









一、awk
sed以行为单位处理文件,awk不仅能以行为单位还能以列为单位处理文件。
awk缺省的行分隔符是换行符,缺省的列分隔符是连续的空格和tab,而且行分隔符和列分隔符都可以重定义,比如/ect/passwd文件的每一行有若干字段以:分隔,则重新定义awk的分隔符为:并可以以列处理这个文件。
awk可以像C语言一样支持分支和循环结构,基本语法和sed类似。
- awk命令基本基本形式为:
awk option 'script' file1 file2
awk option -f scriptfile file1 file 2
- 编辑命令的格式为:
/pattern/{action} 其中pattern为正则表达式,action为一系列操作。
awk程序一行一行读出待处理文件,若某行与pattern匹配,或满足condition条件,则执行相应的action,若一条awk命令只有action部分,则action作用于待处理文件的每一行。
2.从栗子中学习
栗1
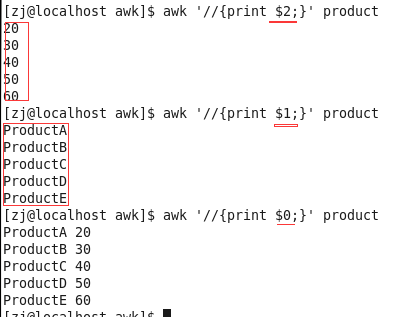
- 自动变量$0、$1、$2分别表示当前行、第一列、第二列
- printf是一条命令
- 读到的一行数据称一条记录,每一条记录被列分隔符分成多个域
栗2

- 支持脚本的动作判断
栗3 统计空行数与以E结尾的产品数
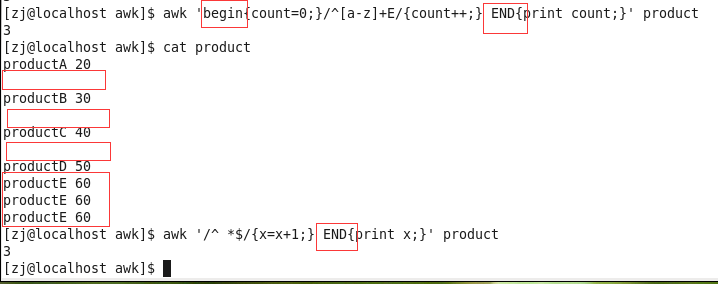
- 对于每个待处理的文件,BEGIN后面的action在处理整个文件之间执行一次,后面的END后面的action在文件处理完成后执行一次
- awk可以像C语言一样使用变量,不过不需要定义
- BEGIN和END可写可不写,但是位置一定在最开头和最结尾,且只执行一次
栗4 awk搜索

- NF即匹配最后一列,$(NF-1)表示最后一列的前一行
3、awk调用方式
①命令行模式
awk [-F field-separator] 'commands' input-file
其中,commands是真正的awk命令,[-F域分隔符可选],input-file是待处理文件
②shell脚本模式
将所有的awk命令写入文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行。
#!/bin/awk -f 相当于shell脚本的#!/bin/sh
解释时和shell脚本的步骤一样,先加权限,再运行。
4、awk调用正则表达式方法
- awk语句
-
- awk ‘/REG/{action}’ action为正则表达式
例:
awk '/^a.*n$/{print $0;}' file 在file里匹配以a开头、以n结尾的任意字符序列
- awk正则运算语句
-
- awk '{if ($0 ~ /^a.*n$/){print $0;}}' file 同上,不过里面加上了语句
- awk内置使用正则表达式函数
-
- gsub(Ere,Repl,[in])
- sub(Ere,Repl,[In])
- match(String,Ere)
- split(String,A,[Ere])
例:awk ‘{if (match($0, "^a.*n$")){print $0;}}' file
5.awk中的printf和print
awk中同时提供print和printf两种打印输出语句。
其中print函数的参数可以是变量、数值或者字符串。字符必须用双引号引用,参数用逗号分隔,若没有逗号,参数就串联在一起无法区分。这里,逗号的作用和文件的分隔符是一样的。
printf函数,语法和c中的printf相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
6、awk中的语句
- 循环语句
-
- while
- do/while
- for
- break
- 条件判断
-
- if
- if/else if
基本和c中风格类似
二、cut
cut负责在文件中剪切数据,cut以行为处理对象
1、cut命令的三个定位方法
- 字节 -b

一般汉字的byte大小不确定
- 字符 -c
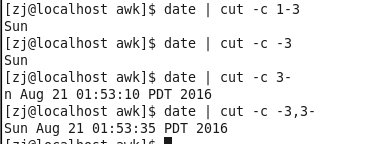
其中中文字符和空格都算一个字符
- 域 -f
-d指定域风格符,-f指定要剪出哪几个域
三、sort
sort将文件的每一行作为一个单位,相互比较,比较的原则是从首字符向后,依次按ASKII码直接进行比较,再肾虚输出
- sort -u 在输出行中去除重复行
- sort -r sort默认升序,加r表示降序
- sort -o 将排序好的写回源文件
- sort -n 以数值来排序而不是以字符来排序
- -t -k选项 后面可以设置间隔符,-k后面指定列数,以某一列来排序
- 其他

四、uniq
读取输入文件,并比较相邻的行,若相邻的行有重复则删去。一般都是先排好序,将相同的放到一起在进行删去重复。
此外,该命令将加工后的结果写到输出文件中,输入的文件和输出的文件必须不同,否则将会丢失数据 。














 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









