






问题:
/*
*Copyright(c) 2016,烟台大学计算机学院
*All rights reserved。
*文件名称:123.cpp
*作者:王靖淇
*完成日期:2016年9月7号
*版本号:V1.0.1
*
*问题描述: 排序是计算机科学中的一个基本问题,产生了很多种适合不同情况下适用的算法,也一直作为算法研究的热点。
本项目提供两种排序算法,复杂度为O(n 2)的选择排序selectsort,和复杂度为O(nlogn)的快速排序quicksort,
在main函数中加入了对运行时间的统计。
输入描述:近10万条大数据文件
输出描述:运行时间
*/
算法1代码:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#define MAXNUM 100000
void selectsort(int a[], int n)
{
int i, j, k, tmp;
for(i = 0; i < n-1; i++)
{
k = i;
for(j = i+1; j < n; j++)
{
if(a[j] < a[k])
k = j;
}
if(k != j)
{
tmp = a[i];
a[i] = a[k];
a[k] = tmp;
}
}
}
int main()
{
int x[MAXNUM];
int n = 0;
double t1,t2;
FILE *fp;
fp = fopen("numbers.txt", "r");
while(fscanf(fp, "%d", &x[n])!=EOF)
n++;
printf("数据量:%d, 开始排序....", n);
t1=time(0);
selectsort(x, n);
t2=time(0);
printf("用时 %d 秒!", (int)(t2-t1));
fclose(fp);
return 0;
}
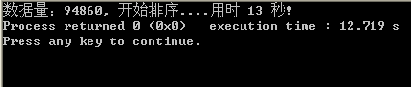
运行结果:
算法2代码:
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#define MAXNUM 100000
void quicksort(int data[],int first,int last)
{
int i, j, t, base;
if (first>last)
return;
base=data[first];
i=first;
j=last;
while(i!=j)
{
while(data[j]>=base && i<j)
j--;
while(data[i]<=base && i<j)
i++;
if(i<j)
{
t=data[i];
data[i]=data[j];
data[j]=t;
}
}
data[first]=data[i];
data[i]=base;
quicksort(data,first,i-1);
quicksort(data,i+1,last);
}
int main()
{
int x[MAXNUM];
int n = 0;
double t1,t2;
FILE *fp;
fp = fopen("numbers.txt", "r");
while(fscanf(fp, "%d", &x[n])!=EOF)
n++;
printf("数据量:%d, 开始排序....", n);
t1=time(0);
quicksort(x, 0, n-1);
t2=time(0);
printf("用时 %d 秒!", (int)(t2-t1));
fclose(fp);
return 0;
} 运行结果:
差异比较:
第一个程序的复杂度是n的平方,第二个程序的复杂度时nlogn,当n趋向于正无穷时,n方的值大于nlogn的值,因此第一个程序的复杂度更高;
通过比较运行结果,发现第一个运行时间为13秒,而第二个几乎为0,证明一般情况下,复杂度越高的程序运行时间越长。
知识点总结:
通过这个程序,我们加深了对于程序时间复杂度的理解,通过两个不同复杂度对比,更加直观的感受复杂度对运行时间的影响。
学习心得:
1.复杂度对运行时间的影响较大,需要在编程时考虑效率问题。
2.当我们试图得到两个量之间关系的时候,可以通过设计不同的实验方法来进行比较,从而更加直观深入的理解它们的意义。















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









