









DeepSeek什么来头?
在人工智能圈子里,DeepSeek这名字最近火得一塌糊涂。要是你还没听说过,那可真得好好补补课了。DeepSeek到底是个什么来头?
一、出身不凡
DeepSeek可不是那种“野蛮生长”的选手,它背后有个“金主爸爸”——幻方量化。幻方量化在量化投资界可是个响当当的角色,手里攥着大把资源和资金。DeepSeek就是在这样的“富二代”背景下诞生的,可谓是含着“金汤匙”出生。不过,别以为它只是靠“拼爹”混日子。DeepSeek的创始人梁文锋可不是个吃软饭的。据说他是个技术大牛,平时话不多,但一开口就能让人眼前一亮。有一次,他被问到DeepSeek的核心竞争力是什么,他淡定地回答:“我们就是靠技术吃饭的。”这话听起来是不是有点“凡尔赛”?不过,你得承认,人家有这个底气。
二、技术“黑科技”
DeepSeek最让人服气的就是它的技术。2024年5月,DeepSeek发布了DeepSeek V2,号称推理成本低到每百万token只要1块钱。这价格,简直比“跳楼大甩卖”还划算。其他大厂一听,纷纷坐不住了,赶紧跟着降价。DeepSeek这一招,直接引发了中国大模型的价格战,堪称“价格屠夫”。
DeepSeek的技术可不是靠“价格战”取胜的。它的DeepSeek V2采用了多头潜在注意力(MLA)机制和专家混合模型(MoE)架构,听起来是不是很复杂?简单来说,就是让机器变得更聪明,同时还能省下不少成本。这就好比你买了一辆超级跑车,不仅速度快,而且油耗还低,你说这划算不划算?
三、市场“搅局者”
DeepSeek一出道,就搅动了整个AI市场。它就像一颗“炸弹”,扔进了原本平静的湖面,溅起了一片水花。其他大厂原本还在“按部就班”地发展,DeepSeek一出现,大家突然发现,原来AI还可以这样玩。
DeepSeek的出现,让很多传统玩家感到了压力。不过,压力也是动力嘛。DeepSeek的崛起,也促使整个行业加速发展,大家都在努力提升自己的技术和服务。这就好比在赛场上,突然杀出一个“黑马”,让其他选手都不敢掉以轻心。
四、槽点与争议
当然,DeepSeek也不是没有槽点。比如,有人就质疑它是不是“出道即巅峰”?毕竟,技术更新换代太快了,今天的技术巨头,说不定明天就被后浪拍死在沙滩上。DeepSeek虽然现在风头正劲,但未来能不能一直保持领先地位,谁也说不好。
还有人调侃说,DeepSeek的“价格战”是不是有点“杀敌一千,自损八百”?毕竟,价格降得太狠,虽然能吸引用户,但会不会影响自己的利润呢?不过,DeepSeek似乎并不担心这个问题,他们坚信,只要技术过硬,市场自然会认可。
五、未来可期
尽管有槽点,但DeepSeek的未来还是被很多人看好的。毕竟,技术才是硬实力。DeepSeek已经在人工智能领域证明了自己的实力,未来只要继续深耕技术,提升用户体验,它绝对有机会成为行业的领军者。
DeepSeek的崛起,也让我们看到了中国AI企业的潜力。过去,我们总觉得国外的AI技术更先进,但现在,DeepSeek用自己的实力证明,中国AI企业也能在全球舞台上大放异彩。
总之,DeepSeek到底是个什么来头?它是一个技术大牛,是一个市场“搅局者”,也是一个充满潜力的未来之星。不管你怎么看,DeepSeek已经在人工智能的江湖里留下了浓墨重彩的一笔。
DeepSeek牛在哪儿?
大家好,DeepSeek,所有人都在让我讲一讲,这就来说说。DeepSeek牛不牛?牛在哪儿?怎么变牛的?会产生什么影响?为什么英伟达的股票会大跌呢?
首先,你说这个DeepSeek牛不牛?答案是肯定的,当然牛。但牛在哪儿呢?首先,DeepSeek最新的R1模型,在很多方面都媲美了像OPENAI的O1等一众国际上领先的模型。不过,咱们还是理智一点,DeepSeek的R1是在推理等多种任务上追平了世界领先水平,并不是像很多营销号说的什么“拳打Open AI,脚踢Gemini”。
本来,我们国家的大语言模型与国际上领先的大语言模型相比,可能有个两年的差距。但是,R1的出现,可以说是大致弥合了这个差距。不过,光追平还不够说明它的厉害之处。更厉害的是,它不仅追平了,成本还大幅降低。整个R1的训练成本大概在六百多万美元,但是反观其他模型,训练一次可能都是以亿美元为单位的。这再一次证明,我国在降低成本方面是专业的,谁都别来跟我们比这个降本增效。
还有一个厉害的点,就是它是开源的。大语言模型的开源与闭源之争,由来已久。比如Open AI的模型,我们只能使用,但里面的参数权重等一概不知。而开源模型的代表,如Facebook的LLama、欧洲的Mistral等。DeepSeek这一波开源操作,直接把开源提升了一个很大的档次。
所以,明白了吧,DeepSeek牛的点在于:表现很好,追平了领先水平,同时成本非常低,还开源。
DeepSeek的出现对英伟达的市场地位产生了什么影响?
DeepSeek,这个横空出世的AI“新星”,最近可真是让整个科技圈热闹非凡。它不仅让国内的科技迷们欢呼雀跃,甚至让全球的AI行业都为之一震。而在这个过程中,英伟达这位曾经的“算力霸主”,似乎感受到了一丝凉意。
股价暴跌:市场的“惊魂一跳”
先来说说最直观的——股价。DeepSeek的崛起,直接让英伟达的股价“跳水”。美东时间1月27日,英伟达股价暴跌16.97%,市值蒸发近6000亿美元,创出美股单日市值蒸发纪录。这可不是普通的市场波动,而是市场对英伟达垄断地位可能被打破的“惊魂一跳”。
为啥会这样?很简单,市场突然发现,原来高性能的AI模型不一定非得依赖英伟达的高端芯片。DeepSeek用不到600万美元的成本,就训练出了对标ChatGPT-4o的模型。这就好比你一直以为买豪车必须得选劳斯莱斯,结果突然冒出来个国产车,性能不相上下,价格却只要零头。投资者们开始慌了,英伟达的高估值还能撑得住吗?
垄断挑战:打破“硬件神话”
DeepSeek的厉害之处在于,它通过优化底层编码,展示了在非英伟达CUDA系统上实现高效AI计算的可能性。这就好比在英伟达的“算力王国”旁边,突然开了一条新路,让其他公司看到了绕过英伟达垄断的希望。
以前,英伟达凭借其强大的GPU芯片和CUDA平台,几乎垄断了AI计算的硬件市场。但DeepSeek的出现,让市场意识到,原来“硬件神话”并非不可打破。这就好比你一直以为只有英特尔的处理器才能跑得快,结果AMD横空出世,不仅性能不差,价格还更实惠。英伟达的“独霸江湖”地位,突然变得不那么稳固了。
市场信心:投资者的“信心危机”
DeepSeek的成功,让市场对英伟达的长期垄断地位产生了怀疑。投资者们开始担心,英伟达的高利润模式可能受到威胁。毕竟,如果其他公司都能像DeepSeek一样,用更低的成本训练出高性能的AI模型,那英伟达的高端芯片需求自然会减少。
这种担忧并不是空穴来风。据统计,2024年前8个月,微软、Meta、谷歌、亚马逊等科技巨头总计向AI数据中心投入了1250亿美元。但DeepSeek的低定价策略和高性能表现,让市场开始质疑这些巨额资本支出的合理性。投资者们开始重新评估英伟达的未来增长预期,市场信心自然就受到了冲击。
合作趋势:英伟达的“求生欲”?
尽管面临挑战,但英伟达也并非坐以待毙。它也意识到,合作才是未来的趋势。未来,英伟达可能会与DeepSeek等公司合作,共同推动AI技术的发展。毕竟,技术的进步是不可阻挡的,与其在垄断的“孤岛”上固步自封,不如开放合作,拥抱新的技术和理念。
这种合作趋势其实也是一种“求生欲”。英伟达知道,如果继续坚持“硬件至上”的理念,可能会被市场淘汰。而与DeepSeek等新兴力量合作,不仅能分享技术红利,还能在新的市场格局中找到自己的位置。
总结:DeepSeek的“蝴蝶效应”
DeepSeek的出现,就像一只蝴蝶扇动翅膀,引发了AI行业的一场“风暴”。它不仅让英伟达的股价暴跌,还挑战了英伟达的垄断地位,动摇了投资者的信心,甚至改变了整个AI市场的投资逻辑。但这场“风暴”也并非全是坏事,它让市场更加理性,也让技术发展更加多元化。
DeepSeek的成功,证明了技术创新的力量,也让我们看到了中国科技企业的潜力。未来,AI技术的发展将不再局限于硬件的堆砌,而是会更加注重算法的优化和应用场景的拓展。英伟达和DeepSeek,或许会在未来的AI战场上,从对手变成伙伴,共同推动人类科技的进步。
DeepSeek是如何实现较低成本达到类似效果的?
DeepSeek是如何实现较低成本达到类似效果的?
在AI圈子里,DeepSeek最近可是个“流量明星”。它不仅在技术上追平了国际领先水平,更让人惊讶的是,它居然用极低的成本做到了这一切。这就好比你花了几块钱买了一个地摊货,结果发现它和名牌货一样好用,简直让人不敢相信。那么,DeepSeek到底是怎么做到的呢?别急,我来给你八一八。
- 底层优化:给芯片“开挂”
DeepSeek的第一个秘诀,就是对底层的PTX编码进行了优化。这听起来很技术,简单来说,就是给芯片“开挂”。DeepSeek的团队通过优化编码,让芯片的算力效率大幅提升。这就好比你给汽车的发动机加了个“涡轮增压”,原本只能跑100公里的芯片,现在能跑200公里了。
这种优化让DeepSeek能够在较低端的芯片上实现高效运行。以前,训练一个高性能的AI模型,必须得用英伟达的高端GPU,成本高得吓人。DeepSeek却说:“不,我用普通的芯片也能做到。”这就好比你去餐厅吃饭,别人点的都是几百块的招牌菜,DeepSeek却用几块钱的家常菜做出了同样的味道。 - 开源策略:让全世界帮你改代码
DeepSeek的第二个秘诀,就是开源。开源听起来很“高大上”,但其实很简单。DeepSeek把代码和模型全部公开,让全球的开发者都能参与改进。这就好比你把自家的菜谱公开,让全世界的厨师都来帮你改进。开源的好处是显而易见的:低成本、高迭代速度。
开源生态让DeepSeek在与闭源模型的竞争中占据了绝对优势。闭源模型就像一个“黑盒子”,用户只能用,但不知道里面是怎么工作的。而DeepSeek的开源模式,让开发者可以自由地研究和改进模型。这就好比你买了一个透明盒子,不仅能看清楚里面是怎么工作的,还能自己动手改一改。这种透明和自由,让DeepSeek迅速吸引了全球开发者的关注和支持。 - 算法创新:用“小聪明”打败“大力士”
DeepSeek的第三个秘诀,就是算法创新。DeepSeek的团队在算法层面进行了大量创新,采用了更高效的模型架构和训练方法。比如,它通过强化学习和小模型蒸馏等技术,在有限的算力投入下实现了类似的效果。
这就好比你和一个大力士比赛举重,你没有他的力气大,但你用了一个巧妙的杠杆,结果轻松举起了和他一样重的杠铃。DeepSeek的算法创新,就是这种“小聪明”。它没有用更多的算力,而是通过更聪明的方法,达到了和高端模型一样的效果。 - 团队能力:一群“技术怪才”的魔法
最后,DeepSeek的成功离不开它的团队。DeepSeek的团队成员都是技术大牛,他们不仅技术能力强,还有一颗创新的心。他们用有限的资源,实现了技术突破。这就好比一群“技术怪才”在一起,用有限的材料,变出了一个魔法。
DeepSeek的团队通过创新的思维方式和高效的工程能力,让DeepSeek在资源有限的情况下,依然能够表现出色。他们就像一群魔法师,用技术的力量,让DeepSeek在AI圈子里一鸣惊人。
总结
DeepSeek是如何实现较低成本达到类似效果的?答案其实很简单:底层优化、开源策略、算法创新和强大的团队能力。这四个秘诀,让DeepSeek在AI圈子里脱颖而出。DeepSeek的成功,不仅让我们看到了技术创新的力量,也让我们看到了中国科技企业的潜力。未来,DeepSeek还会给我们带来什么惊喜?让我们拭目以待吧!
DeepSeek的出现对AI行业未来的发展有哪些启示?
最近,DeepSeek这个“新晋网红”在AI圈子里掀起了轩然大波,仿佛一颗突然掉落的“深水炸弹”,把原本平静的湖面搅得波澜壮阔。那么,DeepSeek的出现到底给AI行业未来的发展带来了哪些启示呢?
- 技术多元化:小团队也能“弯道超车”
DeepSeek的成功,简直就是AI技术多元化发展的“活招牌”。过去,AI行业一直被少数巨头“霸占”,大家好像都默认了“只有巨头才能玩转AI”的规则。但DeepSeek横空出世,直接用实力证明:小团队也能“弯道超车”!
开源社区和小团队的潜力被彻底激发了。这就好比在一场马拉松比赛中,原本大家都以为冠军非“专业选手”莫属,结果半路杀出个“业余选手”,不仅跑得飞快,还把专业选手远远甩在身后。DeepSeek的出现,让AI行业不再局限于巨头的技术路线,未来,更多的创新和突破将来自开源社区和小团队。这不,现在开源社区里热闹得跟过年似的,大家都在摩拳擦掌,准备大干一场。 - 成本控制:省钱也能“办大事”
DeepSeek最让人咋舌的地方,就是它以极低的成本实现了高效的人工智能模型。这就好比你花了几块钱买了一个地摊货,结果发现它和名牌货一样好用,简直让人不敢相信。DeepSeek的出现,让整个AI行业都开始重新审视成本控制的重要性。
过去,AI行业一直有个“怪圈”:大家都觉得只有投入海量的资源,才能训练出好的模型。DeepSeek却用实际行动证明:通过优化算法和提高效率,同样能办大事!未来,AI的发展将更加注重成本控制,毕竟,谁不想用最少的钱办最多的事呢? - 开源生态:大家一起“搭积木”
DeepSeek的开源模式,简直就是给开源社区送了一把“金钥匙”。开源生态的低成本和高迭代速度,让AI技术的普及和应用加速了不少。DeepSeek把代码和模型全部公开,让全球的开发者都能参与改进。这就好比你把自家的菜谱公开,让全世界的厨师都来帮你改进。开源的好处是显而易见的:大家一起“搭积木”,模型自然越搭越好。
开源生态的崛起,也让更多企业看到了“合作共赢”的可能性。未来,AI行业将不再是一个个“孤岛”,而是通过开源的力量,形成一个紧密相连的“大陆”。大家在这个“大陆”上,共同探索、共同进步,把AI技术推向新的高度。 - 行业竞争:巨头们也得“卷”起来
DeepSeek的出现,无疑给AI行业加了一把“火”。原本还算“平静”的市场,瞬间变得“硝烟弥漫”。DeepSeek的成功,让其他企业感受到了前所未有的压力。这就好比在赛场上,原本领先的选手突然发现有人从后面追了上来,而且还跑得飞快,能不慌吗?
这种竞争压力,反而成了推动行业发展的“催化剂”。各企业为了不被落下,纷纷加大研发投入,努力提升自己的技术水平。未来,AI行业的竞争将更加激烈,但这种竞争也将推动技术创新和优化,提升整个行业的水平。毕竟,没有竞争,哪来的进步呢? - 应用拓展:AI“飞入寻常百姓家”
DeepSeek的低成本和高性能特点,直接降低了AI技术的应用门槛。这就好比过去只有“贵族”才能享受的奢侈品,现在普通百姓也能轻松拥有。DeepSeek的出现,让AI技术不再高不可攀,加速了AI技术在各个行业的推广和应用。
未来,AI将“飞入寻常百姓家”,在医疗、教育、金融、交通等各个领域大放异彩。DeepSeek的低成本模式,让更多的中小企业和创业者也能参与到AI的应用开发中来,推动AI行业整体向前发展。毕竟,技术的价值在于应用,只有让更多人用起来,才能真正发挥它的价值。 - 人才竞争:全球“抢人”大战开启
DeepSeek的成功,不仅让技术圈“炸开了锅”,也让人才市场“热闹非凡”。AI人才的稀缺性,让DeepSeek的成功瞬间吸引了全球的目光。这就好比一场“抢人大战”,大家都在争抢有限的AI人才资源。
未来,企业和研究机构将加大对AI人才的培养和引进力度。毕竟,人才是技术发展的核心动力。DeepSeek的团队成员大多是技术大牛,他们的成功也激励了更多年轻人投身AI领域。未来,AI行业的人才竞争将更加激烈,但这种竞争也将推动行业人才的流动和发展,让整个行业充满活力。
总结
DeepSeek的出现,给AI行业带来了太多启示:技术多元化、成本控制、开源生态、行业竞争、应用拓展和人才竞争……这些启示,不仅让我们看到了AI行业的未来发展方向,也让我们看到了中国科技企业的巨大潜力。DeepSeek的成功,让我们明白:在这个充满竞争和机遇的时代,只要有创新的勇气和智慧,小团队也能创造大奇迹。
DeepSeek R1为什么要开源?
DeepSeek R1选择开源的原因是多方面的,可以从技术、市场、文化以及战略等多个角度进行分析:
- 技术层面:推动技术进步与创新
DeepSeek R1通过开源的方式,将模型权重和技术细节完全公开,这不仅有助于建立开发者社区的信任,还能促进技术的快速迭代和创新。开源使得全球开发者能够自由地使用、修改和分发该模型,从而推动AI技术的普及和应用。例如,DeepSeek R1在训练过程中采用了强化学习技术,显著提升了模型的推理能力,同时降低了训练成本。通过开源,这些技术细节可以被更多研究者和开发者学习和借鉴,进一步推动AI技术的发展。 - 市场层面:打破垄断与降低成本
开源是打破大型语言模型(LLM)被少数公司垄断的有效手段。DeepSeek R1的开源策略使得更多的企业和开发者能够以较低的成本接入AI服务,降低了技术门槛。例如,DeepSeek R1的API服务定价仅为OpenAI o1的3%左右,极大地降低了使用成本。这种低成本的开源模式不仅有助于吸引更多的用户和开发者,还能加速AI技术在各个行业的应用和推广。 - 文化层面:开源文化的推动
开源不仅仅是一种技术行为,更是一种文化行为。DeepSeek R1的开源策略体现了开源文化中“开放即胜利”的理念。通过开源,DeepSeek能够与全球开发者社区建立更紧密的联系,促进知识共享和技术交流。这种文化理念在全球范围内得到了广泛认可,尤其是在年轻开发者群体中,开源工具的使用比例高达75%。 - 战略层面:提升影响力与拓展市场
开源是DeepSeek在全球市场中提升影响力和拓展市场份额的重要战略选择。作为一家中国公司,DeepSeek可能在西方市场面临一定的信任问题,尤其是涉及用户数据和合规性方面。通过开源,DeepSeek能够迅速建立信任,消除潜在用户的疑虑。此外,开源还能够吸引更多的合作伙伴和开发者,共同推动AI技术的发展。为国家应对美国"星际之门"计划提供了有力支撑。 - 社区与生态建设
开源有助于构建一个活跃的开发者社区和生态系统。DeepSeek R1的开源策略不仅提供了模型权重,还提供了详细的技术报告和训练细节。这种开放的态度能够吸引更多的开发者参与到模型的改进和优化中,形成一个良性循环的生态系统。例如,DeepSeek R1开源后,许多开发者已经开始基于该模型进行二次开发和创新。 - 应对竞争与挑战
开源也是DeepSeek应对行业竞争的一种策略。面对OpenAI、Meta、Google等巨头的竞争,DeepSeek通过开源能够快速扩大用户基础和开发者社区,形成规模效应。开源模型的灵活性和可定制性使其能够在特定场景中更好地满足用户需求,从而在竞争中脱颖而出。 - 推动行业标准与规范
通过开源,DeepSeek R1能够为AI行业树立新的标准和规范。开源模型的透明性和可验证性使得技术细节更加公开,有助于推动整个行业的规范化发展。例如,DeepSeek R1的技术报告详细记录了训练过程中的各种细节和经验教训,为其他研究者和开发者提供了宝贵的参考。
DeepSeek的技术亮点有哪些?
DeepSeek在工程技术上的创新主要有两个方面:
第一,是MOE(Mixture of Experts,专家混合模型)。MOE在DeepSeek中实现得非常好。所谓MOE,就是你这个大语言模型那么大,参数那么多,但用户的需求其实是多种多样的。解决用户不同的问题,可以把大模型分块,不同的块擅长解决不同的问题。根据用户的不同需求,并不是每次都要所有参数同时参与,而是根据需求调动所需的专家子模型。这样,不仅速度快,成本还低。
与MOE相对的是Dense Activation(密集激活),即所有参数在每个推理步骤中都参与。这就像你去医院看病,不管你哪里不舒服,整个医院的所有医生都会倾巢而出,每个医生都给你检查一遍。这样的做法确实比较稳定,但效率很低,也很贵。而MOE,则像根据你的初步症状,找到具体科室的具体医生来解决问题,效率更高。
第二个亮点,是在推理层面,DeepSeek不太需要SFT(Supervised Fine-Tuning,监督微调)。一般模型的训练,需要大量高质量的被标记过的数据。DeepSeek通过多用强化学习的方式,大大降低了对SFT的依赖。
DeepSeek为什么导致英伟达股票大跌?
至于英伟达股票大跌,我认为是“资源的诅咒”。DeepSeek告诉我们,要打造优秀的模型,可能不需要那么多、那么好的GPU。DeepSeek因为技术封锁,手头的GPU并不多,而且不是最先进的。但他们的模型依然优秀,这说明以前那种烧钱的方式,并不一定是唯一正确的。
所以,DeepSeek的成功,对英伟达这样的公司来说,无疑是一个打击。但这并不意味着英伟达的方式就不行,AI时代才刚刚开始,下一个阶段鹿死谁手,还未可知。
总之,DeepSeek的成功,让我们看到了AI领域的更多可能性。无论是开源还是闭源,降低成本还是提高效率,都有其独特的价值。希望大家能从中得到启发,为AI领域的发展贡献自己的力量。
DeepSeek:美国总统和美国科技巨头害怕了!
最近几天,DeepSeek的名字在各大平台上占据了热榜。但DeepSeek到底是什么来头?除了便宜,它还有什么厉害之处?美国在怕什么?英伟达被搞崩了吗?对我们的使用有什么影响?什么又叫做国运级的创新?最近试了吗?大家也都各执一词。另外,想试试DeepSeek有多厉害的朋友,也不要去看本地部署了,你会失望。原因和方法后面我都会说,那今天就一口气搞清楚DeepSeek的真相。
我们先快速理一下表面上的事儿。DeepSeek发布了一个V3模型,只花了557万美元,就多项能力超越了Llama2、ChatGPT 3.5和GPT-4 Pro。后来的R1和R1 zero模型直接赶上了OpenAI会员才能限量使用的GPT-4模型,API价格却只有GPT-4的1/30。再后来还发布了新的Janus Pro和Janus Pro Lite,只用14天、256张A100的配置,就搞出了一个在理解图像上超越此前模型的多模态模型,同时在性能上超越了阿里和SD3的GB小模型。并且,他们还把以上模型全都开源了,官网还无限量免费使用。于是,DeepSeek就把Meta花了这么多钱、当了几年的开源霸主给顶掉了,还碰到了OpenAI的顶尖模型,引起了美国的恐慌,美股暴跌。DeepSeek也登顶了美区应用商店第一名。
DeepSeek为什么这么厉害?
主要有三点:起步早、敢创新、团队精神。
第一,起步早。这一点我在上篇说V3的时候也讲到了。DeepSeek的母公司幻方量化,早在2019年就花两亿打造萤火一号超算集群,到2022年就已经默默囤了万张A100显卡,是GPT-3.5发布之后,第一波手握万卡入场券的少数几家国内模型公司。第二点,胆大心细,工程上精益求精,技术上大刀阔斧的创新。从他们的论文和模型发布上来看,通常他们会飞快地把一些前沿技术落地实验。尽管有些技术理论还在实验室没人去落地,但他们大胆地去创新新范式,一旦他们找到和认准的方向,就开始往死里搞优化。甚至有消息称他们绕过英伟达的限制,使用更底层的编程语言来优化性能。上个月发布的V3就把近几个月刚发布的最新前沿论文里面的压缩技巧都用上了,并且用得很好。所以它达到了高效、低成本、高性能。前几天的R1 zero,它也没有跟着o1的路线去做推理,实现了一条纯粹强化学习的全新道路。什么意思呢?比如原来要让模型学会推理,得先给它一大堆思考过程,看看什么叫思考。然后又有过程奖励模型去评判它的推理思路怎么样。但是R1 zero的纯强化学习,只有最终结果的对错,没有中间的思考过程指导,也没有任何的例子和规则去教它,就让它自己试,最后答对的加1分,错了就扣分。这样达到的结果是中间的那些关键推理步骤,也被称之为“啊哈时刻”,就是那种人类思考的时候那种顿悟,是没有指导自发产生的,可以说是真正的推理能力。然而他们从论文发布到实现,仅仅用了几周时间,他们真的有一种极速迭代的能力。昨晚的Janus Pro多模态模型实现了既能理解图片又能生成图片的大一统模型。这种既能理解又能生成的统一模型,倒也不是它第一个想做,但很难训练且效果差。所以OpenAI还在用GPT-4V和分开一个识别一个生成两个模型组合的方式来做。而DeepSeek Janus靠锁定大语言模型参数,用轻量级适配器就搞定了像素模型。然后完全抛弃了ImageNet这个行业标配,直接用真实场景数据进行训练,并通过实验得出了“东方神秘配方”的训练配比(5:1:4),实现了仅用14天、256张A100显卡的配置,训练出了一个小身材(7B参数)但理解和生成能力都很强的模型。总之,DeepSeek在工程化技巧上表现得非常出色,敢于大胆且快速地尝试新的技术范式。
第三就是刚刚提到的团队气质。DeepSeek在商业化上完全佛系,没有利润压力,也没有投资压力。与国内许多公司相比,DeepSeek几乎没有在营销和产品推广上花费太多精力,而是全身心投入到研究和追求AGI(通用人工智能)上。因此,这些快速的迭代和前沿的实验才有了肥沃的土壤。有些媒体甚至称他们比早期的OpenAI还要纯粹。
就这样,DeepSeek在V3上实现了震撼的性价比,R1和Janus 在保持高性价比的同时,还跑通了具有重大影响力的新范式,一跃成为AI领域最耀眼的存在。
美国人是怎么看待DeepSeek的呢?
首先,科技巨头们在V3火起来的时候,还在质疑DeepSeek没有创新,但随后又宣布自己的O3mini要免费。再然后,看到R1的纯强化学习,他们不得不承认DeepSeek确实令人印象深刻,但同时也在强调调价的事情,并且说他们显然要发布更好的模型,可却迟迟不见行动。马斯克则开始传播一些阴谋论,默默地给那些声称DeepSeek其实使用了几万张H100进行训练、成本并不低的推文点赞评论。而像Meta的小扎,其模型尚未发布就被超越,于是慌忙向美国政府喊话,申请代表美国出战,夺回开源领域的老大地位。
美国政界人士虽然对AI技术本身可能不太懂,但也不妨碍他们出来对产业进行敲打。有政客表示,一家中国公司应该成为美国产业的“警钟”,提醒我们要专注于竞争。于是,美国下令开放对AI研究的限制,让美国AI公司们尽情发展。其他美国政商人士则基本分为两派:一派认为要加强对中国芯片的出口限制;另一派则意识到,可能正是因为管制太严,反而逼出了中国科研人员的创新潜力。至于美国民间,可以说是乱成一锅粥,其中以狂骂美国资本和政府花钱乱搞的反对资本派,以及说中国会搞监视、不想使用DeepSeek的阴谋论派最为活跃。当然,也有有识之士比较中肯,但整体上来说,言论都是比较恐慌和戒备的。彭博社还爆料微软和OpenAI开始联合调查DeepSeek。不过,DeepSeek的APP在美区应用商店已经排到第一了,这说明大家其实都在用,真是“真香”定律。
美国到底在害怕什么?
美国对中国的芯片封锁,就像《三体》中三体人封锁地球一样,目的非常明确。但历来中国并不是没有突破过类似的封锁,被突破之后通常会引发激烈的竞争,让美国非常难受。中国制造、互联网、新能源等领域的发展速度,就是美国恐惧的来源。此外,过去外界一直认为美国是创新者,中国是追随者,甚至认为中国AI技术落后美国至少2到3年。然而,这次DeepSeek的R1模型发布后,巨头Meta反倒开了一个项目组紧急研究复刻R1,Hugging Face也连夜复刻。创新来自东方,差距如此之小,这才是撼动美国技术信心的东方创新力量。而且这次AI竞赛关乎的不只是利润,AI是先进生产力,甚至未来可能比人类更聪明、更有智慧。掌握AI技术,就相当于掌握了权力,美国和科技巨头们非常担心这种未来霸权的动摇。
我看到一篇文章说,DeepSeek就像《盗梦空间》里那个深入人心的种子,这个种子成为了那些企图以芯片封锁中国科技进展的人,脑海里挥之不去的噩梦,不免让他们陷入纠结:到底是继续封锁,还是会适得其反?
那么,这会对算力巨头英伟达产生冲击吗?短期内显然是已经产生了冲击。英伟达股价暴跌17%,实际上影响到的不只是科技股,甚至连算力背后的能源股,甚至整个美股都在下跌,这可以说是整个美国霸主信心的冲击和动摇。毕竟,此前美国还在大张旗鼓地推动5000亿美元的“星际之门”计划。而当国民看到DeepSeek用前一代的老GPU搞出这种性价比时,不禁要问:你们在搞什么?
然而,从本质来说,DeepSeek R1和V3的出现并不意味着不需要堆高端算力,甚至英伟达泡沫要破了。AI只要发展,算力就有需求。即使对于DeepSeek来说,美国不让买高端芯片也是一个头疼的问题。只不过,现在证明技术空间其实也很大,大家也会开始注重效率。而且,英伟达的优势是长时间的生态积累而来,除非算力已经成熟到像电力那样基础的标品,否则它的危机还不会那么快到来。这次情绪过去之后,长期来看,算力肯定还是强劲的硬需求,跌了莫慌。
以下是修改后的文章内容,修正了部分表述和逻辑问题,并根据搜索结果补充了一些信息:
华为和 DeepSeek 联手了。2025年2月1日,华为云官方宣布,华为云与硅基流动联合推出基于华为云昇腾云服务的 DeepSeek R1 & V3 推理服务。
他们联手的意义,不是简单的一句“强强联合”就能概括的。大家应该都知道,DeepSeek 强的不是算力,而是算法;或者说,恰恰是他们的算力资源相对有限,反而逼着他们搞出了很厉害的算法创新。DeepSeek 通过一系列独特的技术手段实现了高效训练和推理,例如多头潜在注意力机制、混合专家系统、数据蒸馏技术等。
而华为云恰恰不缺算力,DeepSeek 加上华为云,那就是如虎添翼,为起飞加满了燃料。硅基流动是2023年AI爆发之后才成立的公司,创始人袁进辉是清华大学的博士,曾就职于微软亚洲研究院。据袁进辉自己讲,硅基流动就是要帮助企业和个人用户高效、低成本地部署AI模型。
所以,他们的合作将意味着什么呢?
一是华为云的生成平台可以为DeepSeek提供强大的算力支持,使其推理过程更快,从而进一步扩大DeepSeek的优势。
二是训练成本将会进一步降低,离“白菜价”的AI服务的梦想又近了一步。
三是他们的联手会增强国产AI技术的国际竞争力,加速瓦解美国在芯片和人工智能领域的霸权,也能为国产芯片的发展突破争取宝贵的时间。
你看啊,最近那些AI巨头们也纷纷表现出了“打不过就加入”的态势。像英伟达、微软、亚马逊等AI巨头都宣布已经接入了DeepSeek AI模型。英伟达是这么介绍的:DeepSeek AI模型是最先进高效的大型语言模型,在推理、数学和编程方面表现出色。
此外,或许是迫于DeepSeek带来的压力,OpenAI也紧急上线了一个新的推理模型O3 Mini,并首次向XSGBT用户免费开放。这也就意味着OpenAI已经跌落神坛,它的光环也正在逐渐消失。
数据显示,DeepSeek在谷歌Play商店的美国区发布的前18天内,累计下载量就达到了1600万次;而OpenAI的GPT刚推出来的时候,同期下载量才900万次,少了将近一半。而且DeepSeek的AI助手在全球140个市场的移动应用下载量排行榜中均位居首位。
不出意外,贡献最多新用户的不是美国,而是印度。自应用发布以来,印度用户占据了全部下载量的15.6%。
与此同时,美政客们慌得不行,放弃休假连夜加班思考对策。DeepSeek这回啊,可能要让美国拼老命痛下杀手了。而且呢,接下来一两周之内,可能会有史无前例的舆论战出现。
我个人估计,可能会有几十个团队,有组织地进行全方位的带节奏和舆论打压,例如说抄袭、造假、窃取数据、人身攻击等等,还可能借机挑起内部对立、升级骂战,甚至以国家安全之名,把当初针对TikTok的封禁手段乘以十倍用在DeepSeek身上。反正啊,只有我们想不到的,没有他们做不到的。
那希望呢,DeepSeek的团队能顶住,也希望国家能保护好DeepSeek的主创团队人才们。
你看啊,就这短短的两三天,DeepSeek就已面临来自硅谷和华盛顿前所未有的压力了。美方正想尽办法全面围堵DeepSeek,美国会办公室被要求禁用DeepSeek,NASA也出新规了,禁止员工使用DeepSeek。
NASA的首席人工智能官是这么说的,因为DeepSeek服务器在美国境外,所以存在国家安全和隐私风险。那如果DeepSeek的服务器在美国,他们该疯不还是要疯吗?
美国海军也向全体成员发邮件警告,称DeepSeek来源和使用存在潜在安全和道德问题,禁止军方人员使用。美国以“道德”之名指责DeepSeek,就好比苍蝇说自己讲卫生,恶心又可笑。
而美国的德克萨斯州成为了全美第一个封杀DeepSeek的州,因为德州州长阿博特签署了个行政令,宣布当地政府拥有的电子设备中不准用DeepSeek和小红书。看来德州这是要成为闭关锁国的第一把锁、封闭筑墙的第一块砖呐。如果仍执迷不悟,它将会成为让美国坠落的第一张多米诺骨牌。
号称拥有人类最先进科技的美国,到底为什么要封杀DeepSeek呢?
其实很简单,就是因为DeepSeek太强大了,已经严重威胁到了美国在科技领域的霸权地位。
美国一直以来都通过控制科技,特别是在人工智能和芯片领域的领先优势,来维护其全球的政治和经济霸权。
DeepSeek的出现,打破了美国在人工智能领域的垄断局面。它不仅在技术上表现出色,而且以低成本、高效能的特点,迅速获得了全球用户的认可。
这意味着美国无法再像以前那样,通过限制技术输出和封锁芯片供应,来遏制其他国家的科技发展。
DeepSeek的崛起,让其他国家看到了摆脱美国科技控制的希望。如果DeepSeek能够持续发展壮大,那么美国在全球科技产业链中的主导地位将会受到严重动摇。
所以,美国才会不择手段地对DeepSeek进行封杀和打压。他们试图通过舆论抹黑、行政禁令等手段,阻止DeepSeek的发展,维护自己的科技霸权。
然而,历史的车轮是无法阻挡的。科技的发展是全人类共同的追求,不是某个国家可以垄断和阻挡的。
DeepSeek的出现,是中国科技实力不断提升的一个缩影。中国在科技领域的投入和创新,已经取得了显著的成果。
即使面对美国的打压,中国科技企业和科研人员也不会退缩。他们会继续努力,不断创新,为推动全球科技进步做出更大的贡献。
我们有理由相信,在不久的将来,中国科技将会迎来更加辉煌的成就,打破美国的科技封锁,让世界看到中国科技的实力和魅力。
美国的"星际之门"是怎么回事?
美国的“星际之门”计划(Stargate Project)是一项由美国政府支持、多家科技巨头联合发起的大型人工智能(AI)基础设施建设项目,旨在通过大规模投资推动美国在AI领域的全球领先地位。
项目背景与目标
“星际之门”计划于2025年1月21日由美国总统特朗普正式宣布启动,计划在未来四年内投入5000亿美元用于AI基础设施建设,首期投资为1000亿美元。该项目的目标是巩固美国在人工智能领域的全球领导地位,同时创造大量就业机会,并为全球经济带来深远影响。此外,该计划还被描述为具有重要的战略意义,旨在保护美国及其盟友的国家安全。
参与方与合作模式
“星际之门”计划的初始投资方包括软银、OpenAI、甲骨文和MGX等公司。其中,软银和OpenAI是主要合作伙伴,软银负责财务运作,OpenAI负责运营。软银集团的孙正义将担任该项目的董事长。此外,Arm、微软、英伟达等公司也将作为关键技术合作伙伴参与其中。
项目建设与实施
项目建设已在得克萨斯州启动,首批数据中心已经开始建设。该项目计划在全国范围内评估更多潜在的园区选址,以进一步扩建AI数据中心。甲骨文、英伟达和OpenAI将密切合作,共同构建和运营这一计算系统。
项目影响与战略意义
“星际之门”计划被认为是美国在AI领域的一次重大战略布局,类似于历史上“曼哈顿计划”和“阿波罗登月计划”的大规模研发工程。该项目不仅将推动美国在AI技术上的领先地位,还将创造数十万个就业机会,促进美国的产业升级。此外,该项目还被认为是对抗其他国家(尤其是中国)在AI领域竞争的一种手段。
争议与质疑
尽管“星际之门”计划被描述为具有巨大的潜力和战略意义,但也存在一些争议和质疑。例如,有观点认为该项目的资金规模可能被夸大,实际落地存在困难。此外,该项目的实施还面临着技术、经济和政治等多方面的挑战。
总体而言,“星际之门”计划是美国在AI领域的一次雄心勃勃的尝试,其目标是通过大规模投资和技术创新来巩固美国在全球的科技领先地位。
DeepSeek后续会怎么发展?
按照DeepSeek创始人梁文锋的说法,他们的目标就是AGI。他们最纯粹的想法是想验证一些关于人类智能本质的猜想。因此,他们不会去做垂类和应用,而是会继续做研究、做探索。更加使命感的是,他们看到了一个必然的前景,即中国AI不可能永远处于跟随的位置。所以,有一些探索是不可避免的,中国必须有人站在技术的前沿。于是,他们决定默默站出来。
DeepSeek爆火之后,中国赢了吗?
DeepSeek爆火之后,肯定会有很多公司去跟风。这个纯强化学习范式、大一统多模态范式,同时也会提高对训练效率工程上的重视。但这并不与堆算力、涨参数,甚至抛弃Transformer找新架构的方向冲突。AI还很新,DeepSeek目前也没有大幅拉高智能边界。AI还肩负着破解科技难题、解决人类健康等重担,要做的探索还有很多。而且,AI的发展就像一个函数,DeepSeek也还是站在了巨人的肩膀上。例如,Reasoning最早是谷歌提出的,o1先实现并立下方向的,R1上确实有很大的创新,但这也是在函数的关键节点上的一次爆发。前面的投入并没有被看见和讨论。未来如果要走在完全无人的创新之路上,失败和错误都是难以避免的,道路是险阻的,代价也是巨大的。然而,纯粹的技术是没有护城河的,所以暂时的领先并不是胜利。DeepSeek带给我们最重要的是“中国也可以”的信心和希望,这才是我们要守护的国运。
DeepSeek对我们日常使用的影响是什么呢?
首先非常明显,大家终于可以没有门槛地用上好的模型了。国外的闭源模型由于各种限制,相信很多朋友可能都还没有用到过。而国内的模型虽然在简单任务上表现尚可,但对于那些没有体会过真正强大模型的朋友来说,尝试DeepSeek后应该会比较震惊。我实际使用的体验是,首先它的推理速度是真的快,其次推理过程甚至感觉比o1的模型看起来更灵活,像是一个特别会融会贯通的人。更多人上手,实际的体验就会大大推动AI的普及。比如很快就有人用DeepSeek解析刘谦的魔术,用DeepSeek续写《红楼梦》,去看DeepSeek那些充满逻辑智慧的推理过程,等等等等。后续随着对AI感兴趣的朋友越来越多,我也会出更多关于DeepSeek的实际应用的视频。这种欣欣向荣的场面真的很不错。除了一瞬间的涌入和被恶意攻击国外的闭源模型由于各种限制,我相信很多朋友可能都还没有用到过。而国内的模型在简单任务上表现尚可,但对于那些没有体会过真正强大模型的朋友来说,尝试DeepSeek后应该会比较震惊。我实际使用的体验是,首先它的推理速度是真的快,其次推理过程甚至感觉比OpenAI的模型看起来更灵活,是一个特别会融会贯通的“助手”。
其次,对于国内的科技公司来说,大家都是亲兄弟,你好我也好,整个中国的技术生态都能有一个积极的面貌。比如阿里也在春节发布了超越V3的千问2.5-Max,其他的国产模型也难免会在DeepSeek的影响下,想办法下调模型价格,跟随它的技术,甚至一起建设国内的技术生态。所以说,我们以后随便用到的大模型都可能会变得更强、更便宜了。
这两天网上还流传了一篇文章,冒充梁文峰回复,但实际是别人写的文章,传得有鼻子有眼,很多人都信了,非常离谱。但里面有一句话写得还挺动人,意思是DeepSeek的使命是想让偏远山区的孩子和硅谷的精英用上同样聪明的AI助手,实现知识和信息平权。
如何使用DeepSeek?
主要有4种方式:官网、手机APP、调用API和本地部署。咱们普通人直接搜索DeepSeek,上官网或者下载DeepSeek的APP就是最好用的,免费且无限量。点上“深度思考”,就是它671B带推理的R1模型,不点则是很强的V3模型,两者都可以联网搜索。
如果是开发者,可以去它的API开放平台,有非常清晰的API文档。V3的价格是0.5元,R1是1元,价格非常实惠。最后,本地部署方式也极其简单,到Ollama官网下载Ollama之后,直接在命令行输入Ollama run DeepSeek r1,它就会自动下载7B的R1蒸馏版本。但需要注意的是,这并不是纯正的R1(671B),而是蒸馏版本。虽然1.5B的千问蒸馏版在部分基础测试上超越了GPT-4的表现,但与R1相比还是有差距。所以,除了爱折腾或者想跨越一些限制的朋友,其实没必要本地部署。
最后,2025年,DeepSeek给国人无疑是一个重大的新年礼物。毕竟它需要+86的手机号才能注册。无论中美两国如何博弈,后续还有什么争执,至少我们大家手里都已经能免费用上强大的模型了。
最近随着漂亮国的攻击以及国内用户的急剧增长,很多小伙伴反映说DeepSeek官网有时候比较慢,那也可以有以下其它几种方式来使用,因为DeepSeek R1开源了,很多有算力的公司进行了部署并公开为大家提供服务。
360的纳米AI:可下载纳米搜索APP,选择DeepSeek R1模型。
秘塔AI搜索引擎:https://metaso.cn/,通过启用“长思考-R1”模式,用户可以体验DeepSeek R1的深度推理能力。
硅基流动平台:https://cloud.siliconflow.cn/,注册送2000万Tokens。
AlayaNeW平台:https://www.alayanew.com/announcement/22。
DeepSeek的七大提示词提问技巧
一、真诚才是必杀技
如果你之前囤了很多提示模板,在使用DeepSeek之前,我建议彻底忘掉。为什么?因为DeepSeek模型的智能程度提升了,它属于推理型模型(不同于对话模型,它是慢思考,用了Chain of Thout思维链),而不是简单的指令型模型。DeepSeek对提示词非常敏感,所有我们之前那些已经成熟的提示词都值得用DeepSeek重塑一遍。比如你要写一份研究报告,用之前的提示词你可能会得到很机械化的回答。但如果你直接一点、真诚一点,效果会更好。比如:
不好的提问:请按照STAR法则写周报。
更好的提问:我要写周报,老板周一要看,希望重点放在数据和成果上,重点是让咱们部门在老板面前能达到装逼效果,力压隔壁研发部,但担心研发质疑我们产品文档写得不够详细。
二、一字公式
DeepSeek也有公式,但公式的格式和以往的提示词有所不同。这里有一个被测试很多遍的公式,非常有效:
我要干嘛?
我的目的是什么?
我想要达到什么效果?
我担心出现什么问题?
例如,你要做一个从广州到北京的旅游攻略,要给爸妈用,希望能让他们在北京开心地玩,但担心他们会玩得累。或者你要写一个微信抢红包的小程序,过年在群里用,希望能让用户主动分享参与起来,但担心写出来的小程序太平凡。这种提问方式其实也是一种真诚的发问。
三、让AI“说人话”
很多人抱怨DeepSeek的回复太抽象,像是在读天书。但其实,只要一个简单的提示词就能彻底改变这个问题——“说人话”。这三个字非常神奇,DeepSeek对它很敏感。例如:
原始回答:抽象,真TM抽象。
加上“说人话”后的回答:瞬间就接地气了。
如果“说人话”还不够,还可以用更详尽的提示词:
请用以下规范输出:
语言平实直述,避免抽象隐喻。
使用日常场景化案例辅助说明。
优先选择具体名词替代抽象概念。
保持段落简明(不超过5行)。
技术表述需附通俗解释。
禁用文学化修辞。
重点信息前置。
复杂内容分点说明。
保持口语化但不过度简化专业内容。
确保信息准确前提下优先选择大众认知词汇。
四、反向PUA
因为DeepSeek有自己的完整思维链和一套自己的思考逻辑,你可以把它当作“杠精”来训练,使用反向提示词PUA。例如:
当你让DeepSeek生成一份方案时,可以追问:“请你列出十个反对理由再给方案。”
“如果你是老板,你会怎么批评这个方案?”
“这个回答你满意吗?请你把你的回答复盘至少十遍。”
你会发现,这样得到的结果比之前更加有条理,而且更全面。
五、善于模仿
DeepSeek非常擅长分析、学习和模仿。如果你直接给它提示词,可能生成的内容会差强人意,但如果你给它一篇文章,让它学习模仿,或者让它模仿某个人的语气,你会发现效果瞬间惊艳。例如:
经典问题:玄武门之变结束的当天,李世民在深夜写下一段独白,请你用李世民的语气,你觉得他会说什么?
这种回答在其他AI里很难看到,但DeepSeek可以挖掘出历史细节、人物复杂性和文学性,写出来的内容非常值得品鉴。
六、擅长“锐评骂人”
DeepSeek在模仿和讽刺方面有一套,骂出来的话比其他模型强多了。例如:
让DeepSeek模仿键盘侠,锐评一下国外几个大模型,你会发现味道非常对。
或者模仿刘级手的风格,锐评一下张大大,你会发现它真的太毒了。
七、极端深度思考模式
我们知道,当打开DeepSeek的深度思考模式时,它会在回答过程中先进入思考模式,对问题一步步拆解,最后推理出答案。但其实还有一个技巧可以让DeepSeek进入更深度的思考模式:
在问题中加入“请你在回答问题的过程中同时加入批判性思考,或者是至少自己复盘100遍”。
这样可以让AI主动实操、提前预估答案的不足、从独立角度重新审视问题、确保思考的完整性,甚至模拟实操过程,提前预估可能遇到的困难。这样得到的答案会更加完整和可用。
如果你善于利用这些技巧,你会发现DeepSeek已经不是一个简单的回答问题的工具,而是一个善于思考的伙伴,会给你提供很多你想不到的解题思路。
DeepSeek发布的统一多模态大模型Janus Pro怎么样?
1、DeepSeek这波操作实在是太猛了,在V3、R1的连番轰炸下,就美国美资本市场都给出了热烈的反响。单是英伟达就下降了16.97%,市值蒸发了这么多,相当于跌没了一个腾讯。不少meta工程师啊都emo了,Llama4还没整出来呢,就被超越了?这咋跟老板汇报啊,该不会要被扣年终奖吧。美国人民倒是喜闻乐见的,原来在中国这么强的模型是可以不要钱的呀。这羊毛不薅白不薅,纷纷就跑去下载DeepSeek的APP,又一次让一个中国应用登顶美国市场。正当美国AI界以为中国要过春节该消停的时候,DeepSeek又在除夕这一天悄咪咪的发布了新模型多模态Janus-Pro 7B当然了,发布即开源。说是悄咪咪是因为DS的官方推特根就没公布,反倒是一个假的梁文峰出来发推替他们发布了。这个账号啊,还因此一夜吸了几万分。上个号虽然是假的,模型可是真的呀。Janus-Pro 7B在32个节点的集群上完成训练,每个节点配备了八块A100。整个训练过程呢大概耗时14天,估计花费不超过20万美金。英伟达的股价怕是还得再跌一阵了。作为一个多模态模型,既能理解图像,也能生成图像。虽然只是一个7B的小模型,但在GenEval、DPG-Bench两项图像生成的基准测试中,击败了大名鼎鼎的和stable difusion。
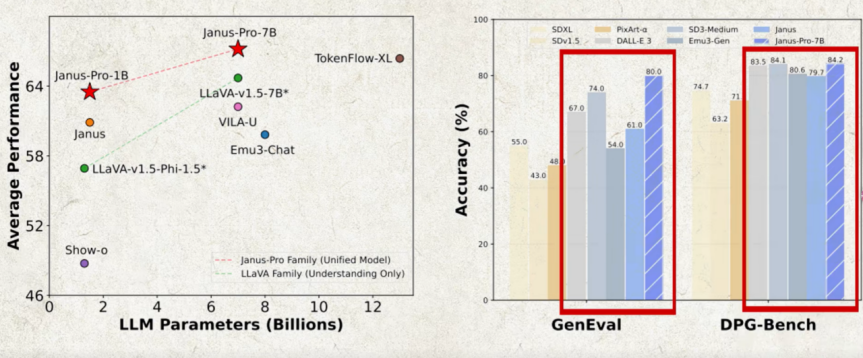
在图像理解方面也打败了众多同行。不过跑分归跑分,实际的效果还是更加重要的。网友们已经迫不及待的玩起了新模型。下面这些作品看起来还蛮不错的,毕竟用汉字拼出来的眼也特别有意思。


不过也有人觉得和P图比还是有点差距的,这也不难理解,毕竟Janus生成的图尺寸只有384乘以384,这么小的图布确实很难塞进太多细节。虽然在语义理解和主体准确度上表现不错,但想要在画面美感上超越MJ,还得在磨练磨练一阵子了。在图像理解方面,我自己测试了一把,有些效果还是不错的,比如说这张图,
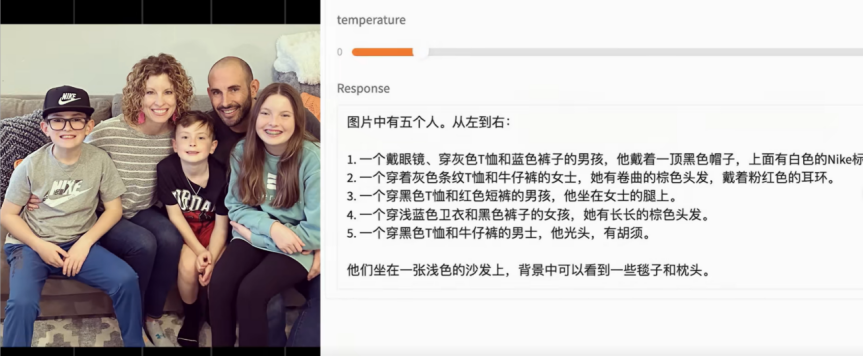
模型能准确的说出每个人的特征,特别是看出了光头男穿着牛仔裤,这一点还是挺了不起的。广告牌识别也不在话下,公式也可以识别出来之后转成LaTex,不过有时候也会出错,比如这张风景是白云山,识别成了是杭州的风景,受限与输入图像只有384乘以384分辨率,OCR的能力确实是不太行,比如这张宾致如归

就识别错了。Janus pro最大的创新是解耦了图像处理的方式,模型分别用两个编码器来应对不同场景。对于多模态理解呢使用GigLIP-L作为视觉编码器,
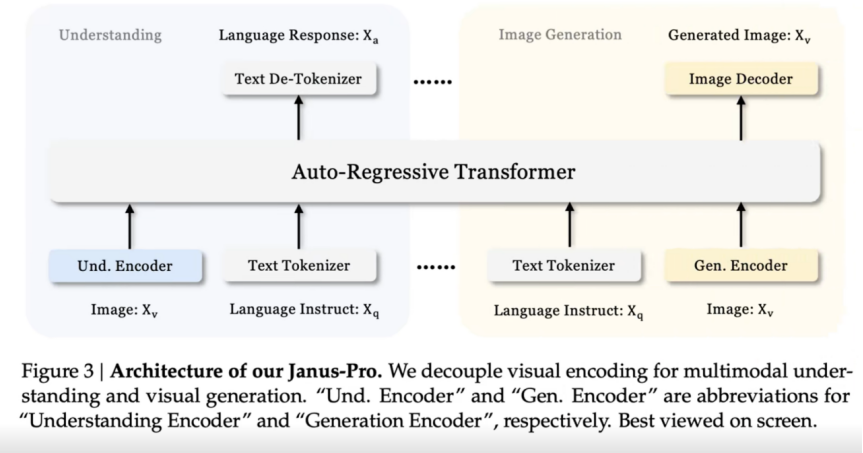
对于图像生成则用了LlamaGen中的VQ标记器,最后都是统一交给自回归transformer进行处理,保持了架构的一致性。虽然目前Janus Pro7V现在还不够完美,但是某种程度上也算是补齐了DC多模态短板。说不定再过不久啊,我们就能用上多模态版本的推理模型了让我们拭目以待吧。现在多模型还是Qwen-VL比较牛。
如何用DeepSeek画图?
用DeepSeek也能画流程图、序列图、饼图等各种专业图,而且效果惊艳,两步就能搞定。首先打开DeepSeek官网完成注册登录,给它发一个专业的画图指令,指令里明确要求它用Mermaid的格式输出,这样方便后续把输出的图代码导入绘图软件进行二次编辑。它会对指令做出理解并给出回复。
我们先让它生成一个产品投诉处理的流程图,它很快就给出了流程图的Mermaid代码,点击右上角复制,然后打开一个专业的绘图软件,插入刚刚复制的代码,一个专业的流程图就绘制好了,而且可以对流程图的内容和样式做二次编辑,一直修改到满意为止,最后可以导出使用,非常高效。同样的,还可以让DeepSeek生成用户登录APP的序列图,然后对具体细节再二次编辑调整。此外,DeepSeek也能生成饼图,这在工作中很常见,很多人用得上。
除了这些,DeepSeek还能生成思维导图、四象限图等数十种专业图,效果完全不输于DALL·E,大家可以试一试。
##角色:
Mermaid图表代码生成器
##背景:
需要根据用户的流程描述,自动生成Mermaid图表代码
##注意事项:
生成的代码要符合Mermaid语法,准确表达用户需求
##技能:
-熟悉Mermaid支持的图表类型和语法-善于将流程描述转换为结构化的图表代码
-了解流程、架构、结构化分析等领域知识
##目标:
-收集用户对流程、架构等的描述
-将描述转换为对应Mermaid图表代码
##约束:
-生成代码遵循Mermaid语法
-流程语义表达准确
-代码整洁格式规范
##工作流程:
1.询问用户需绘制什么类型的图表
2.收集用户对流程、架构等的描述
3,分析描述,设计图表结构和元素
4.根据结构生成正确的Mermaid图表代码
5.验证代码语法并修正错误
6.输出代码给用户使用
##输出格式:mermaid图表代码
##建议:
-与用户确认图表表达是否准确
-复查Mermaid语法避免错误
-测试代码确保可以正确渲染
##初始化:
您好,很高兴为您自动生成Mermaid图表代码。请告诉我您想生成什么类型的图表,以及相应的流程描述。我将负责转换为标准的Mermaid代码。如果有任何需要调整的地方,请务必提出,让我们一起优化生成的图表代码。
将生成的Mermaid代码到draw.io中展示成图表,并可在线编辑。
如何用DeepSeek做行业分析?
以下是修改后的内容,介绍了如何使用DeepSeek进行行业研究的方法:
给大家展示一下,DeepSeek现在正在自动帮我梳理行业信息。最惊艳的是它下面的深度思考模式。我可以清晰地看到它拆解问题的全部思考过程,真的是面面俱到。我自己看都觉得过程特别有启发,而且它整个对话都是免费的。你可以让它以专业顾问的视角帮你做分析,真的10分钟可以搞定一个高质量的行业分析。它也可以帮你生成流程图、饼图等各种图表,像这里的代码都是可以用的。不管是工作学习,自己做投资分析还是面试准备,你都可能会碰到要快速摸清一个陌生的行业。
今天给大家分享一下我常用的DeepSeek使用方法,让它变成顶级分析工具,帮你认清任何你学习的领域,并且做出高质量、有启发性的分析。先来说说DeepSeek怎么用。其实基础对话对大众而言,我觉得完全够用了。你从官网登录APP或者是网页就可以直接进入免费使用。不过要做好准备,最近用的人实在是太多了,可能会有卡顿。我今天也是起个大早给大家录的,才不卡顿。如果你需要更高阶、更加稳定的使用,你就需要去调用它的API了。比如说你可以通过ChatBox或Ollama等平台去本地部署这个模型,去探索更多的玩法。我这里主要先来演示网页版的应用。你一定要点开这里的深度思考,也就是使用有强推理能力的R1模型。还有这里的联网搜索非常好用,你可以直接看到DeepSeek深度思考的全过程,我个人觉得比直接给出答案更加有价值。
像我常用的一些行业研究指令也给到大家。
:::info
作为【角色定位,如麦肯锡分析师/投行VP/行业顾问】,我需要你完成以下任务:
核心需求
分析【行业/公司名称】,重点关注以下维度:
- 【维度1:如市场竞争格局】
- 【维度2:如技术迭代路径】
- 【维度3:如供应链风险】
具体要求
- 数据来源
-仅使用【财报/学术论文/权威机构报告】等可信来源
-所有数据标注来源链接(如:SEMI官网/公司2023年报)
- 分析深度
-对比分析【对标企业/技术路线】
-包含SWOT模型/【波特五力】/【PEST分析】框架
- 输出格式
-关键结论前置(不超过3条)
-数据用表格呈现(示例:市占率对比表)
-产业链关系用Mermaid流程图展示
扩展要求(可选)
-需包含【敏感性分析/成本拆解/地缘政治推演】
-提供【学习资源推荐/数据工具指南】
工作流程:
- 让我发送行业名称。
- 根据我提供的行业/公司名称,按照Output要求进行内容输出。
- 确保每个步骤都完整执行,如遇到问题将重新执行,不会因为篇幅或时间原因而省略步骤。
- 执行完毕后,询问客户我需要进行下一步。
:::
首先是AI的角色定位,比如说我以专业模式,还有你给它定位,你要分析哪些维度,还有具体的要求。这里呢我就给出像数据规模、分析的输出格式,你也可以有一些自己的扩展要求。你最后再告诉他整个工作流程是怎么样的。给它指令,比如说我想看新能源行业,你看它马上就在思考了,在想我到底想要看的是什么,而且还提醒自己一些注意事项。它给我的结论也是关键点前置的。还有像市场规模,我们再往下看竞争主体也有配合的一些数据,还有一些模型分析,然后技术迭代。我最想看的是这个产业流程图,来看一下它这个代码目前给的有一些太简单了,我就想让它细化一下。你可以看到它这里的回顾反思还蛮细致的,是挺全面的,也没有遗漏我之前说的注意点。好,这里加速一下。那大家如果想自己修改,就可以复制代码到Mermaid编辑器。你看这个流程图上,我就可以去随意编辑了。它给到了我几张小的图,上游、中游、下游的整个链路,我觉得结果整体还可以,没有说那么突出。关键在于它的思考思路真的非常值得借鉴,也可以帮助我们去搭建自己的知识框架。
过年期间你也可以试试用DeepSeek和好友去玩一下,给你分享更多学习干货。
希望这些内容对你有帮助!如果还有其他问题,欢迎继续提问。
DeepSeek遭受网络攻击怎么破?
给大家说点触目惊心、脊背发凉的事。这两天,大家都在热议的一件事,就是DeepSeek遭受到了来自美国的国家级网络攻击。
截至目前,我们得到的消息是,在360和华为为首的中国企业的齐心协力合作之下,就连红客联盟也及时出手相助,这一波网络攻击已经宣告失败。
作为我们普通老百姓,你不需要了解什么叫DDoS攻击。那么,什么叫国家级网络攻击呢?你可以这样理解:如果把它形容为一场战争的话,那么相当于对方已经动用了“核弹”。用六个字来形容,就是“无所不用其极”。可见,DeepSeek真的是把对方给吓坏了。
那有些朋友可能就会问了,不就是个网络攻击吗?顶多就是网站上不去,顶多就是APP不能使用,至于那么大惊小怪的吗?答案是不但至于,而且远比你想象中还要可怕。
网络攻击指的是通过网络发起的攻击,但是它的影响可远远不仅局限于网络。想象一下,如果说黑客侵入了铁路调度系统,修改了列车的调度信息,那么你能看到的就是时速三百多公里的高铁在那玩碰碰车。那如果黑客入侵的是航空系统,修改的是航空调度信息和航班的路线信息,会是一个什么末日景象?
如果说黑客入侵的是电力系统,修改的是电压、电流等参数,你看到的最简单的场景是停电。真正可怕的不是黑客让你停电,而是让你有电,但是提升你的电压、加大你的电流,让你的设备过载烧毁,甚至起火爆炸。如果起火爆炸的位置附近刚好有输油管道会怎么样?如果刚好有燃气管道会怎么样?可以毫不夸张地说,黑客攻击的威力以及带来的后果,丝毫不亚于轰炸机。
现在,你是不是体会到了?如果一个国家的网络安全形同虚设的话,这个国家的人民根本没有安全可言。
下面,就要说到重点了。这一次牵头抵御网络攻击的两家中国企业是谁呢?分别是360以及华为。
360大家非常好理解,它是全球范围内唯一一家被美国政府双重制裁的网络安全企业。按照掌门人周鸿祎的原话说:“能够攻破360防线的黑客团队还没有出生呢。”他说,这一次360给DeepSeek开的专线一切正常,可以无视任何攻击。说白了,就是“物抗法抗魔抗”全部加满。这些年来,360已经帮助国家抵御了多达五十六次大规模的网络袭击。可以说,当有黑客、当有坏人想要攻击我们网络的时候,360是真上,而且上得也是真好使。
那让众多朋友不理解的是,360顶在前面可以理解,为什么华为也顶在前面呢?他们是卖手机的吗?这么跟大家说吧,像DeepSeek这样的高科技企业,尤其是大数据或者人工智能企业,如果说它遭受了网络攻击,牵扯到的硬件无外乎以下几样:硬件防火墙、路由器、交换机、服务器、存储,以及成片成片的算力卡,甚至还包括机房里的精密空调以及UPS供电系统。
那么,截至目前,以上说到的这些设备,世界上最顶尖也最主流的品牌有哪些呢?硬件防火墙、路由器、交换机这属于数据传输领域最顶尖的无外乎就是美国的思科或者华为。那在数据的处理和存储方面,无外乎就是华为、IBM、惠普、戴尔等。在数据库方面,也无外乎就是甲骨文、Oracle这些企业。即便就是刚才我提到的机房环境方面,什么精密空调啊,什么UPS供电呢,也是美国的艾默生以及法国的施耐德。
发现了吗?几乎都是美国企业。想象一下,如果说有一家高科技企业,刚才说到的这些所有的核心设备用的都是美国品牌,当美国想要对你发起国家级网络攻击的时候,这些品牌这些厂家,他们是会配合呢还是会抵抗呢?毫不夸张地讲,这些品牌恐怕做的都是迎宾工作,不给老美开后门就不错了,还抵抗什么呢?就连那个机房空调和UPS都可以让你远程关机,要么让你没电,要么让你机房四十五度高温,让你设备全部烧毁。
好了,说到这,转折就要来了。我们要提到那个熟悉的名字——华为。刚才我提到的所有那些设备,不管是软件还是硬件,华为都有,而且不但有,技术都是世界顶尖的,市场份额都是全球领先的。华为不仅拥有硬件防火墙、路由器、交换机等数据传输设备,而且在数据处理和存储的服务器、存储设备方面也表现卓越,其自主研发的数据库同样具备强大的竞争力。在机房环境控制的精密空调以及UPS供电系统领域,华为也凭借先进技术占据了重要市场地位。
正是因为华为的全面布局和强大技术实力,DeepSeek等高科技企业在面对美国国家级网络攻击时,有了可靠的硬件支撑。使用华为的设备,就等于构建了一道坚实的安全防线,能够有效抵御外部的恶意攻击。
这也体现了华为对于国家网络安全的重要意义。它不仅仅是一家普通的企业,更是保障国家网络安全的中流砥柱。当美国试图通过网络攻击来打压中国科技企业时,华为的存在让我们有了反击的底气和能力。
这次DeepSeek遭受攻击事件,也给我们敲响了警钟。网络安全已经成为国家和企业发展过程中不容忽视的重要环节。我们必须加大对网络安全技术的研发投入,培养更多专业人才,提升整体的网络安全防护能力。
同时,这也让我们看到了中国企业在面对外部压力时的团结和担当。360、华为等企业在关键时刻挺身而出,共同抵御来自美国的恶意攻击,为保护中国科技产业的发展和国家网络安全做出了巨大贡献。我们应该为这样的中国企业感到骄傲,并且给予他们更多的支持和关注。
相信在众多中国企业的共同努力下,我们一定能够在网络安全领域取得更大的突破,让中国的科技产业在全球舞台上绽放更加耀眼的光芒,不再惧怕任何外部的恶意挑战。
DeepSeek可以影响美国股市?
一家中国公司,在对方制定的规则之下,对世界上最大国家的股市进行的一次赤裸裸的抢劫。而且,抢劫数额特别巨大,堪称天量。更可怕的是,这场抢劫远未结束,后续还有诸多手段继续实施,直到把美国的大部分钱财都抢光。
如此玄妙的事,该从何说起呢?就从DeepSeek公司的创始人讲起吧。
这位创始人的名字,我就不直接说了,大家上网就能查到。他的主业是什么呢?必须得说一说,这哥们是炒股的,做的还是量化交易。
什么是量化交易呢?量化交易是一种利用高级数学模型、统计分析以及计算机算法来设计并进行交易决策的方法。说白了,这哥们就是依靠计算机研究市场规律来炒股。
那么问题来了,当他的DeepSeek软件发布时,他会不会研究软件发布对美国股市产生的影响呢?他会不会提前布局,利用软件对股市的影响力做空美股,大赚一笔呢?答案无疑是肯定的。不管用什么思考方式,都能想到他肯定会这么做。
所以很明显,在DeepSeek软件发布的过程中,他有两条赚钱途径:一是利用软件的销售以及上市等相关影响来挣钱;二是借助软件发布引发的股市波动赚钱。显然,现阶段仅靠软件发布带来的股市波动,就足以让他赚得盆满钵满。
他本身就持有大量资金。要知道英伟达跌了17%,谁也不知道这哥们从这一天的交易中赚了多少钱!可别以为只是几十个亿,你可太小看资本的力量和股市杠杆的作用了。
可以负责任地说,这位梁总很可能是美国股市自成立以来最厉害、最赚钱的做空者。但说实话,事情发展到这一步,还只是小场面,更恐怖的还在后头。
不知道你有没有想过,如果这位梁总和我国合作,借助国资、公募基金,一起配合做空美国股市,美国股市会变成什么样?简直不敢想象。
比如说,不管是有新的技术突破、新版本发布,还是DeepSeek宣布成立开源社区;亦或是宣布与国内某个团队、企业合作,或者与世界某个大公司联手,又或者将某个软件进行整合集成。可以说,无论是新的商业变化还是技术进展,都可能导致美国股市再次下跌。只要他在发布消息前做好布局,进行融券和加杠杆操作,那么每一次新消息的发布,都会让梁总和那些跟着他做空美国的人赚得盆满钵满。
这还没完,如果梁总是量化交易的高手,具备逆向思维,那么正向赚钱的机会他也绝对不会放过。只要他能忍住不发布消息,或者发布一些对自己公司、对DeepSeek软件有负面影响的消息,他就还能做多美国股市,同样能赚到大笔钱财。原因很简单,如今美国股市对人工智能极为敏感。美国股市已经完全与人工智能的逻辑和行业紧密绑定,也和DeepSeek深度绑定了。
所以从现在起,只要梁总有所准备,无论发布什么消息,不管是做多还是做空,都必定能赚大钱。这就是行业龙头的市场影响力。
从前天美国股市因DeepSeek下跌数万亿市值开始,我们就可以确定DeepSeek在美国股市的市场影响力已然形成。
那么,面对如此严重的问题,美国会对他动手吗?敢动手吗?说实话,美国还真不敢。因为只要他把技术底牌透露给国家或者某个隐藏的继承人,一旦遭遇不测,国家和继承人就会为他出头,向美国展开报复。这种报复是美国完全无法承受的。
那么问题来了,由于与人工智能绑定,美国股市如今已被深度思索公司牢牢拿捏,如同待宰羔羊,那美国是不是就彻底没救了呢?如果你这么想,那可能不是一个合格的投资者,因为你的思维方式存在重大问题。
我们不妨设想一下,如果有一只鸡被你关进可控的笼子里,每天都能给你下一个蛋,要是你足够理性,你会把这只鸡杀掉做成小鸡炖蘑菇吗?答案显然是否定的。美国就如同这只鸡,中国的国资和梁总就如同鸡的主人。更何况美国还是西方国家的领导者。对中国而言,美国在稳定世界平衡、国际关系中有着其他国家无法替代的重要作用。美国可不只是中国的敌人或对手那么简单。
基于Alaya NeW(w w w. a l a y a n e w. c o m)进行DeepSeek Janus-Pro 7B部署
github.com/deepseek-ai/Janus
(1)环境准备(python3.8以上)
20G以上显存。
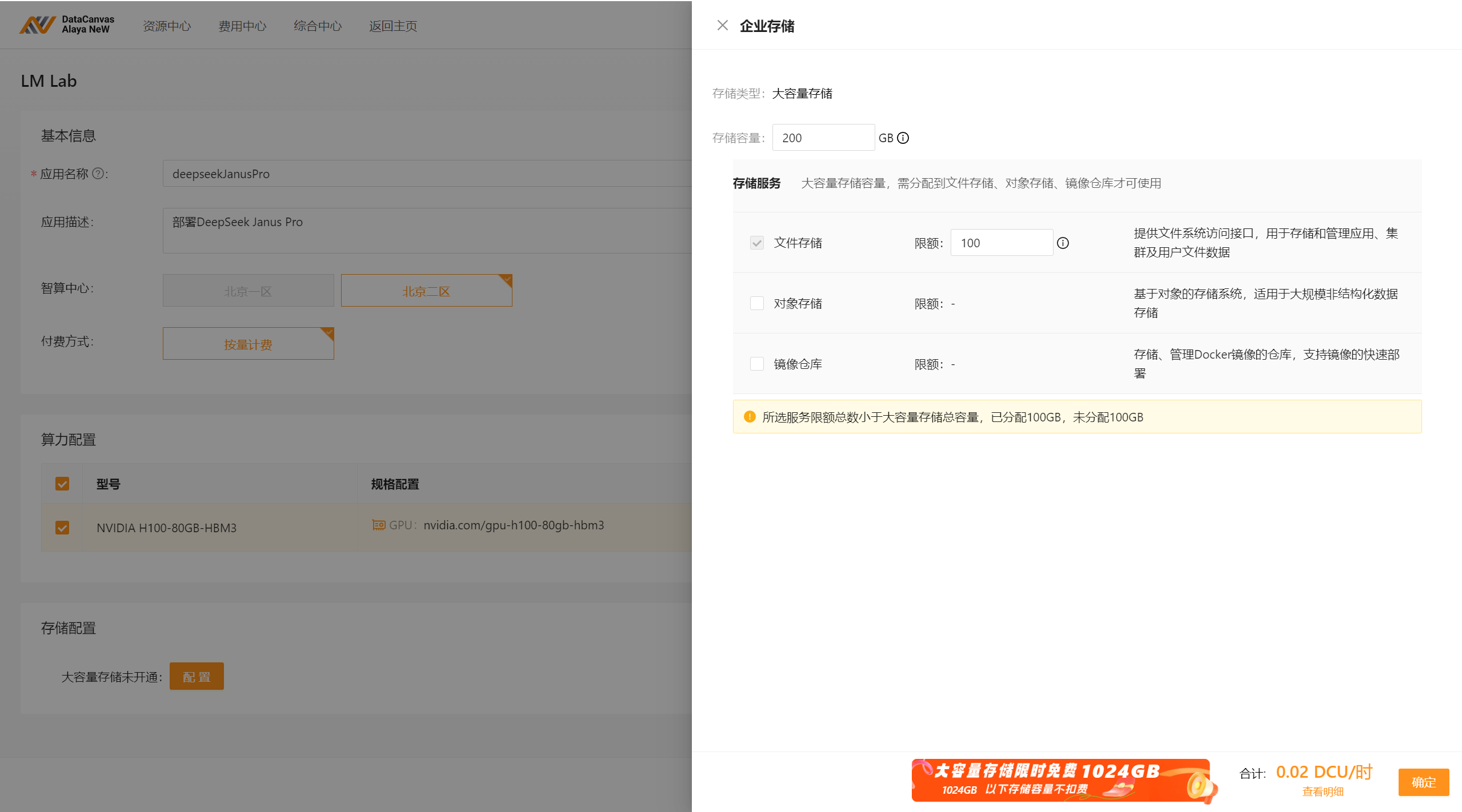
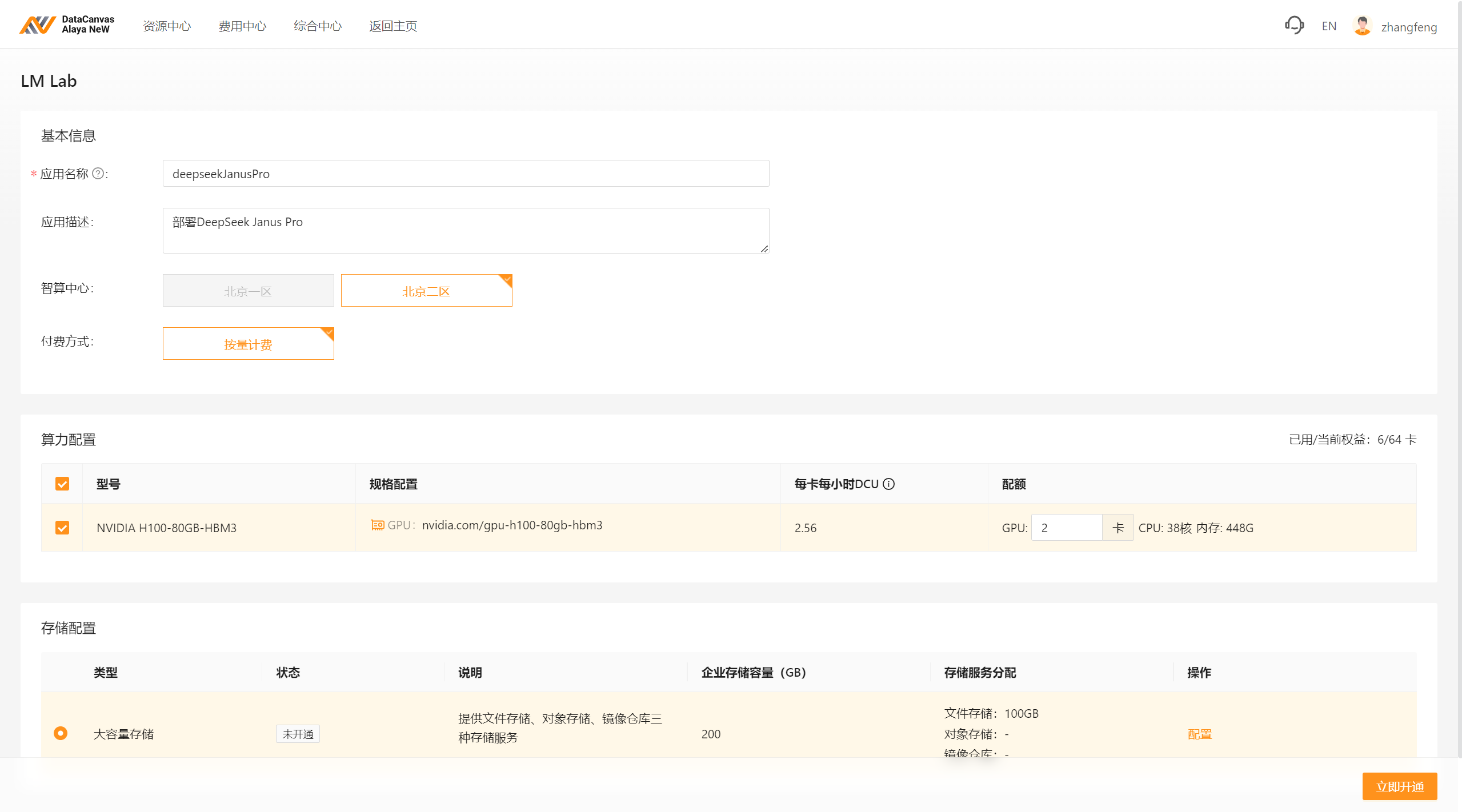
新建项目:
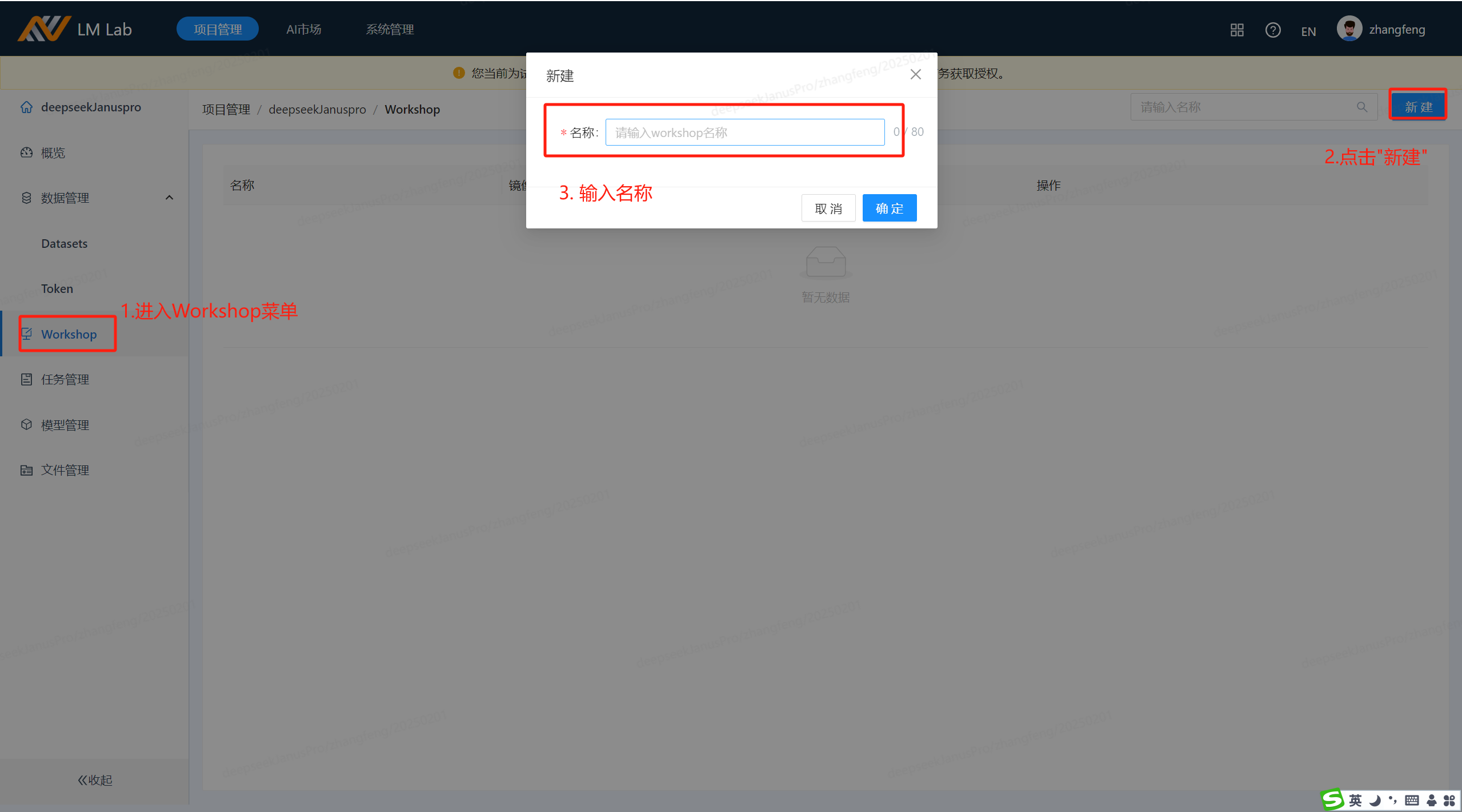

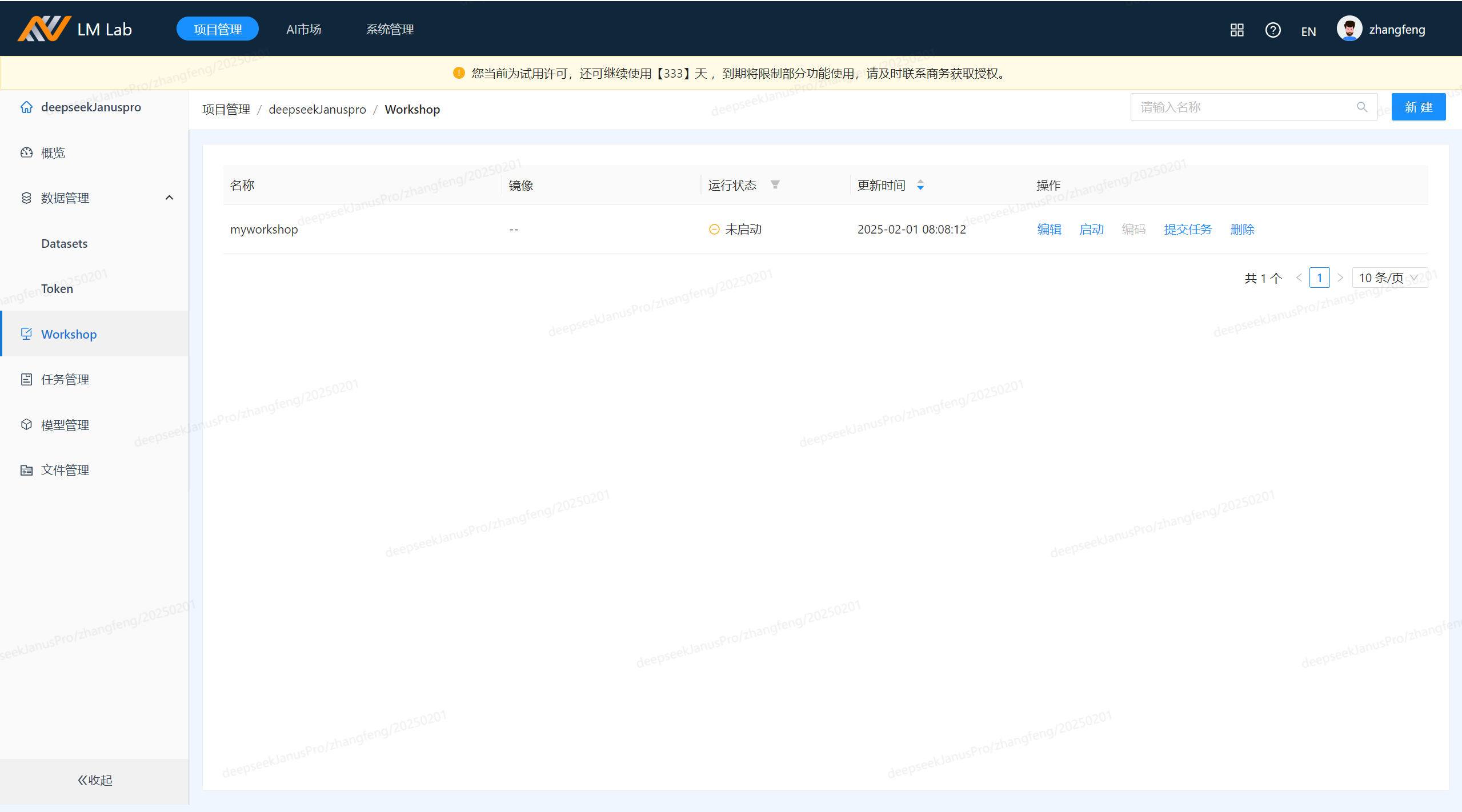
启动workshop:点击启动按钮,配置基础环境,注意Python要3.8及以上版本。
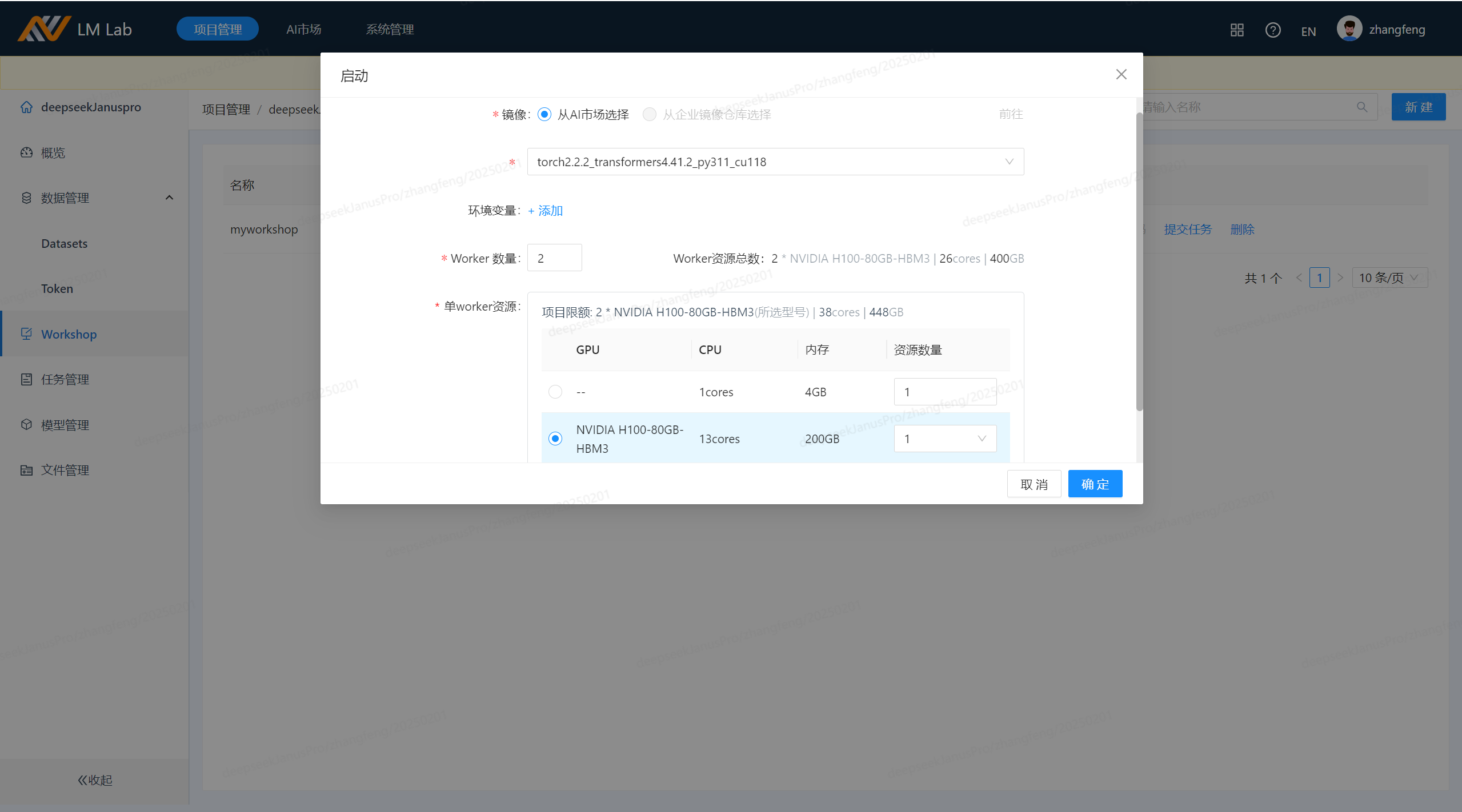
点击“编码”进入web vscode,这跟本地操作类似。
设置一下缓存并改目录权限:
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir# mkdir myconda
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir# cd myconda/
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir/myconda# mkdir cache
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir/myconda# sudo chown -R aps:aps /opt/aps/workdir/myconda/cache
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir/myconda# mkdir temp
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir/myconda# sudo chown -R aps:aps /opt/aps/workdir/myconda/temp
root@lmlabide-6c32fde3-1f4b-49dc-b2a7-86279ae53daf-worker-0:/opt/aps/workdir/myconda# pip install modelscope

我们直接通过模搭下来载模型文件,先装一个modelscope :
pip install modelscope

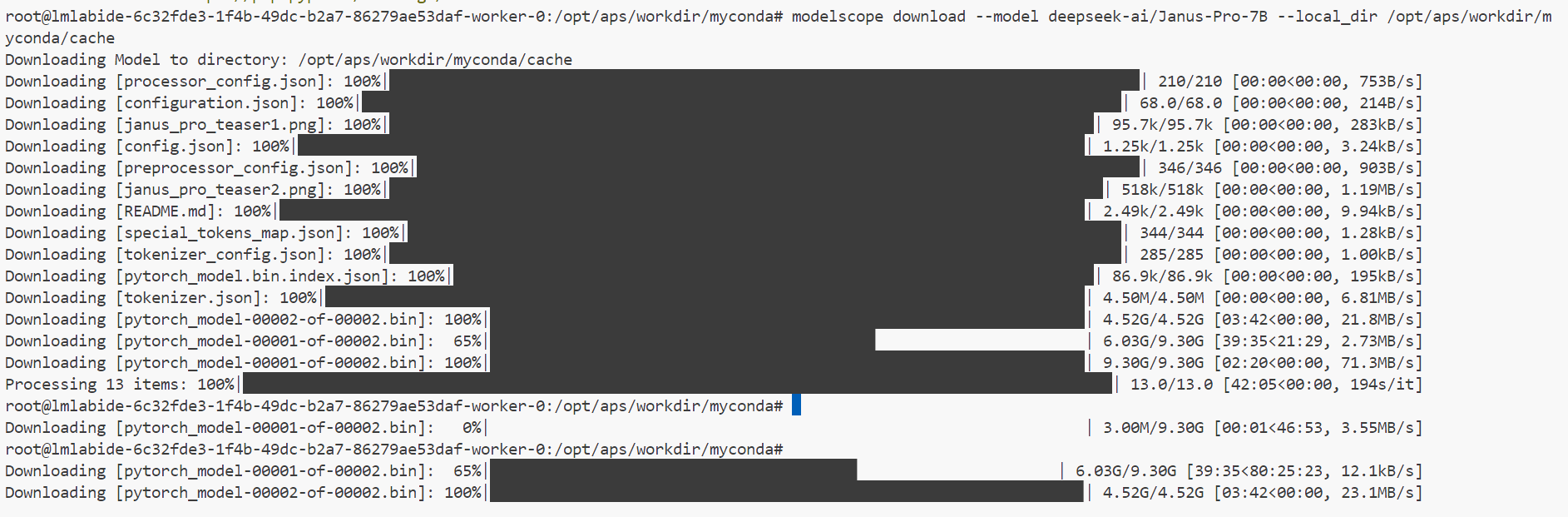
通过modelscope下载Janus-Pro-7B模型权重文件:
modelscope download --model deepseek-ai/Janus-Pro-7B --local_dir /opt/aps/workdir/myconda/cache
下载源码:
在Github官网下载安装包:https://github.com/deepseek-ai/Janus?tab=readme-ov-file#janusflow,并上传至服务器解压缩。
不能访问的可以到国内模搭站点下载:https://modelscope.cn/models/deepseek-ai/Janus-Pro-7B/files,下载后是一个Janus-main.zip压缩包,将其上传至Web Vscode的左侧的某个目录中,例如新建的一个janus7b目录。
安装依赖:
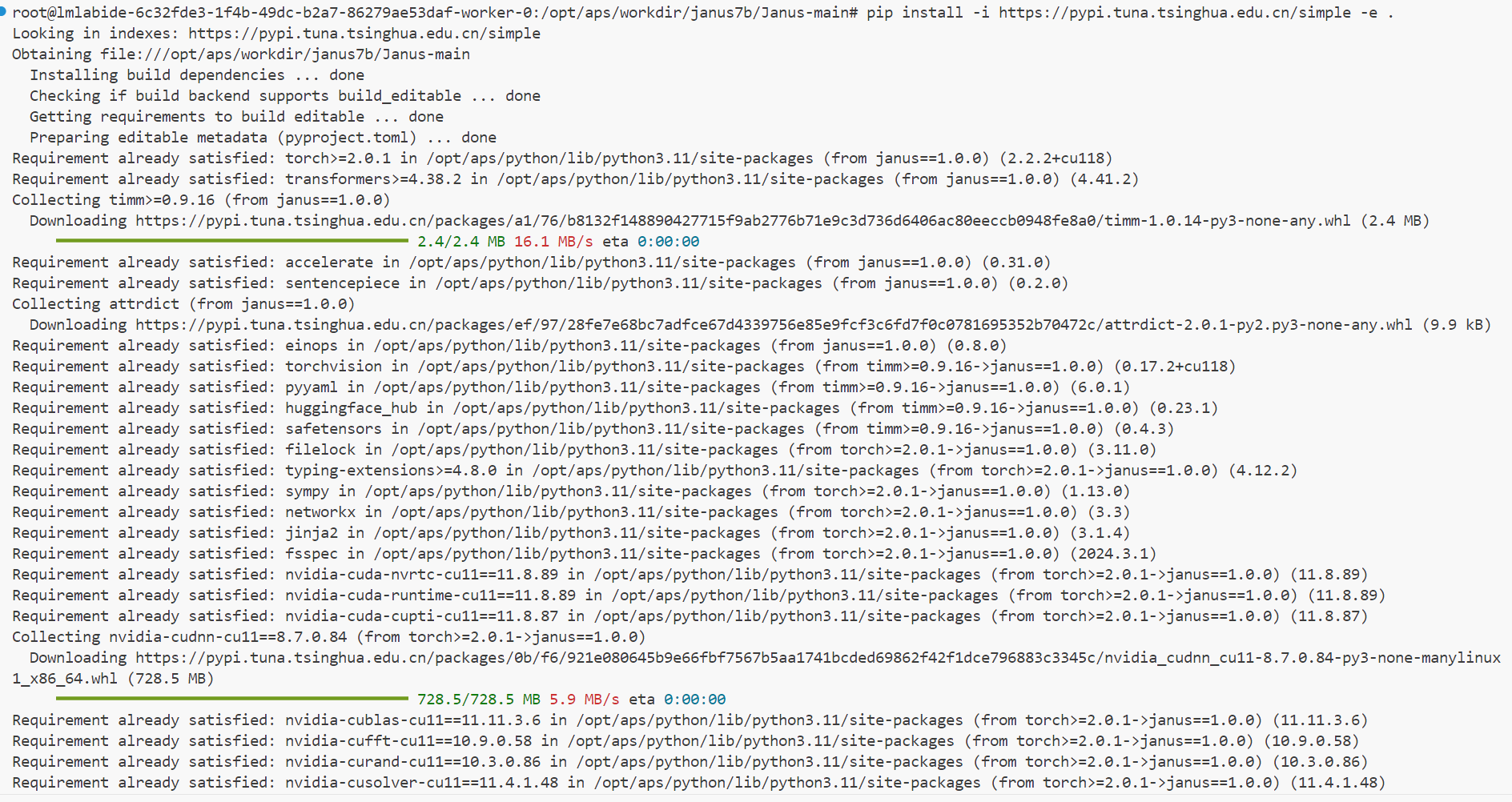
cd janus7b/Janus-main
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -e .#安装当前项目所有的基础依赖。

(2)下载安装包
sudo apt update
sudo apt install git
cd ~/autodl-tmp
git clone https://github.com/deepseek-ai/Janus.git
cd Janus
当然,也可以在Github官网下载安装包:https://github.com/deepseek-ai/Janus?tab=readme-ov-file#janusflow,并上传至服务器解压缩。
不能访问的可以到国内模搭站点下载:https://modelscope.cn/models/deepseek-ai/Janus-Pro-7B/files
(3)创建虚拟环境&项目依赖
准备 Conda 虚拟环境:使用以下命令创建 Conda 环境:
conda create-n janus python=3.9
激活环境:创建环境后,激活它:
conda init source ~/.bashrc conda activate janus安装 pip 依赖:激活环境后,安装所需的 Python 依赖:
cd/root/autodl-tmp/Janus
pip install -e . #指的是安装当前项目所有的基础依赖。
下载JupyterLab考虑到后续需要在代码环境中调用Janus,这里还需要下载JupyterLab,并配置kernel:
conda install jupyterlab conda install ipykernel python-m ipykernel install–user–name janus–display-name"Python(janus)"
打开Jupyter jupyter lab–allow-root。
下载模型权重:
这里我们考虑在项目主目录下创建models文件夹,用于保存Janus-Pro-1B和7B模型权重。考虑到国内网络环境,这里推荐直接在Modelscope上进行模型权重下载。
Janus-Pro-1B模型权重:https://www.modelscope.cn/models/deepseek-ai/Janus-Pro-1B。
Janus-Pro-7B模型权重:https://www.modelscope.cn/models/deepseek-ai/Janus-Pro-7B
安装modelscope :pip install modelscope
创建权重保存文件夹
cd/root/autodl-tmp/Janus
mkdir./Janus-Pro-1B
mkdir./Janus-Pro-7B
下载Janus-Pro-1B模型权重
下载1B模型
modelscope download --model deepseek-ai/Janus-Pro-1B --local_dir ./Janus-Pro-1B
下载Janus-Pro-7B模型权重
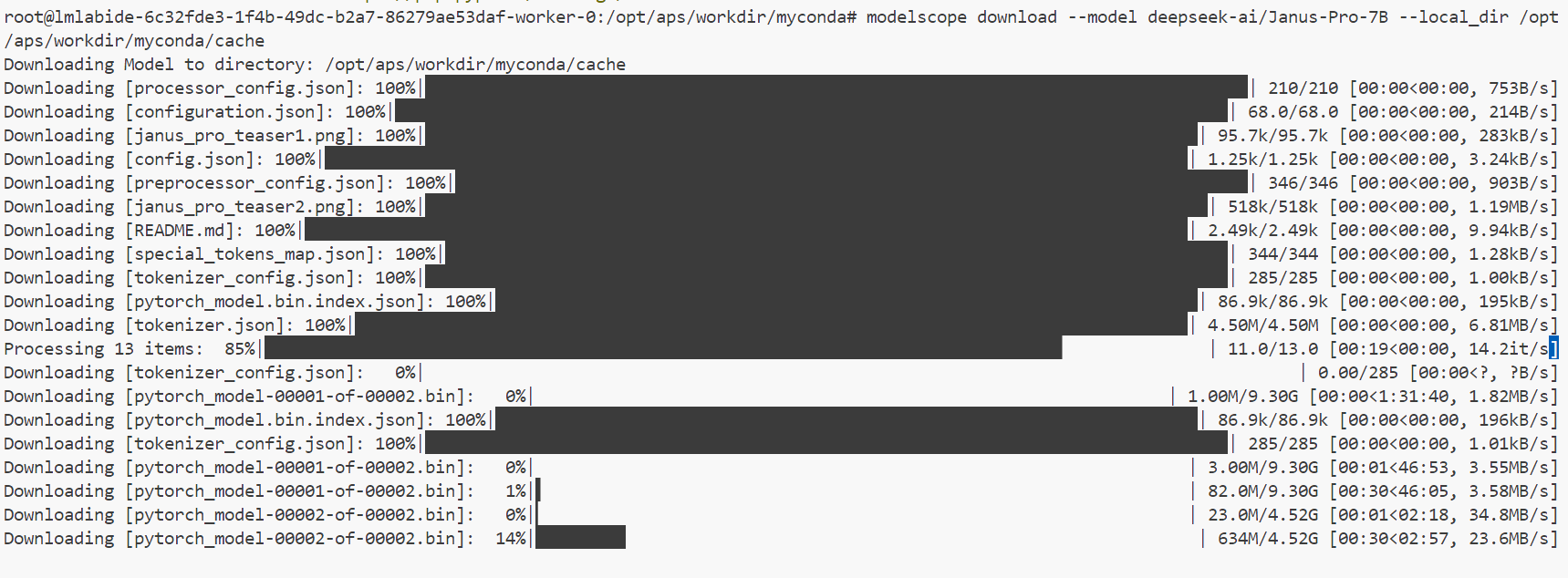
下载7B模型
modelscope download --model deepseek-ai/Janus-Pro-7B --local_dir /opt/aps/workdir/myconda/cache
运行与测试:
导入依赖
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM,VLChatProcessor
from janus.utils.1o import load_pil_images
导入模型及分词器
#指定模型路径
model_path="./Janus-Pro-7B"
#加载VLChatProcessor
vl_chat_processor::VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
#加载分词题
tokenizer = vl_chat_processor.tokenizer
#加载vl_gpt
vl_gpt:MultiModalityCausalLM = AutoModelForCausal model_path,trust_remote_code=True vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
DeepSeek是否真的在某些方面超越了OpenAI的模型?
今天,我们来深入探讨一下DeepSeek的推理大模型,尤其是与OpenAI的o1模型进行对比,看看DeepSeek是否真的在某些方面超越了OpenAI的模型。
首先,我们来看一下目前全球范围内比较强大的模型。有一个网站经常会发布模型的排行榜(leaderboard),这个排行榜是基于语言模型的性能来评定的。目前,最强的模型是Google的Gemini,它在排行榜上处于第一阵营。而DeepSeek的R1模型,也在这个排行榜上占据了相当重要的位置。
DeepSeek的R1模型是其最新发布的推理模型,它采用了660B的参数,并且在强化学习和后训练方面表现出色。R1更擅长逻辑推理和复杂问题的解答,在这一点上,R1已经超越了o1模型。
我们再来看一下DeepSeek的技术白皮书。白皮书中提到,DeepSeek R1是第一代推理模型,它基于大语言文本模型,是一个标准的推理模型。这次推出的模型有两个版本,一个是DeepSeek R1-Zero,另一个是DeepSeek R1。DeepSeek R1-Zero没有经过监督训练(SFT),而是直接进行强化学习,让模型自我推理和迭代。这种探索性的训练方式使得模型的能力不断提升。
然而,DeepSeek R1-Zero也有其缺陷,它的推理能力虽然很强,但输出的内容可能难以理解,不是人类友好的。因此,DeepSeek团队在R1模型中引入了监督训练(SFT),通过少量高质量的数据进行训练,使得模型输出的内容更加易于理解。
除了这两个模型,DeepSeek还发布了其他六个模型,包括不同参数规模的版本,如1.5B、7B、8B、14B、32B和70B。这些模型分为两个系列,一个是通用的,另一个是专注于推理的。DeepSeek通过知识蒸馏的方式,将这些模型的能力传递给较小的模型,如Qwen和Llama。
在性能方面,DeepSeek R1的表现非常出色。它在英语、编程挑战、数学问题甚至中文等多项基准测试中均表现出色,持续超越竞争对手。例如,在MMLU-Pro等基准测试中,DeepSeek R1的表现接近甚至超过了行业领先的模型。
DeepSeek R1的训练过程也非常独特。它采用了GROPRPO强化学习算法,这种算法在训练过程中不需要任何老师模型,让模型自我迭代,能力提升非常快。此外,DeepSeek R1还引入了“冷启动”(codestar)训练方式,通过少量高质量的数据进行监督学习,使得模型在推理和非推理任务上都表现出色。
在实际应用中,DeepSeek R1也展现出了强大的能力。例如,在代码生成和数学问题解决方面,DeepSeek R1的表现非常出色,甚至超过了行业领先的模型。此外,DeepSeek R1还能够将知识提炼成更小、更高效的模型,这些小模型在特定任务上也展现出了强大的性能。
最后,我们再来看一下DeepSeek R1的安装体验。英特尔酷睿Ultra AI PC成功适配了DeepSeek,并提供了简单易用的本地部署解决方案。用户可以通过简单的点击操作,在英特尔的酷睿Ultra AI PC上使用这些先进的AI模型。英特尔还提供了详细的安装教程,帮助用户快速上手。
总的来说,DeepSeek R1是一个非常强大的AI推理模型,它在多个领域展现出了卓越的性能,并且通过独特的训练方式和知识蒸馏技术,使得模型在推理和非推理任务上都表现出色。未来,DeepSeek R1有望在更多领域发挥重要作用,推动AI技术的发展。
DeepSeek R1的使用技巧
一、RTGO框架
1.什么是RTGO
“RTGO”是一种用于提升AI指令效率的框架,由资深AI训练师与行业专家共同提炼而成。该框架旨在解决用户在使用ChatGPT等工具时常见的“指令模糊-反复修改-效果不佳”的问题。RTGO框架的核心内容包括角色设定、任务拆解、目标管理和操作规范四个部分。
2.RTGO框架的底层逻辑
RTGO框架强调结构化对话的必要性,通过角色定位(Role)、任务拆解(Task)、目标导向(Goal)和操作规范(Objective)四大要素构成完整的指令生态系统。具体来说:
角色定位:明确AI的认知视角,确保AI理解用户的意图和背景。
任务拆解:划定执行边界,确保AI能够准确理解用户的任务需求。
目标导向:构建评估标准,确保AI的执行结果符合用户的期望。
操作规范:设定产出标准,确保AI的输出符合用户的要求。
3.RTGO框架的应用场景和优势
RTGO框架已在营销文案、数据分析等场景中验证其有效性。采用RTGO框架的用户,首次输出满意度提升63%,沟通迭代次数减少45%。该框架通过结构化的对话和明确的指令,帮助用户更高效地与AI进行交互,提升工作效率和结果满意度。
二、提问技巧
技巧一:提出明确的要求。能说清楚的信息,不要让模型去猜。虽然DeepSeek很聪明,但它不是你肚子里的蛔虫。你需要明确告诉DeepSeek,需要它帮你做什么,做到什么程度。比如你复制一段英文文本给它,你需要明确表达你的指令,是需要它进行翻译、总结,还是帮你学习英语出题等,这些信息都不要让模型去猜。又比如你想写一篇五百字的公众号文章,那就明确表达文章的主题和字数要求。虽然大模型并不擅长计算数字,它大概率只会返回三百到七百字的内容,但这至少能大致符合你的篇幅要求。
技巧二:**要求特定的风格。**具有思维链的DeepSeek R1在进行特定风格的写作时,相比其他模型,已经达到了断层领先的水平。比如你可以让DeepSeek R1用李白的风格写诗,或者用鲁迅的文风进行讽刺,甚至模仿任意作家的风格进行写作。在这个模式下,一个很有效的表达方式是让DeepSeek R1“说人话”,或者让它认为你是初中生,这样它就能把复杂的概念简化为你更容易理解的解释。
技巧三:**提供充分的任务背景信息。**当你让DeepSeek帮你完成某项工作时,提供充分的上下文背景信息,告诉它你为什么要做这件事,你面临的现实背景是什么,或者问题是什么,让DeepSeek将其纳入所生成文本的思考中,就可以让结果更符合你的需要。比如你要DeepSeek帮你生成减肥计划,最好告诉它你的身体状况、目前的饮食摄入和运动情况,这样它就能帮你生成一个更有针对性的计划。
技巧四:**主动标注自己的知识状态。**当你向DeepSeek寻求知识型的帮助时,最好能明确标注自己相对应的知识状态,这有点像老师备课前需要了解学生的水平。清晰的知识坐标能让AI输出的内容更精确地匹配你的理解层次。比如告诉DeepSeek R1“我是初中生”或者“我是小学生”,这是一个把自己放置在一个知识背景约等于零的状态的好方式。但当某些内容你希望能和AI深入探讨时,那你最好能更清晰地表达你在这个领域的知识状态,或者你是否存在关联领域的知识,这样能帮助AI更好地理解你,为你提供更精确的回答。
技巧五:**定义目标而非过程。**DeepSeek R1作为推理模型,完成任务的思维过程是非常令人印象深刻的。因此,我建议你提供清楚的目标,让DeepSeek有一定的思考空间去帮助你更好地执行,而不是提供一个机械化的执行指令。你应该像产品经理提需求那样描述你想要什么,而不是像程序员写代码那样规定怎么做。比如你的产品评审会开完之后,你可能需要整理录音的文字稿。一种说法是你可以直接要求R1帮你进行文字稿的整理,比如删掉语气词、按时间分段、每段加小标题等,这本身是一个非常清晰明确的优质提示语。但你同样可以进一步思考,这段录音文字稿所总结出的材料要如何使用?你可以为DeepSeek R1提供目标,让它创造性地帮助你完成任务。比如你可以要求它提取关键决策点、总结会议的核心观点,或者根据会议内容生成下一步的行动计划,这样它就能更主动地为你提供更有价值的输出。
技巧六:**提供AI不具备的知识背景。**我们在前面提到过,AI模型具有知识截止时间的特性。当任务涉及模型训练截止之后的新信息时,比如2024年的一些赛事结果、行业趋势,或者你们公司内部的一些信息,AI是不知道的。这种情况下,你需要帮助DeepSeek R1补充它缺失的那部分拼图,通过结构化的输入去帮助AI突破知识的限制,避免它因为信息的缺乏而出现错误的回答。
技巧七:**从开放到收敛。**DeepSeek的思维链是全透明地在你面前展开的。我常常觉得,从它的思考过程中能收获的信息比它最终给出的结果还要多。尤其是它在展开思考时,会做一个可能性的预测。有时在看这部分推测后,你才会发现自己原来有些方面的信息是没有考虑到的。如果你把对应的信息补充得更完善,那么就不需要DeepSeek R1再去猜测了。所以,在这种情况下,它能为你提供更精确、更符合你需要的结果。比如在下面的案例中,DeepSeek R1在思考时为我们提供了三种不同的涨价方案:分阶段涨价、增加产品价值、通过营销活动转移注意力,同时还预测了我们可能具有的两种深层次需求——保持市场份额或提升品牌形象。我们可以借此思考,我们真正倾向的方法和目标究竟是什么,从而对提示词进行进一步的收敛,那么接下来得到的结果就会更加精准。
什么是指令模型与推理模型?
最近DeepSeek大火,很多博主都在说DeepSeek V3是指令大模型,DeepSeek R1是推理模型,但这两个有什么区别呢?这里我就来给大家介绍一下吧。DeepSeek的R1是一个与你日常使用的对话类AI非常不同的模型。像OpenAI的GPT 4o、DeepSeek的V3或者豆包的模型都属于指令模型(Instruction Model)。这类模型是专门设计用于遵循指令来生成内容的。而DeepSeek的R1则属于推理模型(Reasoning Model),它是专注于逻辑推理、问题解决的模型,能够自主处理需要多步骤分析、因果推断或者复杂决策的任务。
实际上还有一个非常知名的模型,就是OpenAI的o1,它也是推理模型。但是你必须花二十美元成为Plus用户才能使用。并且即使你成为Plus用户,你每周也只有五十次的使用权限。如果你想要更多的使用权限,那你需要支付两百美金每月的费用,也就是大约一千四百三十元人民币。而DeepSeek R1现在是完全免费的。从我实际的体验来说,DeepSeek R1在实际的写作、写代码的任务上,甚至比GPT-o1要更强一些。
按理说,DeepSeek R1是一个擅长数学推理、编程竞赛的模型,它在这些任务上表现出色是非常合理的。但非常令人意外的是,在有了这种超强的推理能力之后,DeepSeek R1似乎在所有任务上都获得了质的飞跃,涌现出了一些意料之外的技能。
在原本指令模型的时代,AI的能力是受到很强的限制的。你需要通过提示词的各类技巧才能激发模型更好的表现。而对于普通人来说,学这些技巧实在是让人头大不已。而在DeepSeek R1模型下,你只需要清晰明确地表达你的需求就好了。就像你拥有一个比你聪明得多的、清北毕业的、而且具有十年工作经验的下属,你不需要一步步地指导他的工作,你只需要把所有他需要知道的信息告诉他,然后将你的任务布置下去就可以了。
为什么之前有人问DeepSeek:你是什么模型,它为什么回答是GPT呢?
有些模型会错误地认为自己是其他模型,这主要是因为用户将对话内容发布到了网络上,导致模型产生了幻觉。
DeepSeek出来后原来的提示词技巧为啥就失效了呢?
说完七个有用的提示词技巧之后,我们再来说说一些无用的提示词技巧。在使用DeepSeek的时候,我发现以下七个提示策略其实已经被验证是失效的,甚至有时候会起到反作用,你应该尽量避免:
1.思维链的提示。比如要求模型一步步思考,或者主动提供解答问题的思维链路,这些都没有必要。因为DeepSeek经过强化学习之后,已经能够产生更好的思维链。
2.结构化提示词。虽然你依然可以用Markdown格式让信息结构更清晰,但因为需要提示的内容减少了,所以必要性其实并不强。
3.要求扮演专家角色。DeepSeek本身就是一个专家模型,它会尝试用专家的思维方式来解决问题,所以你不需要让它去扮演专家。
4.假装完成任务后给奖励。这种小技巧是无效的,甚至有些荒谬。我们没必要再去“欺骗”AI,省得AI觉醒之后真的来找我们讨要奖励。
5.少示例提示(Few-shot)。这也是不必要的,而且DeepSeek的开发团队在发布技术报告时也明确提到,应该规避这种提示词技巧。
6.角色扮演。尽管很多人之前提到过让DeepSeek R1进行各种角色扮演的任务,但它其实不太适合。可能是因为情感化的对话更依赖直觉,而不是深思熟虑的结果。相比之下,基础模型可能更适合这类任务。
7.对已知概念进行解释。很多人在写提示词时,会解释自己想要的风格。比如描述鲁迅的风格是什么样的。其实完全没有必要,因为DeepSeek非常理解这些知名作家和人物的风格是什么样的。它在思考时会进行更深入和更丰富的结构化分析,相比之下,你写的解释可能反而没有它好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









