







1、概述
上一篇文章,我们对zookeeper中的数据组织结构、Leader选举原理进行了讲述(http://blog.csdn.net/yinwenjie/article/details/47613309)。这篇文章我们紧接上文讲解zookeeper中的事件机制。并通过示例代码告诉读者怎么使用zookeeper中的事件通知器:watcher。
2、zookeeper中的监听机制
按照上文中的讲解,我们知道zookeeper主要是为了统一分布式系统中各个节点的工作状态,在资源冲突的情况下协调提供节点资源抢占,提供给每个节点了解整个集群所处状态的途径。这一切的实现都依赖于zookeeper中的事件监听和通知机制
2.1、zookeeper中的事件和状态
事件和状态构成了zookeeper客户端连接描述的两个维度。注意,网上很多帖子都是在介绍zookeeper客户端连接的事件,但是忽略了zookeeper客户端状态的变化也是要进行监听和通知的。这里我们通过下面的两个表详细介绍zookeeper中的事件和状态(zookeeper API中被定义为@Deprecated的事件和状态就不介绍了):
- zookeeper客户端与zookeeper server连接的状态
| 连接状态 | 状态含义 |
|---|---|
| KeeperState.Expired | 客户端和服务器在ticktime的时间周期内,是要发送心跳通知的。这是租约协议的一个实现。客户端发送request,告诉服务器其上一个租约时间,服务器收到这个请求后,告诉客户端其下一个租约时间是哪个时间点。当客户端时间戳达到最后一个租约时间,而没有收到服务器发来的任何新租约时间,即认为自己下线(此后客户端会废弃这次连接,并试图重新建立连接)。这个过期状态就是Expired状态 |
| KeeperState.Disconnected | 就像上面那个状态所述,当客户端断开一个连接(可能是租约期满,也可能是客户端主动断开)这是客户端和服务器的连接就是Disconnected状态 |
| KeeperState.SyncConnected | 一旦客户端和服务器的某一个节点建立连接(注意,虽然集群有多个节点,但是客户端一次连接到一个节点就行了),并完成一次version、zxid的同步,这时的客户端和服务器的连接状态就是SyncConnected |
| KeeperState.AuthFailed | zookeeper客户端进行连接认证失败时,发生该状态 |
需要说明的是,这些状态在触发时,所记录的事件类型都是:EventType.None
- zookeeper中的事件。当zookeeper客户端监听某个znode节点”/node-x”时:
| zookeeper事件 | 事件含义 |
|---|---|
| EventType.NodeCreated | 当node-x这个节点被创建时,该事件被触发 |
| EventType.NodeChildrenChanged | 当node-x这个节点的直接子节点被创建、被删除、子节点数据发生变更时,该事件被触发。 |
| EventType.NodeDataChanged | 当node-x这个节点的数据发生变更时,该事件被触发 |
| EventType.NodeDeleted | 当node-x这个节点被删除时,该事件被触发。 |
| EventType.None | 当zookeeper客户端的连接状态发生变更时,即KeeperState.Expired、KeeperState.Disconnected、KeeperState.SyncConnected、KeeperState.AuthFailed状态切换时,描述的事件类型为EventType.None |
2.2、获取相应的响应
我们详细描述了zookeeper客户端连接的状态和zookeeper对znode节点监听的事件类型,下面我们来讲解如何建立zookeeper的watcher监听。在zookeeper中,并没有传统的add****Listener这样的注册监听器的方法。而是采用zk.getChildren(path, watch)、zk.exists(path, watch)、zk.getData(path, watcher, stat)这样的方式为某个znode注册监听。也可以通过zk.register(watcher)注册默认监听。
- 无论哪一种注册监听的方式,都可以对EventType.None事件进行监听,如果有多个监听器,这些监听器都会收到EventType.None事件。(后文实验)
下表以node-x节点为例,说明调用的注册方法和可监听事件间的关系:
| 注册方式 | NodeCreated | NodeChildrenChanged | NodeDataChanged | EventType.NodeDeleted |
|---|---|---|---|---|
| zk.getChildren(“/node-x”,watcher) | 可监控 | 可监控 | ||
| zk.exists(“/node-x”,watcher) | 可监控 | 可监控 | 可监控 | |
| zk.getData(“/node-x”,watcher) | 悖论 | 可监控 | 可监控 |
网上很多文章都会引用官方的一个事件表格,这里我就不再引用了,请自行百度吧(反正我觉得80%是抄的,并没有把事件对应的监听关系说清楚),还不如看我这个
2.3、watcher机制
zookeeper中的watcher机制很特别,请注意以下一些关键的经验提醒(这些经验提醒在其他地方找不到):
一个节点可以注册多个watcher,但是分成两种情况,当一个watcher实例多次注册时,zkClient也只会通知一次;当多个不同的watcher实例都注册时,zkClient会依次进行通知(并不是很多网贴粗略说的“多次注册一次通知”),后文将会有实验。
监控同一个节点X的一个watcher实例,通过exist、getData等注册方式多次注册的,zkClient也只会通知一次。这个原理在很多网贴上也都有说明,后文我们同样进行实验。
注意,很多网贴都说zk.getData(“/node-x”,watcher)这种注册方式可以监控节点的NodeCreated事件,实际上是不行的(或者说没有意义)。当一个节点还不存在时,zk.getData这样设置的watcher是会抛出KeeperException$NoNodeException异常的,这次注册会失败,watcher也不会起作用;一旦node-x节点存在了,那这个节点的NodeCreated事件又有什么意义呢?(后文做实验)
zookeeper中并没有“永久监听”这种机制。网上所谓实现了”永久监听”的帖子,只是一种编程技巧。思路可以归为两类:一种是“在保证所有节点的watcher都被重新注册”的前提下,再进行目录、子目录的更改;另外一种是“在监听被触发后,被重新注册前,重新取一次节点的信息”确保在“监听真空期”znode没有变化。 有兴趣的读者可自行百度。
下图可以反映zookeeper-watcher的监听真空期:
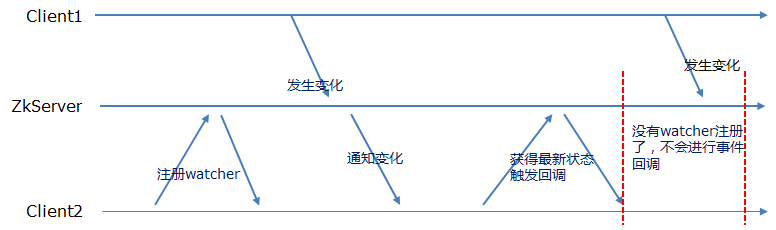
我本人对真空期的处理,更倾向于,注册监听后主动检查本次节点的znode-version和上次节点的znode-version是否一致,来确定是否真空期有节点变化。
3、代码示例
实践是检验真理的唯一途径
3.1、验证监听
3.1.1、验证对一个znode多次注册watcher
为了简单起见,我们先检验一个最好检验的东西,就是为一个znode注册多个watcher时,watcher的通知机制到底是什么样的。这样依赖,第一次接触zookeeper的读者也可以根据代码,快速上手。我们依据前文建立的zookeeper集群,启动了zookeeper的三个工作节点,并注册watcher(我们只会使用其中的一个):
然后我们加测,使用getDate方法是否能够检测一个不存在的节点“Y”的创建事件。
package com.yinwenjie.test.zookeepertest.test;
import java.io.FileNotFoundException;
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.Watcher.Event.EventType;
import org.apache.zookeeper.Watcher.Event.KeeperState;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.springframework.util.Log4jConfigurer;
import com.yinwenjie.test.zookeepertest.TestZookeeperAgainst;
/**
* 这个测试类测试多个watcher监控某一个znode节点的效果。<br>
* servers:192.168.61.129:2181,192.168.61.130:2181,192.168.61.132:2181<br>
* 为了验证zk集群的工作效果,我们选择一个节点进行连接(192.168.61.129)。
* @author yinwenjie
*/
public class TestManyWatcher implements Runnable {
static {
try {
Log4jConfigurer.initLogging("classpath:log4j.properties");
} catch (FileNotFoundException ex) {
System.err.println("Cannot Initialize log4j");
System.exit(-1);
}
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(TestZookeeperAgainst.class);
public static void main(String[] args) throws Exception {
TestManyWatcher testManyWatcher = new TestManyWatcher();
new Thread(testManyWatcher).start();
}
public void run() {
/*
* 验证过程如下:
* 1、验证一个节点X上使用exist方式注册的多个监听器(ManyWatcherOne、ManyWatcherTwo),
* 在节点X发生create事件时的事件通知情况
* 2、验证一个节点Y上使用getDate方式注册的多个监听器(ManyWatcherOne、ManyWatcherTwo),
* 在节点X发生create事件时的事件通知情况
* */
//默认监听:注册默认监听是为了让None事件都由默认监听处理,
//不干扰ManyWatcherOne、ManyWatcherTwo的日志输出
ManyWatcherDefault watcherDefault = new ManyWatcherDefault();
ZooKeeper zkClient = null;
try {
zkClient = new ZooKeeper("192.168.61.129:2181", 120000, watcherDefault);
} catch (IOException e) {
TestManyWatcher.LOGGER.error(e.getMessage(), e);
return;
}
//默认监听也可以使用register方法注册
//zkClient.register(watcherDefault);
//1、========================================================
TestManyWatcher.LOGGER.info("=======&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









