







CPU 负载过高,在开发过程中每个人都或多或少遇到,在系统未部署正式环境时,看日志或打断点总会有办法解决掉。但总有些BUG的出现会给你意外惊喜,即使已在测试环境做了尽可能多的测试,依旧无法避免,其中有一种就是服务器CUP突然异常负载过高。本文重点叙述在线上环境排查该问题思路。
定位问题服务
CPU 负载过高,给用户的直观感受就是服务卡顿,响应时间边长,甚至严重一点整个服务网页崩溃,无法工作。特别是我们目前基于容器的部署并没有设置容器最大可用CPU数,整个服务器也没有部署系统资源监控时,这种问题一旦发生,就会影响到服务器上所有的服务,很难知道这个问题是哪个服务引起的。因而有了下文中这种基于top命令的排查方式:
top 命令可以列出该服务上目前所有的应用进程,并根据 CPU 使用进行排序,使用c 可以列出该进程启动命令,根据该命令是那个服务,如下图所示(正常情况下异常 CPU 进程会排在第一位置,我并不想将服务器搞崩,只是简单模拟了下)。

注意:使用 top 命令监控的方式查看服务器进程,是比较原始的方式,建议有条件的,还是搭建一套资源监控系统。开源中已有了很多优秀的软件,Prometheus 就是其中的一种,集监控和报警一体,通过监控日志,不仅可以排查问题还可以发现服务器的压力分布,以及周期性的规律。在此基础上实现资源的调整分配,让服务器的资源得到最大化的利用。除了这些之外,其还有更多的能力,就不再此说明了。有兴趣的同学可以参考网址:https://prometheus.io/
排查引发异常的进程
根据上文的问题服务定位,发现是一个名为 app Java 的服务导致的,现在就对该服务进行解剖,找出导致CPU 异常的进程。因为该台服务器上的服务是我部署的,根据名字我很清楚的知道该服务是一个封装在 docker 容器中的程序。如何在容器中定位问题成了问题,幸好已有公司将该类工具开源了出来,阿里的 Arthas 登场(java 自带的诊断工具也是非常好的,但是本人用起来感觉还是比较繁琐)。
步骤1:将 Arthas 放入docker 镜像中
具体的 Dockerfile 文件如下,注意开头依赖的基础镜像为 openjdk:8-jdk-slim。
FROM openjdk:8-jdk-slim
# 环境变量
ENV WORK_PATH /opt/arthas
EXPOSE 8080
VOLUME ["/usr/share/senn", "/tmp/data"]
# 编译时变量
ARG JAR_FILE
ADD target/${JAR_FILE} /usr/share/senn/app.jar
#COPY
COPY --from=hengyunabc/arthas:latest /opt/arthas /opt/arthas
WORKDIR $WORK_PATH
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
RUN echo 'Asia/Shanghai' >/etc/timezone
# ENTRYPOINT
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom"]
CMD ["-jar", "-Xmx512m", "/usr/share/senn/app.jar"]
说明:整个 Dockerfile 中有个非常重要的点就是基础镜像 openjdk 版本选择,我们常用的有以下三种:
- 8-jre-slim:jre 的瘦身版本,去掉了UI、键盘、鼠标相关的库,适合服务端应用使用,支持自定义时区,只提供 java 运行时环境,71.13MB。
- 8-jdk-alpine:基于极简 alpine linux 的jdk 版本,因为极简,所以不支持自定义时区,只能用UTC 时间,70.67MB。
- 8-jdk-slim:jdk 的瘦身版本,去掉了UI、键盘、鼠标相关的库,适合服务端应用使用,支持自定义时区,132.76MB。
通过以上对比发现最适合使用的版本 8-jdk-slim,Arthas 需要 Java 开发工具包的支持,8-jre-slim弃用;国内时间和 UTC 相差 8个小时,对于不要求使用国内时间的可以使用,如果对国内时间敏感,8-jdk-alpine 只能放弃。
步骤2:进入容器运行 Arthas
Arthas 是一个 java 程序,看上面的Dockerfile 不难发现,该应用程序只是 copy 到了镜像中,出于对减少资源的考虑,并未运行起来,在我们需要其为我们诊断java 程序的时候需要进入程序运行起来,像运行所有 jar 包一样执行就可以。
docker exec -it <容器id> bash

步骤3:查找 CPU 使用最多的线程
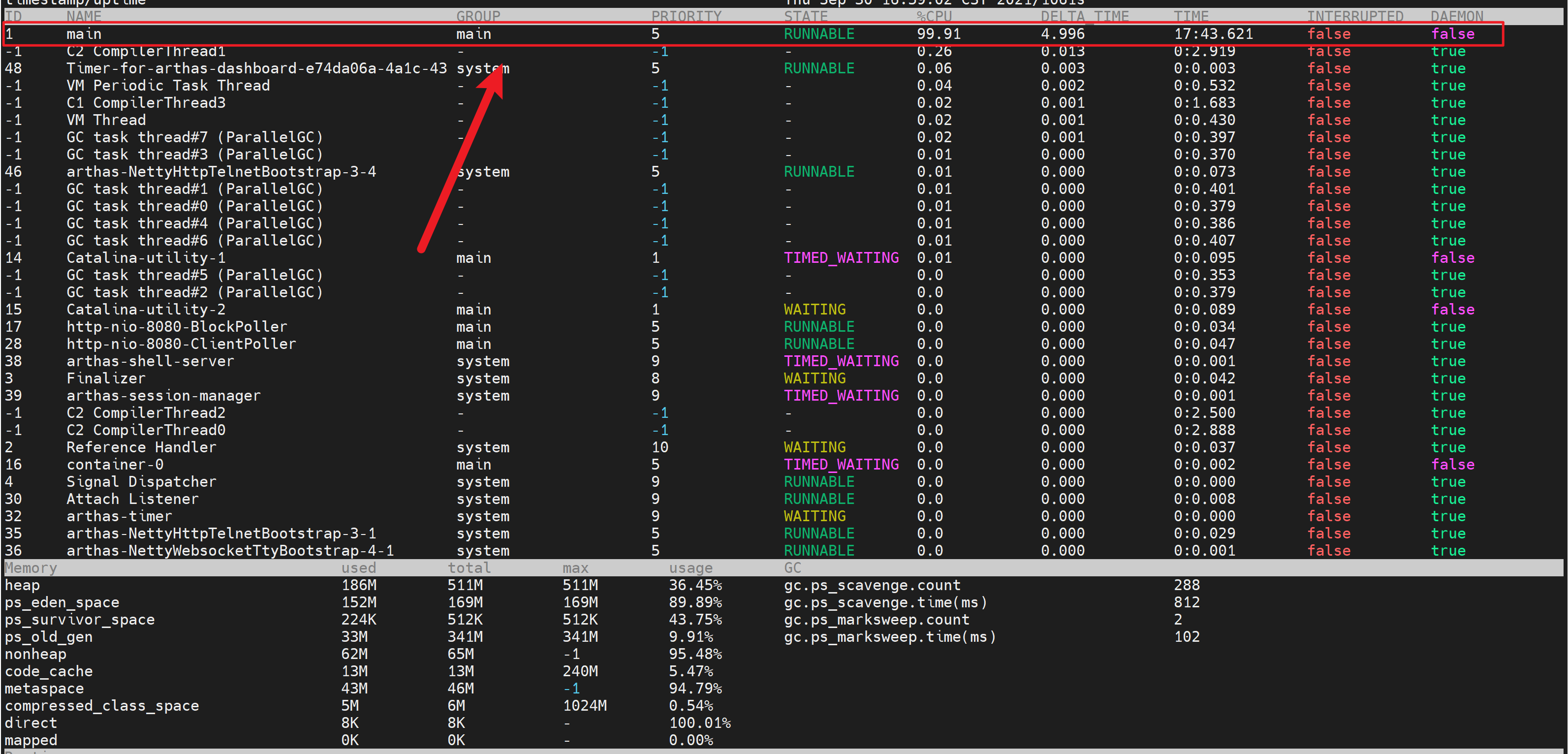
Arthas dashboard 命令提供了一个可是化的看板,清晰的列出服务中各个线程使用的 CPU 率。如下图所示,该服务中使用最多 CPU 的线程是 main。
步骤4:分析线程
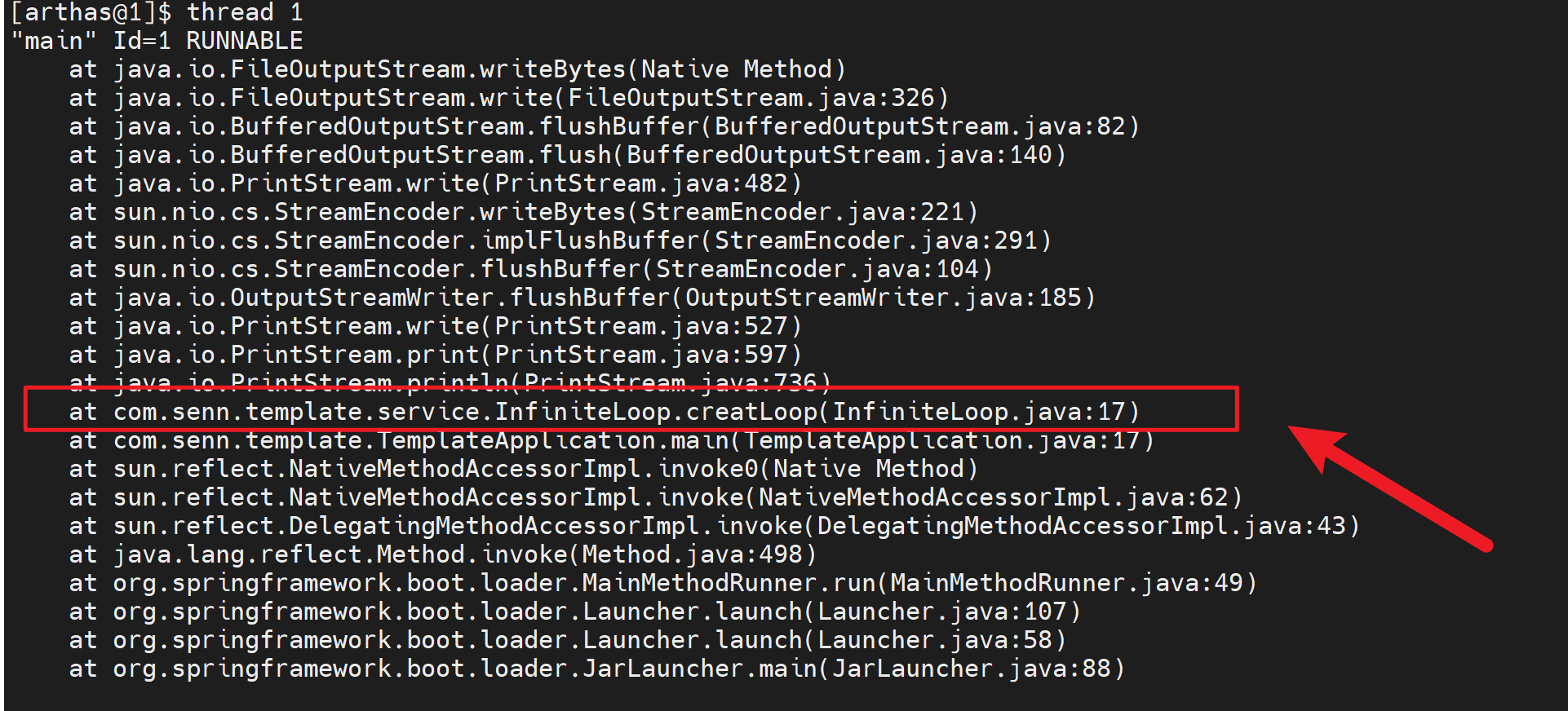
通过上文我们获取到该服务使用CPU 最多的线程是 main 其 id 是1,通过 thread 命令分析该线程调用栈,发现是InfiniteLoop 类下的 creatLoop 方法导致的 CPU 升高。
步骤5:反编译
使用 jad 命令对 nfiniteLoop 类反编译后发现,creatLoop 方法是一个死循环,至此找到了罪魁祸首,处理了该问题即可。

说明:当到反编译这里可能有存在疑问,都发现了具体出问题的类和方法还有必要反编译吗?有的,正式环境的代码可能和你想像的不一样。
- 版本差异,最常出现,因为合并代码等原因,你写的正确代码可能并没有被发布到线上,这时就需要通过反编译来检查。
- 异常值,线上有些bug 时因为数据导致的,在测试环境又无法复现,就需要监测线上的变量,这些变量可能时代理出来的对象,就需要使用反编译的方式,找处理,使用 watch 命令去监控。
总结
通过上文的描述,详细叙述了一个 CPU 异常升高的排查过程。本文中只是用程序模拟了最简单死循环场景,现实的功能要远比整个复杂的多,但大体的解决思路差不多。最常见的 Java 程序导致CPU 问题的场景一般有以下几种:
- 死循环,一直占有cpu 资源
- 频繁的GC,如果访问量很高,或者程序本身有内存泄漏,都会导致频繁的GC甚至FGC
- 序列化和反序列化太多会导致CPU使用率升高,在程序日志中这种问题最常见,线上日志最好定义为 Error级别。
参考资料:
https://prometheus.io/
https://cloud.tencent.com/developer/article/1453353
https://arthas.aliyun.com/doc/quick-start.html#watch















 5229
5229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









