







拍摄于无锡
原文地址
https://blog.csdn.net/weixin_45689053/article/details/121744872
文章目录
1. HANA的三大杀器
1.1 内存式数据库
1.2 多核架构
1.3 列式存储
1.3.1 数据压缩
1.3.2 并行处理
1.3.3 聚集和索引
1.3.4 代码下移
2. CDS 概念
2.1 ABAP 开发环境
2.2 OPEN SQL语句
2.3 CDS 到底是啥
2.4 CDS 类型
2.5 创建CDS view
3. CDS 实操
3.1 Annotation注解
3.2 Case 语句
3.3 数学计算
3.4 字符串表达
3.5 货币转换
3.6 聚集语句
3.7 Join
3.8 Union
3.9 参数
3.10 作为子CDS View
3.11 CDS View中的association关联
3.12 扩展CDS View
3.13 CDS权限
1.1 内存式数据库
也就是说内存式计算,这个是实时OLAP的前提。也就是啥意思呢?
以前你家冰箱在厨房,要是躺床上饿了,得下床跑到厨房去拿。
现在给你家冰箱嵌卧室了,手一伸够着了。
数据都搞内存里去了。传输的就快了。
不用去硬盘再去拿了。原先大量数据过来要传好久的。现在我直接在内存里取数了。具体我好像这里描述了。这里.
1.2 多核架构
也就是可以大量并行。CPU可以扩展。
以前家里有一个保姆。干啥事都只能一件一件来。
现在你花钱多雇了几个保姆。送娃和做饭可以并行来。以上例子是瞎举的。保姆是请不起的。还是自己干吧。
1.3 列式存储
聚集和查询速度非常快。
一般关系型数据库表都是二维表。是有关系的。有行有列。
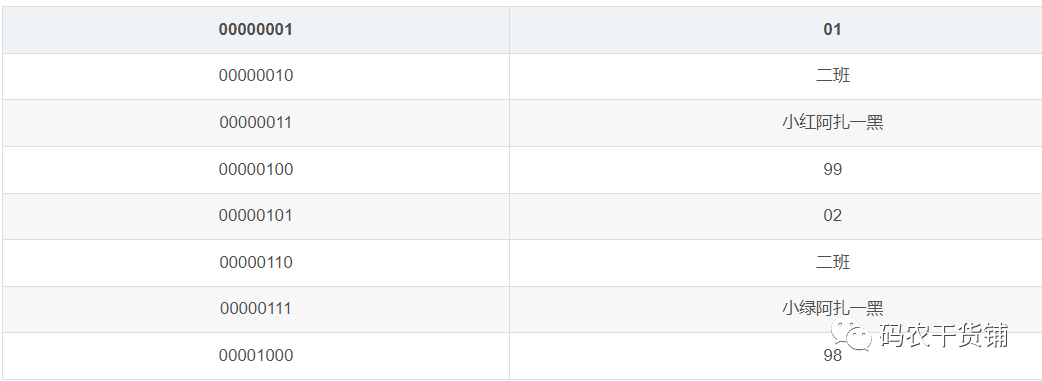
比如下面这个表:

数据库有按行来存储的,也有按列来存储的。
按照最小存储单元为1byte。存储单元都是按地址顺序来排。如果你是按行来存储,那就是这样的(以下是个示例,实际占据的空间是一个字节1byte,int型的占四个字节):
如果按照列式存储,那就是这样的:
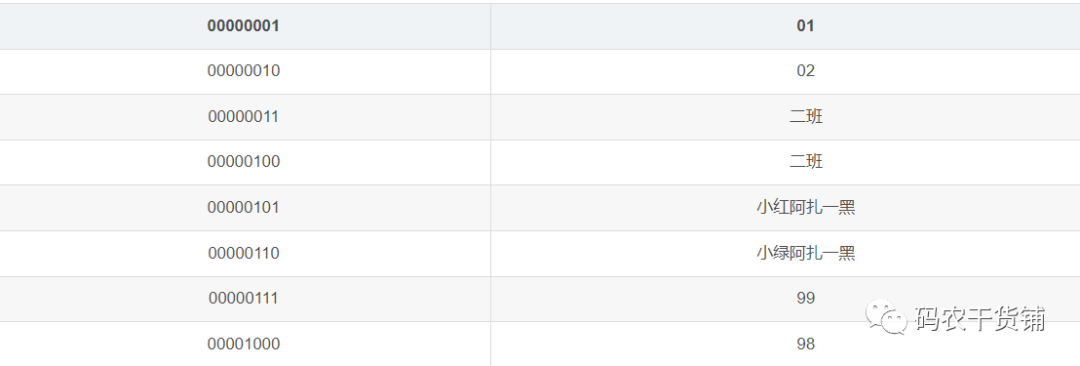
按照这种连续的存储空间来存储。
那么我们到这里看下,行列的优缺点:
行存储:我去读数据的时候,按序来读,会从上到下读一行,然后再往下读另外一行。每一行都是存完了再存另外一行。这种情况下,如果我说我的需求是把完整的一条数据取出来,那么这种行存储就明显比列存储快。我就去把表遍历一遍,看我要的是哪条就行了。但是对于列的话,假如我要第二行,那我得先去找02地址的,再去找04地址的,再去找06地址的。我要N个属性遍。
列存储:如果我不是要完整的一条。我要找最高的分数。那如果在行存储里,我还是要遍历全表。但是列存储里,我只要找分数这个属性,然后去找它的最大值。或者说我去找班级是二班的有多少个。那么我只要找班级这个属性。实际应用中这种需求是居多的。
总结一下:行存储适用于表条目数少,属性值都很少重复,不需要聚集或不需要快速查询的。
列存储适用于表量大,属性多,有聚集的需求,表列属性多有重复的。
至于说为啥我要查找班级分数最高的,就会很快呢?行表是遍历去找。为啥列表就是直接去找属性了呢?因为列式存储的给属性加了个数据字典。
啥意思呢?
比如对于第二列班级,列表中会有数据字典,数据字典只保存非重复值。

这个数据字典会另外存储,实际列表存储的时候是以编号代替字符的。
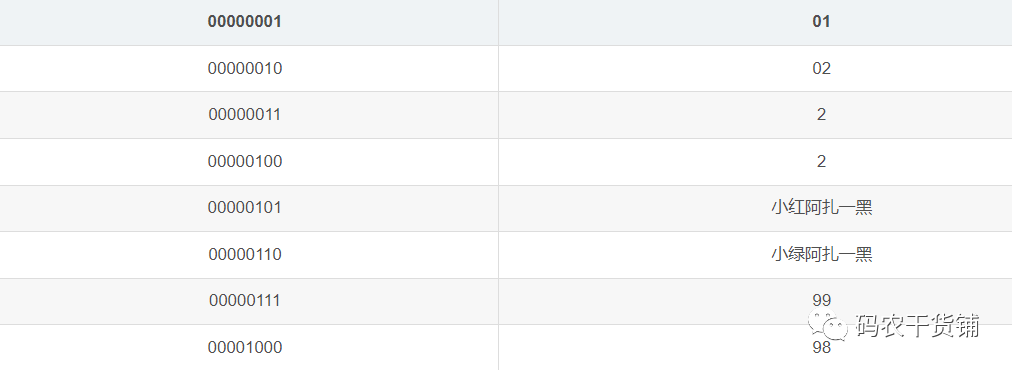
可以节省空间,毕竟字符是8个byte,有些长的字符那就更占空间了。比如二班这两个汉字,4个字符,32个byte。如果你用INT来存储编号,那是只有一个2,那就是4个byte。一个就省了28个byte。
1.3.1 数据压缩
默认列式存储会自动压缩,还有一些高级压缩涉及到前缀译码,运行长度译码等等。自动压缩就是上面那个列式存储的压缩。
1.3.2 并行处理
对于列式存储,如果我们只要一个属性的什么最大值啦,计算个数啦,总计等等的。由于CPU的可扩展性,在HANA中可以由多核CPU并行处理不同的列需求。
同一列也可拆分成不同的并行处理。比如二班三班的。
1.3.3 聚集和索引
到了HANA上是不需要聚集和索引了的。可能大家也听说过了,是因为HANA上处理速度都那么快了。要啥聚集和索引啊。
注意这里是不需要了,不是说不能建了。
为啥我们一开始要聚集。那还不是性能的问题。
这就回到了为啥OLTP和OLAP要分开。如果我们直接在OLTP上搞分析,那不行么?就是因为人家一方面在录入订单,你一方面在查询。一个写,一个读。大家都在访问数据库,如果系统有1000个用户都在这么搞,这么多次点击,这么多次要求,我都得建立链接,解析SQL,执行请求,系统进程扛不住啊,也不知道该响应谁的,大家会把系统数据搞的一团糟。所以OLAP分离成BW了,就先每天晚上跑处理链,把数据复制过来一把,然后再读吧,也别搞实时了。至少数据是准确的。
但是HANA为啥就不需要聚集了呢?因为人家可以在任何行项目表上建实时聚集视图你搞吧,随便你这会是要保存个订单还是修改个订单,你弄啥我就给你投影出去啥。人家都能从我视图上看到实时数据。
为啥HANA不需要索引了呢?一般行存储的表需要索引,要不然遍历起来费劲。但是我都搞列式存储了。不按序来查找数据了,我也就不需要索引了。
聚集和索引的去除,节省了一大部分处理聚集和索引的应用代码。
1.3.4 代码下移
至于代码下移又是啥意思呢?就针对我们BW来讲,如果我要在转换里面结合其他表的数据,我为了不频繁访问数据库,我都是把能结合的表先结合了,把数据都全拉过来到应用服务器上,然后再操作这些取过来的数据。虽然说有时候内表过大取数很费时,但是我有了这所有的数据,然后再操作我想要的结果就方便多了。总好过去我一会去数据库取一点数。
但是到HANA这,需要你代码下移到数据库了。啥意思?
就是你别把数据都取到应用服务器上了,我数据库不怕你取,你要啥你就取啥,你在数据库都精准的取好你要的数据,我只会返还给你你需要的那一部分数据。
就是说这个结果集会很小,多用用WHERE和HAVING,SORT吧。传输的数据量会很小,SELECT with 字段名,别*。不必要的查询结果就没必要传输了。别弄那个select的循环了,弄弄join和subquery限制数据量。
这一下就减轻了数据库存储和网络传输到应用服务器的负担。有时候还可以用用缓存。
2. CDS 概念
在看CDS之前,先看一下ABAP开发环境
2.1 ABAP 开发环境
先进入eclipse的ABAP perspective。
说实话这个perspective我也不知道咋翻译。就是这个perspective下面有好多。
我装的这个eclipse是什么Java developer啥的。这个IDE下面就有好多perspective,反正不管了。这些对于我够用了。
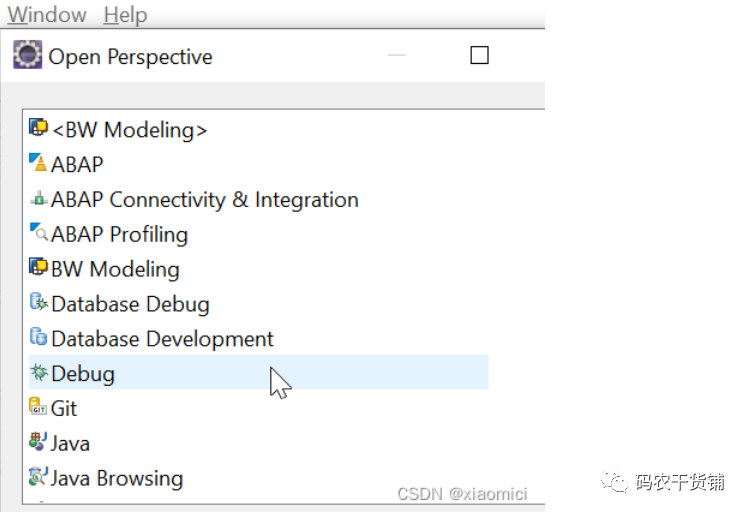
点击了之后在右上角能看到。最左边那个带加号的也可直接加perspective。就这个开发环境我看支持BW啊,ABAP啊,JAVA啊,HANA啊的。

创建了ABAP的project之后,也就是说通过把ABAP后台系统和eclipse的开发环境关联上了,通过这个eclipse平台,创建,运行,测试你ABAP系统repository里的对象都可以。
也就是现在的面向对象ABAP在eclipse里面的编程环境搞。
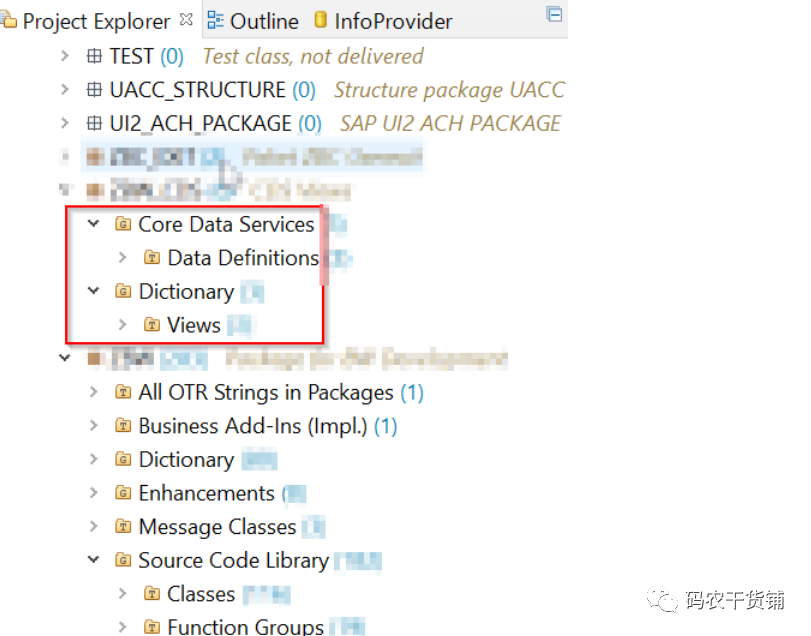
进入ABAP环境就是它下面啥呢?就像ABAP se80下面好多东西。
这一个个package下面。有新的CDS啦,有数据字典啦,有类,接口,程序,功能组,BADI 啥啥啥。
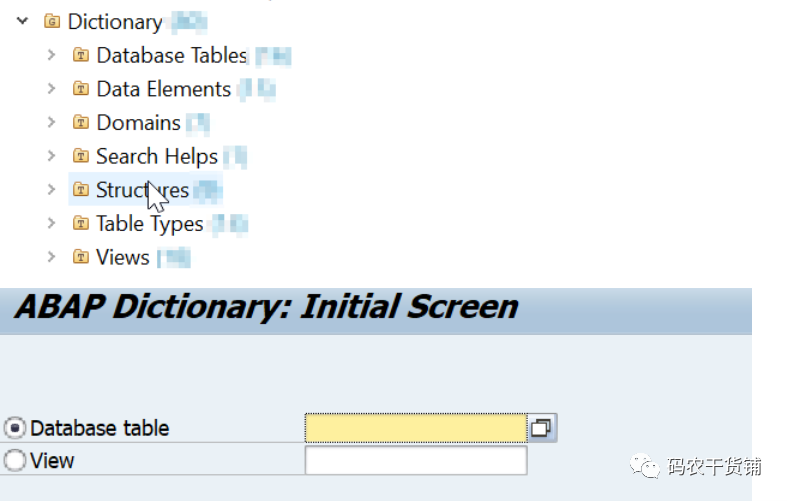
然后就是经常去outline看看,这个里面就是你点了什么对象,就会给个对象里的详细信息。
还有最顶上一系列按钮,然后和最底下一系列按钮都挺有用的。

2.2 OPEN SQL语句
SQL结构化查询语句,其实分三个子语句:

我们在ABAP里面用的是OPEN SQL,只涉及到DML语句。
DDL这些都是在数据字典里弄。而DCL呢,好像是BASIS来搞。我们在SE11里面建透明表,激活了之后后台系统会生成建表语句。
而在ABAP里面用的open SQL其实是简化版本的,像现在在HANA里面的computed columns啦,case啦,right outer join啦,UNION啦,DAYS_BETWEEN()都不能用。而且你也不能去open HANA的 view和procedure。这些都是限制啊。
但是7.4SP5之后的open SQL可以用新语法了:
arithmetic/aggregation/comparative functions这些是用来支持代码下推的。SP5之后上面的功能也都是支持的。
那有啥区别呢?
就新的select的字段后加逗号分隔,然后主变量前加@。就它OPEN SQL自己的变量。建议用新的OPEN SQL。别跟旧的混了。
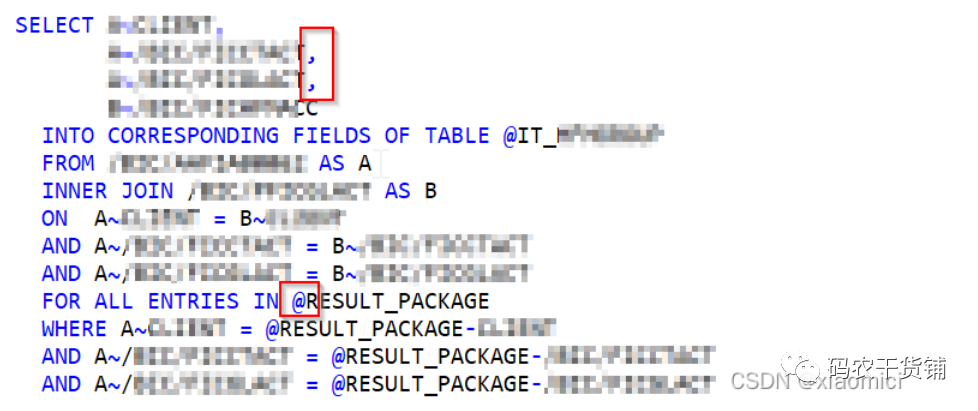
为啥讲这个?因为CDS view它用的是新的OPEN SQL语句。
那么再回到DDL去,如果我们用ABAP数据字典建view,那么跟CDS view会有啥差别?
建过的都知道。那就只能用inner join啊。你就不能在里面搞什么计算,聚集,分组啥的。
2.3 CDS 到底是啥
Core Data Services 核心数据服务。是数据+服务。
要知道你去ABAP创建字段的时候,先去创建数据元素 data element,里面是field,label,短描述长描述。其实这个field还要再进一层去建domain,domain里面是技术属性 data type和length 。这个是DDL层。在CDS里面同样也有这个:
那么CDS包含啥?

好了,大致包含上面。
那么这个DDL干啥?
就是说数据库表,视图这些呢,有个名字叫做CDS实体。那这些东西,你不在SE11里面弄,可以直接DDL弄。
而QL,如果你用CDS DDL弄了视图,那么你就可以用QL来使用这个视图。当然你这个视图在其他CDS view里面也可以被用。
最后一个DCL,控制CDS实体的权限的。以前的权限是通过权限相关对象来搞,要么是你执行的时候后台搞,要么你用语句来authority check。这个CDS实体权限也就是当你用open SQL去对CDS view进行操作的时候,ABAP运行会自动检查。
2.4 CDS 类型
在看CDS类型之前呢,要知道跟着CDS来的有两个东西:
数据定义 data definitions
DDL source,就是CDS view或者CDS table的定义,这个你在GUI里面能看到,但是要想修改,只能在eclipse里面。
权限控制 access controls
DCL source,在程序访问CDS view 或者CDS table的时候自动检查的权限规则的定义。也是只能在eclipse里面修改。
下面来到CDS类型:
CDS有两种类型:
ABAP CDS:就是不管底层数据库是啥,我都能用。是建在ABAP application server上的view。
HANA CDS:直接在HANA数据库上面弄的,用来从头搞建模的。一般没有BW,直接从底层HANA XS建模。
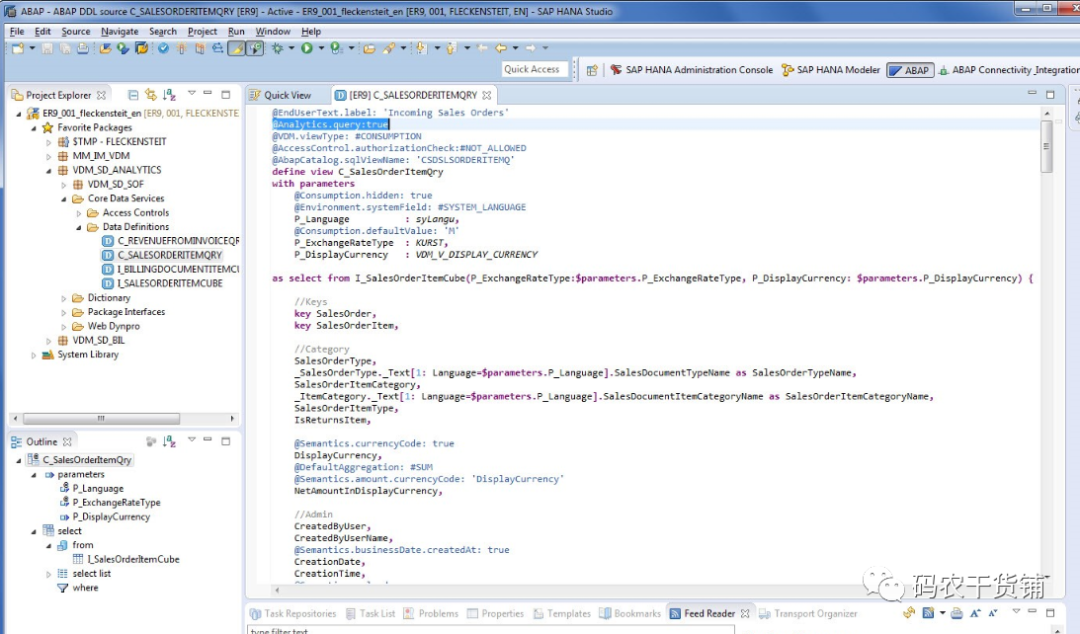
那么CDS view和传统的ABAP view有啥区别?
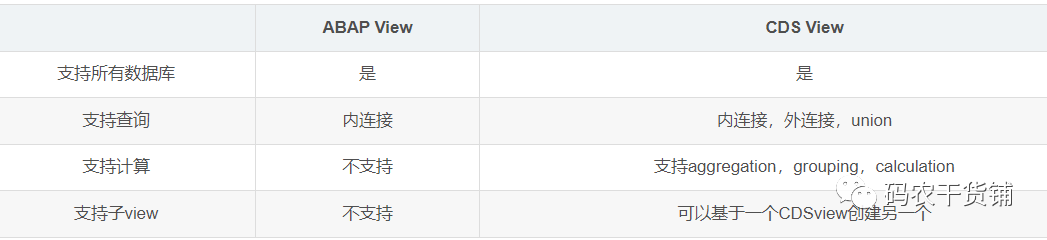
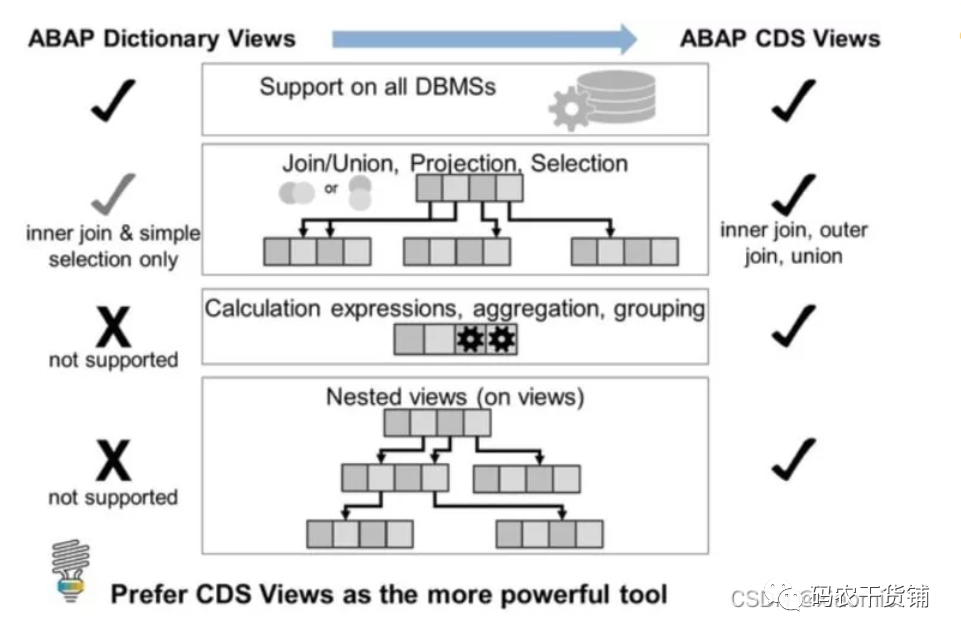
CDS 同时支持annotations,这个是啥呢?就是一些语义信息的添加。接下来会写。
你也可以DCL定义权限规则。
CDS里还可以用associations关联。这个会自动根据你的select语句转换为join。
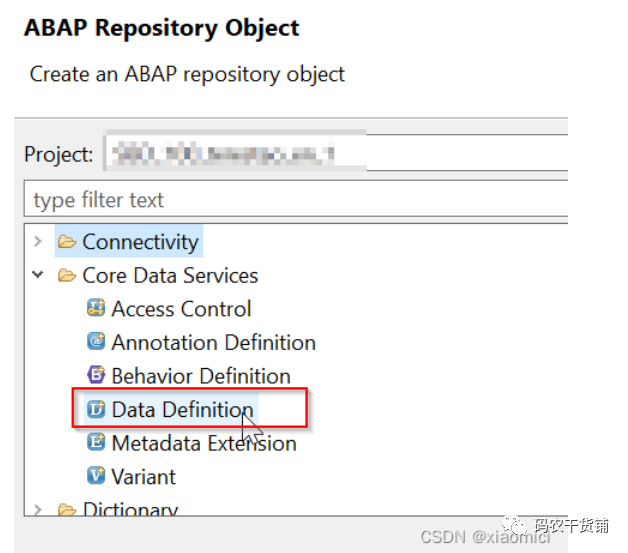
2.5 创建CDS view
CDS view 的创建很简单,包上右键。

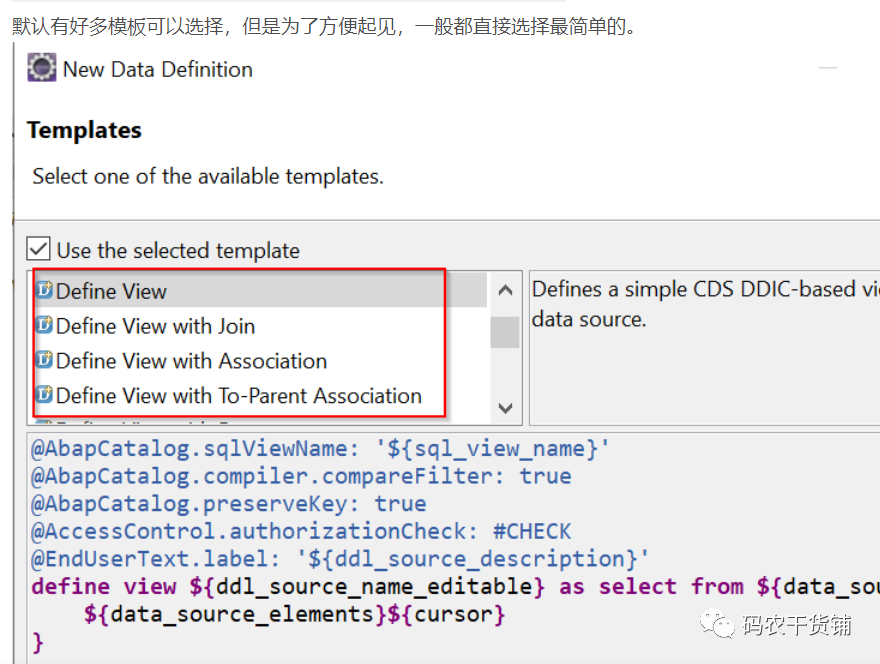
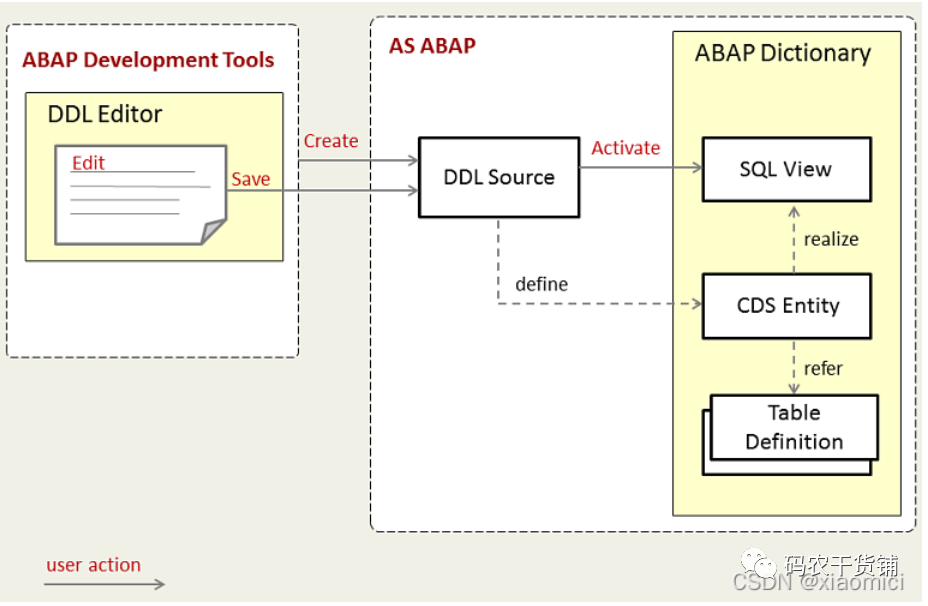
到这里呢,有个要注意的地方了。我们用DDL去定义View的时候,一旦这个view激活,将会生成两个view,一个是SQL view,就是第一行@sqlVIEWNAME。另一个是CDS VIEW)。说实话,我也不知道这个SQL View用来干啥的。这个SQL View可以在ABAP数据字典里看到。CDS View只能在eclipse里面看到。
你可以把SQL View理解为CDS View在数据字典的代表。CDS View本身是不存在于数据字典的(下面那个CDS实体有误,不应该在数据字典的框框里),它只能被open SQL访问。
一般情况下,你建的DDL名字和你建的CDS View名字要一样。然后SQL View无所谓。
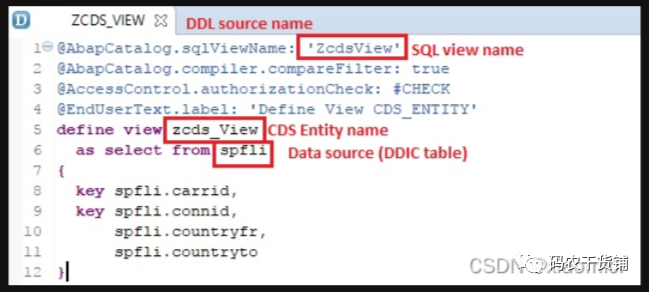
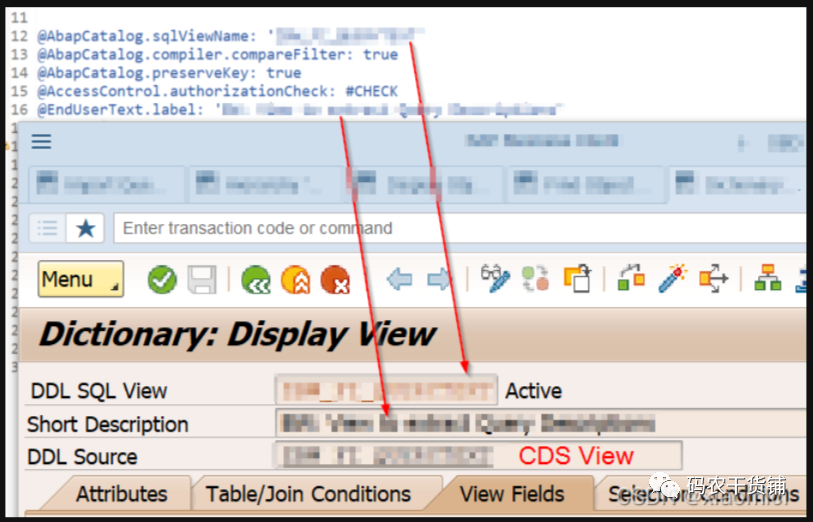
以@开头的是一些annotation,就是注解,用来添加一些附加信息。怎么缓存啦,怎么扩展啦。这些注解都是SAP预定义好的。@SQLViewNAME这个是强制的。这个在实际应用过程中才能慢慢贯通。

看看人家的一个例子:
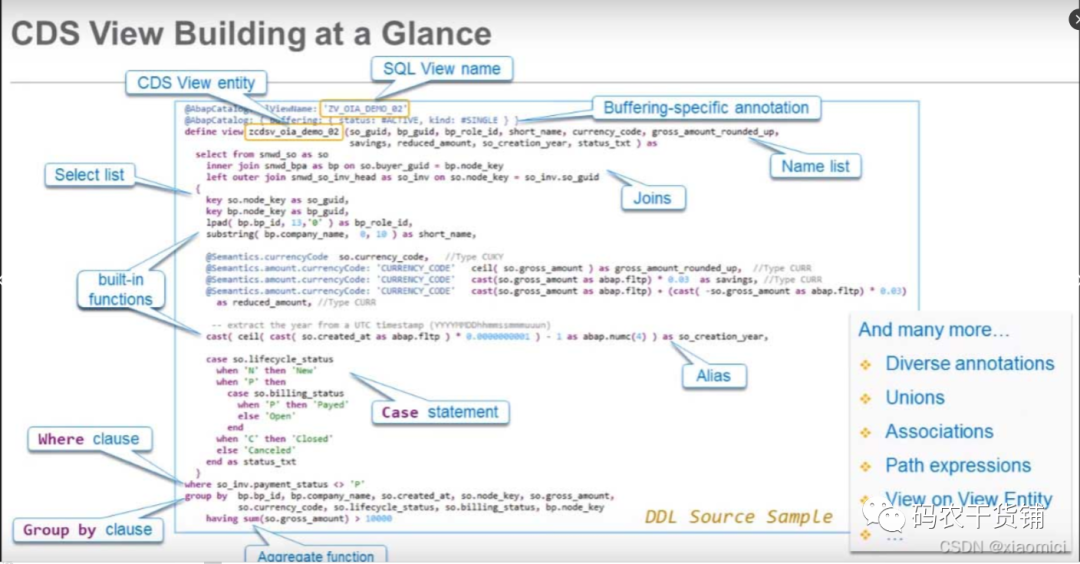
还可以有参数:


还可以Append view。可以说是功能很强大了。
在创建CDS View的过程中,有两个很有用的快捷键:
Ctrl + Space 自动填充,关键词,模板,变量名方法名。
Ctrl + 1 快速修复error,warning。创建方法implementation,方法定义,interface实现等等。
3. CDS 实操
在此之前,找SAP的表练习,先把一些SAP给的表给填充一下:
用这个program:
SAPBC_DATA_GENERATOR

好了,在创建DDL之前,你要知道一些格式问题:
关键字,要么全大写,要么全小写,要么首字母大写。DDL名字就全大写吧。
// 后面注释掉你想注释的东西
/* 里面囊括要注释的 */
CDS view名字最长30字符,SQL view 最长16字符,两个最好不一样。
数字小数得加0 , 不能说写成.5要写全成0.5 字符数字加’0.5’。
语法推荐:
define view ***
as select from ***
{
key ***
}在project右键新建:
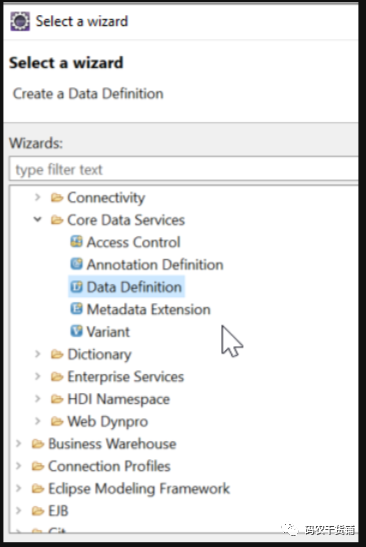
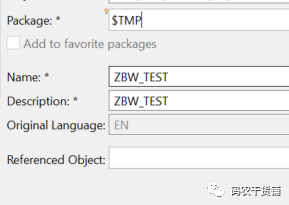
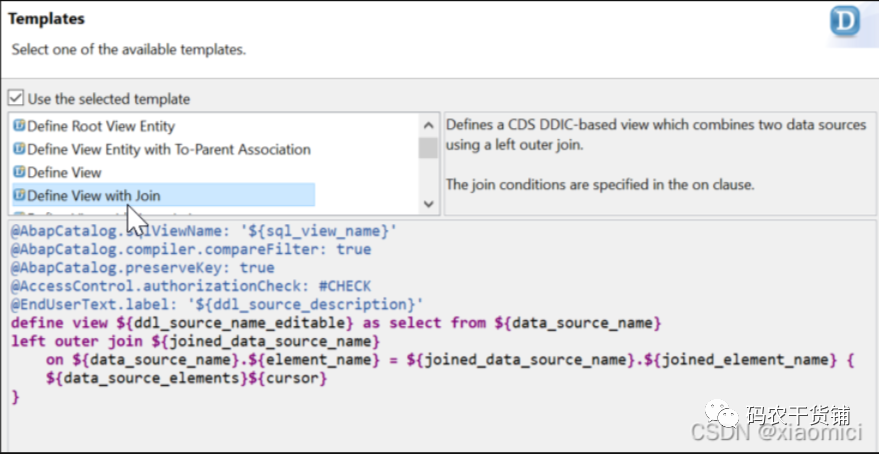
先放到本地包里去。然后下一步好多模板可以选。不选的话默认view。
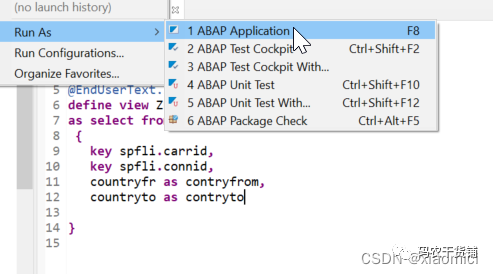
F8预览数据。
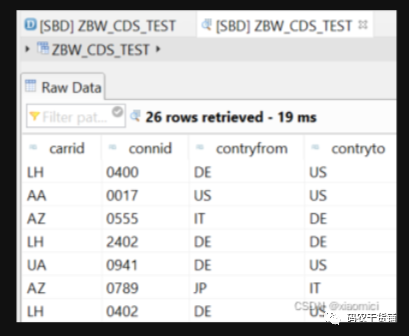
预览的页面里有SQL Console,还可以对CDS View进行进一步操作。
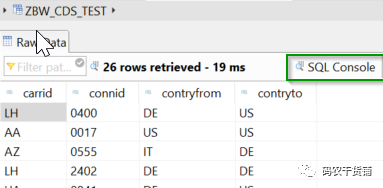
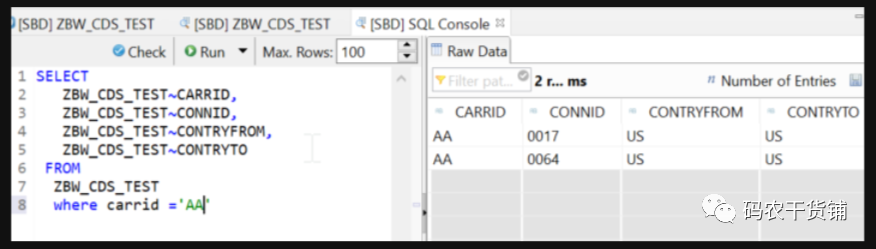
好了,接下来可以去看看你的SQL View了,那就直接在eclipse里面去看吧。
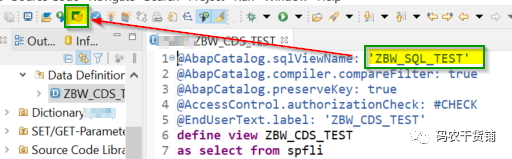
MANDT也给带上来了。
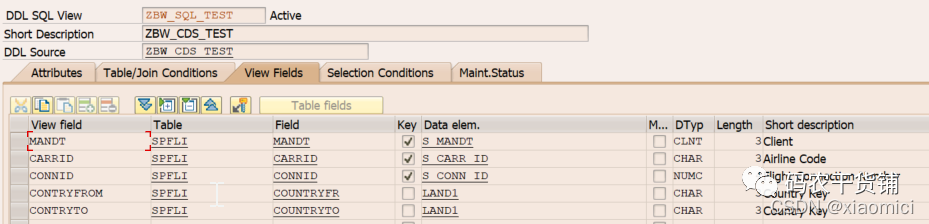
右键CDS View看到很多有用的信息:
这个自己点进去看看。
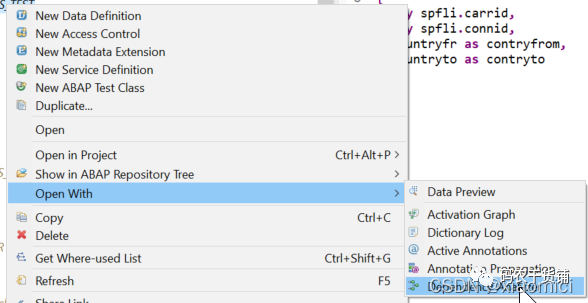
3. CDS View
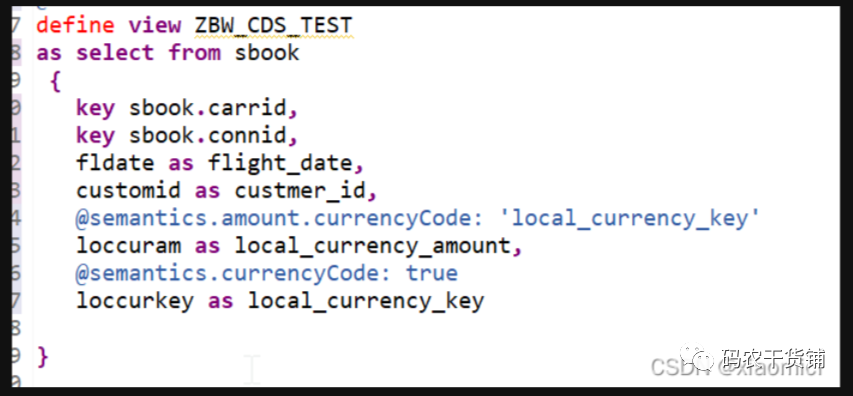
3.1 Annotation注解
注解分为几大类:
视图注解:
@AbapCatalog.sqlViewName: ‘ZBW_SQL_TEST’ (这个注解是强制性的,必须得有一个,而且是和CDS View名字不一样的)
@EndUserText.label: ‘ZBW_CDS_TEST’
就在define view的开头
或者说这些注解:
也就是这些注解去手动设置一些配置项。
元素注解:
是view中间的元素
@Sementics.amount.currencyCode:‘local_currency_key’
@Semantics.currencyCode:true
比如:
你要把金额和单位关联起来,就像下面这样给这两个注解。
参数注解
@Environment.systemField:#SYSTEM_DATE
扩展注解
@AbapCatalog.sqlViewAppendName:‘Z_CDS_SQL’
用来扩展CDSView的
功能注解
在不同功能前的注解。
Ctrl+空格键你能看到系统提供好多注解。
3.2 Case 语句
一般的case语句
以关键字case开头判断紧跟在后,end 结尾,as别名在CDSview里面加一列。
不满足判断条件就依据else的判断。
case smoker
when 'x' then loccuram + 100
else loccuram
end as inc_smoker_charge_1l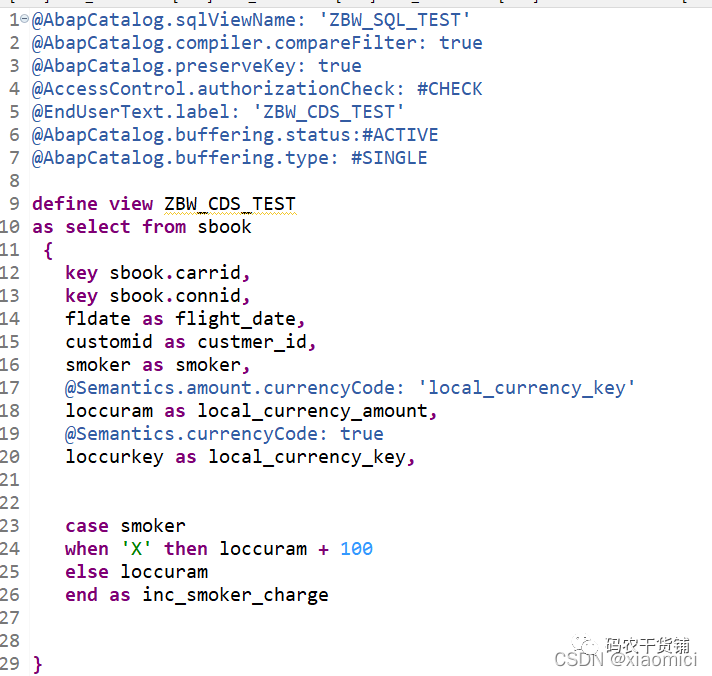
多加一列,抽烟加100块钱

2. 类似if/else的case语句
这个就很类似if语句,判断条件没有紧跟在后,而是在When里面进行判断。
case
when smoker = 'x' and currencytype = 'E' then loccuram + 100
when smoker = 'x' and currencytype = 'C' then loccuram + 200
else loccuram
end as inc_smoker_charge_2,嵌套case语句
case smoker
when ' ' then loccuram
else case
when custtype = 'b' then loccuram + 100
when custtype = 'p' then loccuram + 200
else loccuram
end
end as inc_smoker_charge_3,3.3 数学计算
加减乘除肯定是支持的。那么剩下的就是一些内置的计算了。
ABS:绝对值 abs(-1.7) = 1.7
FLOOR : 往低值取整 floor(-3.5) = -4 floor(3.5) = 3
CEIL: 往高值取整 ceil(-3.5) = -3 ceil(3.5) = 4
ROUND: 四舍五入 round(3.1415,2) = 3.14
CAST:这个关键字转换数据格式 CAST(操作数 AS 目标类型)
操作数:可以是数据源字段,数学表达式,case语句表达式,预定义功能
目标类型:可以是预定义的数据类型:ABAP int4、char
也可以是数据字典元素 S_CARR_ID
3.4 字符串表达
CONCAT(a,b) 连接字符,返回类型为CHAR或者STRING
REPLACE(a,b,c)这个意思是replace all occurrences of b in a with c 把a里面的所有b替换成c,返回类型是a的类型
SUBSTRING (a,pos,len)截取从pos后开始的len位。返回类型为a类型
LENGTH(a)取a的长度,返回值类型是个INT4型
3.5 货币和单位转换
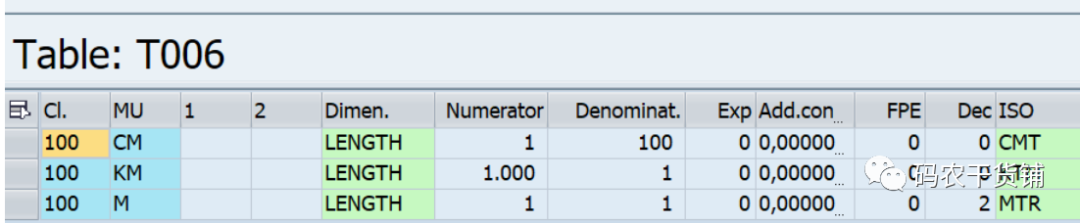
就是说把源货币单位转换成目标货币单位,那么源单位和目标单位的转换关系就得有地方存。
unit_conversion(quantity=>a, source_unit=>b,target_unit=>c):这个转换规则一般通过CUNI这个tcode配置,保存在T006表里
返回值类型为abap.quan
currency_conversion(amount=>a,source_currency=>b,target_currency=>c):这个同样的,得有换算比例,OB08设置在TCURR这个表里了。
返回值类型为abap.curr
这些自己做做例子。
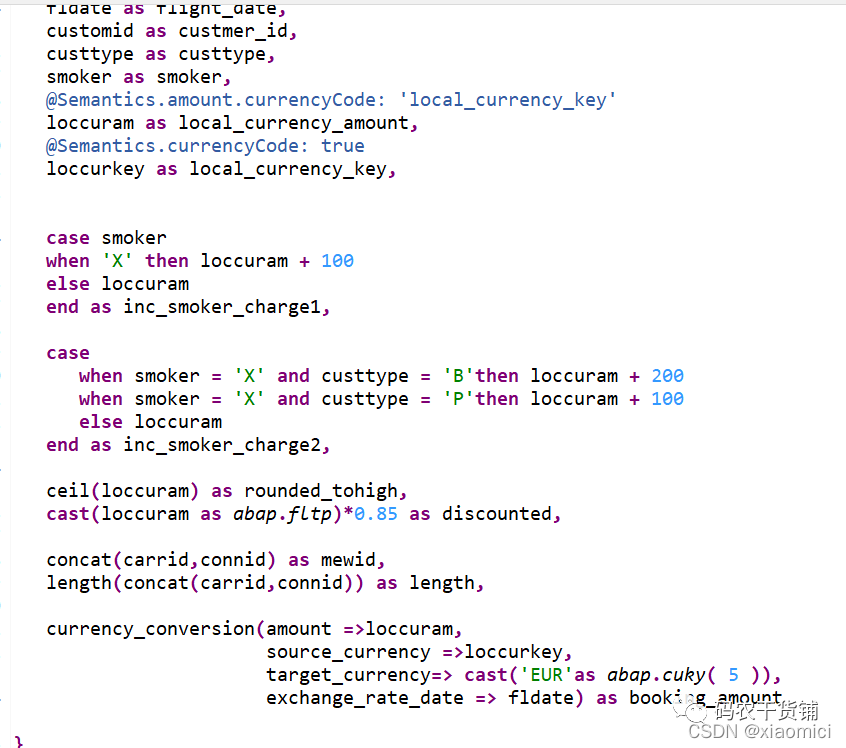
@AbapCatalog.sqlViewName: 'ZBW_SQL_TEST'
@AbapCatalog.compiler.compareFilter: true
@AbapCatalog.preserveKey: true
@AccessControl.authorizationCheck: #CHECK
@EndUserText.label: 'ZBW_CDS_TEST'
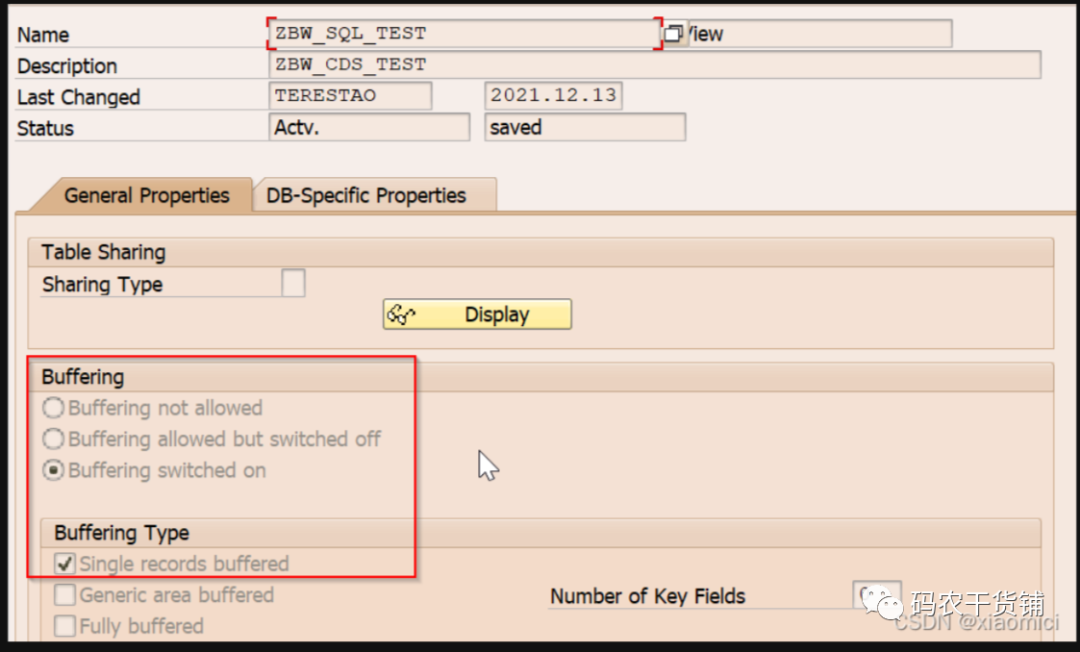
@AbapCatalog.buffering.status:#ACTIVE
@AbapCatalog.buffering.type: #SINGLE
define view ZBW_CDS_TEST
as select from sbook
{
key sbook.carrid,
key sbook.connid,
fldate as flight_date,
customid as custmer_id,
custtype as custtype,
smoker as smoker,
@Semantics.amount.currencyCode: 'local_currency_key'
loccuram as local_currency_amount,
@Semantics.currencyCode: true
loccurkey as local_currency_key,
case smoker
when 'X' then loccuram + 100
else loccuram
end as inc_smoker_charge1,
case
when smoker = 'X' and custtype = 'B'then loccuram + 200
when smoker = 'X' and custtype = 'P'then loccuram + 100
else loccuram
end as inc_smoker_charge2,
ceil(loccuram) as rounded_tohigh,
cast(loccuram as abap.fltp)*0.85 as discounted,
concat(carrid,connid) as mewid,
length(concat(carrid,connid)) as length,
currency_conversion(amount =>loccuram,
source_currency =>loccurkey,
target_currency=> cast('EUR'as abap.cuky( 5 )),
exchange_rate_date => fldate) as booking_amount
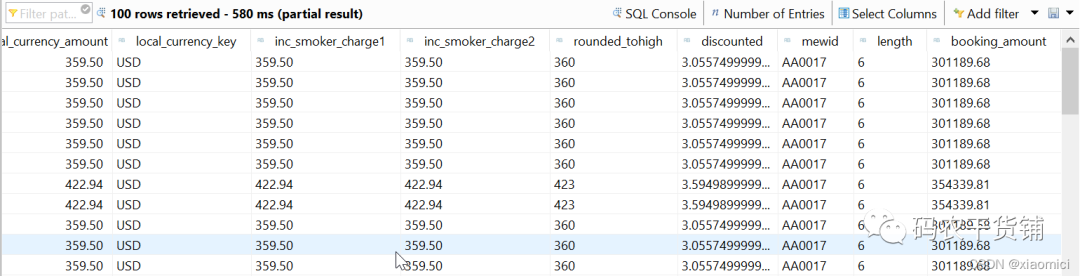
}3.6 聚集语句
MIN(a) 取最小值 返回类型为a的类型
MAX(a)取最大值 返回类型为a的类型
SUM (a)取整 返回类型为a的类型
AVG(a)取平均 返回类型为floating
COUNT (*) 计算行数 返回类型为INT型
COUNT(DISTINCT a)计算不重复值得行数 返回类型为INT型
以上经常和GROUP BY或HAVING连用。
可以在select或者having语句中使用,select语句要给as别名
注意:当你使用聚集,那么没用聚集的那列要在group by里用,不然会报错。这时候Ctrl+1会自动提示
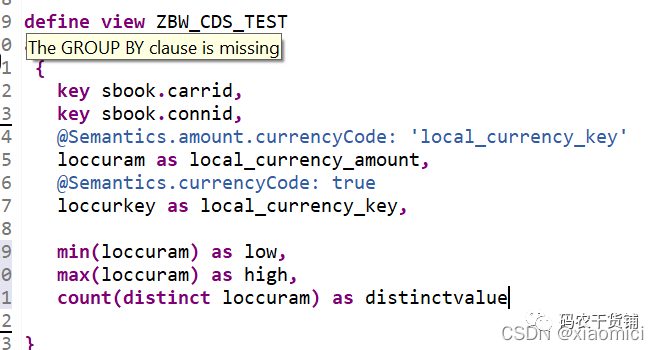
只要你没用aggregation的,都会给你加在group by后面。
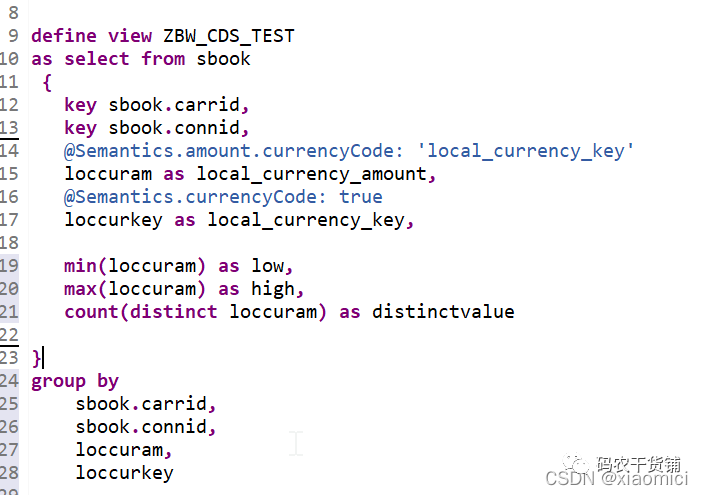
having这样用:它就是用来限制group by返回值的。

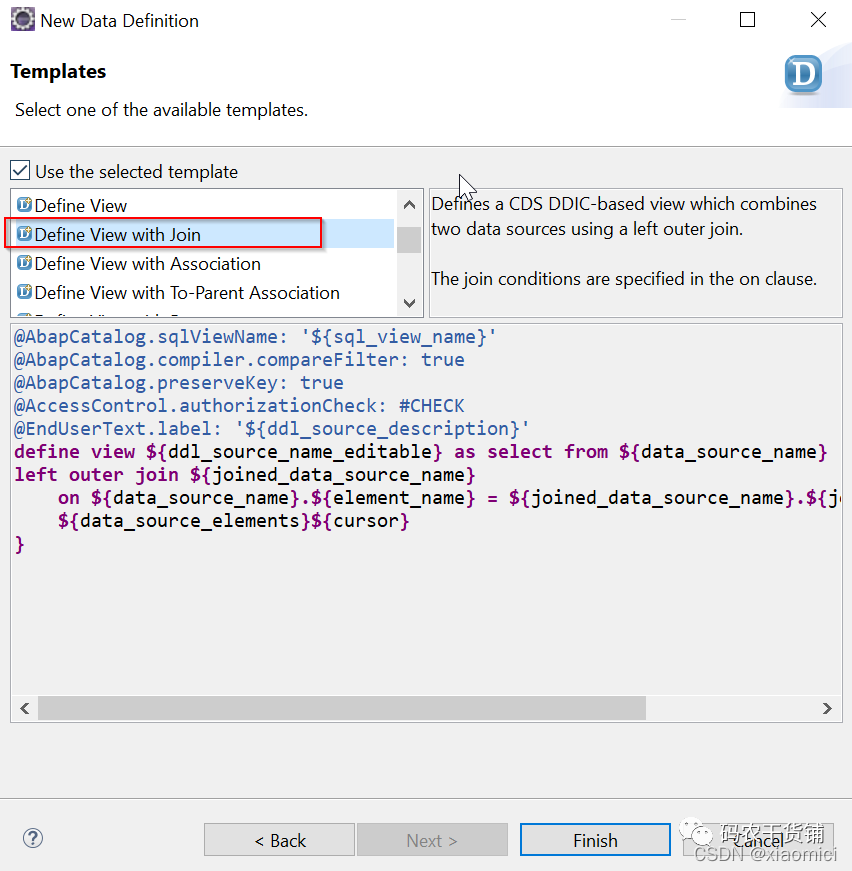
3.7 Join
对于Join有三种:内连,左外,右外。
这里有个要注意的点。
在ABAP的open SQL语法里,join是在字段后面。select A.a B.b from A inner join B on A.a = B.a
在eclipse里面我们是要把join放到字段选择之前,这样ADT语法编译可以自动帮我们补全查找错误之类的。
在CDS view里面用join的话,是不能用select *的。
Inner Join
Left Outer Join
Right Outer Join
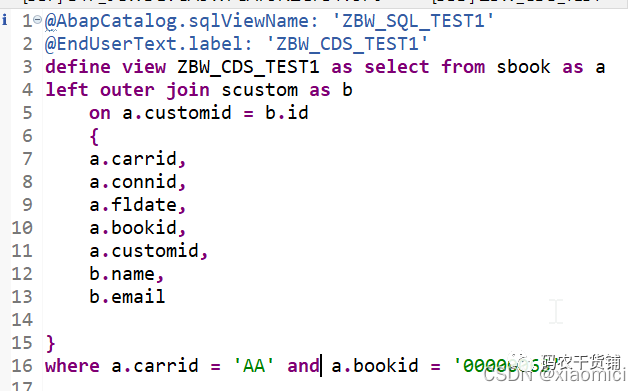
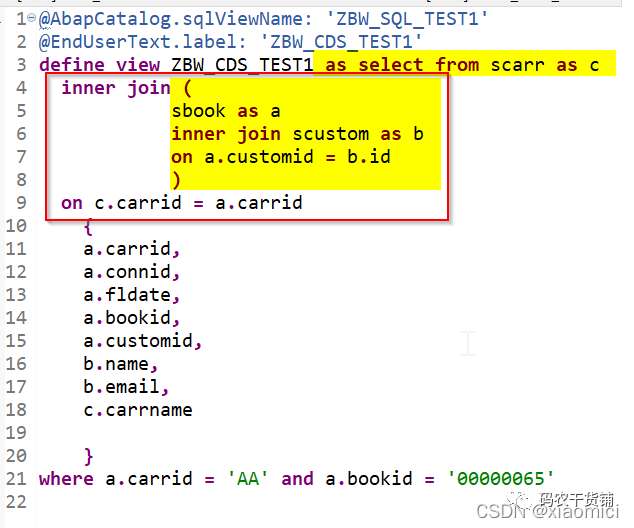
嵌套Join也是可以的,直接在第一个select from 后面添加要嵌套的join,然后加括号把已经有的join放进去。
这个join执行的时候会先执行括号里的join,然后把括号里join之后的结果作为外面的join的内容:
3.8 Union
在Union里面其实还有个Union ALL
这两个区别是:
Union不包含重复的行
Union ALL有可能包含重复行
在去Union的时候,有很多前提:
你union的表要有相同的字段个数。
在相同位置的字段,字段类型得能兼容
相同位置的字段名或者别名要相同
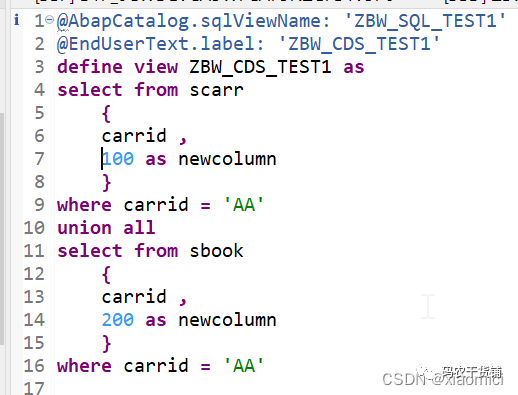
union all就是所有
另外,如果两个表的字段名不同,那就用个别名搞成一样的。
3.9 参数
也就是说给CDS View里面加个参数,CDS里面的参数是强制的。现在还没可选。你只要设置了参数,那就得输入。
参数就很简单了。
你要在一开始定义。
然后再在不同的地方调用。
直接看个例子: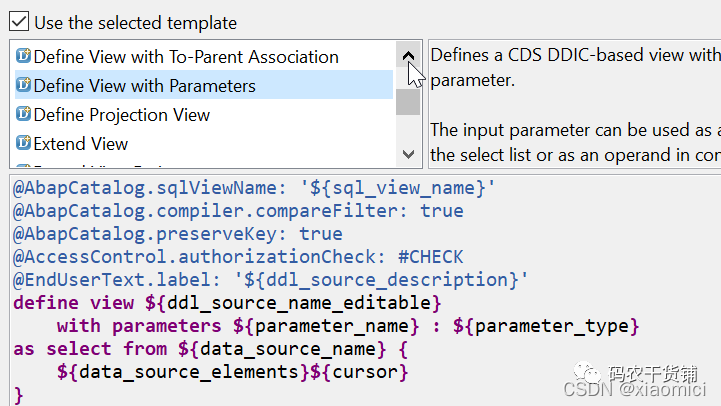
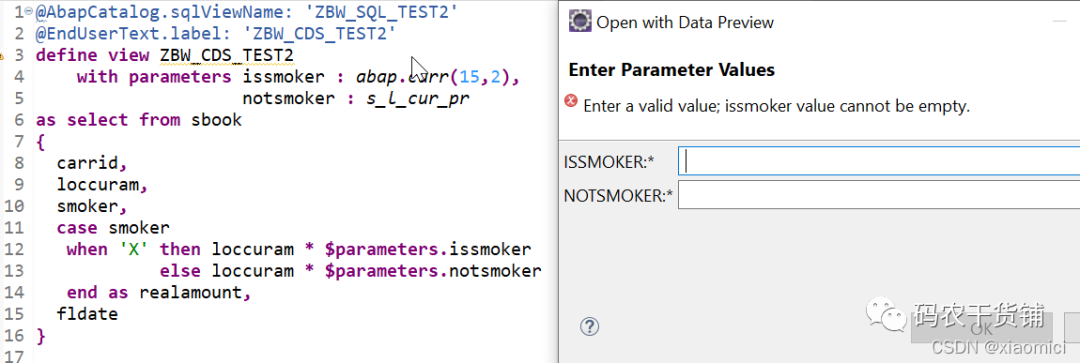
以上参数,给类型的时候,可以参照数据元素,或者是给个预定义的类型。
调用的时候要用$parameters。或者是前面加:调用。
但是最好是用第一种,因为ADT可以识别帮助。

直接定义和调用参数时,参数是必须输入的。
如果你借用系统数据,那就可以不必须输入。
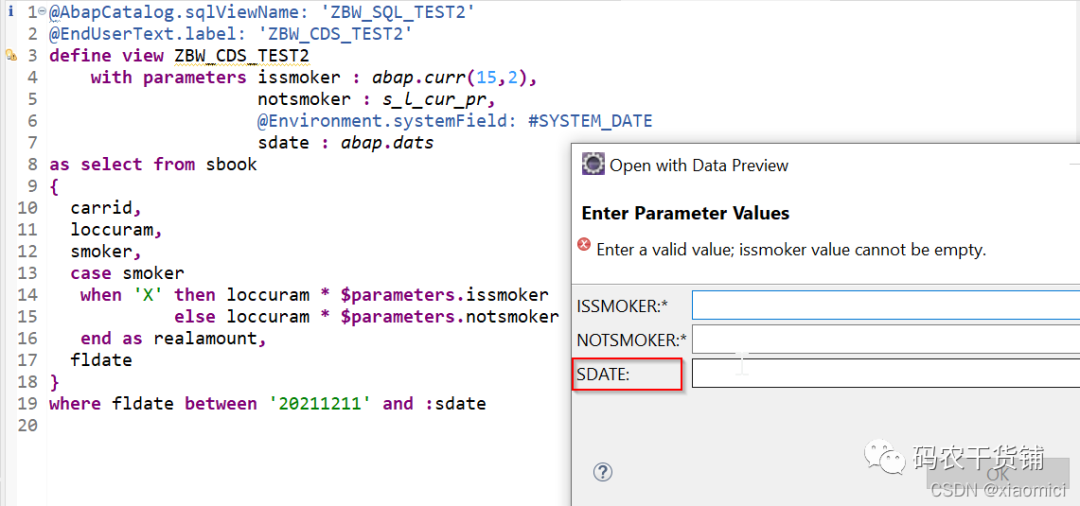
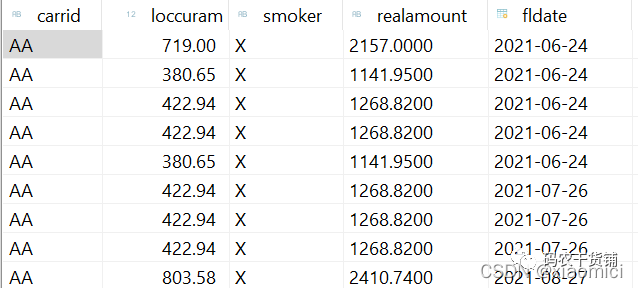
比如下面这个,借用系统日期,需要加个注解的:
因为注解传递系统日期给参数sdate,所以无论你输不输这个参数,它都会填系统当前日期。
参数调用的地方多种多样,你可以用在case里,也可以用在where里,having里等等。
3.10 作为子CDS View
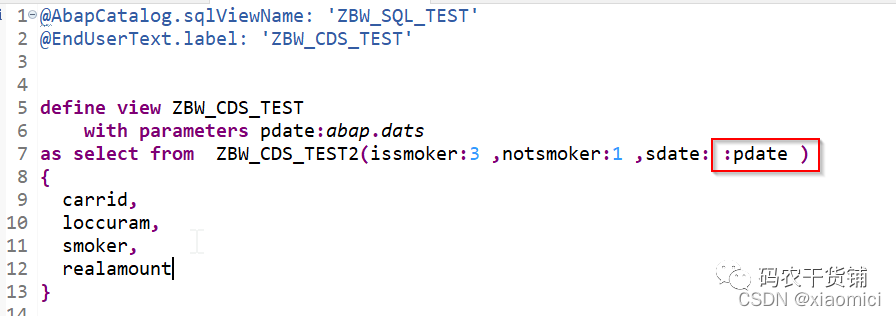
如果你要用已经存在的CDS view就很简单。就像用表一样。
如果这个要用到的CDS View有参数,那么用到的时候要把参数值直接给上,还要跟它本身参数定义顺序一致。
如果你有的参数是和外面的CDS View用的参数一样,那你去调用外面的CDS参数要给:或者$parameters
在CDS View里面。
当然作为view也是可以在ABAP 程序里面调用的。
就是现在用新的OPEN SQL的语法。有些许不一样。
在ABAP 程序里调用有参数的CDS View:坑待填.
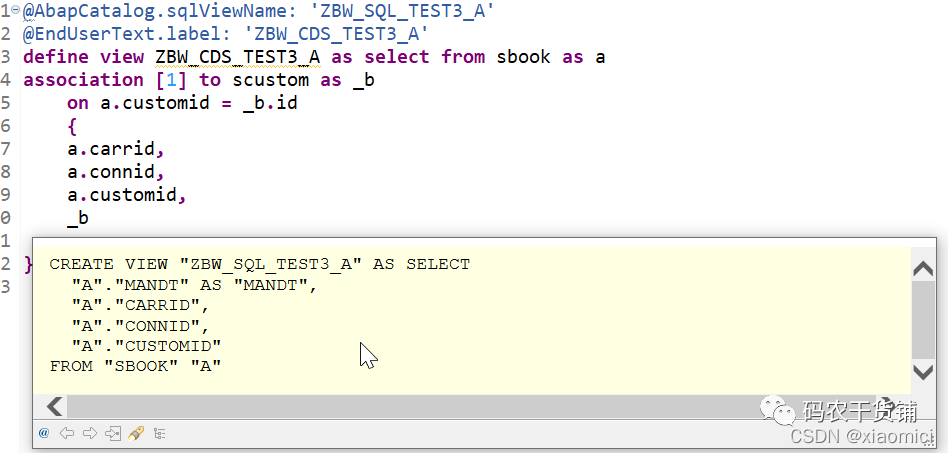
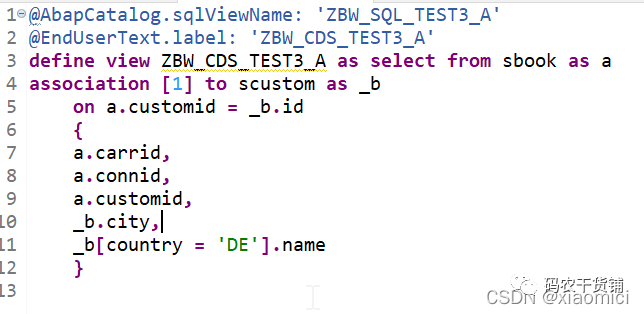
3.11 CDS View中的association关联
association 关联在数据库后台的表示和join没啥区别。
它可以提供一些简便的写法,还有加上基数。但是实际执行起来就是个join。
关联分三种:
Ad-hoc association: 定点关联,就是关联另外一个表或视图的一个或几个字段
exposed association: 全部关联,就是关联别人的整个表或者视图(前提条件是你这个关联的所有用来join的字段,都要展示在新定义的view里面)而且只有你这个整个表的字段真被用到了,才会在后台建View,不然后台是不会建的。
这个就和HANA里面的view有点像了,left outer join里面有一种情况是on demand,也就是只有你真用到了右表的数据,人家才会给你创建view,如果你搞半天只用到了左表的数据,他是不会给你建view的。
filtered associations: 就是关联里面加了个过滤,只是写法有些不一样。
一般被关联的要名字前加_前短横。这样规定呢,估计是为了看着方便。
association后面会有中括号[0…1]这种就是映射基数。也就是说对于customid在_b中最少有0个,最多有1个对应的id。
最左边是最小对应,最后边是最大对应[1…*] *是无穷大。
如果缺省[1]就是把最小的0给省略了。
这种右键看SQL creation
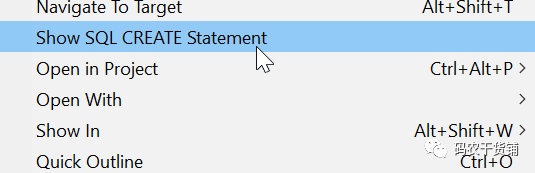
一下就能看出来CDS view的association和open SQL的区别了。除了语法上的区别,基本和join没区别。
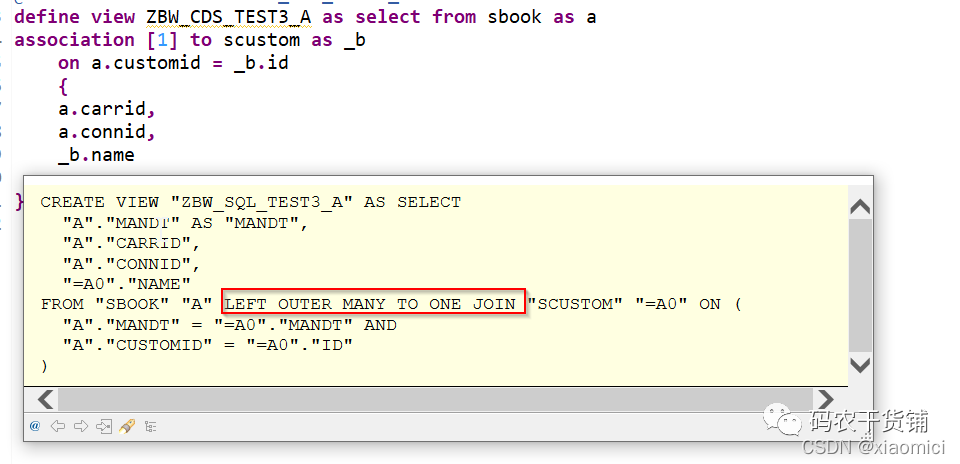
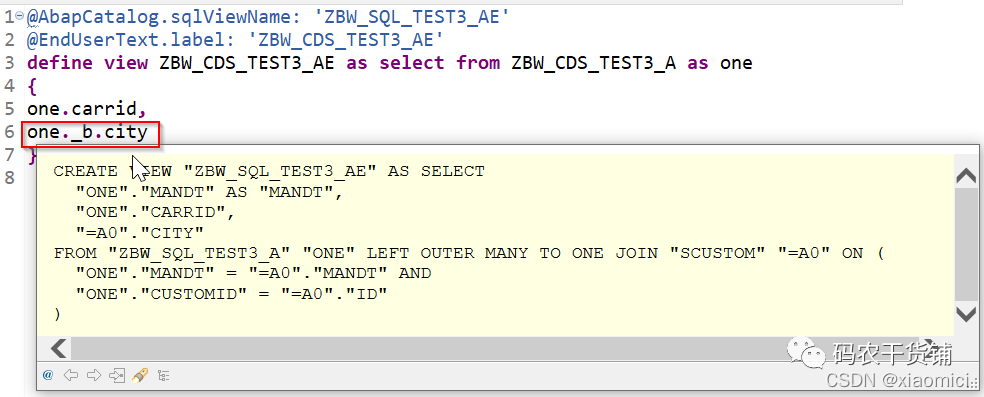
下面去写全部关联:
如果这样写就错了。为啥呢,因为人家说了,全部关联的话,你的join的字段也要在view视图里。
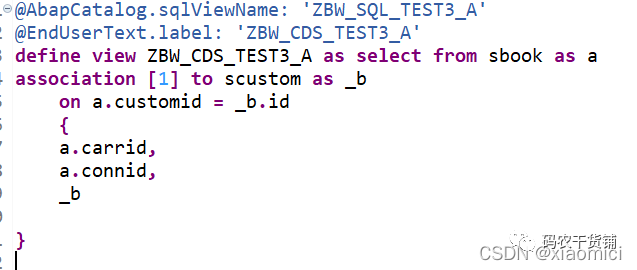
所以要改成这样:
最终创建只有连接的左表,只有你真实用到右表数据才会创建view。
啥个意思呢?比如你再去建一个view,用到这个包含全部连接的view。然后用到全部连接的右表的字段。才会生成前面这个view。不用不生成。
用的时候,别忘了加全部连接的右表的名字:也就是._b这个叫做路径表达式。
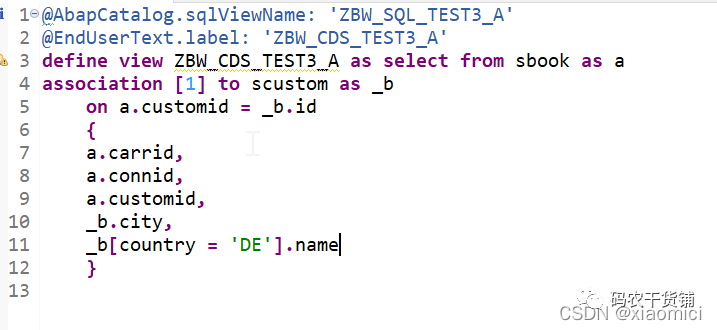
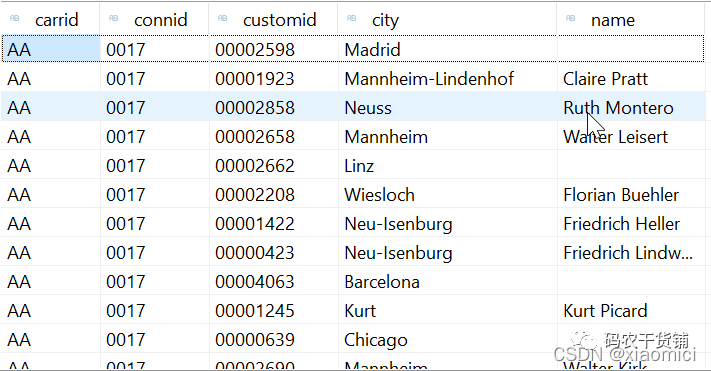
过滤关联就是字段里面给个过滤,这个过滤啥意思呢?
就是这个name,只有country=DE的时候才给name,其他时候是空值。
过滤只作用于这个name字段。过滤的写在中括号里。
在ABAP 程序里调用有关联的CDS View:坑待填.
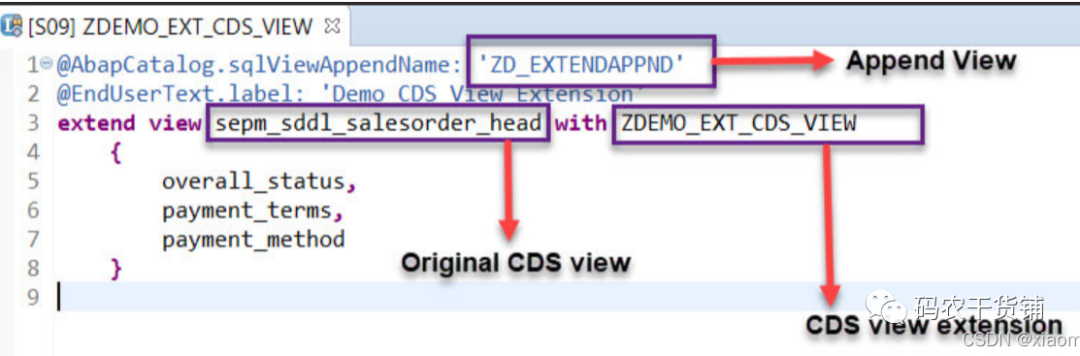
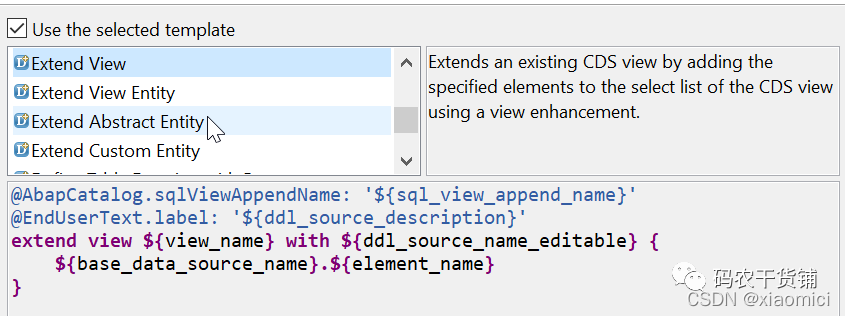
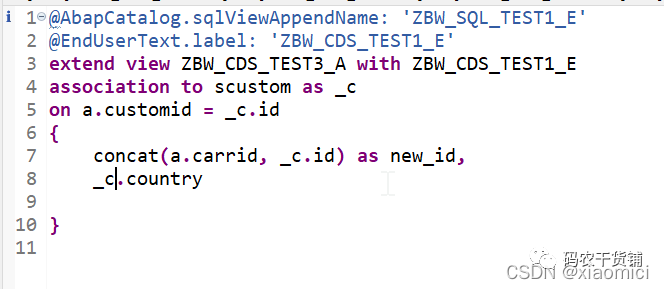
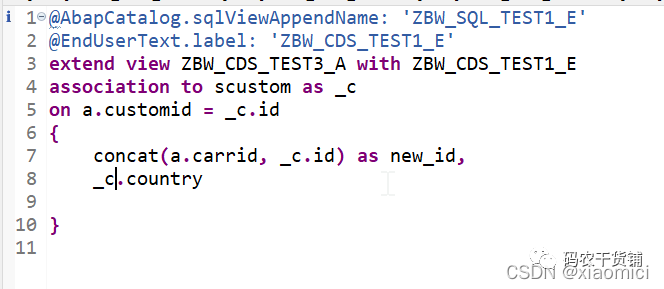
3.12 扩展CDS View
就是给CDS View来个append。但是这里涉及到一些注解。
注解里可以说给这个append一个带union的,带参数的等等的view。
扩展了之后这个新view就是7列。
去看它的SQLview,有个append。不一样的是,如果你去append一个数据字典表,那么有命名规则是ZZ或YY开头的字段,这里没有规定。
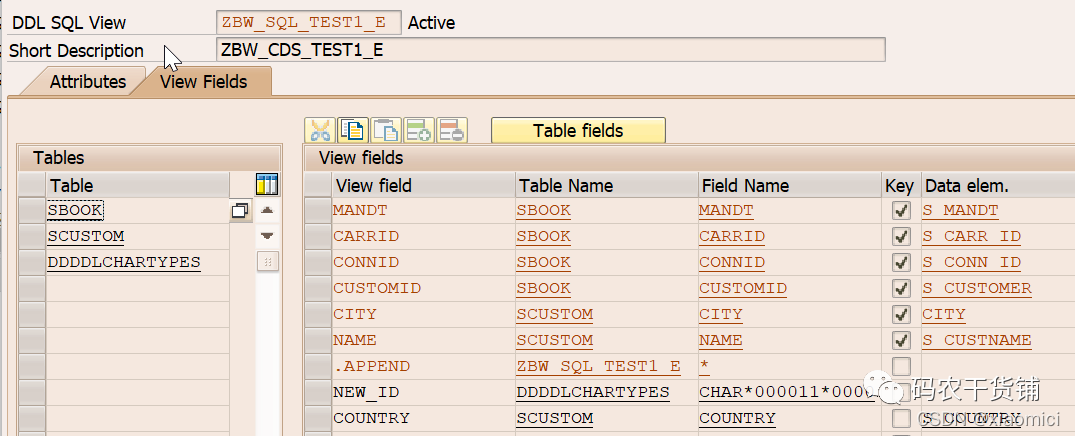
回到被extend的view能看到个小圈圈,表示被扩展了。我下图有个警告,实际上是个像箭靶的小圈圈。

3.13 CDS权限
权限管理这是个比较大的话题。
但是这里只讲简单的CDS View的权限管理。
一般在BW里面,权限管理通过权限相关对象,权限profile,到角色,再到用户。
而在ABAP里面,传统的权限控制是这样的:
loop at lt_tab into ls_tab.
authority-check object 'ZS_carrid'
ID 'CARRID' FIELD ls_tab-carrid
ID 'ACTVT' FIELD '03'.
if sy-subrc <> 0.
delete lt_tab index sy-tabix.
endif.
endloop.这种要从数据库先大量查找,然后删除。
但是现在我们是代码下推到数据库层,也就是只有需要的数据量才会被带到application server层。所以原先的逻辑就变了。
现在是咋了呢?
就是直接在一个CDS view上建一个DCL的role,即时权限控制。我控制你到这个CDS View的权限,只能看这个CDS View里面的哪些哪些数据。
但是有一点就是,我觉得是个bug。如果我从open SQL直接访问这个CDS View那么权限控制是有用的。如果我从其他的CDS View来访问这个CDS View那么在这个CDS View上面的权限控制就不起作用了。
关键字就是 define role, grant select on,等等
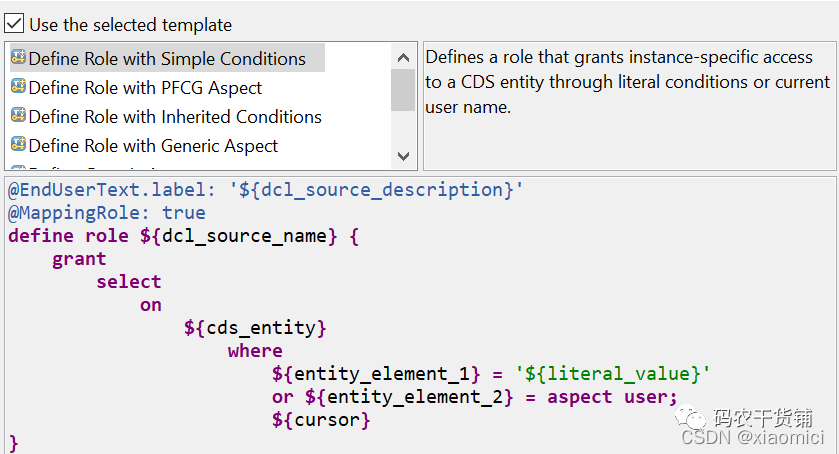
这边你建了role,那么CDS View里面就可以给一个注解了:

那么要讲建role。哎,这也是个大话题。反正在BW里面能牵扯到很多。
不过先简单来看看,从SU21开始。先建一个权限对象。
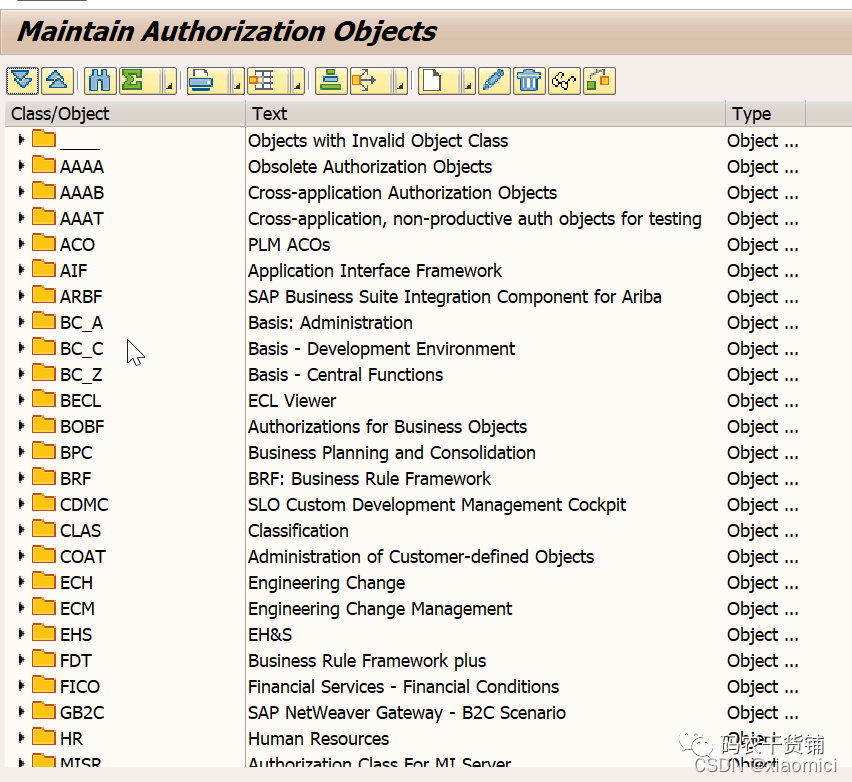
class相当于文件夹,文件夹里面有权限对象,权限对象里面有权限字段。这个所有组成了SAP_ALL这个profile。
如果你建了一个新对象,给了SAP_ALL这个profile,那他就有所有的权限对象的权限了。
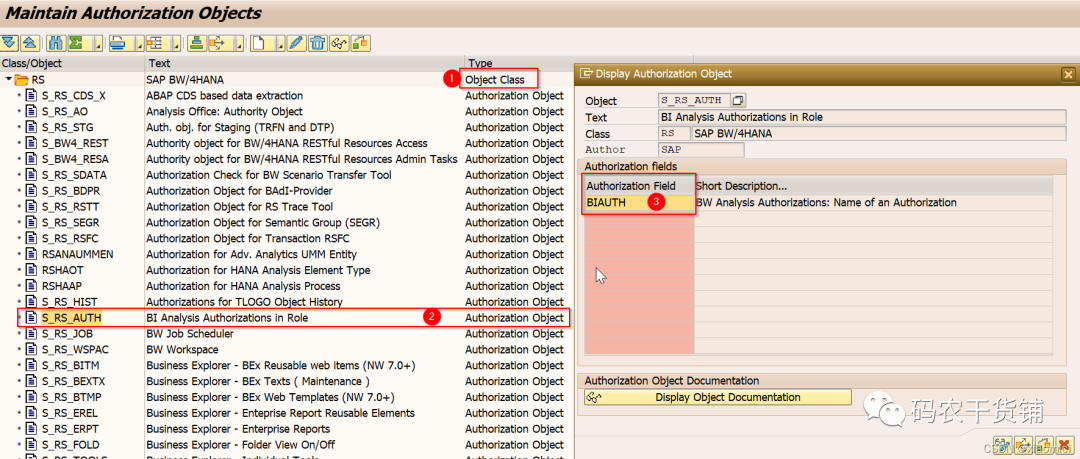
也就是常见的role下面的权限对象和权限字段。

再往权限字段里面填值,就是它允许的用来限制权限的值了。
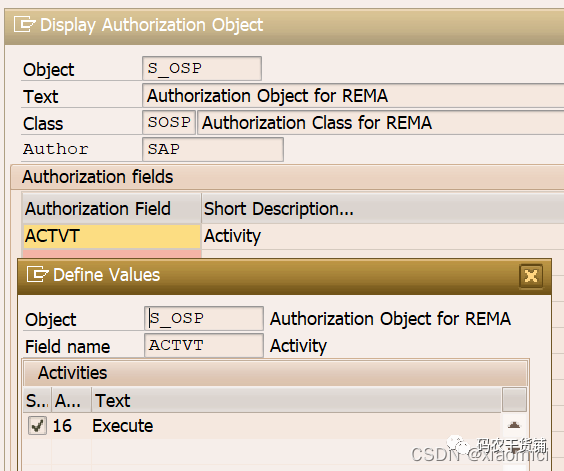
建了role之后,要生成profile才有用啊。因为实际上是profile来控制的。有效方向盘的就是自建的role生成的profile。profile就是你的权限对象和权限字段及权限字段给的值得文档记录。

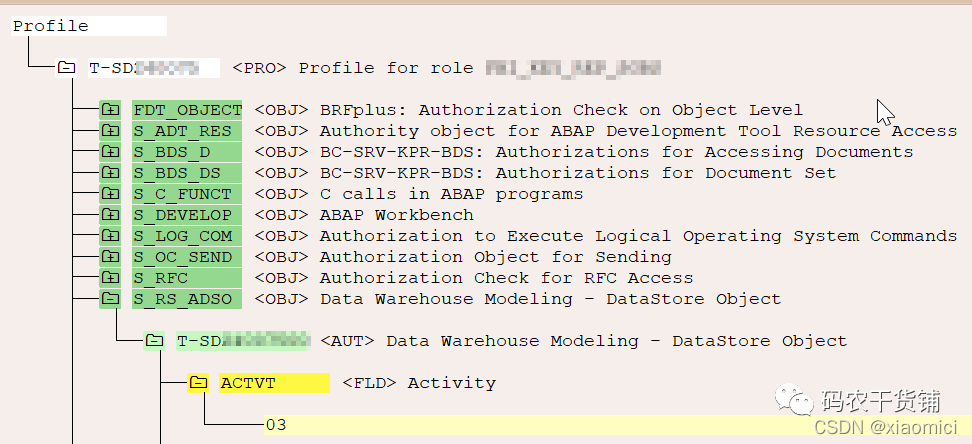
如果我们自己建也是可以的,就是在SU21下面建权限对象class,然后建权限对象,然后填入你的权限字段。最后填允许的值。
再接着呢,就给它加到role里面。再赋给用户。生成role的时候必须生成profile,也就是把profile给了用户。
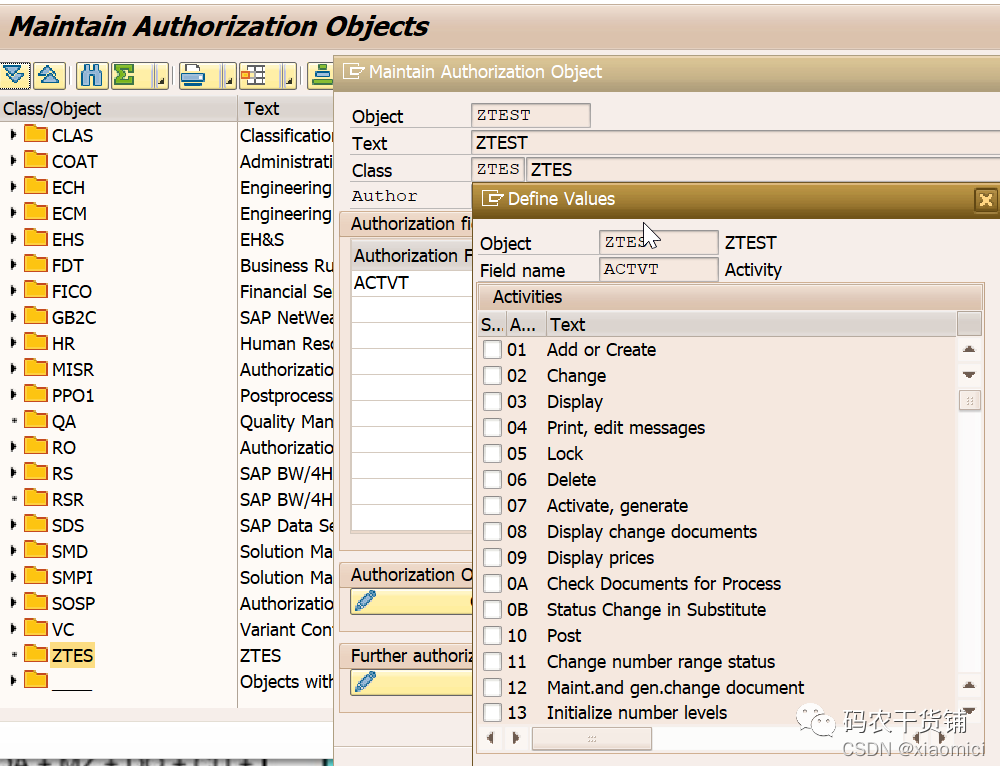
这个就是简单的给权限字段限制。
比如你在这里设置CDS View的权限相关字段,那就给个比如CARRID这个字段。然后只给‘AA’的值。最后再建role,然后赋给用户。
到此并没有结束:
还要建个CDS Access Control
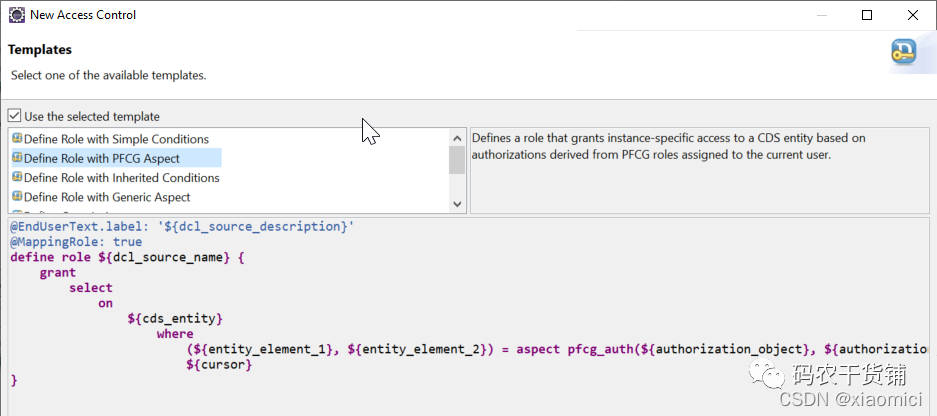
这下等你去在ABAP 程序里跑CDS View的时候就只能跑你限定的值。以上是个例子,carrid是你建的权限对象里的字段(同时是CDSView里面想要限定的值),并且在role里面给值。
————————————————
版权声明:本文为CSDN博主「xiaomici」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45689053/article/details/121907077
推荐阅读:
《ABAP新语法1》
《关于 SM30/VIEW_MAINTENANCE_CALL锁整张表问题》
《使用cl_gui_docking_container 实现多ALV》
《DEMO:S/4 1809 FAGLL03H 增加字段增强》
《几个ABAP实用模板,体力活就别一行行敲了,复制粘贴得了》
《SAP Parallel Accounting(平行分类账业务)配置+操作手册+BAPI demo程序》
《CC02修改确认日期BAPI:Processing of change number was canceled》《我是怎样调试BAPI的,以F-02为例》
《苏州游记》
《杂谈:几种接口》
《RESTful DEMO 一:SAP 如何提供 RESTful Web 服务》
《DEMO search help 增强 ( vl03n KO03 等)》
Debug 系列















 2855
2855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









