









向表中装载数据(Load)
语法:
load data [local] inpath 'XXXX' [overwrite] into table tb_name [partition (partcol1=val1,…)];
(1) load data:表示加载数据
(2)local :表示从本地加载数据到hive表(复制到hdfs);否则从HDFS加载数据到Hive表(移动文件到表目录)
(3)inpath:表示加载数据的路径
(4)overwriter:表示覆盖表中已有的数据,否则表示追加
(5)into table : 表示加载数据到哪张表
(6)tb_name: 目标表名
(7)partition : 表示上传到指定分区
实例操作:
创建一张表:create table student3(id string,name string) row format delimited fields terminated by '\t' stored as textfile;

本地准备一个文档:

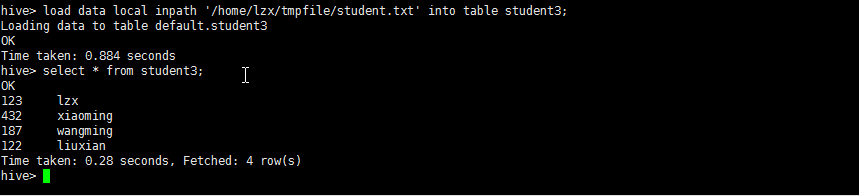
加载本地数据到Hive中:load data local inpath '/home/lzx/tmpfile/student.txt' into table student3;
查询student3:

上传一个新的文件到HDFS:
root@master:/home/lzx/tmpfile# vim student.txt
root@master:/home/lzx/tmpfile# hadoop fs -put student.txt /^C
root@master:/home/lzx/tmpfile# hadoop fs -mkdir -p /tmpfile/lzx
root@master:/home/lzx/tmpfile# hadoop fs -put student.txt /tmpfile/lzx
root@master:/home/lzx/tmpfile# hadoop fs -lsr /tmpfile/lzx
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 1 root supergroup 59 2019-08-21 15:45 /tmpfile/lzx/student.txt
root@master:/home/lzx/tmpfile#
加载新数据到表student3并覆盖旧数据:load data inpath '/tmpfile/lzx/student.txt' overwrite into table student3;
查询结果:

通过插入语句向表中插入数据(Insert)
创建一个分区表:create table student5(id string,name string) partitioned by (month string) row format delimited fields terminated by '\t' stored as textfile;

插入数据:insert into table student5 partition(month='201908') values('1','wangli');

根据单表查询结果插入数据:insert into table student5 partition(month='201909') select id,name from student5 where month = '201908';

可以看到已经插入到分区201909了。insert 有两种模式,一种insert into(追加) 一种insert overwriter(覆盖)。
执行两次insert into 执行一次insert overwrite 结果为:

多插入模式(根据多张表查询结果):from student5 insert into table student5 partition(month='201910') select id,name where month ='201908' or month='201909';
如果是同一张表 可以把表提出来 from tb_name放在最前面。即使用一张表的数据插入到其他不同的表,如果不是同一张表,则需要各自单独写插入sql,写多个insert语句。

也可以插入多张表或者多个分区:from student5 insert into student5 partition(month='201911') select id,name where month='201908' insert into student5 partition(month='201912') select id,name where month='201911';

查看一下分区,
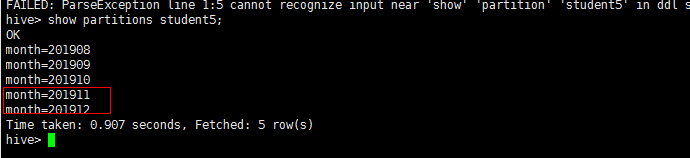
显示已经创建好了分区,数据也是有的。
查询语句中创建表并加载数据(As Select)
根据查询结果创建表:create table if not exists student6 as select id,name from student5 where month='201908';

like 是复制表结构创建表,不复制数据
创建表时通过Location指定加载数据路径
创建表指定hdfs存储位置:create table if not exists student8(id string,name string) row format delimited fields terminated by '\t' stored as textfile location '/user/hive/warehouse/student8';
上传文本:dfs -put /home/lzx/tmpfile/student.txt /user/hive/warehouse/student8;


Import数据到指定Hive表中
数据导入:import table student9 from '/user/hive/warehouse/export_student';
注意这种方式,必须先导出表,并且表结构要一样。

实际上就是文件的复制。














 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









