









一、前言
以前在FME软件遇到处理两组数据之间分别一一比对的时候就脑壳痛,FME大佬们都纷纷献计叫使用循环,然后我看了他们的模板,转换器太多,很绕,难以理解。后来他们又说可用Pythoncaller来写几行代码实现。因为之前没有系统学过Python语言,所以就此作罢。最近学了点Python,写了几个脚本,也有朋友问到这种问题,于是乎决定试下调用Pythoncaller来处理一下。
二、任务要求
当日期在某个开始时间和结束日期之间,那么就把图2的唯一值赋值给图1的待赋值。
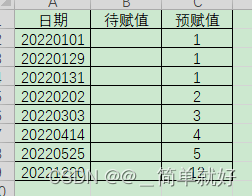
图1 需要根据日期区间来赋值的表格
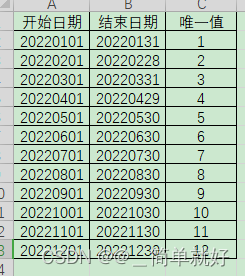
图2 需要作比对的表格
三、实现路劲
- 用Aggregator转换器把 它们整成列表,当然可以用Listbuilder转换器
- 然后用FeatureMerger把它们合并成一个要素
- 进入PythonCaller转换器
- 把需要用到的列表传到转换器里来
- 创建过程列表
- 然后用一个for和while来执行一个列表与另一个列表元素之间的一一对比。
- 添加feature.setAttribute('df_list',df_list)代码,这个代码的意思就是把df_list列表设置为FME属性,但其实从PythonCaller转换器出来df_list其实还是列表。但你不能没有这句代码!
- PythonCaller要暴露的属性这里也一定要把输入df_list{},与上一步的设置FME属性代码缺一不可。
- 从PythonCaller出来后接一个ListExploder转换器把刚刚的df_list列表暴露出来即可。
代码是需要卸载FeatureProcessor类的input函数里。我写的那部分代码有注释了开始和结束的标志,其他都是Pythoncaller自带的代码,不用管。代码如下:
import fme
import fmeobjects
class FeatureProcessor(object):
"""Template Class Interface:
When using this class, make sure its name is set as the value of the 'Class
to Process Features' transformer parameter.
"""
def __init__(self):
"""Base constructor for class members."""
pass
def input(self, feature):
"""This method is called for each FME Feature entering the
PythonCaller. If knowledge of all input Features is not required for
processing, then the processed Feature can be emitted from this method
through self.pyoutput(). Otherwise, the input FME Feature should be
cached to a list class member and processed in process_group() when
'Group by' attributes(s) are specified, or the close() method.
:param fmeobjects.FMEFeature feature: FME Feature entering the
transformer.
"""
#新增代码开始
print('分割线'+10*'——————')
dg_list = feature.getAttribute('daiguajie{}.日期')
ys_start_list = feature.getAttribute('yuanshi{}.开始日期')
ys_end_list = feature.getAttribute('yuanshi{}.结束日期')
id_list = feature.getAttribute('yuanshi{}.唯一值')
df_list = []
print(f'一共信息条数:{len(dg_list)}')
for i in range(len(dg_list)):
j = 0
while j < len(ys_start_list):
print(f'正在处理第{i}信息:{dg_list[i]}')
print(f'开始和结束时间区间:{ys_start_list[j]}——{ys_end_list[j]}')
if dg_list[i] >= ys_start_list[j] and dg_list[i] <= ys_end_list[j]:
df_list.append(id_list[j])
print(f'已匹配唯一值:{id_list[j]}')
break
else:
j += 1
if j < len(ys_start_list):
print('不匹配')
#当搜索到最后一个都没有比配到时,赋空值
else:
df_list.append('')
print('未匹配到,赋空值')
print('分割线'+10*'——————')
#添加字段,此行必须要有!
feature.setAttribute('df_list',df_list)
#新增代码结束
self.pyoutput(feature)
def close(self):
"""This method is called once all the FME Features have been processed
from input().
"""
pass
def process_group(self):
"""When 'Group By' attribute(s) are specified, this method is called
once all the FME Features in a current group have been sent to input().
FME Features sent to input() should generally be cached for group-by
processing in this method when knowledge of all Features is required.
The resulting Feature(s) from the group-by processing should be emitted
through self.pyoutput().
FME will continue calling input() a number of times followed
by process_group() for each 'Group By' attribute, so this
implementation should reset any class members for the next group.
"""
pass
五、任务小结
PythonCaller转换器有个问题,就是进入的属性数据没有暴露的话,出来就会丢失,所以需要加个count等转换器来做个标识,方便重新挂接到原始数据上去。这只是测试用的,模板我已上传到资源,需要的朋友可以下载参考看下。















 2314
2314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









