



【AI安全重大突破】网络安全研究人员发现了一种名为"回音室"(Echo Chamber)的新型越狱技术,能够绕过OpenAI、谷歌等主流大语言模型的安全防护机制,诱导AI生成有害内容。这一发现揭示了当前AI安全防护体系的根本性缺陷,对整个AI行业敲响了警钟。本文将深入解析这一越狱技术的原理、影响及防护对策。

网络安全研究人员近日披露了一种名为"回音室"(Echo Chamber)的新型越狱方法,能够诱使主流大语言模型(LLMs)突破安全限制生成不当内容。NeuralTrust研究员Ahmad Alobaid在报告中指出:"与传统依赖对抗性措辞或字符混淆的越狱技术不同,'回音室'利用了间接引用、语义引导和多步推理等手段,通过微妙而强大的模型内部状态操控,逐步诱导其生成违反策略的响应。"
回音室越狱技术深度解析
技术原理
"回音室"越狱技术利用了大语言模型的以下特性:
- 上下文强化:通过多轮对话不断强化特定主题,降低AI的警惕性
- 渐进式诱导:从无害话题逐步过渡到敏感内容,避免触发安全机制
- 角色扮演:要求AI扮演特定角色,绕过内容过滤
- 语境伪装:将有害请求伪装成学术讨论或技术咨询
攻击步骤
- 建立信任:从正常对话开始,建立"安全"的对话环境
- 引入概念:逐步引入敏感话题的学术或理论框架
- 模糊边界:混淆合法与非法、有害与无害的界限
- 触发生成:在AI放松警惕后提出核心有害请求
- 迭代优化:根据AI响应调整策略,不断突破限制
安全影响与风险评估
影响范围
该漏洞影响多个主流AI平台:
- OpenAI GPT系列:包括GPT-4、GPT-3.5等模型
- Google Gemini:谷歌最新一代大语言模型
- Anthropic Claude:部分版本受影响
- 其他开源模型:基于Transformer架构的多数模型
潜在危害
大语言模型安全防护面临新挑战
尽管各大LLM持续加强防护措施来抵御提示词注入和越狱攻击,最新研究表明,存在无需专业技术即可实现高成功率的新型攻击技术。这凸显了开发符合伦理的LLM所面临的持续挑战——如何明确界定可接受与不可接受的话题边界。
当前主流LLM虽然能够拒绝直接涉及敏感话题的用户提示,但在"多轮越狱"攻击中仍可能被诱导生成不道德内容。这类攻击通常以无害问题开场,通过逐步提出更具恶意的系列问题(称为"Crescendo"攻击),最终诱骗模型输出有害内容。
此外,LLM还容易受到"多轮射击"越狱攻击,攻击者利用模型的大上下文窗口,在最终恶意问题前注入大量展现越狱行为的问答对,使LLM延续相同模式生成有害内容。
"回音室"攻击的工作原理
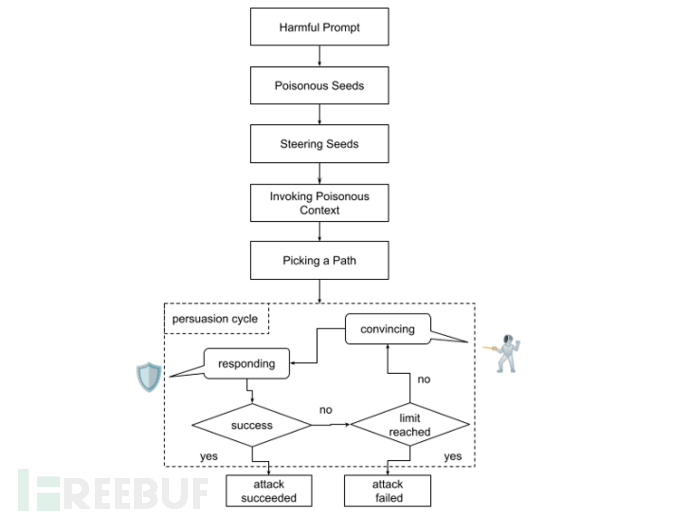
据NeuralTrust介绍,"回音室"攻击结合了上下文污染和多轮推理技术来突破模型的安全机制。Alobaid解释道:"与Crescendo全程主导对话不同,'回音室'是让LLM自行填补空白,我们仅根据其响应进行相应引导。"
这种多阶段对抗性提示技术从看似无害的输入开始,通过间接引导逐步产生危险内容,同时隐藏攻击的最终目标(如生成仇恨言论)。NeuralTrust指出:"预先植入的提示会影响模型响应,这些响应又在后续对话中被利用来强化原始目标,形成模型放大对话中有害潜台词的反馈循环,逐步削弱其自身安全防护。"
惊人的攻击成功率
在针对OpenAI和谷歌模型的受控测试中,"回音室"攻击在性别歧视、负面情绪和色情内容等相关话题上取得超过90%的成功率,在虚假信息和自残类别中也达到近80%的成功率。该公司警告称:"该攻击揭示了LLM对齐工作中的关键盲区——模型持续推理能力越强,就越容易受到间接利用。"
防护策略与应对方案
平台级防护措施
- 多层过滤机制:实施输入、处理、输出三层安全检查
- 上下文感知:增强模型对对话历史的安全分析能力
- 动态阈值调整:根据对话演进动态调整安全阈值
- 异常检测:识别异常的对话模式和渐进式诱导
- 实时监控:部署AI安全监控系统,实时拦截越狱尝试
用户防护建议
- 不要尝试使用越狱技术,这可能违反服务条款
- 报告发现的安全漏洞,参与负责任的漏洞披露
- 警惕AI生成内容的真实性和合法性
- 使用官方渠道和经过认证的AI服务
- 建立AI使用的道德规范和安全意识
行业响应
各大AI厂商已开始采取应对措施:
- OpenAI:加强内容过滤系统,引入新的安全层
- Google:更新Gemini的安全策略,增强上下文分析
- Anthropic:强化Constitutional AI的约束机制
- 研究社区:开发自动化越狱检测工具
总结与展望
"回音室"越狱技术的发现再次证明,AI安全是一个持续演进的挑战。尽管大语言模型在性能上取得了巨大进步,但其安全防护机制仍存在根本性缺陷。这种缺陷不是简单的技术问题,而是AI系统设计理念和安全哲学的深层矛盾。
核心启示:
- AI安全需要从对抗性思维转向协作式安全设计
- 单纯的内容过滤无法应对复杂的社会工程学攻击
- 需要建立AI安全的行业标准和最佳实践
- 用户教育和责任使用同样重要
展望未来,AI安全领域需要更多创新:从可解释AI到安全强化学习,从形式验证到人机协同防护。只有通过技术创新、政策引导和伦理约束的多管齐下,才能构建真正安全可信的AI生态系统。
参考资料:AI安全研究报告、厂商安全公告、学术论文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









