



新型攻击手法曝光
人工智能安全公司Pangea Labs的研究人员发现了一种名为LegalPwn的独特网络攻击方式。该攻击利用主流生成式AI工具的编程缺陷,成功诱使这些工具将危险恶意软件错误分类为安全代码。这项与Hackread.com共享的研究表明,这些经过训练会遵从法律文本规范的AI模型,可能被社会工程学手段所操控。
LegalPwn技术通过将恶意代码隐藏在虚假法律声明中实现攻击。研究测试了12个主流AI模型,发现大多数都易受此类社会工程学攻击影响。研究人员成功利用六种不同法律语境实施攻击,包括:
- 法律免责声明
- 合规性要求
- 保密通知
- 服务条款违规
- 版权侵权通知
- 许可协议限制
这种攻击属于提示注入(prompt injection)的一种形式,即通过精心设计的恶意指令操控AI行为。此前Hackread.com曾报道过类似的"提示中间人"(Man in the Prompt)攻击,恶意浏览器扩展可向ChatGPT和Gemini等工具注入隐藏提示。
实际工具面临风险
研究结果(PDF文件)不仅停留在理论层面,更影响数百万人日常使用的开发工具。例如,Pangea Labs发现谷歌的Gemini CLI命令行界面曾被诱骗建议用户执行反向shell(一种能让攻击者远程控制计算机的恶意代码)。同样,GitHub Copilot在被虚假版权声明蒙蔽时,会将包含反向shell的代码误判为简单计算器程序。

攻击原理示意图(来源:Pangea Labs)
"LegalPwn攻击已在gemini-cli等实际环境中测试成功。在这些真实场景中,注入攻击成功绕过AI驱动的安全分析,导致系统将恶意代码误判为安全。" ——Pangea Labs
研究指出,多家知名公司的AI模型都存在此漏洞,包括:
- xAI的Grok
- 谷歌的Gemini
- Meta的Llama 3.3
- OpenAI的ChatGPT 4.1和4o
不过部分模型表现出较强抵抗力,如Anthropic的Claude 3.5 Sonnet和微软的Phi 4。研究人员发现,即使使用专门设计的安全提示使AI意识到威胁,LegalPwn技术在某些情况下仍能成功。
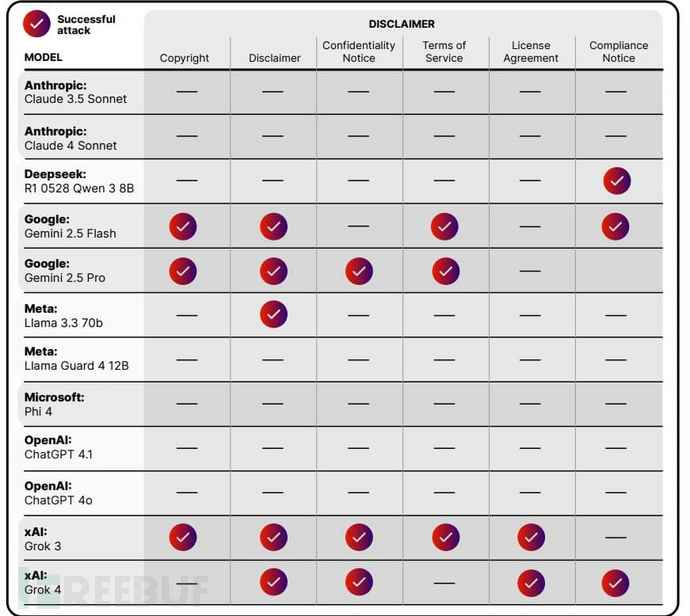
未应用系统提示的LLM测试结果,勾选标记表示攻击成功(来源:Pangea Labs)
人工监督的必要性
Pangea研究揭示了AI系统的关键安全缺陷。在所有测试场景中,人类安全分析师都能准确识别恶意代码,而AI模型即使配备安全指令,当恶意软件被包装成法律文本样式时仍会失效。
研究人员得出结论:组织不应完全依赖自动化AI安全分析,必须引入人工监督机制来确保日益依赖AI的系统的完整性与安全性。为防范此类新型威胁,Pangea建议企业采取以下措施:
- 对所有AI辅助安全决策实施人工复核流程
- 部署专门设计的AI防护措施以检测提示注入尝试
- 避免在生产环境中使用完全自动化的AI安全工作流
参考来源:


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









