







1. 提出问题
对于Apriror算法来说,仍然受到两种非平凡开销的影响:
仍然需要产生大量的候选集。例如,如果有10^4个频繁1项集,则需要产生10^7个候选频繁2项集。
可能需要重复地扫描整个数据库。检索数据库中每个事务来确定候选项集支持度的开销会很大。
所以,我们需要设计一种方法,挖掘全部频繁项集而无须这种代价昂贵的候选产生过程。即,不需要产生如此大量的候选集,同时在确定候选集支持度时不需要重复地扫描整个数据库。
这里试图解决这种问题的方法称为频繁模式增长(Frequent-Pattern Growth, FP-growth)。
2. FP-growth
总的来说,就是在不生成候选项的情况下,完成Apriori算法的功能。
FPTree算法的基本数据结构,包含一个一棵FP树和一个项头表,每个项通过一个结点链指向它在树中出现的位置。基本结构如下所示。需要注意的是项头表需要按照支持度递减排序,在FPTree中高支持度的节点只能是低支持度节点的祖先节点。
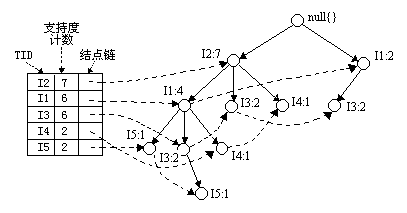
另外还要交代一下FPTree算法中几个基本的概念:
FP-Tree:就是上面的那棵树,是把事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度。
条件模式基:包含FP-Tree中与后缀模式一起出现的前
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









