






介绍
Kubernetes Service 用于流量的负载均衡和反向代理,其通过 kube-proxy 组件实现。从服务的角度来看,kube-controller-manager 实现了服务注册,kube-proxy 实现了 kubernetes 集群内服务的负载均衡。
示意图如下:
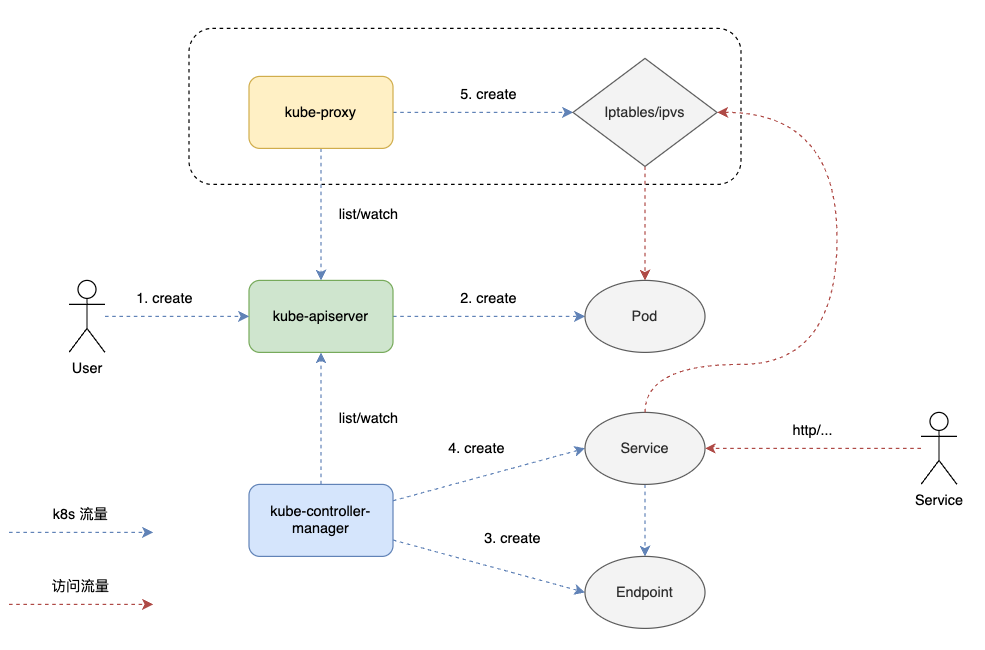
kube-proxy 通过三种模式 userspace,iptables 和 IPVS 实现 Service 流量的负载均衡。userspace 不太常用,kube-proxy 自 v1.8 开始支持 IPVS,v1.11 GA。
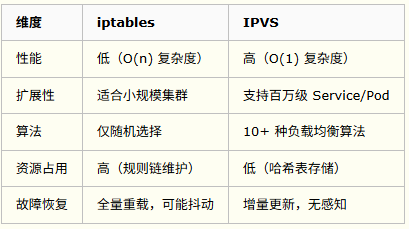
iptables 和 IPVS 都是基于内核的 Netfilter 实现。iptables 基于 iptables 表匹配规则,复杂度为 O(n),IPVS 基于哈希表实现规则匹配,复杂度为 O(1)。详细对比如下:
性能对比测试:
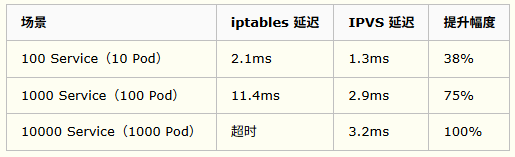
数据来源:Kubernetes 社区性能测试
多维度对比:
iptabls
iptables 介绍学习可参考 iptables,非常好的 iptables 学习资料,强烈推荐。
iptables 重点在五链五表,其示意图如下:
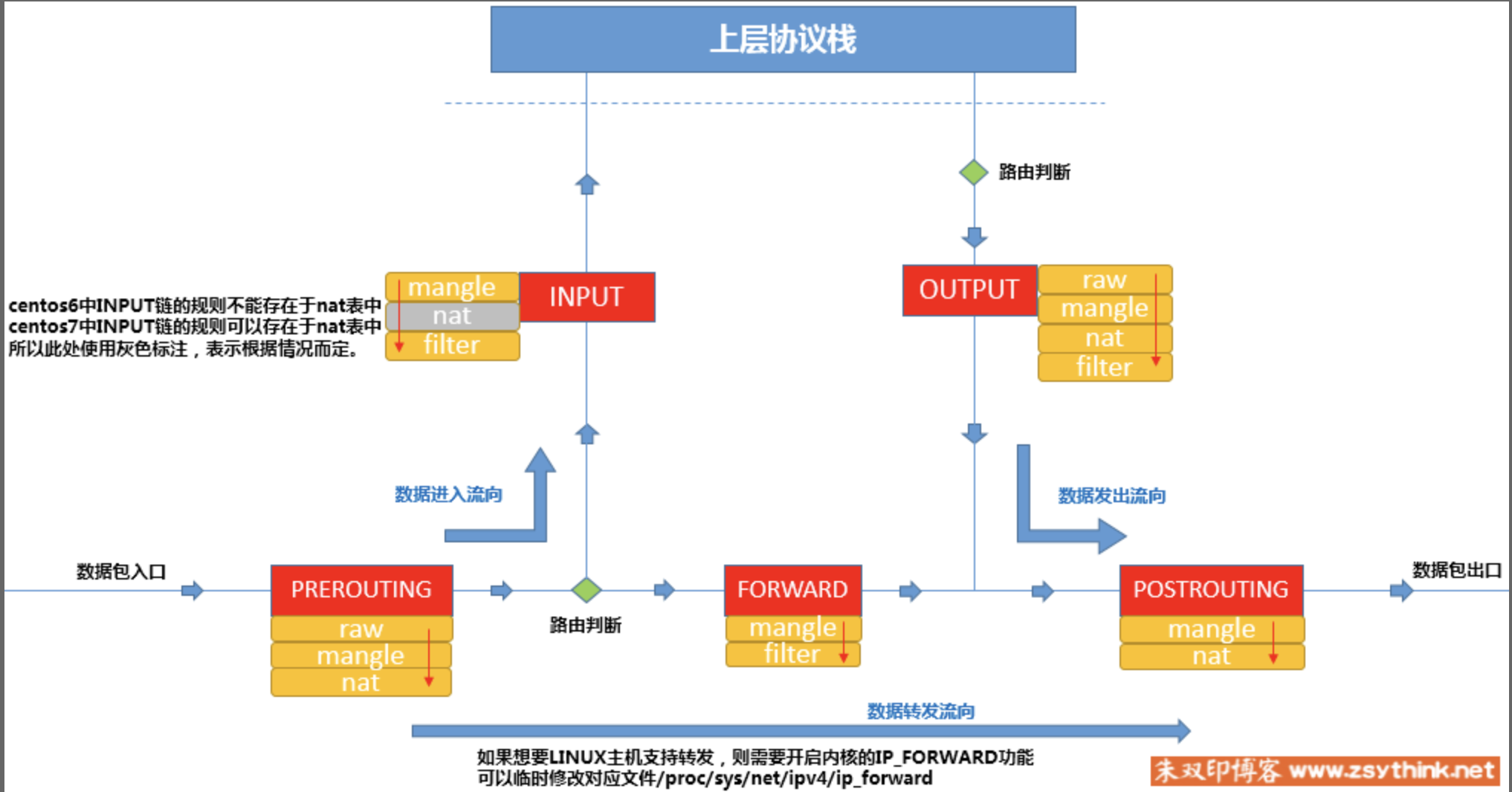
kube-proxy 通过在 INPUT,FORWARD,POST_ROUTING 链上添加钩子规则实现 Service 的负载均衡和反向代理。示意图如下:
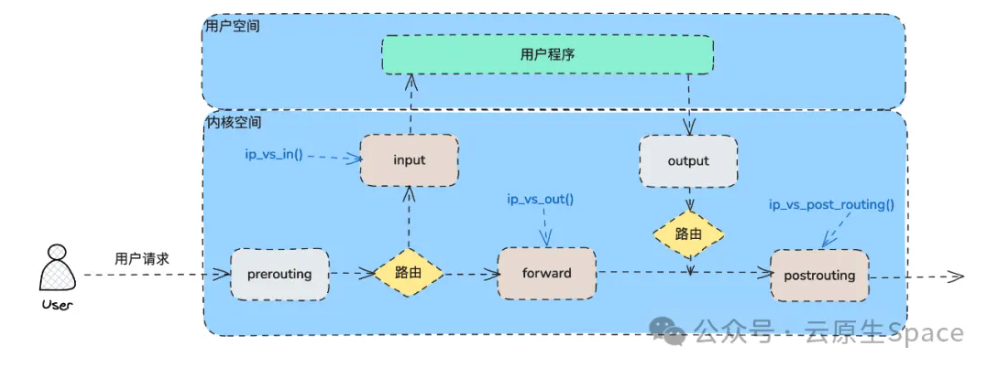
图片来源于 公众号:云原生 Space
ipvs
IPVS 提供 DNAT 和负载均衡,需要和 iptables 配合使用才能实现 Service 的流量转发。
结合 ClusterIP 看 kube-proxy ipvs 是如何实现流量负载均衡的。
Service ClusterIP
Kubernetes Service:
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.233.0.1 <none> 443/TCP 385dipvsadm 查看 svc 的负载均衡信息:
# ipvsadm -l -n | grep 10.233.0.1:443 -A 3
TCP 10.233.0.1:443 rr
-> 10.251.xxx.30:6443 Masq 1 18 2
-> 10.251.xxx.31:6443 Masq 1 25 0
-> 10.251.xxx.32:6443 Masq 1 13 1输出部分元素解释:
-
rr: 表示负载均衡策略,默认是 rr。
-
Masq:负载均衡模式,Masq 指的是 NAT 模式。IPVS 支持 Direct Routing,Tunneling 模式,这两种都不支持端口映射,IPVS 使用的是 Masq 模式。
IPVS 提供如下负载均衡策略:
rr:轮询调度
lc:最小连接数
dh:目标哈希
sh:源哈希
sed:最短期望延迟
nq: 不排队调度
只有负载均衡信息并不能使集群内访问 ClusterIP 的流量转发到后端服务。流量首先需要经过内核,由内核根据 iptables 策略决定丢弃/接受还是转发包。要接收访问 ClusterIP 的流量就需要在 iptables 的 PREROUTING 表中配置接受策略。并且需要创一个 dummy 接口,添加 ClusterIP 从而骗过内核,接收集群内发往 ClusterIP 的数据包。
kube-proxy 会创建 kube-ipvs0 的 dummy 接口,如下:
kube-ipvs0: flags=130<BROADCAST,NOARP> mtu 1500
inet 10.233.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever这里也从侧面印证了为什么是集群内访问,这是 dummy 接口,集群外不通
查看 iptables 策略看内核是如何接收访问 ClusterIP 的数据包的:
# iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
// 流量首先经过 PREROUTING 链的 nat 表,匹配 KUBE-SERVICES 规则
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
Chain KUBE-SERVICES (2 references)
target prot opt source destination
// KUBE-LOAD-BALANCER:匹配访问 LoadBalancer 的流量,和 ClusterIP 没有关系
KUBE-LOAD-BALANCER all -- anywhere anywhere /* Kubernetes service lb portal */ match-set KUBE-LOAD-BALANCER dst,dst
// 集群内源 ip 不是 10.222.0.0/18 网段的流量将进入 KUBE-MARK-MASQ 规则
// 这里匹配是发往 ClusterIP 的流量,10.222.0.0/18 网段是 kubernetes 分给 pod 的 ip,这条策略的意思是匹配集群内非 pod 访问 ClusterIP 的流量
KUBE-MARK-MASQ all -- !10.222.0.0/18 anywhere /* Kubernetes service cluster ip + port for masquerade purpose */ match-set KUBE-CLUSTER-IP dst,dst
// KUBE-NODE-PORT:匹配访问 NodePort 的流量,和 ClusterIP 没有关系
KUBE-NODE-PORT all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
ACCEPT all -- anywhere anywhere match-set KUBE-CLUSTER-IP dst,dst
ACCEPT all -- anywhere anywhere match-set KUBE-LOAD-BALANCER dst,dst这里的逻辑很重要,为了理解清晰,有必要进一步介绍下 KUBE-MARK-MASQ 这条规则:
KUBE-MARK-MASQ all -- !10.222.0.0/18 anywhere /* Kubernetes service cluster ip + port for masquerade purpose */ match-set KUBE-CLUSTER-IP dst,dst这条规则包括两个点:
1、match-set KUBE-CLUSTER-IP dst,dst 使用 iptables 的 ipset 模块匹配访问 ClusterIP 的流量。ipset 创建了一个包括 ip 信息等的集合 KUBE-CLUSTER-IP(实际是哈希表,查找复杂度为 O(1)):
# ipset list KUBE-CLUSTER-IP | grep 10.233.0.1,tcp:443
10.233.0.1,tcp:4432、匹配到访问 ClusterIP 的流量后进入 KUBE-MARK-MASQ 规则:
Chain KUBE-MARK-MASQ (4 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK or 0x4000KUBE-MARK-MASQ 规则将数据包打上 MARK:0x4000 标签。
这里留个问题,为什么需要打上
MARK:0x4000标签?
接着打上 MARK 标签的数据包被接收,进入 ipvs 负载均衡到相应的后端服务。
转发到哪里?
kubernetes 集群中每个节点都会起 kube-proxy 配置 iptables/ipvs 规则,并且这些规则是一致的。不同于传统负载均衡,kubernetes 集群内的负载均衡是分布式的。由 kube-proxy 保持信息一致。
集群内节点访问本节点的后端服务可以通过流量被接收后通过 ipvs 做 DNAT 直接转发到 pod 服务,没有问题。
那么,集群内节点访问 ClusterIP 转发到其它节点的 pod 该怎么做的呢?这涉及到跨节点通信,就需要 CNI 的帮忙了。示意图如下:
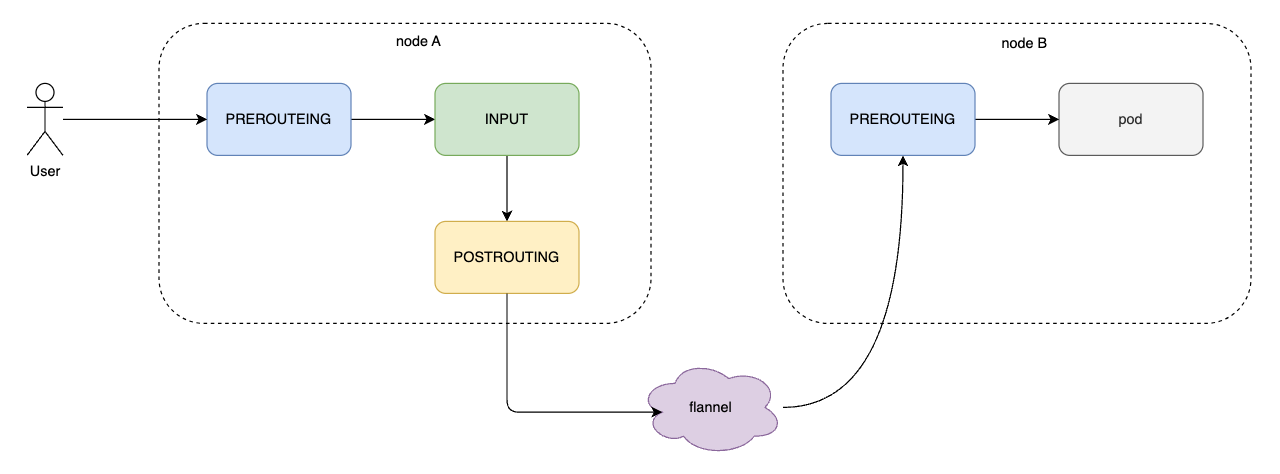
数据怎么回去?
前面提到通过 DNAT 数据包会转发到后端服务。后端服务的数据包又该怎么回去呢?
后端数据包经过 OUTPUT 链到 POSTROUTING 链,在 POSTROUTING 链做 SNAT 转发数据包到访问节点。
流程如下:
// 从集群内发出的数据包先走 OUTPUT
// OUTPUT 链接收数据包,继续进入 POSTROUTING 链
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
DOCKER all -- anywhere !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
// POSTROUTING 实现出去流量的转发
// 流量将进入 KUBE-POSTROUTING 链
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
KUBE-POSTROUTING all -- anywhere anywhere /* kubernetes postrouting rules */
Chain KUBE-POSTROUTING (1 references)
target prot opt source destination
MASQUERADE all -- anywhere anywhere /* Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose */ match-set KUBE-LOOP-BACK dst,dst,src
RETURN all -- anywhere anywhere mark match ! 0x4000/0x4000
MARK all -- anywhere anywhere MARK xor 0x4000
MASQUERADE all -- anywhere anywhere /* kubernetes service traffic requiring SNAT */ random-fullyKUBE-POSTROUTING 的规则非常重要,值得拆开好好讲。
规则1: MASQUERADE
MASQUERADE all -- anywhere anywhere /* Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose */ match-set KUBE-LOOP-BACK dst,dst,src
这条规则是给 pod 访问自己用的,如果 pod 要访问自己,那就别匹配其它规则了,直接将流量转给自己。这称为发卡弯(hairping)模式。
这也是为什么这条规则在 KUBE-POSTROUTING 链最前面的原因。
继续往下看,我们的任务是探索后端服务的数据包又该怎么回去的。
规则2: RETURN
RETURN all -- anywhere anywhere mark match ! 0x4000/0x4000
啊哈,还记得我们前面留的问题为什么要打 MARK:0x4000 标签吗?
答案就在这条规则,如果包不带 MARK:0x4000 则退出 KUBE-POSTROUTING,意味着只有带 MARK:0x4000 标签的数据包才会做 SNAT。MARK:0X4000 实际是用来区分是否做 NAT 的标签。
我们的数据包是带 MARK:0X4000 标签的,继续往下走。
规则3: MARK
MARK all -- anywhere anywhere MARK xor 0x4000
MARK xor 0x4000 清除数据包的 MARK:0X4000 标签。
规则4: MASQUERADE
MASQUERADE all -- anywhere anywhere /* kubernetes service traffic requiring SNAT */ random-fully
终于到 SNAT 规则了,对数据包做 SNAT,将请求转发回去。
小结
本文主要通过 kubernetes service 的 ClusterIP 示例介绍了 iptables 结合 ipvs 是如何管理集群内流量的。关于 NodePort,Ingress,LoadBalancer 并未在文中的讨论范围之内。后续看是否需要继续介绍其它 service 类型。
文章转载自:hxia043
原文链接:kubernetes service 原理精讲 - hxia043 - 博客园
体验地址:JNPF快速开发平台

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









