






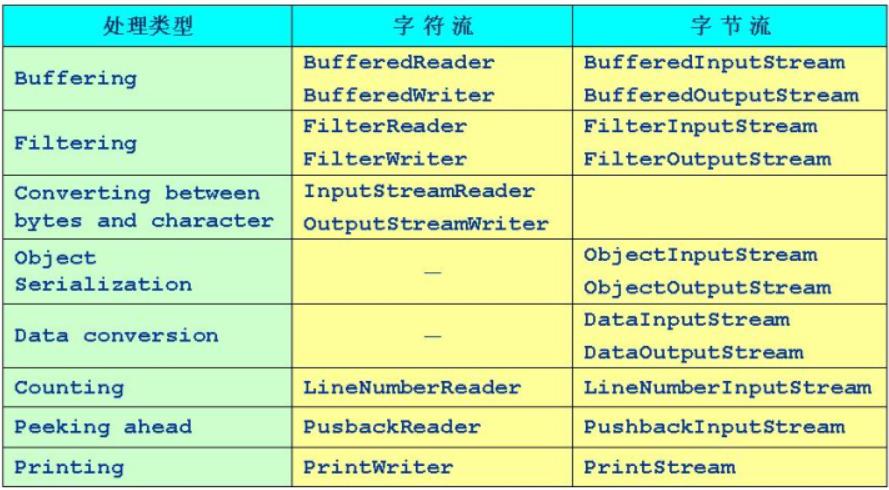
处理流类型
一、缓冲流
▶缓冲流要“套接”在相应的节点流之上,对读写的数据提供了缓冲的功能,提高了读写的效率,同时增加了一些新的方法。
▶J2SDK提供了四种缓冲流,其常见的构造方法为:
BufferedReader (Reader in)
BufferedReader (Reader in, int size) //sz为自定义缓存区的大小
BufferedWriter (Writer out)
BufferedWriter (Writer out, int size)
BufferedInputStream (InputStream in)
BufferedInputStream (InputStream in, int size)
BufferedOutputStream (OutputStream out)
BufferedOutputStream (OutputStream out, int size)
●缓冲输入流支持其父类的mark 和reset 方法。
●BufferedReader 提供了readLine 方法用于读取一行字符串。(以 \r 或 \n 分隔)
●BufferedWriter 提供了newLine 用于写入一个行分隔符。
●对于输出的缓冲流,写出的数据会先在内存中缓存,使用 flush 方法将会使内存中的数据立刻写出。
例1:TestBufferStream1.java
import java.io.*;
public class TestBufferStream1 {
public static void main(String[] args) {
try{
FileInputStream fis = new FileInputStream("C:\\Users\\Administrator\\desktop\\HelloWorld.java");
BufferedInputStream bis = new BufferedInputStream(fis);
int c = 0;
System.out.println((char)bis.read());
System.out.println((char)bis.read());
bis.mark(100);//把标记放到100,从100开始读
for(int i=0; i<=10 && (c=bis.read())!=-1 ; i++) {
System.out.print((char)c+" ");
}
System.out.println();
bis.reset();//回到标记的点
for(int i=0; i<=10 && (c=bis.read()) != -1; i++) {
System.out.print((char)c+" ");
}
bis.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}
例2:TestBufferStream2.java
import java.io.*;
public class TestBufferStream2 {
public static void main(String[] args) {
try {
BufferedWriter bw = new BufferedWriter(new FileWriter("C:\\Users\\Administrator\\desktop\\Result1.txt"));
BufferedReader br = new BufferedReader(new FileReader("C:\\Users\\Administrator\\desktop\\Result1.txt"));
String s = null;
for(int i=1; i<=100; i++) {
s = String.valueOf(Math.random());
bw.write(s);
bw.newLine();
}
bw.flush();
while((s=br.readLine()) != null) {
System.out.println(s);
}
bw.close();
br.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
二、转换流
●InputStreamReader 和 OutputStreamWriter 用于字节数据到字符数据之间的转换。
简单的说,就是把InputStream转换成Reader。于是现在可以直接写入字符,而不是一个字节一个字节的写入。
●InputStreamReader 需要和 InputStream “套接”。
●OutputStreamWriter 需要和 OutputStream “套接”。
●转换流在构造时可以指定其编码集合,例如:
InputStream isr = new InputStreamReader(System.in, "ISO8859_1")
例1:TestTransform.java
import java.io.*;
public class TestTransform1 {
public static void main(String[] args) {
try {
OutputStreamWriter osw = new OutputStreamWriter(
new FileOutputStream("C:\\Users\\Administrator\\desktop\\Result2.txt"));
osw.write("microsoftibmsunapplehp");
System.out.println(osw.getEncoding());
osw.close();
osw = new OutputStreamWriter(
new FileOutputStream("C:\\Users\\Administrator\\desktop\\Result2.txt",true),
"ISO8859_1");
osw.write("microsoftibmsunapplehp");
System.out.println(osw.getEncoding());
osw.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}例2:TestTransform2.java(阻塞/同步)
import java.io.*;
public class TestTransform2 {
public static void main(String[] args) {
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
String s = null;
try {
s = br.readLine();
while(s!=null) {
if(s.equalsIgnoreCase("exit")) {
break;
}
System.out.println(s.toUpperCase());
s = br.readLine();
}
br.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}三、数据流
●DataInputStream 和 DataOutputStream 分别继承自 InputStream 和 OutputStream ,它属于处理流,需要分别“套接”在 InputStream 和 OutputStream 类型的节点流上。
●DataInputStream 和 DataOutputStream 提供了可以存取与机器无关的Java原始类型数据(如:int, double等)的方法。
●DataInputStream 和 DataOutputStream 的构造方法为:
DataInputStream (InputStream in)
DataOutputStream (OutputStream out)
例3:TestDataStream
import java.io.*;
public class TestDataStream {
public static void main(String[] args) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();//第一步在内存中分配了一个字节数组,第二步把管道插上去
DataOutputStream dos = new DataOutputStream(baos);//
try {
dos.writeDouble(Math.random());
dos.writeBoolean(true);
ByteArrayInputStream bais =
new ByteArrayInputStream(baos.toByteArray());
System.out.println(bais.available());
DataInputStream dis = new DataInputStream(bais);
System.out.println(dis.readDouble());
System.out.println(dis.readBoolean());
dos.close();
dis.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}注:队列。先进先出,先写的先读
四、Print 流
●PrintWriter 和 PrintStream 都属于输出流,分别针对字符和字节。
●PrintWriter 和 PrintStream 提供了重载的 Print 方法
●Println 方法用于多种数据类型的输出。
●PrintWriter 和 PrintStream 的输出操作不会抛出异常,用户通过检测错误状态获取错误信息。
●PrintWriter 和 PrintStream 有自动 flush 功能
例1:TestPrintStream1.java
import java.io.*;
public class TestPrintStream1 {
public static void main(String[] args) {
PrintStream ps = null;
try {
FileOutputStream fos =
new FileOutputStream("C:\\Users\\Administrator\\Desktop\\log.dat");
ps = new PrintStream(fos);
}catch(IOException e){
e.printStackTrace();
}
if(ps != null) {
System.setOut(ps);
}
int ln = 0;
for(char c = 0; c <= 60000; c++) {
System.out.print(c+" ");
ln++;
if(ln >=100) {
System.out.println();
ln = 0;
}
}
}
}例2:TestPrintStream2.java
import java.io.*;
public class TestPrintStream2 {
public static void main(String[] args) {
String filename = args[0];
if(filename!=null) {
list(filename,System.out);//System.out是PrintStream类型
}
}
public static void list(String f,PrintStream fs) {
try{
BufferedReader br = new BufferedReader(new FileReader(f));
String s = null;
while((s=br.readLine()) != null) {
fs.println(s);
}
br.close();
}catch(IOException e){
fs.println("无法读取文件");
}
}
}例3:TestPrintStream3.java
import java.util.*;
import java.io.*;
public class TestPrintStream3 {
public static void main(String[] args) {
String s = null;
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
try {
FileWriter fw = new FileWriter("C:\\Users\\Administrator\\Desktop\\logfile.log",true);
PrintWriter log = new PrintWriter(fw);
while( (s=br.readLine()) != null ) {
if(s.equalsIgnoreCase("exit")) {
break;
}
System.out.println(s.toUpperCase());
log.println("_____");
log.println(s.toUpperCase());
log.flush();
}
log.println("==="+new Date()+"===");
log.flush();
log.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}五、Object 流
▶直接将 Object 写入或读出
●transient 关键字
transient修饰的成员变量在序列化的时候不予考虑
●serializable接口
标记性接口。想把某个对象序列化,必须实现这个接口,打上标记。
●externalizable 接口
一个serializable的子接口,可以控制序列化的过程。有两个方法:readExternal (ObjectInput in) 和 writeExternal(ObejectOutput out)
例1:TestObjectIO.java
import java.io.*;
public class TestObjectIO {
public static void main(String[] args) {
try{
T t = new T();
t.k = 8;
FileOutputStream fos = new FileOutputStream("C:\\Users\\Administrator\\Desktop\\testobjectio.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(t);
oos.flush();
oos.close();
FileInputStream fis = new FileInputStream("C:\\Users\\Administrator\\Desktop\\testobjectio.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
T tReaded = (T)ois.readObject();
System.out.println(tReaded.i + " "+tReaded.j + " "+tReaded.d+" "+tReaded.k);
}catch(IOException e){
e.printStackTrace();
}catch(ClassNotFoundException e1){
e1.printStackTrace();
}
}
}
class T implements Serializable {
int i = 0;
int j = 9;
double d = 2.3;
int k = 15;
}















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









