







项目中有一个步骤:数据移植。数据移植要迁移很多的表,迁移完之后我们要看一下我们迁移的表的记录数对不对。假如说有一百多张表,不可能每次都一张表一张表的去查询然后记录,这时候就得有一个脚本可以自动执行。我在数据可视化工具上怎么试都不行,同时执行一百多个查询语句,数据可视化工具上会产生一百多个窗口,没有什么用。
最后是在sqlplus中实现的可批量查询的脚本(用项目数据库的sqlplus来执行下面的命令),虽然格式不怎么好看,不管是调整select语句的格式,还是执行后对结果文件做修改,但最重要的是已经实现批量执行。
基本格式
sqlplus -s $SQL_PWD <<end_of
spool 1.txt
select语句1
select语句2
spool off
end_ofsqlplus -s $SQL_PWD <<end_of
spool 1.txt
select count(*)||'t_pub_hlp' as res from t_pub_hlp;
select count(*)||'t_pub_msg' as res from t_pub_msg;
select 'T_ACM_ACBL : '||count(*) from T_ACM_ACBL;
spool off
end_of结果

这是最简单的spool命令,记得spool只能在sqlplus中使用。同时如果想要进一步学习spool,让它按你的想法去输出数据,可以看下我之前看过的关于spool的文章
http://blog.csdn.net/wise_man/article/details/5292656
===============
把下面的语句放到test.sql里面,然后执行start test.sql或者 @test.sql 可以得到仅有数据的记录文件
set echo off;
set feedback off;
set trimspool off;
set heading off;
set pagesize 0;
set term off;
set timing off;
set termout off;
set verify off;
spool 2.txt;
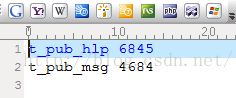
select 't_pub_hlp '||count(*) as res from t_pub_hlp;
select 't_pub_msg '||count(*) as res from t_pub_msg;
spool off















 2040
2040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









