel.sem=1055 32000 100 128
kernel.shmmax=2147483648
kernel.shmall = 2097152
net.ipv4.tcp_sack = 0
net.ipv4.tcp_timestamps = 0
net.ipv4.conf.default.rp_filter = 0
net.core.optmem_max = 65535
net.core.rmem_default = 4194304
net.core.wmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_max = 262144
fs.file-max = 6553600
net.ipv4.ip_local_port_range = 1024 65000
RHEL 5 默认安装几乎不用作额外配置,当然,要关闭 seLinux 和防火墙。./runInstaller 后图形界面起来,检查的时候也会报告 warning 信息,比如 libaio-devel 没有安装什么的。如果只是测试目的,倒是不用非那么多心思。
关于一些界面的变化,可以看我的 Yupoo 相册. 个人评价是 Oracle 对安装流程还是做了不少改进,有的地方相比 Oracle 10g 交代的更清楚一点。
--EOF--
Oracle 似乎越来越想直接填补 OS 与 RDBMS 之间的技术缝隙。之前的 ASM 已经向存储层跨了一大步,可以说是 Oracle 自己的 LVM 软件,而且,应该说也占据了一定的市场。然后是 OCFS (Oracle Cluster File System)更进一步--用于集群的文件系统,OCFS 的表现似乎还需要观察(主要是还不够稳定)。现在,Oracle 又准备开发新的文件系统了。这个项目名字叫做 Btrfs。
这个 Btrfs 的特性中列表:
- Extent based file storage (2的64次方 max file size)
- Space efficient packing of small files 【 vs ZFS: Built in compression】
- Space efficient indexed directories
- Dynamic inode allocation
- Writable snapshots
- Subvolumes (separate internal filesystem roots)
- Object level mirroring and striping 【对象级别的镜像与条带】
- Checksums on data and metadata (multiple algorithms available)
- Strong integration with device mapper for multiple device support 【似乎 Oracle 对当前 Linux 系统的 LVM 软件并不满意】
- Online filesystem check 【 vs ZFS: Always consistent on disk】
- Very fast offline filesystem check 【对于大文件系统十分有效】
- Efficient incremental backup and FS mirroring 【 vs ZFS: Fast native backup and restore】
【】内是我的注释或猜测。看得出来,Btrfs 应该参考了 Sun ZFS 的很多设计思想,而 Btrfs 的设计目的是面向数据库的,所以有很多独特的面向数据库的特性在里面。Btrfs 目前还在设计中,所有关键特性都实现并且成熟稳定恐怕还真是有待时日,Oracle 软件代码的质量那可真是叫人没话说--可不是好的让人没话说。
或许很多人已经忘记了 Oracle 多年以前失败的 Raw Iron 项目,但现在,Oracle 似乎在用搭机木的方式重新实现这个目标。
--EOF--
最近会议比较多,下周一到周四要跑到上海参加甲骨文全球大会(Oracle Open World)。
对于一个 DBA 来说,每次 OOW 的技术讲座肯定比那些到处派发的小奖品更加吸引人。刚才总算有空仔细看了一下本次 OOW 的技术讲座列表。我对如下几个主题比较感兴趣:
- Rich Niemiec 讲座序号 720: Oracle数据库11g的最佳新功能(一)
- Rich Niemiec 讲座序号 721: Oracle数据库11g的最佳新功能(二)
Oracle 11g 最早也要到 8 月份才可以发布,不过现了解一点新功能过把瘾还是不错的。
顺便说一下,Rich Niemiec 接受了 Alibaba DBA 团队的邀请,将于 OOW 之后在杭州举办一场 Tuning at Block Level 的技术演讲。如果有杭州的朋友感兴趣,可以联系我。给你预留座位。技术方面国外过来的人物,Rich Niemiec 算是这次 OOW 比较大的腕儿了。如果你不知道他是谁,可以忽略这一段。
其他感兴趣的主题有:
- 讲座序号 276: SQL Server向Oracle数据库迁移案例研究
- 讲座序号 221: Oracle数据卫士----开创数据可用性和数据保护的新纪元 (数据卫士, 就是 Data Guard,翻译的挺好......)
- 讲座序号 228: 如何利用 Oracle TimesTen 内存数据库大幅提高数据库管理软件的响应速度
- 讲座序号 222: 超大型数据库备份和恢复策略
- 讲座序号 238: Linux用户当然之选(Oracle Linux配置管理)
- 讲座序号 215: 利用Oracle Database Vault选件保护数据
Oracle OTN 中文网还有个 OTN Lounge,我需要参加的。主要是个陪衬 :) 基本上国内这几个 ACE 凑齐了。对于这次活动,可以参见 eygle 的介绍。
30 号晚上 ITpub 有个采访。主题是 《ITPub 5大 ACE 点评 Oracle 11g 数据库》. 其他的时间我还没有安排呢。或许去看看同学。对了,如果有朋友准备加入我们团队,可以直接和我联系 :)
周四我可能就必需要回到杭州了。
--EOF--
翻出以前写的这则: 恢复 EXT3 Superblock 的正确方法 , 补充几点内容。
1) 获取超级块位置
前文说过超级块的位置,对于一个未知的 Ext3 文件系统,也可以用 fsck 模拟对设备的格式化,输出的内容中会列出 Superblock 的位置。命令开关是 "-N".
Testdisk是一款超强的开源文件系统恢复工具,通过它也很容易检查到超级块的信息以及如何恢复,很关键的一点是,这个工具能检查到"可用"的超级块信息
有关分区表信息
有的时候,也有可能是分区表信息损坏。fdisk -l /dev/hdx 会提示该设备上没有任何分区信息。gpart 这个小工具恢复分区表比较有效。当然,前面介绍的 Testdisk 也能做到这一点,如果该设备上只有一个文件系统,那么直接 fdisk 处理一下也是可行的。
恢复 Ext 文件系统上删除的文件
Linux / Unix 没有 Windows 回收站这个概念,rm -rf 有的时候会造成一定的灾难。个别的时候,e2undel 能派上用场。
--EOF--
Linux 和Solaris是同源亲家。Linux这小老弟,近年来在这块跑得快些。可是 Solaris 路走多了,不需回头走冤枉路。
-- Sun中国工程研究院院长王星耀. 推荐阅读《Solaris 内核结构(第2版)》中文版序
很难确定过去几年来谷歌出色的表现,多大程度上是埃里克管理技能的结果,多大程度是他们当初灵机一动的结果--这个灵机一动,开发出了历史上最为成功的产品之一。
--华尔街分析师 Henry Blodget 评价 Google CEO 施密特 (Eric Schmidt)
怎样形容互联网呢?想象一下,从前有些商人是专门靠在沙漠里卖水赚钱的,可如今,沙漠开始下雨了。
--周奕. (前不久才知道他是周筠老师的弟弟)
我们今天坐在这里,就在这一时间,世界各地仍在上演着人间惨剧。这让我们感到心碎,我们之所以没有采取任何行动,并不是我们没有同情心,而是因为我们不知道如何去做。
--比尔·盖茨哈佛演讲
目前发现的问题员工主要是北京员工,主要是因为北京员工抗压能力很弱,不愿意吃苦。
--大旗网周春兰
几乎任何人都不可能提出理由证明中国股票价格不高。不过,就历史的市盈率和股息收益率来看,上海证券交易所的股价似乎并不比纳斯达克高多少。
--汇丰投资管理集团新兴市场业务全球主管狄圣莱(Deseglise Christian)
MySQL 应该给 Google 发感谢信: Google 在 Google Code 上发布的 Google Mysql Tools 使得 MySQL 在性能、可管理性、稳定性上都增色不少。
在该项目的首页将这个工具集分为三部分:
* mypgrep.py - a tool, similar to pgrep, for managing mysql connections
* compact_innodb.py - compacts innodb datafiles
by dumping and reloading all tables
* patches - patches to add features to MySQL 4.0.26 and MySQL 5.0.37
这份介绍似乎已经不能完全概括 Google Mysql Tools 了。现在的重点似乎是补丁包部分。根据版本号分为 MySQL4 与 MySQL 5,MySQL 5 的 Patch 现在很少,而 MySQL 4 部分内容真的比较丰富,关键改进列表:
* SemiSyncReplication - block commit on a master until at least one slave acknowledges receipt of all replication events.
* MirroredBinlogs - maintain a copy of the master's binlog on a slave
* TransactionalReplication - make InnoDB and slave replication state consistent during crash recovery
* UserTableMonitoring - monitor and report database activity per account and table
* InnodbAsyncIo - support multiple background IO threads for InnoDB InnoDB 异步IO的支持相信对性能会有很明显的提升
* FastMasterPromotion - promote a slave to a master without restart
MySQL 在联机备份方面是弱势,倒是期待 Google 也能在这个方面做出改进(我非常好奇对于 Google Checkout 数据库是如何备份的).
在 Code 上的另外一个 关键项目 Google Perftools 中的 TCMalloc 对 MySQL 的性能也有很大的改进,相信国内很多出色的 Web 2.0 公司都已经用到这个东西了吧。TCMalloc : Thread-Caching Malloc 号称是目前最快的 Malloc ,对于解决 MySQL 遇到的 Malloc 扩展问题有很大的影响。
没有 Google 的支持,相信 Firefox 不会有现在这么大的影响力。有了 Google 的支持, MySQL 会发展多快 ?
--EOF--
这篇 Bash Shell Shortcuts 的快捷键总结的非常好。值得学习。下面内容大多数是拷贝粘贴与总结.
CTRL 键相关的快捷键:
Ctrl + a - Jump to the start of the lineCtrl + b - Move back a charCtrl + c - Terminate the command //用的最多了吧?Ctrl + d - Delete from under the cursorCtrl + e - Jump to the end of the lineCtrl + f - Move forward a charCtrl + k - Delete to EOLCtrl + l - Clear the screen //清屏,类似 clear 命令Ctrl + r - Search the history backwards //查找历史命令Ctrl + R - Search the history backwards with multi occurrenceCtrl + u - Delete backward from cursor // 密码输入错误的时候比较有用Ctrl + xx - Move between EOL and current cursor positionCtrl + x @ - Show possible hostname completions Ctrl + z - Suspend/ Stop the command补充:Ctrl + h - 删除当前字符Ctrl + w - 删除最后输入的单词
ALT 键相关的快捷键:
平时很少用。有些和远程登陆工具冲突。Alt + < - Move to the first line in the historyAlt + > - Move to the last line in the historyAlt + ? - Show current completion listAlt + * - Insert all possible completionsAlt + / - Attempt to complete filenameAlt + . - Yank last argument to previous commandAlt + b - Move backwardAlt + c - Capitalize the wordAlt + d - Delete wordAlt + f - Move forwardAlt + l - Make word lowercaseAlt + n - Search the history forwards non-incrementalAlt + p - Search the history backwards non-incrementalAlt + r - Recall commandAlt + t - Move words aroundAlt + u - Make word uppercaseAlt + back-space - Delete backward from cursor
// SecureCRT 如果没有配置好,这个就很管用了。
其他特定的键绑定:
输入 bind -P 可以查看所有的键盘绑定。这一系列我觉得更为实用。Here "2T" means Press TAB twice$ 2T - All available commands(common) //命令行补全,我认为是 Bash 最好用的一点 $ (string)2T - All available commands starting with (string)$ /2T - Entire directory structure including Hidden one$ ./2T - Only Sub Dirs inside including Hidden one$ *2T - Only Sub Dirs inside without Hidden one$ ~2T - All Present Users on system from "/etc/passwd" //第一次见到,很好用$ $2T - All Sys variables //写Shell脚本的时候很实用$ @2T - Entries from "/etc/hosts" //第一次见到$ =2T - Output like ls or dir //好像还不如 ls 快捷补充:Esc + T - 交换光标前面的两个单词
很多来自GNU 的 readline 库。另外一份总结也很好
记忆是所有技术人员的敌人。一次要把所有的都记住是不可能的。针对自己的使用习惯,对少数快捷键反复使用,短期内就会有效果。
你还知道那些好用的快捷键 ? 补充一下 ?
--EOF--
原谅我最近的更新频率吧。上回说的基本是 19 日上午的事情,再来说说下午的情况
吃过午饭,赶回人民大会堂。下午的技术演讲已经开始了。我参加的是操作系统的部分。进入会场,第一场章文嵩博士关于 LVS 的讲座已经接近尾声。我胡乱拍了几张照片后发现了阿北。到了提问时间,阿北问了一个关于 LVS 一般会遇到 IO 瓶颈还是 CPU 瓶颈(大意如此)。这个问题提问过后,有个自称是在电信做手机视频工作的朋友走过来和阿北聊了几句,我在旁边介绍说,这就是豆瓣的阿北啊,那个兄弟似乎没听说过,坐在阿北旁边的一个兄弟这时候也转过头来聊了几句,他是 51.com 的,我听说 51.com 买了几十台 EMC 的存储设备用来存储会员上传的视频,一问,这位仁兄很自豪的确认,没错,一天数据量就达到 1T 了。可惜互联网不是单靠数据量取胜,否则这位仁兄更该骄傲了。
第二场是雷鸣的《Linux平台下的高性能系统设计》,演讲内容和 Linux 其实关系不大,如果说成 "Web 高性能系统设计" 也很切题。一场讲座听下来,感觉雷鸣经验的确非常丰富。可能别人觉得挺空洞,不过他举的几个例子倒是对我挺有启发。
下一场则是关于 .net 的了,阿北说没意思,于是走到会议室外面聊天。博文视点的方舟还有 InfoQ 的泰稳也在外面,方舟对 Python 非常着迷,几乎是见人就推荐 Python 的好,刚好豆瓣堪称是国内最成功最大的 Python Web 应用...
最后我和阿北聊起了豆瓣,其实聊的内容有些类似于采访的形式了,基本上是我问,阿北在答。如果能把整个聊天的内容都记录下来,我相信肯定比那些外行的记者采访要精彩一些。豆瓣的经营理念可以说绝对是特立独行的,而且,不功利,从这一点上看,与国内所有的互联网公司经营理念都不同。开始和阿北接触,感觉他是个不善言谈的人,但是围绕豆瓣说开来后,简直是滔滔不绝,到了最后,我只得心里感叹我对豆瓣了解的还太少了。这次和阿北一起来的是 hongqn,他在豆瓣上的 Logo 很容易让人记住:带口罩的。
4 点多,各自准备回去休息一下。我在路边打车,足足等了有 30 分钟,晚上约阿北和 Hongqn 吃饭,结果...我又迟到了,在杭州两年多了,还不如刚来杭州的人熟悉地形呢,丢人。
吃过饭后,和他们两位一起去参加晚上在卡萨布兰卡酒吧的"大侠风尚"网络工程师沙龙,听信了一个出租车司机的话,"没多远", 沿着湖滨路走了整整半个小时,才算看到了湖边的酒吧招牌,我这个带路的,又丢人一次,我路过多少次,都没有注意到这里有个酒吧。
看到了 Rasmus Lerdorf 和 Jeremy Zawodny ,在里面悠闲的喝着啤酒。过了一会儿, Lerdorf 拿着个相机,这拍拍,那拍拍的,这个时候终于没人打扰他了。
其实工程师到酒吧,谈的也都是技术。几位平时就相互很了解的做 DBA 的朋友,见了面还是谈数据库 :) .这次总算见到了高春辉,上次在北京住的地方离他很近,不过时间不凑巧。其实我俩还算半个同乡,他是沈阳人,我是吉林的。老高给我免费培训了一下他的 ECSHOP,现在回想起来,我还是觉得这个产品很有市场,一定会被某个 C2C 大站点看上。
酒吧还看到了不少新老同事,好几位前同事辞职创业,在搞一个很有趣的项目,暂时替他们保密一下。本来和王皓说好这个礼拜天去上海看胡德夫的演唱会,又食言了,他至少给我推荐过二十场我感兴趣的演唱会,可是我...一场都没去过,尤其是上次 Roger Waters 的,我那个后悔啊,谁让我总加班呢??
Yupoo 也来了两位朋友,小橘子,还有他们的内容总监。小橘子送我一个 Yupoo 的 小纪念品,挺好玩的。对了,已经和他们约好,过一段时间参加他们举办的摄影活动去。
--EOF--
Oracle 10g R2 的 Data Pump 是一个好工具,弥补了传统 export/import 工具的很多不足。相关信息可以参考一下我以前对 Data Pump 的介绍。
最近在 Linux 平台上经常遇到 ORA-39095 错误。这个错误。这个错误号,文档的解释:
ORA-39095:Dump file space has been exhausted: Unable to allocate string bytes
Cause: The Export job ran out of dump file space before the job was completed.
Action: Reattach to the job and add additional dump files to the job restarting the job.
这个解释只针对一般情况。我遇到的这个案例,目录的空间还有很多,可是也一样报错了。而且,一般在第 100 个 导出文件出错(更正:%U参数是2位,定长的,最大99)。开始以为是 Bug,可是遍查 Metalink,发现和 ORA-39095 错误有关只有两条信息,和我遇到的情况不符。
偶然在阅读 Oracle Database Utilities 手册的时候,发现了这一段话:
Because each active worker process or I/O server process writes exclusively to one file at a time, an insufficient number of files can have adverse effects. Some of the worker processes will be idle while waiting for files, thereby degrading the overall performance of the job. More importantly, if any member of a cooperating group of parallel I/O server processes cannot obtain a file for output, then the export operation will be stopped with an ORA-39095 error. Both situations can be corrected by attaching to the job using the Data Pump Export utility, adding more files using the ADD_FILE command while in interactive mode, and in the case of a stopped job, restarting the job.
真是孤陋寡闻了,我的并行度用的是 4 ,减小这个并行度,该错误不再出现。
You can supply multiple file_name specifications as a comma-delimited list or in separate DUMPFILE parameter specifications. If no extension is given for the filename, then Export uses the default file extension of .dmp. The filenames can contain a substitution variable (%U), which implies that multiple files may be generated. The substitution variable is expanded in the resulting filenames into a 2-digit, fixed-width, incrementing integer starting at 01 and ending at 99. If a file specification contains two substitution variables, both are incremented at the same time. For example, exp%Uaa%U.dmp would resolve to exp01aa01.dmp, exp02aa02.dmp, and so forth.
--EOF--
文件完整性校验是安全审计必不可少的一个流程。在不同操作系统的数据库服务器上部署 Tripwire 这样的工具是个麻烦事情(前提是使用非商业软件)。在 Linux 服务器上,我以前测试过 integrit ,参见 integrit - Tripwire 的替代品 。如果操作系统是 AIX , 那么 Samhain 可以作为一个替代方案。
在 AIX 5.3 上编译安装后,提示信息值得看看:
samhain has been configured as follows:
System binaries: /usr/local/sbin
Configuration file: /etc/samhainrc
Manual pages: /usr/local/man
Data: /var/lib/samhain
PID file: /var/run/samhain.pid
Log file: /var/log/samhain_log
Base key: 812826721,276349012
You can use 'samhain-install.sh uninstall' for uninstalling
i.e. you might consider saving that script for future use
Use 'make install-boot' if you want samhain to start on system boot
make install-boot 可以作为启动 daemon 安装.
/etc/samhainrc 是配置文件,可以参考 Samhain 文档 进行配置。之后即可 运行 /usr/local/sbin/samhain -t init -p info 进行数据库初始化。-p 这个参数后面可以跟 warning, cri(critical) 等参数,打印不同级别的信息。Samhain 这个工具唯一让我感觉不好的地方就是文档说明比较晦涩。配置选项什么都还可以,命令行解释连个例子也不给,还需要摸索半天。
命令行说明: samhain -t check #检查数据库 samhain -t update #更新数据库 -p info 可以看到相关信息
注意配置 /etc/samhainrc 的时候,默认可能是设定了程序作为 Daemon 启动,最好修改一下,否则运行几次,后台一堆 samhain daemon 在跑。
初始化--> 更新 --> 检查--> 列出变更信息
这应该是类似工具的统一使用思路。只是实现细节上略有差异。
现在在这一堆类似的软件中,号称支持 AIX 的就有 Tripwire 开源版本、AIDE 等,但是安装编译几乎很难顺利的通过,网上也很少能够找到相关支持信息。对于这几个软件之间的差异,可以参考 Samhain 上的比较表格(注意有的信息可能比较旧了)
--EOF--
这几天一直忙着折腾系统,抽空安装了好几台大大小小的服务器上的 Oracle,简单说说在 AMD 64 机器(RHEL 4) 上部署 Oracle 的注意事项。
首先, Werner Puschitz 的 Oracle 安装指导肯定是要看看的,特别注意其中要求的安装包,glibc-devel 包 32 位与 64 位都是需要的。查询语句如下:
rpm --queryformat "%{NAME}-%{VERSION}.%{RELEASE} (%{ARCH})/n" -q make / binutils / gcc / cpp / glibc-devel / glibc-headers / glibc-kernheaders / compat-db / compat-gcc / compat-gcc-c++ / compat-libstdc++ / compat-libstdc++-devel / gnome-libs / openmotif21 / setarch
第二个必需要注意的地方是 gcc 工具的处理,与 32 位操作系统略有不同:
mv /usr/bin/gcc /usr/bin/gcc.orig
mv /usr/bin/g++ /usr/bin/g++.orig
ln -s /usr/bin/x86_64-redhat-linux-gcc32 /usr/bin/gcc
ln -s /usr/bin/x86_64-redhat-linux-g++32 /usr/bin/g++
$LD_ASSUME_KERNEL 环境变量要设定:
export LD_ASSUME_KERNEL = 2.4.19这个变量如果不设定的话,安装的画面会一直 Hang 在那里。
有的兼容软件可以在 Oracle Compatibility 项目主页上下载,compat-libcwait 与 compat-oracle 这 2 个包是必须的。
Oracle 的安装还是一如既往的麻烦,考虑到每台机器还要打 Patchset,然后是一堆过渡性补丁,绝对是体力活。
--EOF--
先前说过 GNU 核心工具,类比了鸠摩智掌握了小无相功,就可以把 72 绝技耍得有模有样。这里的问题是,72 绝技秘笈在哪里 ? 如何去学 72 绝技呢?
林林总总的 Unix-like 操作系统文档都是可以找到的,如果把这些文档都看一遍恐怕是个大工程。我这里的建议是寻找差异化,推荐一篇很好的参考文档: Unixguide,建议打印下来,留在案头参考。多看几遍,起码对于不同 Unix 之间的差异有个大致的了解。不过可能没有人要同时面对这么多的操作系统要去搞, 有的时候可能只是从 Linux 转向 AIX,或是 Solaris 向 Linux 之间的转换,那么可以看一些迁移文档,比如 Solaris to Linux Migration: A Guide for System Administrators,都是完全可以在网上获取的。掌握差异化往往是节省学习成本的好方法,当然也是蒙人的好办法。
掌握差异化的过程中,或许可以进行一定程度上的总结,向回看,这些差异化有很多是因为 SysV 与 BSD 风格的不同带来的,颇有些武侠小说中佛家与道家武功对比的味道。站在一个更高的角度,比如 Unix 历史图,则令人又另有一番感触。
武侠小说中往往追求正统, 速成的东西大多被归结为邪门武功一类的,学习恐怕也是这样,决不能因为知道"一二三”如何写的就联想到"万"该划一万笔,走捷径或许只能解决一时问题,回头基础的东西还是要学,比如操作系统原理的课程。
未完, 等有机会继续扯...这个【扯淡系列】
关于 Crontab ,维基百科上的词条 Crontab非常好。可惜这个地址在国内不用代理访问不到。
虽然关于 Crontab 的介绍到处都是,详细读了一遍这个词条,收获还是有的。Crontab 这个名字来自 "chronos",一个古希腊语, “时间”的意思.
常见陷阱
每个SA、DBA 或者是普通的 Unix 用户,在第一次使用 Crontab 的时候都会遇到问题. 运行 Crontab 的常见错误包括如下几种:1) 出于测试目的新创建了一条 Cron JOB, 时间间隔必须超过两分钟,否则 JOB 将调度不到。如果必须忽略这两分钟的载入配置时间差,可以通过重新启动 Cron Daemon 做到。
2) 从 Crontab 中启动 X Window 程序需要注意的事项:所以要么在程序前初始化 "DISPLAY=:0.0", 要么在应用程序后面追加参数 --display :0.0
3) 命令中的 % 必须做转义处理: /% .我个人的意见是不要在命令行里带这个参数,干脆写到脚本里,然后调度该脚本即可。
其实我倒是认为使用 Crontab 最常见的一个问题往往是因为环境变量不对。经常会看到论坛里有人问:为什么我的 Crontab 创建了不执行? 准备创建一条 Cron JOB 的时候,很多人都喜欢在命令行下运行一遍,因为这个时候环境变量是随着 Shell 自动带进来,在 Crontab 中则可能因为找不到正确的环境变量,JOB 就不能执行。这个小问题就像出天花,一次教训之后就都记得了。
必须使用的一则技巧
每条 JOB 执行完毕之后,系统会自动将输出发送邮件给当前系统用户。日积月累,非常的多,甚至会撑爆整个系统。所以每条 JOB 命令后面进行重定向处理是非常必要的: >/dev/null 2>&1 。前提是对 Job 中的命令需要正常输出已经作了一定的处理, 比如追加到某个特定日志文件。附: Crontab 的格式说明如下:
* 逗号(',') 指定列表值。如: "1,3,4,7,8"
* 中横线('-') 指定范围值 如 "1-6", 代表 "1,2,3,4,5,6"
* 星号 ('*') 代表所有可能的值
Linux(开源系统似乎都可以)下还有个 "/" 可以用. 在 Minute 字段上,*/15 表示每 15 分钟执行一次. 而这个特性在商业 Unix ,比如 AIX 上就没有.
# Use the hash sign to prefix a comment# +---------------- minute (0 - 59)# | +------------- hour (0 - 23)# | | +---------- day of month (1 - 31)# | | | +------- month (1 - 12)# | | | | +---- day of week (0 - 7) (Sunday=0 or 7)# | | | | |# * * * * * command to be executed
Matrix 似乎提前来到我们身边。从 06 年开始,陆续看到多次关于 Second Life(SL) 的报道。因为自己的笔记本跑不起来 SL 的客户端,所以一直没有能体会这个虚拟世界的魅力。今天花了一点时间,读了几篇相关的文档。
RealNetworks 前 CTO Philip Rosedale 通过 Linden 实验室创建了 Second Life,2002 年这个项目开始 Alpha 版测试,当时叫做 LindenWorld。
2007 年 2 月 24 日号称已经达到 400 万用户(用户在游戏中被称为 "Residents",居民)。 2001 年 2 月 1 日,并发用户达到 3 万。并发用户每月的增长是 20%。这个 20%现在看起来有些保守了,随着媒体的关注,增长的会有明显的变化。系统的设计目标是 10 万并发用户,系统的复杂度不小,但 Linden 实验室对SL 的可扩展能力信心满满。
目前在旧金山与达拉斯共有 2000 多台(现在恐怕3000也不止了吧) Intel/AMD 服务器来支撑整个虚拟世界(refer here)。64 位的 AMD 服务器居多。操作系统选用的 Debian Linux, 数据库是 MySQL。通过 Tim O'relly 的这篇 Web 2.0 and Databases Part 1: Second Life ,可以了解到一点关于 SL 数据库建设的信息。在 Second Life 中每个地理区域都是运行在服务器软件单一实例上的,叫做"模拟器"或者简称是 "sim",每个 Sim 负责 16 英亩的虚拟土地。当用户在相邻的 Sim 间移动,实际上是从一个处理器(或是服务器)移动到另一个。根据这篇访谈,用户当前所在 Sim 的信息,以及用户本身的账户信息是存储在一个中心数据库上的。
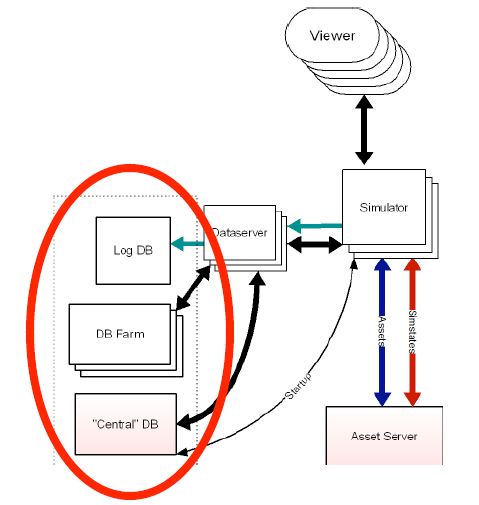
SL 的客户端软件的下载使用了 Amazon 的 S3 服务。
一点感想:MySQL 真是这波 Web 2.0 大潮中最大赢家之一啊
--EOF--
这段时间在邮件列表中讨论最多的一个话题就是 DST(Daylight Saving Time)。这个 DST 我们以前称之为"夏令时",不过英文的叫法似乎更直接(日光节省时、节能时),更能引起人们重视--节约能源。
啥是 DST?
美国加拿大实行 DST 的时间是 3 月的第二个星期天早晨两点开始到 11 月的第一个星期日的早晨两点。三月第二个个星期日早晨两点所有时钟向前回拨一个小时,到 11 月 DST 截止再拨回来。我查了一下,以前似乎不是强制的,这和现任总统小布什签署的 Energy Policy Act of 2005 法案 有关。而 2007 年是改方案实行的第一年。
很明显,对于计算机操作系统与数据库来说,这样折腾来折腾去的不可能靠人手工去调整时间,所以很多欧美软件产商纷纷推出软件补丁来解决这个问题。规模之大足以让人想起千年虫的事件。
DST 与 Oracle
Oracle 数据库的调整可以从 Oracle 站点上的这个指导开始: Oracle Database Daylight Saving Time Update Guide。因为需要打新的软件补丁,数据库必需要进行重新启动。所以很多在线应用必需要忍受这次调整带来的影响。DST 影响中国么?
我国因为取消了夏令时制度,这可能是因为能源问题虽然更加紧迫,但因为时间变来变去给人们带来的麻烦更多而取消的吧。具体的原因我不清楚,谁知道麻烦告诉我一下。如前所述,国内的 DST 问题实际上是不存在的。当然,如果你的服务器是放在美国或者加拿大,或者是面向这两个地区的用户,就需要评估一下影响了。关于夏令时
我国曾于1986年到1991年每年从四月的第二个星期天早上2点钟,到九月的第二个星期天早上2点钟,在这段时期内,全国都将时间拨快1小时,实行夏令时。从九月的第二个星期天早上2点钟起,又将拨快的时间重新拨回来,直到第二年四月的第二个星期天早上2点钟。Linux 怎么应对 DST?
Linux 厂商会有一个官方指导(比如 Redhat 的 DST 指导 )。如果是个人 PC,不妨参考这个:Switching your Linux systems to the new DST。
-EOF--
监控 Linux 服务器的时候,经常在 /var/log/messages 文件中看到类似如下的信息:
fooServer ntpd[7250]: can't open /etc/ntp/drift.TEMP: Permission denied
快速解决:
编辑 /etc/ntpd.conf 文件,找到这一行:
修改为:driftfile /etc/ntp/drift
更多信息参考 这里driftfile /var/lib/ntp/drift
这个问题最容易在 RHEL 服务器上遇到,碰上两次了,记录一下备忘。
--EOF--
Internet Archive(IA) 这个站点大家应该都不陌生。IA 旨在建立所有互联网站点的"档案库",如果说 Google 是互联网的数据库的话,那么 IA 就是互联网的数据仓库了,定期对每个 Web 页面保存快照,数据量之大可想而知。
先看看 IA 每天需要面对的处理能力:
存储超过 850 亿个 Web 页面;
每天大约 600 万次的下载;
Wayback Machine 收到大约 1000 万次点击,每秒钟要处理 100-200 个点击;
每天10万次左右通过 URL 查找;
每天 400 万次返回请求;
存储的内容包括本文、音频、视频...等各种 Web 可见的格式。
显然 IA 需要的是一种前所未有的存储解决解决方案--廉价、可靠、低功耗...总之用起来要省钱。IA 的志愿者不得不考虑自己动手建立符合他们需要的存储系统,这下子可不简单,2004 年,第一个 100GB 容量的近线存储投入使用 。IA 的志愿者之一 Saikley 干脆抽身而出成立了 Capricorn Technologies 公司,专为类似组织提供存储解决方案。前面提到的 100TB 容量的产品即为该公司 GB 系列的产品。现在 IA 已经采用 PS(PowerStore) 系列的 PetaBox,是量身定做的,装机容量 1.5T,目前容量已经超过 3PB(怕是远远超过 3PB 了)。PS 系列产品每节点原始容量可以达到 3T,使用日立 Deskstar 硬盘,仅仅占 1U 的机柜空间。IA 也在站点上介绍了定制的这台 PetaBox 的一些规格要求以及参数。

PetaBox 也是 Linux 在企业级应用取得成功的一个范例。
PetaBox 存储产品给存储界带来了不小的震撼。每 GB 的成本仅仅是 2 美元。这还是 2005 年的价格,现在应该更便宜了。搜索了一下,这家公司目前还没有进入中国。
PetaBox 系统通过一个集中式的 PXE 启动服务器运行在 Debian 或是 Fedora Linux ,通过 Nagios 进行整个环境的监控。 管理成本也并不高--每 PB 一个人。
--EOF--
"说出 10 个 Linux 基本命令?"
这是当年我在毕业求职的时候遇到的一个面试题。没有难度。如果说法换一下,"说出 10 个 GNU 核心命令",即使我能蒙出来 10 个,怕也会有错误。
GNU 核心工具(GNU Core Utilities)指的是 GNU 操作系统基本的文件、Shell、文本维护工具。
The GNU Core Utilities are the basic file, shell and text manipulation utilities of the GNU operating system. These are the core utilities which are expected to exist on every operating system.
GNU 核心工具 包括 fileutils、Shellutils、textutils 三个部分。其中 fileutils 只有 22 个命令,有三个命令我居然从来没有用到过,分别是 mkfifo(Creates FIFOs)、shred(Destroy data in files)、vdir(Long directory listing)。Shellutils 有 35 条命令,其中也有我从来没有注意过的命令,比如 pinky(Lightweight finger);textutils 工具中也有用的极少的工具,而且用的时候也往往有一些坏习惯,textutils 有 26 条命令,注意 VI/VIM 并不在其中。
初学 Unix/GNU Linux 的时候往往觉得老虎吃天,无从下口。这里有个小小的建议:从这个 GNU 核心工具开始,逐步掌握包含的三类几十条命令。对于类 Unix 操作系统你就可以拿出去蒙人了,呵呵,象 Unix 操作系统速成? 这有点像《天龙八部》中鸠摩智学会了小无相功,就能把少林 72 绝技耍的像模像样有些类似。当然,仅靠这一点还不足以行走江湖,有时间咱再继续说。
--EOF--
最近 IBM developerWorks 中国 刊载了一篇 《UNIX 高手的 10 个习惯》,尽管这个标题有点标题党的味道(英文名字不过是 UNIX tips: Learn 10 good UNIX usage habits),但是从内容上看还是一篇好文章。
先看看这10个好习惯都是什么:
- 在单个命令中创建目录树
- 更改路径;不要移动存档
- 将命令与控制操作符组合使用
- 谨慎引用变量
- 使用转义序列来管理较长的输入
- 在列表中对命令分组
- 在 find 之外使用 xargs
- 了解何时 grep 应该执行计数——何时应该绕过
- 匹配输出中的某些字段,而不只是对行进行匹配
- 停止对 cat 使用管道
如果换个角度,我们可以从中得到 10 个坏习惯。Unix 新手可能或多或少都会有这些毛病。就拿我自己来说,最后的三条的毛病现在就有。..grep 计数的话往往来个 |wc -l , 或者是 cat .. | grep 。这 10 条经验中,有些好习惯我倒是有的,比如第三条的"将命令与控制操作符组合使用", 如果有几十上百次手工编译 Linux Kernel 代码的话,对这一条肯定会潜移默化形成好习惯。
有这样一种说法"习惯是行为不断重复制造出来,并根据自然法则养成",习惯比较容易养成,可究竟是好习惯还是坏习惯,这是一个问题啊。
--EOF--
Oracle 10g 的 Data Pump 是个不错的新特性,因为新(其实 10g 也发布好几年了),所以也存在不少问题。
比如 EXPDP 的 EXCLUDE 参数,expdp help=y 输出的内容是这样说明的:
EXCLUDE Exclude specific object types, e.g. EXCLUDE=TABLE:EMP.
可是实际上用这样的格式却是不正确的,会得到一个错误提示信息:
ORA-39071: Value for EXCLUDE is badly formed.
正确的格式是啥? 如果第一次遇到或许还有些不知就里,莫明其妙。在 ITpub 上有个讨论,有朋友贴的文档给出了正确的语法:
EXCLUDE=TABLE:"IN ('TABLENAME1', 'TABLENAME2')"
对于 EXCLUDE/INCLUDE 参数还要注意的是二者不能共用。此外,Linux 和 Windows 下的命令行可能要对转义符号注意一点。
这个语法问题存在好久了,应该算是文档的 Bug ? Oracle 还没有进行修正。
EXPDP 我还遇到另外一个问题,生成的文件超过 99 个就会报错。有谁遇到过没?
--EOF--
BTW: 最近看到有朋友批评我写的东西没意思,其实首先要明确一点,我写的东西基本上是比较简单的所谓"技术", 另外我也不知道写什么有意思,众口难调,而且,写多了我也腻。
在 Red Hat Enterprise Linux Server 上安装 Oracle 的时候,如果误打误撞顺利的话可能一个错误都碰不到,如果不顺利可能每一步都有槛。以下是几个小建议,可能会让一些朋友少一点麻烦。
1. 安装 OS 时候请选择 "Install Default Software Servers"
很多朋友在安装操作系统的时候会选择 Custom 模式安装软件包, 这样看上去似乎会灵活一些,但是也带来潜在的极多麻烦。数据库软件依赖的包如果缺少的话,再次安装就麻烦了--软件之间的依赖性非常让人闹心的。RHEL 又没有对 YUM/ APT 等自动解决依赖性工具的正式支持。2. 参考 Oracle Validated Configuration
Oracle 这个服务很好。每个配置清单都是经厂商验证过可行的,参考性比较大。尤其是关于当前版本的临时 Patch 参考,更是必需要着重处理。3. OS 安装文件 .iso 在服务器上放置一份
对数据库来说,一般都是远程操作服务器,如果临时需要安装文件,总不能跑到机房再把光盘扔里面吧? 这时这个 iso image就有用场了。如果上面说的第一条是定制安装 OS 的话,那么几乎就会用到安装光盘. 很多人要找安装包就从网上 rpmfind.net 之类的地方随便找个 RPM 包安装,强烈反对这样做。另外:Werner Puschitz 的安装参考要超过 Oracle 的官方指导。必读。
几个小小建议,行家眼里不值一哂。
--EOF--
Oracle 这只大鲨鱼胃口越来越好了。LAMP (Linux, Apache, MySQL, PHP) 一直以来被视为一个非常完美的组合形式,现在 Oracle 或许有了想把 LAMP 中的 "M" 替换为 "O" -Oracle 的想法。LAOP, LAOP? 现在这还是我的猜测,起因是看到了这篇 Drupal + Oracle: Inside the OraDrup Project。
现在 OraDrup 项目还只是刚刚起步,Oracle XE 的确拉近了使用者与 Oracle 之间的距离,这个易于部署的版本一改 Oracle 过去"重"的形象,多少有点"轻量级"的意思,在中小应用上开始抢 MySQL 的地盘。LAOP 中的 O 有点牵强,却也是可以为之。
LAOP 中的 "P" (PHP)呢? Oracle 对 PHP 也是下了不少力气的。与 Zend 的倾力合作时间也不短了,Oracle 在 PHP 这一块的技术社区也逐渐做了起来。
至于 Linux 和 Apache ,对 Oracle 来说也是必争之地,苦心经营了多年。尤其是 Linux 服务器这一块,甚至不惜与多年的合作伙伴 Red Hat 交恶。
Oracle 会花多大力气来争夺这最关键的一环还真不好说,也或许只是一些 Oracle 技术爱好者的一厢情愿(或许更多是我的猜测:))。
再过一段时间没准 LAOP 这个缩写就流行起来喽,谁知道呢。
--EOF--
在 RHEL 4 上,默认 top 命令的显示有了一点小变化:如果是 SMP 机器 ,只显示 CPU 的概要信息。
其实很多用户还是喜欢看到 CPU 的细节数据的,要恢复旧的显示习惯,只需要输入数字 1 即可打开到 SMP 显示模式。输入大写的英文字母 I 则显示 Irix/Solaris 模式。
小技巧:在输入 1 后,再输入一个大写的 W 即可在当前用户默认路径下保存一个 .toprc 文件,下次启动 top 命令就不用费事了。
这个变化和 procps 版本有关,还不确定是否是因为 RHEL 的 Bug -- 虽然 RHEL 与 procps 相关的 Bug 挺多。
--EOF--
在 OTN 上下载文件,有的时候是比较烦人的事情。估计是出于负载均衡的原因,直接使用浏览器看到的地址还要经过几次 http 302 跳转才可以看到。而这个跳转是要带着 Session 走的,如果使用多线程下载工具就有可能到一个很小的错误页面文件。新版本的 FlashGet 就有这毛病。
如果准备安装的服务器在远程,参考这里的方法,用 Wget 直接下载其实也并不费事。
现通过浏览器获知该数据文件的 URL 地址。然后来个投石问路看看具体的跳转情况:
$ wget --limit-rate=150k /http://download.oracle.com/otn/linux/oracle10g/ /10201/10201_database_linux_x86_64.cpio.gz http://download.oracle.com/otn/linux/oracle10g/ /10201/10201_database_linux_x86_64.cpio.gz => `10201_database_linux_x86_64.cpio.gz'Resolving download.oracle.com... 213.35.100.1Connecting to download.oracle.com[213.35.100.1]:80... connected.
HTTP request sent, awaiting response... 302 Found
Location: http://download-
west.oracle.com/otn/linux/oracle10g/10201/ 10201_database_linux_x86_64.cpio.gz [following] http://download-west.oracle.com/otn/linux/oracle10g/10201/ 10201_database_linux_x86_64.cpio.gz
=> `10201_database_linux_x86_64.cpio.gz'Resolving download-west.oracle.com... 206.204.21.139Connecting to download-west.oracle.com[206.204.21.139]:80... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://profile.oracle.com/jsp/realms/otnLogin.jsp?
remoteIp=218.108.233.1&globalId=&redirectUrl=http%3a%2f%2fdownload-
west.oracle.com%3a80%2fotn%2flinux%2foracle10g%2f10201%
2f10201_database_linux_x86_64.cpio.gz [following]--16:11:01-- https://profile.oracle.com/jsp/realms/otnLogin.jsp? remoteIp=218.108.233.1&globalId=&redirectUrl=http%3a%2f%2fdownload-west.oracle.com%3a80%2fotn%2flinux%2foracle10g%2f10201%2f10201_database_linux_x86_64.cpio.gz => `otnLogin.jsp? /remoteIp=218.108.233.1&globalId=&redirectUrl=http:%2F%2Fdownload-
west.oracle.com:80%2Fotn%2Flinux%2Foracle10g%2F10201%
2F10201_database_linux_x86_64.cpio.gz'Resolving profile.oracle.com... 141.146.8.116Connecting to profile.oracle.com[141.146.8.116]:443... connected.
HTTP request sent, awaiting response... 200 OKLength: 4,106 [text/html]
输出实在是有点恶心,我在适当的地方做了换行处理。要在第二个 Location 处下手:
https://profile.oracle.com/jsp/realms/otnLogin.jsp?remoteIp=218.108.233.1&globalId=&redirectUrl=http%3a%2f%2fdownload-west.oracle.com%3a80%2fotn%2flinux%2foracle10g%2f10201%2f10201_database_linux_x86_64.cpio.gz
在这个地址后添加 &username=YOURPASSWORD&password=YOURPASSWORD&submit=Continue . YOURUSERNAME/YOURPASSWORD 是在 OTN 上的用户名与口令。然后提交如下的命令即可:
wget --limit-rate=128K --post-data="https://profile.oracle.com/jsp/realms/otnLogin.jsp? /remoteIp=218.108.233.1&globalId=&redirectUrl=http%3a%2f%2fdownload- /west.oracle.com%3a80%2fotn%2flinux%2foracle10g%2f10201% /2f10201_database_linux_x86_64.cpio.gz /&username=YOURUSERNAME&password=YOURPASSWORD&submit=Continue" /https://profile.oracle.com/jsp/reg/loginHandler.jsp
如果嫌输出麻烦,可以在最后 -o downloadOracle.log . 新开一个终端窗口 tail -f downloadOracle.log 就可以观察下载进度了。
要养成随时用 Unix 的习惯思考问题,还真是一个需要时间的事情 :)
--EOF--
手边有一份 2005 Winter TopTen Award Winners的报告,包含了一些关于世界上排名前几位的 VLDB 的信息。VLDB,超大数据库,其实叫做"狂大数据库"倒是也很贴切。
如果不区分操作系统环境,Yahoo! 力拔数据仓库一项的头筹,单个数据库数据大小接近 100T 。采用的是 Oracle 数据库,部署在 Unix 上, 存储是 EMC 的设备。这是 2005年的数据,雅虎现在每日接近 40 亿 PV,这个数据仓库现在应该远超 100T 了吧。 电信巨头 AT&T 的数据仓库屈居亚军。Amazon 的两个数据仓库也不小,数据量多达 24773 GB,是用 Oracle RAC 实现的,部署在 Linux 操作系统上。
OLTP Top 10
我比较关心 OLTP 数据库的情况。下面这个图表是包括所有操作系统环境的 OLTP 数据库情况。前 10 名中只有两个采用了集群,而且都是集中式集群(Centralized/Cluster)。其余8个席位都采用了 SMP 架构,而且大多是集中式(Centralized)。分布式超大 OLTP 的成功案例看来并不多(只有 1 例,另外有一例是Federated)。让 Fenng 稍微有些惊讶的是 SQL Server 占了三个席位,数据量最大接近 8T 。整个表看来,数据库类别、所用的软件平台还真的比较平均。并非我想象的完全是 DB2/Oracle+Unix 的格局。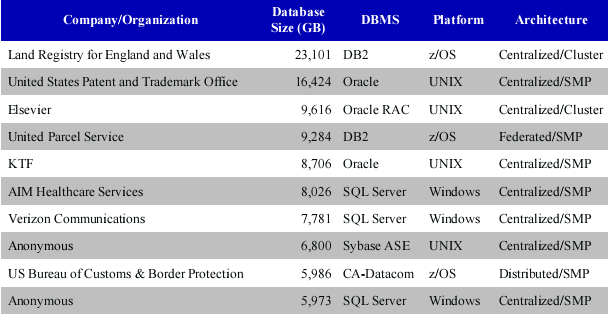
Unix 上 OLTP TOP 10
下表是使用 Unix 操作系统 OLTP TOP 10。好家伙,几乎清一色的 Oracle。DB2 不见踪影,只有 Sybase ASE 还算争气,占了一个席位。 9 个 Unix 平台上的 Oracle OLTP DB,只有两个使用了 RAC ,其他都是 Centralized/SMP。
到现在为止,都还没有看到互联网站点的身影。
(现在是广告时间)
如果你对海量数据有较强的分析处理能力,能够透过数据发现一些潜在的问题;
如果你有超强的逻辑推理能力,能够敏锐的寻找到支持你论据的特征值,还原案发现场;
如果你对 SEO 或者点击器有一定的了解,做过这方面的探索研究或者是实践;
如果你曾经是一名站长,厌倦了江湖争斗,希望成为网络秩序的捍卫者...
那么你就是我们最合适的人选,我们诚邀你加盟我们(雅虎中国)的竞价防作弊Team,还我们的客户一个明亮纯洁的广告投放空间。
如果你不具备以上的条件,只要你有一颗正直的心,同时有希望成长为一个经验丰富的网络安全卫士的决心和勇气。当你具备以下技能后,你仍然可以加入我们的队伍。
1. 1 年以上工作经验。
2. 半年以上 Linux 使用经验。
3. 开发语言:Perl/PHP/Shell,熟练掌握其中至少1种。
4. 了解 HTML/JavaCcript 网站制作技术,具有网站制作、开发经验。
5. 有过海量(百万以上)数据统计、分析经验更佳。
6. 有一定的沟通能力,具有协同工作经验。
来吧!惩恶扬善,维护世界和平的重任就落在你的肩上了!
此时此刻,非你莫属!
感兴趣的朋友给我发电子邮件吧: dbanotes@gmail.com
--EOF--
今天升级 foobar2000 的时候,忽然想起来一个问题:在今天还有人用超级解霸的么? (一个音频工具,一个视频工具,我也不知道怎么就联系上了)
曾几何时,超级解霸就是媒体播放工具的代名词,梁肇新也是那个年代的 IT 传奇英雄。从一些媒介上能看出来,这个大脑袋的梁肇新是一个 Windows 编程高手,也是一个非常偏执的人,不过对于技术趋势并没有很好的感觉。我还记得他曾经说过的 "Linux 是假技术"论,搜了一下,当初梁肇新是这样说的:
从一开始,我就认定,Linux 不会走得太远,我认为它注定只是一种炒作,一种'假技术'。一种技术要有前途,必须满足下面的三个要素:兼容性、开放性和标准性。Linux 的致命缺陷在兼容性上面。所以,我断定,Linux 不会有什么前途。
现在把这段话再拿出来看,几乎和笑话一样。"兼容性、开放性和标准性",超级解霸是符合的么? 相反,几乎没有什么高精尖技术而仅仅是封装开源产品的暴风影音等同类产品倒是占据了更多的市场。看一下国外,和超级解霸几乎一个模式的 DivX 折腾折腾还上了市。
尽管这个产品拥有"消除毛刺、断点续播、数字音频、P2P播放、数字影院等数十项专利技术",从用户的角度上看,我倒认为,超级解霸最大的一个缺点就是糟糕的界面--一种华丽的土气(如果是 foobar2000 这样的朴素反而是另外一回事)。多少个版本延续花里胡哨的土界面,这种设计理念倒有点和梁肇新的偏执脾气类似。
前一段时间有传言:超级解霸将可能被收购。尽管会有什么"进军网络媒体"之类的豪言壮语,但要想恢复往日的荣光几乎是不可能的了。被收购几乎意味着一种放弃,很难看到有哪一个曾经风光的通用软件被收购后重放光彩,还是提前纪念一下这个曾经的传奇软件吧。
--EOF--
(插播一则新闻:竞拍这本《Don’t Make Me Think》,我出价 RMB 85,留言的不算--不会有恶意竞拍的吧? 要 Ping 过去才可以,失败一次,再来)
Craigslist 绝对是互联网的一个传奇公司。根据以前的一则报道:
每月超过 1000 万人使用该站服务,月浏览量超过 30 亿次,(Craigslist每月新增的帖子近 10 亿条??)网站的网页数量在以每年近百倍的速度增长。Craigslist 至今却只有 18 名员工(现在可能会多一些了)。
Tim O'reilly 采访了 Craigslist 的 Eric Scheide ,于是通过这篇 Database War Stories #5: craigslist 我们能了解一下 Craigslist 的数据库架构以及数据量信息。
数据库软件使用 MySQL 。为充分发挥 MySQL 的能力,数据库都使用 64 位 Linux 服务器, 14 块 本地磁盘(72*14=1T ?), 16G 内存。
不同的服务使用不同方式的数据库集群。
论坛
1 主(master) 1 从(slave)。Slave 大多用于备份. myIsam 表. 索引达到 17G。最大的表接近 4200 万行。分类信息
1 主 12 从。 Slave 各有个的用途. 当前数据包括索引有 114 G , 最大表有 5600 万行(该表数据会定期归档)。 使用 myIsam。分类信息量有多大? "Craigslist每月新增的帖子近 10 亿条",这句话似乎似乎有些夸张,Eric Scheide 说昨日就超过 330000 条数据,如果这样估计的话,每个月的新帖子信息大约在 1 亿多一些。归档数据库
1 主 1 从. 放置所有超过 3 个月的帖子。与分类信息库结构相似但是更大, 数据有 238G, 最大表有 9600 万行。大量使用 Merge 表,便于管理。搜索数据库
4 个 集群用了 16 台服务器。活动的帖子根据 地区/种类划分,并使用 myIsam 全文索引,每个只包含一个子集数据。该索引方案目前还能撑住,未来几年恐怕就不成了。Authdb
1 主 1 从,很小。目前 Craigslist 在 Alexa 上的排名是 30,上面的数据只是反映采访当时(April 28, 2006)的情况,毕竟,Craigslist 数据量还在每年 200% 的速度增长。
Craigslist 采用的数据解决方案从软硬件上来看还是低成本的。优秀的 MySQL 数据库管理员对于 Web 2.0 项目是一个关键因素。
--EOF--
作为电子商务领头羊的 eBay 公司,数据量究竟有多大? 很多朋友可能都会对这个很感兴趣。在这一篇
Web 2.0: How High-Volume eBay Manages Its Storage(从+1 GB/1 min得到的线索) 报道中,eBay 的存储主管 Paul Strong 对数据量做了一些介绍,管中窥豹,这些数据也给我们一个参考。
站点处理能力
- 平均每天的 PV 超过 10 亿 ;
- 每秒钟交易大约 1700 美元的商品 ;
- 每分钟卖出一辆车A ;
- 每秒钟卖出一件汽车饰品或者配件 ;
- 每两分钟卖出一件钻石首饰 ;
- 6 亿商品,2 亿多注册用户; 超过 130 万人把在 eBay 上做生意看作是生活的一部分。
在这样高的压力下,可靠性达到了 99.94%,也就是说每年 5 个小时多一点的服务不可用。从业界消息来看,核心业务的可用性要比这个高。
数据存储工程组控制着 eBay 的 2PB (1Petabyte=1000Terabytes) 可用空间。这是一个什么概念,对比一下 Google 的存储就知道了。每周就要分配 10T 数据出去,稍微算一下,一分钟大约使用 1G 的数据空间。
计算能力
eBay 使用一套传统的网格计算系统。该系统的一些特征数据:- 170 台 Win2000/Win2003 服务器;
- 170 台 Linux (RHES3) 服务器;
- 三个 Solaris 服务器: 为 QA 构建与部署 eBay.com; 编译优化 Java / C++ 以及其他 Web 元素 ;
- Build 整个站点的时间:过去是 10 个小时,现在是 30 分钟;
- 在过去的2年半, 有 200 万次 Build,很可怕的数字。
存储硬件
每个供货商都必须通过严格的测试才有被选中的可能,这些厂家或产品如下:- 交换机: Brocade
- 网管软件:IBM Tivoli
- NAS: Netapp (占总数据量的 5%,2P*0.05, 大约 100 T)
- 阵列存储:HDS (95%,这一份投资可不小,HDS 不便宜, EMC 在 eBay 是出局者) 负载均衡与 Failover: Resonate ;
搜索功能: Thunderstone indexing system ;
数据库软件:Oracle 。大多数 DB 都有 4 份拷贝。数据库使用的服务器 Sun E10000。另外据我所知, eBay 购买了 Quest SharePlex 全球 Licence 用于数据复制.
非常有意思,根据eWeek 的该篇文档,昨天还有上面这段划掉的内容,今天上去发现已经修改了:
架构
- 高分布式
- 拍卖站点是基于 Java 的,搜索的架构是用 C++ 写的
- 数百名工程师进行开发,所有的工作都在同样的代码环境下进行
可能是被采访者看到 eWeek 这篇报道,联系了采访者进行了更正。我还有点奇怪原来"两层"架构的说法。
其他信息
- 集中化存储应用程序日志;
- 全局计费:实时的与第三方应用集成(就是eBay 自己的 PayPal 吧?)
- 业务事件流:使用统一的高效可靠消息队列. 并且使用 Cookie-cutter 模式用于优化用户体验(这似乎是大型电子商务站点普遍使用的用于提高用户体验的手法)。
后记
零散作了一点流水帐。作为一个 DBA, 或许有一天也有机会面对这样的数据量。到那一天,再回头看这一篇电子垃圾。更新:更详细信息请参考:Web 2.0: How High-Volume eBay Manages Its Storage。可能处于 Cache 的问题,好几个人看到的原文内容有差异
--EOF--
应用服务器
应用服务器有哪些特点呢?
- 使用单一的两层架构(这一点有点疑问,看来是自己写的应用服务器)
- 330 万行的 C++ ISAPI DLL (二进制文件有 150M)
- 数百名工程师进行开发
- 每个类的方法已经接近编译器的限制

Larry Ellison 在 Oracle Open World 大会上宣布提供企业级别的 Linux 支持服务,"Unbreakable Linux" ,在 Oracle 公司公布的新闻稿上这么写着:
Oracle starts with Red Hat Linux, removes Red Hat trademarks, and then adds Linux bug fixes.Currently, Red Hat only provides bug fixes for the latest version of its software. This often requires customers to upgrade to a new version of Linux software to get a bug fixed. Oracle's new Unbreakable Linux program will provide bug fixes to future, current, and back releases of Linux. In other words, Oracle will provide the same level of enterprise support for Linux as is available for other operating systems.
也就是说,Oracle 在 Red Hat 的 RHN 之外提供一个同样性质的服务,价格更低($99 per system per year)。红帽子公司会怎么想? 这不摆明了坑人么... 自从 Red Hat 收购 Jboss 之后, Oracle 对红帽子的觊觎之心路人皆知。Oracle 的这个计划 FUD 的意味很浓,似乎就是要给红帽子公司压力,打击客户对 Red Hat 的信心,进而找机会收购它。
另外,Oracle "Unbreakable Linux" 的迁移战略也将展开,据说要协助客户从 "AIX、Solaris、HP/UX、Windows、遗留主机 或者 TRU64" 迁移到 Linux 上来,这是一个非常得罪人的活,不知道 Oracle 的目的何在。颇有讽刺意味的是,HP、IBM 居然加入了这个项目。
我个人的看法:
1) 这件事情对开源软件业界没什么积极的影响;
2) Oracle 提供的这个服务质量好不到什么地方去, 看看他们数据库服务器的一堆一堆的 Patch 就知道了;
3) Oracle 可能不会对 Novell 的 SuSE 下手了
题外话,我觉得 Oracle 在进行连番收购之后,居然财务报表仍然那么好看,似乎耐人寻味。
--EOF--
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow

新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片: ![]()
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block var foo = 'bar'; 生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t   . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram functionality to mermaid
section 现有任务
已完成 :done, des1, 2014-01-06,2014-01-08
进行中 :active, des2, 2014-01-09, 3d
计划一 : des3, after des2, 5d
计划二 : des4, after des3, 5d
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件或者.html文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









