







Lab 1 系统软件启动过程
实验目的
操作系统是一个软件,也需要通过某种机制加载并运行它。在这里我们将通过另外一个更加简单的软件-bootloader来完成这些工作。为此,我们需要完成一个能够切换到x86的保护模式并显示字符的bootloader,为启动操作系统ucore做准备。lab1提供了一个非常小的bootloader和ucore OS,整个bootloader执行代码小于512个字节,这样才能放到硬盘的主引导扇区中。通过分析和实现这个bootloader和ucore OS,读者可以了解到:
- 计算机原理
- CPU的编址与寻址: 基于分段机制的内存管理
- CPU的中断机制
- 外设:串口/并口/CGA,时钟,硬盘
- Bootloader软件
- 编译运行bootloader的过程
- 调试bootloader的方法
- PC启动bootloader的过程
- ELF执行文件的格式和加载
- 外设访问:读硬盘,在CGA上显示字符串
- ucore OS软件
- 编译运行ucore OS的过程
- ucore OS的启动过程
- 调试ucore OS的方法
- 函数调用关系:在汇编级了解函数调用栈的结构和处理过程
- 中断管理:与软件相关的中断处理
- 外设管理:时钟
实验内容:
lab1中包含一个bootloader和一个OS。这个bootloader可以切换到X86保护模式,能够读磁盘并加载ELF执行文件格式,并显示字符。而这lab1中的OS只是一个可以处理时钟中断和显示字符的幼儿园级别OS。
练习:
练习1:理解通过make生成执行文件的过程。
列出本实验各练习中对应的OS原理的知识点,并说明本实验中的实现部分如何对应和体现了原理中的基本概念和关键知识点。
在此练习中,大家需要通过静态分析代码来了解:
1.1 操作系统镜像文件ucore.img是如何一步一步生成的?(需要比较详细地解释Makefile中每一条相关命令和命令参数的含义,以及说明命令导致的结果)
分析:首先使用make "V="可以了解make执行了哪些命令,通过分析make执行了那些命令就可以来分析Makefile中每一条相关命令和命令参数的含义
+ cc kern/init/init.c
gcc -Ikern/init/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/init/init.c -o obj/kern/init/init.o
kern/init/init.c:95:1: warning: ‘lab1_switch_test’ defined but not used [-Wunused-function]
+ cc kern/libs/readline.c
gcc -Ikern/libs/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/libs/readline.c -o obj/kern/libs/readline.o
+ cc kern/libs/stdio.c
gcc -Ikern/libs/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/libs/stdio.c -o obj/kern/libs/stdio.o
+ cc kern/debug/kdebug.c
gcc -Ikern/debug/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/debug/kdebug.c -o obj/kern/debug/kdebug.o
kern/debug/kdebug.c:251:1: warning: ‘read_eip’ defined but not used [-Wunused-function]
+ cc kern/debug/kmonitor.c
gcc -Ikern/debug/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/debug/kmonitor.c -o obj/kern/debug/kmonitor.o
+ cc kern/debug/panic.c
gcc -Ikern/debug/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/debug/panic.c -o obj/kern/debug/panic.o
kern/debug/panic.c: In function ‘__panic’:
kern/debug/panic.c:27:5: warning: implicit declaration of function ‘print_stackframe’ [-Wimplicit-function-declaration]
+ cc kern/driver/clock.c
gcc -Ikern/driver/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/clock.c -o obj/kern/driver/clock.o
+ cc kern/driver/console.c
gcc -Ikern/driver/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/console.c -o obj/kern/driver/console.o
+ cc kern/driver/intr.c
gcc -Ikern/driver/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/intr.c -o obj/kern/driver/intr.o
+ cc kern/driver/picirq.c
gcc -Ikern/driver/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/picirq.c -o obj/kern/driver/picirq.o
+ cc kern/trap/trap.c
gcc -Ikern/trap/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/trap.c -o obj/kern/trap/trap.o
kern/trap/trap.c:14:13: warning: ‘print_ticks’ defined but not used [-Wunused-function]
kern/trap/trap.c:30:26: warning: ‘idt_pd’ defined but not used [-Wunused-variable]
+ cc kern/trap/trapentry.S
gcc -Ikern/trap/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/trapentry.S -o obj/kern/trap/trapentry.o
+ cc kern/trap/vectors.S
gcc -Ikern/trap/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/vectors.S -o obj/kern/trap/vectors.o
+ cc kern/mm/pmm.c
gcc -Ikern/mm/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/mm/pmm.c -o obj/kern/mm/pmm.o
+ cc libs/printfmt.c
gcc -Ilibs/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -c libs/printfmt.c -o obj/libs/printfmt.o
+ cc libs/string.c
gcc -Ilibs/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -c libs/string.c -o obj/libs/string.o
+ ld bin/kernel
ld -m elf_i386 -nostdlib -T tools/kernel.ld -o bin/kernel obj/kern/init/init.o obj/kern/libs/readline.o obj/kern/libs/stdio.o obj/kern/debug/kdebug.o obj/kern/debug/kmonitor.o obj/kern/debug/panic.o obj/kern/driver/clock.o obj/kern/driver/console.o obj/kern/driver/intr.o obj/kern/driver/picirq.o obj/kern/trap/trap.o obj/kern/trap/trapentry.o obj/kern/trap/vectors.o obj/kern/mm/pmm.o obj/libs/printfmt.o obj/libs/string.o
+ cc boot/bootasm.S
gcc -Iboot/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Os -nostdinc -c boot/bootasm.S -o obj/boot/bootasm.o
+ cc boot/bootmain.c
gcc -Iboot/ -march=i686 -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Os -nostdinc -c boot/bootmain.c -o obj/boot/bootmain.o
+ cc tools/sign.c
gcc -Itools/ -g -Wall -O2 -c tools/sign.c -o obj/sign/tools/sign.o
gcc -g -Wall -O2 obj/sign/tools/sign.o -o bin/sign
+ ld bin/bootblock
ld -m elf_i386 -nostdlib -N -e start -Ttext 0x7C00 obj/boot/bootasm.o obj/boot/bootmain.o -o obj/bootblock.o
'obj/bootblock.out' size: 492 bytes
build 512 bytes boot sector: 'bin/bootblock' success!
dd if=/dev/zero of=bin/ucore.img count=10000
10000+0 records in
10000+0 records out
5120000 bytes (5.1 MB) copied, 0.0261621 s, 196 MB/s
dd if=bin/bootblock of=bin/ucore.img conv=notrunc
1+0 records in
1+0 records out
512 bytes (512 B) copied, 2.2322e-05 s, 22.9 MB/s
dd if=bin/kernel of=bin/ucore.img seek=1 conv=notrunc
146+1 records in
146+1 records out
74862 bytes (75 kB) copied, 0.000555262 s, 135 MB/s
通过对上述make执行出来的命令,我们可以发现上述的make主要做了以下几个部分:
-
第一个是针对每个 .c 文件编译出对应的 .o 文件,然后大家一起链接成 bin/kernel 文件。下述代码是几个可执行文件的链接过程:
ld -m elf_i386 -nostdlib -T tools/kernel.ld -o bin/kernel obj/kern/init/init.o obj/kern/libs/readline.o obj/kern/libs/stdio.o obj/kern/debug/kdebug.o obj/kern/debug/kmonitor.o obj/kern/debug/panic.o obj/kern/driver/clock.o obj/kern/driver/console.o obj/kern/driver/intr.o obj/kern/driver/picirq.o obj/kern/trap/trap.o obj/kern/trap/trapentry.o obj/kern/trap/vectors.o obj/kern/mm/pmm.o obj/libs/printfmt.o obj/libs/string.o -
第二个是对于 boot 部分的编译,几个 boot/ 目录下的文件汇编链接成 obj/bootblock.o 。
-
通过编译执行一个预先写好的 tools/sign.c 文件,读取整个 obj/bootblock.out ,判断文件大小是不是小于等于 510 ,如果不是说明构建失败,退出。
-
最后使用
dd命令从 /dev/zero/ 创建空文件 bin/ucore.img,将两个编译出的文件 bin/bootblock 和 bin/kernel 逐字节拷贝到其中。
gcc参数说明
- `-I` 系列: GCC 的 `-I dir` 编译选项,将 dir 加入到搜索头文件的目录列表中,可以用 `#include <...>` 来包含。
- `-fno-builtin` :对所有 GNU C Compiler 内建函数,必须以 `__builtin_` 开头才能被编译器识别,否则作为未定义标识符(或者用户定义标识符)。
- `-Wall` :生成尽可能多警告。为什么叫尽可能多呢……因为还有 `-Wextra` `-Wpedantic` ,甚至 `-Wpedantic` 也不是最多的,有更多警告需要传参手动打开。
- `-ggdb` :生成 gdb 兼容的调试信息,其实这个指令 `-g` 就可以了。
- `-m32` :可以说是最重要的选项了,生成 32 位环境( x86 架构)兼容指令。
- `-gstabs` :生成 stabs 格式的调试信息,在内核源码中有一步输出栈帧信息利用了 stabs 格式的调试信息,和上面的 `-ggdb` 并不冲突。
- `-nostdinc` :不搜索系统标准头文件,只使用 `-I` 选项指明的目录。
- `-fno-stack-protector` : 关闭 canary 保护,这是针对栈溢出的保护,对于内核来说没啥用,毕竟内核本身就是乱写内存的( sorry ,内核就是可以为所欲为),打开反而可能会导致莫名的 crash 。
- `-c` :仅仅编译+汇编,不链接。也就是产生可重定位 ELF 文件(好吧,也叫 object 文件)。
- `-o` :指明输出文件名。
ld参数说明和dd参数说明
-m :指明生成文件格式,此处为 elf_i386 ,则生成 x86 架构的 ELF 格式可执行文件。
-nostdlib :字面意思,不链接标准库。
-T :指明链接脚本,链接脚本是用来指明各个段的位置还有入口之类的链接信息的。
-o :指明输出文件名。
-N :设置 text 和 data 段可写,不要按页对其代码,不和共享库链接。这个命令就是专为编译裸机程序打造的……
-e :指明 entry point ,默认是 _start ,这里设置为入口函数 kern_init 以便随后 boot 进入保护模式后可以直接 jump 到 entry point 函数。
-Ttext 指明 text 段在运行时的内存地址,以便于符号重定位。
if : input file 。
of : output file 。
count :读取并写入的 block size 数。
bs : block size ,默认 512 。
seek :跳过写入文件的 block size 数。
conv : conv 符号处理的东西有点多,就这里的 notrunc 是不设置 write syscall 的参数 O_TRUNC ( dd 默认会设置),这就使得 dd 输出的文件已存在时,如果现在输出的比原来的要小,则文件大小保持被 dd 之前一样不变。
通过对make执行的命令分析我们知道了如何从.c文件到生成.o文件,这些.o⽂ 件将被链接为需要的kenerl可执⾏程序。
接下来,让我们来分析Makefile文件:
首先,我们找到⽣成ucore.img镜像⽂件的内容如下:
# create ucore.img
UCOREIMG := $(call totarget,ucore.img)
$(UCOREIMG): $(kernel) $(bootblock)
$(V)dd if=/dev/zero of=$@ count=10000
$(V)dd if=$(bootblock) of=$@ conv=notrunc
$(V)dd if=$(kernel) of=$@ seek=1 conv=notrunc
$(call create_target,ucore.img)
从这个代码块中可以看出我们需要kernel以及bootblock。接下来我们找到对应部分,并且观察相关代码:
生成kernel文件的代码如下:
# create kernel target
kernel = $(call totarget,kernel)
$(kernel): tools/kernel.ld
$(kernel): $(KOBJS)
@echo + ld $@
$(V)$(LD) $(LDFLAGS) -T tools/kernel.ld -o $@ $(KOBJS)
@$(OBJDUMP) -S $@ > $(call asmfile,kernel)
@$(OBJDUMP) -t $@ | $(SED) '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $(call symfile,kernel)
$(call create_target,kernel)
表示/bin/kernel文件依赖于tools/kernel.ld文件,并且没有指定生成规则,也就是说如果没有预先准备好kernel.ld,就会在make的时候产生错误;之后的$(kernel): $(KOBJS)表示kernel文件的生成还依赖于上述生成的obj/libs, obj/kernels下的.o文件,并且生成规则为使用ld链接器将这些.o文件连接成kernel文件,其中ld的-T表示指定使用kernel.ld来替代默认的链接器脚本。
同时通过上文中对make "V="中所显示的命令一起分析,会让Makefile这里的命令更加清晰。
生成bootblock文件的代码如下:
# create bootblock
bootfiles = $(call listf_cc,boot)
$(foreach f,$(bootfiles),$(call cc_compile,$(f),$(CC),$(CFLAGS) -Os -nostdinc))
bootblock = $(call totarget,bootblock)
$(bootblock): $(call toobj,$(bootfiles)) | $(call totarget,sign)
@echo + ld $@
$(V)$(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 $^ -o $(call toobj,bootblock)
@$(OBJDUMP) -S $(call objfile,bootblock) > $(call asmfile,bootblock)
@$(OBJCOPY) -S -O binary $(call objfile,bootblock) $(call outfile,bootblock)
@$(call totarget,sign) $(call outfile,bootblock) $(bootblock)
$(call create_target,bootblock)
首先是$(foreachf,$(bootfiles),$(callcc_compile,$(f),$(CC),$(CFLAGS) -Os -nostdinc)这一段代码,表示将boot/文件夹下的bootasm.S, bootmain.c两个文件编译成相应的.o文件,并且生成依赖文件.d;其中涉及到的两个gcc编译选项含义如下所示:
-nostdinc: 不搜索默认路径头文件;
-0s: 针对生成代码的大小进行优化,这是因为bootloader的总大小被限制为不大于512-2=510字节;
接下来由代码$(bootblock): $(call toobj,$(bootfiles)) | $(call totarget,sign可知,bootblock依赖于bootasm.o, bootmain.o文件与sign文件,其中两个.o文件由以下规则生成:
( V ) (V) (V)(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 $^ -o ( c a l l t o o b j , b o o t b l o c k ) : 使 用 l d 链 接 器 将 依 赖 的 . o 文 件 链 接 成 b o o t b l o c k . o 文 件 , 该 文 件 中 除 了 (call toobj,bootblock):使用ld链接器将依赖的.o文件链接成bootblock.o文件,该文件中除了 (calltoobj,bootblock):使用ld链接器将依赖的.o文件链接成bootblock.o文件,该文件中除了(LDFLAGS)之外的其他选项含义如下:
-N:将代码段和数据段设置为可读可写;
-e:设置入口;
-Ttext:设置起始地址为0X7C00;
@$(OBJDUMP) -S $(call objfile,bootblock) > $(call asmfile,bootblock): 使用objdump将编译结果反汇编出来,保存在bootclock.asm中,-S表示将源代码与汇编代码混合表示;
@$(OBJCOPY) -S -O binary $(call objfile,bootblock) $(call outfile,bootblock): 使用objcopy将bootblock.o二进制拷贝到bootblock.out,其中:
-S:表示移除符号和重定位信息;
-O:表示指定输出格式;
@$(call totarget,sign) $(call outfile,bootblock) $(bootblock): 使用sign程序, 利用bootblock.out生成bootblock;
$(call add_files_host,tools/sign.c,sign,sign: 利用tools/sing.c生成sign.o, $(call create_target_host,sign,sign)则利用sign.o生成sign,至此bootblock所依赖的文件均生成完毕。
从中可以看到需要利用sign.o来生成sign,所以接下来在makefile中找到sign的部分如下:
# create 'sign' tools
$(call add_files_host,tools/sign.c,sign,sign)
$(call create_target_host,sign,sign)
由此,就解释了kernel和bootblock的⽣成途径,它们将作为依赖使得ucore.img镜像的⽣成成为可能。
接下来分析一开始找到的生成ucore.img镜像的部分:
# create ucore.img
UCOREIMG := $(call totarget,ucore.img)
$(UCOREIMG): $(kernel) $(bootblock)
$(V)dd if=/dev/zero of=$@ count=10000
$(V)dd if=$(bootblock) of=$@ conv=notrunc
$(V)dd if=$(kernel) of=$@ seek=1 conv=notrunc
$(call create_target,ucore.img)
最后一个部分是利用dd命令使用bootblock, kernel文件来生成ucore.img文件:
$(V)dd if=/dev/zero of=$@ count=10000命令表示从/dev/zero文件中获取10000个block,每一个block为512字节,并且均为空字符,并且输出到目标文件ucore.img中;$(V)dd if=$(bootblock) of=$@ conv=notrunc命令表示从bootblock文件中获取数据,并且输出到目标文件ucore.img中,-notruct选项表示不要对数据进行删减;$(V)dd if=$(kernel) of=$@ seek=1 conv=notrunc命令表示从kernel文件中获取数据,并且输出到目标文件ucore.img中, 并且seek = 1表示跳过第一个block,输出到第二个块;
同时接下来根据Makefile文件中的内容对make "V="显示出来的命令进行分析,我们可以得到以下的依赖图:
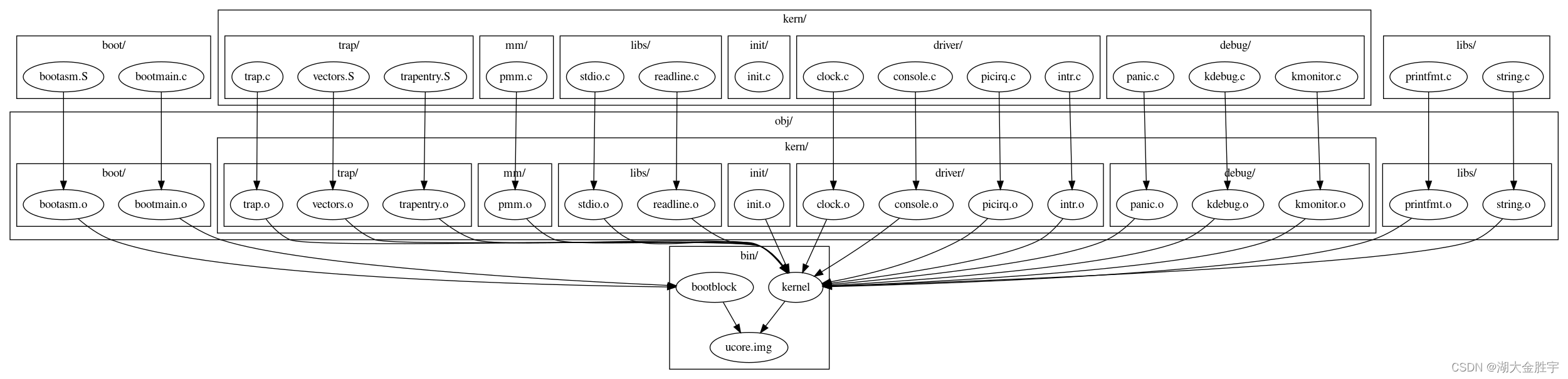
接下来对make "V="显⽰的、有关镜像⽣成的指令如下:
dd if=/dev/zero of=bin/ucore.img count=10000
10000+0 records in
10000+0 records out
5120000 bytes (5.1 MB) copied, 0.0261621 s, 196 MB/s
dd if=bin/bootblock of=bin/ucore.img conv=notrunc
1+0 records in
1+0 records out
512 bytes (512 B) copied, 2.2322e-05 s, 22.9 MB/s
dd if=bin/kernel of=bin/ucore.img seek=1 conv=notrunc
146+1 records in
146+1 records out
74862 bytes (75 kB) copied, 0.000555262 s, 135 MB/s
与上面对makefile中的部分进行分析相对应,下面只说一些具体生成的部分(与上面分析所不同的):
最后一句可以想见,ucore.img的 10000个块中,第⼀个块存放bootblock程序,剩下的存放kernel程序。
相关原理:磁盘镜像是⼀个模拟的磁盘,计算机启动时需要从这⾥读取数据。⾸先,需要执行BIOS程序,这个程序会对CPU进⾏⼀定程度的初始化,并从磁盘的第⼀个块(也就是主引导扇区)⾥加载bootblock进⼊内存;bootblock程序的作⽤是修改CPU从实模式变为保护模式,同时加载磁盘中剩余块⾥的kernel内核代码。bootblock对应的是所谓加载程序,没 有它就⽆法从磁盘中获取实现操作系统功能的内核代码;kernel是真正的操作系统内核程 ,bootblock将它加载⼊内存后,就将控制权转移给它并开始运⾏操作系统。
1.2 ⼀个被系统认为是符合规范的硬盘主引导扇区的特征是什么?
磁盘中的⼀个块,或者说⼀个扇区,⼀般有512个字节。所以,必须恰好 512 字节,且最后两个字节分别是 0x55 和 0xaa , BIOS 只检查这两个字节。因为磁盘主引导区的数据需要一定的格式,所以最后两个字写分别是 0x55 和 0xaa 。
主引导记录(MBR),也被称为主引导扇区,是计算机开机以后访问硬盘时所必须要读取的第一个扇区。在深入讨论主引导扇区内部结构的时候,有时也将其开头的446字节内容特指为”主引导 记录“(MBR),其后是4个16字节的”磁盘分区表“(DPT)以及2字节的结束标志(55AA)。
在执行MBR的引导程序时,会验证MBR扇区最后两个字节是否为“55AA”,如果是“55AA”,那么系统才会继续执行下面的程序;如果不是“55AA”,则程序认为这是一个非法的MBR,那么程序将停止执行,同时会在屏幕上列出错误信息。
练习2:使用qemu执行并调试lab1中的软件。(要求在报告中简要写出练习过程)
为了熟悉使用qemu和gdb进行的调试工作,我们进行如下的小练习:
- 从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。
- 在初始化位置0x7c00设置实地址断点,测试断点正常。
- 从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和bootblock.asm进行比较。
- 自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
2.1 从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行。
由于BIOS是在实模式下运行的,因此需要在tools/gdbinit里进行相应设置,所以根据实验指导书附录B,修改 lab1/tools/gdbinit⽂件的内容为:
set arch i8086
target remote: 1234
之后再执行make debug,就可以使用gdb单步追踪BIOS的指令执行了;具体调试结果如下图所示;由图可见在刚初始化的时候,cs,eip寄存器的数值分别被初始化为0xf000, 0xfff0, 即第一个执行的指令位于内存中的0xffff0处,该指令是一条跳转指令,跳转到BIOS的主题代码所在的入口;如图所示,使用GDB进行调试可以很方便地观察指令执行过程中的所有寄存器的数值变化,也就是使用lay reg就可以轻松追踪到寄存器值的变化:

这个值决定了我们从内存中读数据的位置,PC = 16*CS + IP。
2.2 在初始化位置0x7c00设置实地址断点,测试断点正常。
接下来要设置断点,首先我们找到Makefile中关于debug的部分:
debug: $(UCOREIMG)
$(V)$(QEMU) -S -s -parallel stdio -hda $< -serial null &
$(V)sleep 2
$(V)$(TERMINAL) -e "gdb -q -tui -x tools/gdbinit"
在这里发现debug与tools文件里的gdbinit有关,所以接下来到tools文件中打开gdbinit文件,发现里面可以设置断点,所以根据题目的要求,将文件里面的内容修改为:
file bin/kernel
target remote :1234
set architecture i8086
b *0x7c00
continue
x /2i $pc
在我们设计的gdbinit文件里我们可以看到电脑在运行到kern_init是会触发break,也就是所需要设置断点的地方即0x7c00,然后又紧接着在下一步continue,所以会继续执行,直到断点再次出现。x /2i $pc 使⽤examine命令查看pc变量(也就是地址寄存器中的地址)所对应的内存地址的值。/2i的意思是,n为2,从当前地址往后显⽰2个内存单元的内容。x 表⽰显⽰,则/2i的意思就是显⽰两条指令。同时这里也可以换成在gdb命令行中输入lay reg同样可以看到地址寄存器中的地址。
接下来,我们在lab1的目录下,输入make debug发现会弹出几个终端,然后发现在gdb调试界⾯显⽰调试的效果,已经设置了断点,并显⽰了当前pc中指令地址是0x7c00,且指令的名字是cli(这是靠set architecture来确定的);同时,显示了从0x7c00开始的两条指令。同时,输入lay reg可以发现eip就是当前程序所执行的指令地址。
gdb调试界面显示如下:
Breakpoint 1, 0x00007c00 in ?? ()
=> 0x7c00: cli
0x7c01: cld
(gdb)
可以看到断点设置成功了。
接下来,使用lay reg来观察eip:

使用ni指令之后,结果如下:

所以,断点设置成功了。
2.3 从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较。
可以直接通过x命令查看任意数量的代码并进⾏⽐较。所以使用指令x/10i $pc查看相近的指令:
(gdb) x/10i $pc
=> 0x7c00: cli
0x7c01: cld
0x7c02: xor %ax,%ax
0x7c04: mov %ax,%ds
0x7c06: mov %ax,%es
0x7c08: mov %ax,%ss
0x7c0a: in $0x64,%al
---Type <return> to continue, or q <return> to quit---
0x7c0c: test $0x2,%al
0x7c0e: jne 0x7c0a
0x7c10: mov $0xd1,%al
(gdb)
接下来对照bootasm.S⽂件中的内容:
.code16 # Assemble for 16-bit mode
cli # Disable interrupts
cld # String operations increment
# Set up the important data segment registers (DS, ES, SS).
xorw %ax, %ax # Segment number zero
movw %ax, %ds # -> Data Segment
movw %ax, %es # -> Extra Segment
movw %ax, %ss # -> Stack Segment
# Enable A20:
# For backwards compatibility with the earliest PCs, physical
# address line 20 is tied low, so that addresses higher than
# 1MB wrap around to zero by default. This code undoes this.
seta20.1:
inb $0x64, %al # Wait for not busy(8042 input buffer empty).
testb $0x2, %al
jnz seta20.1
可以看到成功地反汇编了从0x7c00开始的执行的指令的汇编代码,与bootasm.S的入口处的代码进行比较,发现除了gdb反汇编出来的指令中没有指定位宽w(word)之外,其余内容完全一致。
2.4 自己找一个bootloader或内核中的代码位置,设置断点并进行测试。
在本次实验中,选择了在内核中设置断点,由于内核是运行在32位保护模式下的,并且运行是需要符号表信息,使得可以在调试过程中得知具体运行的是哪一行C代码,因此对tools/gdbinit做若干修改如下:
file bin/kernel
target remote :1234
set architecture i8086
b kern_init
continue
接下来对该代码进行调试如下:
(gdb) x /17i $pc
=> 0x101542 <cons_init>: push %bp
0x101543 <cons_init+1>: mov %sp,%bp
0x101545 <cons_init+3>: sub $0x18,%sp
0x101548 <cons_init+6>: call 0x100d63 <delay+107>
0x10154b <cons_init+9>: (bad)
0x10154c <cons_init+10>: ljmp *<internal disassembler error>
0x10154e <cons_init+12>: push %cs
0x10154f <cons_init+13>: stc
0x101550 <cons_init+14>: (bad)
0x101551 <cons_init+15>: ljmp *<internal disassembler error>
0x101553 <cons_init+17>: sar %cl,%bh
0x101555 <cons_init+19>: (bad)
0x101556 <cons_init+20>: jmp *-0x1198(%bx,%di)
0x10155a <cons_init+24>: adc %al,(%bx,%si)
0x10155c <cons_init+26>: test %ax,%ax
0x10155e <cons_init+28>: jne 0x10156c <cons_init+42>
0x101560 <cons_init+30>: movw $0x5324,(%si)
(gdb) b *0x101560
Breakpoint 2 at 0x101560: file kern/driver/console.c, line 430.
(gdb) c
Continuing.
Breakpoint 1, cons_init () at kern/driver/console.c:425
(gdb) x /10i $pc
=> 0x101542 <cons_init>: push %bp
0x101543 <cons_init+1>: mov %sp,%bp
0x101545 <cons_init+3>: sub $0x18,%sp
0x101548 <cons_init+6>: call 0x100d63 <delay+107>
0x10154b <cons_init+9>: (bad)
0x10154c <cons_init+10>: ljmp *<internal disassembler error>
0x10154e <cons_init+12>: push %cs
0x10154f <cons_init+13>: stc
0x101550 <cons_init+14>: (bad)
0x101551 <cons_init+15>: ljmp *<internal disassembler error>
练习3:分析bootloader进入保护模式的过程
BIOS将通过读取硬盘主引导扇区到内存,并转跳到对应内存中的位置执行bootloader。请分析bootloader是如何完成从实模式进入保护模式的。
提示:需要阅读**小节“保护模式和分段机制”**和lab1/boot/bootasm.S源码,了解如何从实模式切换到保护模式,需要了解:
- 为何开启A20,以及如何开启A20
- 如何初始化GDT表
- 如何使能和进入保护模式
首先我们先了解一下bootloader启动过程:
BIOS将通过读取硬盘主引导扇区到内存,并转跳到对应内存中的位置执行bootloader。bootloader完成的工作包括:
- 切换到保护模式,启用分段机制
- 读磁盘中ELF执行文件格式的ucore操作系统到内存
- 显示字符串信息
- 把控制权交给ucore操作系统
对应其工作的实现文件在lab1中的boot目录下的三个文件asm.h、bootasm.S和bootmain.c。
根据提示,我们先阅读小节“保护模式和分段机制”:
(1) 实模式
在bootloader接手BIOS的工作后,当前的PC系统处于实模式(16位模式)运行状态,在这种状态下软件可访问的物理内存空间不能超过1MB,且无法发挥Intel 80386以上级别的32位CPU的4GB内存管理能力。
实模式将整个物理内存看成分段的区域,程序代码和数据位于不同区域,操作系统和用户程序并没有区别对待,而且每一个指针都是指向实际的物理地址。这样,用户程序的一个指针如果指向了操作系统区域或其他用户程序区域,并修改了内容,那么其后果就很可能是灾难性的。通过修改A20地址线可以完成从实模式到保护模式的转换。有关A20的进一步信息可参考附录“关于A20 Gate”。
(2) 保护模式
只有在保护模式下,80386的全部32根地址线有效,可寻址高达4G字节的线性地址空间和物理地址空间,可访问64TB(有214个段,每个段最大空间为232字节)的逻辑地址空间,可采用分段存储管理机制和分页存储管理机制。这不仅为存储共享和保护提供了硬件支持,而且为实现虚拟存储提供了硬件支持。通过提供4个特权级和完善的特权检查机制,既能实现资源共享又能保证代码数据的安全及任务的隔离。
所以,GDT中存放的各个段描述符实际上就描述了各个段的位置信息和某些属性。保护模式下,逻辑地址中会被拆分出⼀部分数据作为索引,⽤于指定GDT中的某⼀个段描述符, 说明当前逻辑地址对应的指令存放在内存的哪⼀个段之中;根据这个索引,可以从GDT中 查找到相应的段描述符,然后得到段的起始地址和相关属性;接着,逻辑地址的剩余部分将 作为段偏移量,⽤于和段的起始地址组合在⼀起,以得到真正的内存地址。
分段地址转换:CPU把逻辑地址(由段选择子selector和段偏移offset组成)中的段选择子的内容作为段描述符表的索引,找到表中对应的段描述符,然后把段描述符中保存的段基址加上段偏移值,形成线性地址(Linear Address)。如果不启动分页存储管理机制,则线性地址等于物理地址。
段寄存器:CS代码段;DS数据段;SS堆栈段;ES附加段。
在这里,我们发现分段存储管理机制需要在启动保护模式的前提下建立。为了使得分段存储管理机制正常运行,需要建立好段描述符和段描述符表,也就是需要参看bootasm.S,mmu.h,pmm.c。
这里着重说明一下选择子:
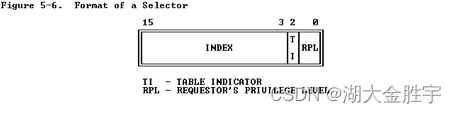
上图是选择子的一个格式,从图中我们可以看出选择子结构:
- 索引(Index):在描述符表中从8192个描述符中选择一个描述符。处理器自动将这个索引值乘以8(描述符的长度),再加上描述符表的基址来索引描述符表,从而选出一个合适的描述符。
- 表指示位(Table Indicator,TI):选择应该访问哪一个描述符表。0代表应该访问全局描述符表(GDT),1代表应该访问局部描述符表(LDT)。
- 请求特权级(Requested Privilege Level,RPL):保护机制。
综上所述,为了切换模式并同时开启段机制,需要⼀个GDT表⽤来存放段描述符;同时, 需要更新段寄存器,⽤来说明当前段的具体信息。
根据这个保护模式和分段机制的相关知识,我们发现是通过修改A20地址线可以完成从实模式到保护模式的转换的,所以接下来我们参考一下附录“关于A20 Gate”。
关于A20Gate
早期的8086 CPU提供了20根地址线,可寻址空间范围即02^20(00000HFFFFFH)的 1MB内存空间。但8086的数据处理位宽位16位,无法直接寻址1MB内存空间,所以8086提供了段地址加偏移地址的地址转换机制。
其中,段寄存器有16位,偏移地址也有16位;为了得到真正地址,⾸先会将段寄存器中的 数据左移4位得到20位的段基址(也就是段的起始地址),然后⽤20位的段机制加上16位的 偏移地址,得到20位的真正地址。
但是段地址加偏移寻址方式支持略高于 20 位的寻址能力,大于等于部分会“回卷”而访问低地址(不会发生异常)。
但下一代的基于Intel 80286 CPU的PC AT计算机系统提供了24根地址线,这样CPU的寻址范围变为 2^24=16M,同时也提供了保护模式,可以访问到1MB以上的内存了,此时如果遇到“寻址超过1MB”的情况,系统不会再“回卷”了,这就造成了向下不兼容。
关于A20Gate则是为了保持完全的向下兼容性,IBM决定在PC AT计算机系统上加个硬件逻辑,来模仿以上的回绕特征,于是出现了A20 Gate,若关闭则保留回卷特性,否则禁用回卷,允许访问高地址。
A20 Gate的方法是把A20地址线控制和键盘控制器的一个输出进行AND操作,这样来控制A20地址线的打开(使能)和关闭(屏蔽禁止)。一开始时A20地址线控制是被屏蔽的(总为0),直到系统软件通过一定的IO操作去打开它。当A20地址线控制禁止时,则程序就像在i8086中运行,1MB以上的地址不可访问;保护模式下A20地址线控制必须打开,A20控制打开后,内存寻址将不会发生回卷,这时CPU可以充分使用32位4G内存的寻址能力。
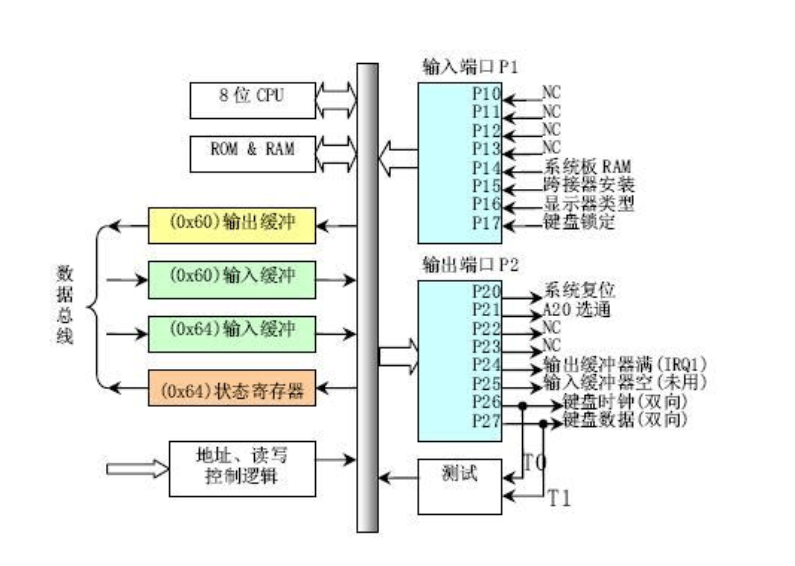
理论上讲,我们只要操作8042芯片的输出端口(64h)的bit 1,就可以控制A20 Gate,但实际上,当你准备向8042的输入缓冲区里写数据时,可能里面还有其它数据没有处理,所以,我们要首先禁止键盘操作,同时等待数据缓冲区中没有数据以后,才能真正地去操作8042打开或者关闭A20 Gate。打开A20 Gate的具体步骤大致如下(参考bootasm.S):
- 禁止中断
- 等待8042 Input buffer为空;
- 发送Write 8042 Output Port (P2)命令到8042 Input buffer;
- 等待8042 Input buffer为空;
- 将8042 Output Port(P2)得到字节的第2位置1,然后写入8042 Input buffer;
代码解析如下:
.globl start
start:
.code16 # Assemble for 16-bit mode
cli # Disable interrupts
cld # String operations increment
# Set up the important data segment registers (DS, ES, SS).
xorw %ax, %ax # Segment number zero
movw %ax, %ds # -> Data Segment
movw %ax, %es # -> Extra Segment
movw %ax, %ss # -> Stack Segment
bootloader入口为start, 根据bootloader的相关知识可知,bootloader会被BIOS加载到内存的0x7c00处,此时cs=0, eip=0x7c00,在刚进入bootloader的时候,最先执行的操作分别为关闭中断、清除EFLAGS的DF位以及将ax, ds, es, ss寄存器初始化为0;
seta20.1:
inb $0x64, %al # Wait for not busy(8042 input buffer empty).
testb $0x2, %al
jnz seta20.1
首先是从0x64内存地址中(映射到8042的status register)中读取8042的状态,直到读取到的该字节第二位(input buffer是否有数据)为0,此时input buffer中无数据;
movb $0xd1, %al # 0xd1 -> port 0x64
outb %al, $0x64 # 0xd1 means: write data to 8042's P2 port
接下来往0x64写入0xd1命令,表示修改8042的P2 port;
seta20.2:
inb $0x64, %al # Wait for not busy(8042 input buffer empty).
testb $0x2, %al
jnz seta20.2
接下来继续等待input buffer为空;
movb $0xdf, %al # 0xdf -> port 0x60
outb %al, $0x60 # 0xdf = 11011111,
接下来往0x60端口写入0xdf,表示将P2 port的第二个位(A20)选通置为1;
到这里,A20已经打开了,进入保护模式之后就可以使用4G的寻址能力;切换到保护模式之后,接下来需要启动分段机制
# Switch from real to protected mode, using a bootstrap GDT
# and segment translation that makes virtual addresses
# identical to physical addresses, so that the
# effective memory map does not change during the switch.
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE_ON, %eax
movl %eax, %cr0
上述代码中,lgdt命令的作⽤是加载数据到gdt段表中。这⾥就是在执⾏载⼊,初始化gdt段表,⽤于段保护机制的实现。接下来,来看下是怎么样来加载gdt全局描述符的。
# Bootstrap GDT
.p2align 2 # force 4 byte alignment
gdt:
SEG_NULLASM # null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # code seg for bootloader and kernel
SEG_ASM(STA_W, 0x0, 0xffffffff) # data seg for bootloader and kernel
gdtdesc:
.word 0x17 # sizeof(gdt) - 1
.long gdt # address gdt
gdt中代码段和数据段的base均设置为了0,而limit设置为了2^32-1即4G,此时就使得逻辑地址等于线性地址,方便后续对于内存的操作;
因此在A20开启之后,只需要使用命令lgdt gdtdesc即可载入全局描述符表;
movl %cr0, %eax
orl $CR0_PE_ON, %eax
movl %eax, %cr0
这里的代码是将cr0寄存器的PE位置设置为1就可以从实模式切换到保护模式;
ljmp $PROT_MODE_CSEG, $protcseg
ljmp指令注释含义:注释含义:#跳转到下⼀条指令,但在32位代码段中。#将处理器切换 到32位模式。
这里使用了一个跳转指令,将cs修改为32位段寄存器,以及跳转到protcseg这一32位代码入口处,此时CPU进入32位模式;
接下来执行的32位代码功能为:设置ds、es, fs, gs, ss这几个段寄存器,然后初始化栈的frame pointer和stack pointer,然后调用使用C语言编写的bootmain函数,进行操作系统内核的加载,至此,bootloader已经完成了从实模式进入到保护模式的任务。
练习4:分析bootloader加载ELF格式的OS的过程。(要求在报告中写出分析)
通过阅读bootmain.c,了解bootloader如何加载ELF文件。通过分析源代码和通过qemu来运行并调试bootloader&OS,
- bootloader如何读取硬盘扇区的?
- bootloader是如何加载ELF格式的OS?
提示:可阅读“硬盘访问概述”,“ELF执行文件格式概述”这两小节。
通过提示,这里我们先阅读一下“硬盘访问概述”,“ELF执行文件格式概述”:
硬盘访问概述
bootloader让CPU进入保护模式后,下一步的工作就是从硬盘上加载并运行OS。这个实验为了简化,所以bootloader的访问硬盘都是LBA模式的PIO(Program IO)方式,即所有的IO操作是通过CPU访问硬盘的IO地址寄存器完成。
一般主板有2个IDE通道,每个通道可以接2个IDE硬盘。
访问第一个硬盘的扇区可设置IO地址寄存器0x1f0-0x1f7实现的,具体参数见下表。一般第一个IDE通道通过访问IO地址0x1f0-0x1f7来实现:
表一 磁盘IO地址和对应功能
第6位:为1=LBA模式;0 = CHS模式 第7位和第5位必须为1
| IO地址 | 功能 |
|---|---|
| 0x1f0 | 读数据,当0x1f7不为忙状态时,可以读。 |
| 0x1f2 | 要读写的扇区数,每次读写前,你需要表明你要读写几个扇区。最小是1个扇区 |
| 0x1f3 | 如果是LBA模式,就是LBA参数的0-7位 |
| 0x1f4 | 如果是LBA模式,就是LBA参数的8-15位 |
| 0x1f5 | 如果是LBA模式,就是LBA参数的16-23位 |
| 0x1f6 | 第0~3位:如果是LBA模式就是24-27位 第4位:为0主盘;为1从盘 |
| 0x1f7 | 状态和命令寄存器。操作时先给命令,再读取,如果不是忙状态就从0x1f0端口读数据 |
第二个IDE通道通过访问0x170-0x17f实现。每个通道的主从盘的选择通过第6个IO偏移地址寄存器来设置。
当前硬盘数据是储存到硬盘扇区中,一个扇区大小为512字节。读一个扇区的流程(可参看boot/bootmain.c中的readsect函数实现)大致如下:
- 等待磁盘准备好
- 发出读取扇区的命令
- 等待磁盘准备好
- 把磁盘扇区数据读到指定内存
ELF文件格式概述
ELF(Executable and linking format)文件格式是Linux系统下的一种常用目标文件(object file)格式,有三种主要类型:
- 用于执行的可执行文件(executable file),用于提供程序的进程映像,加载的内存执行。 这也是本实验的OS文件类型。
- 用于连接的可重定位文件(relocatable file),可与其它目标文件一起创建可执行文件和共享目标文件。
- 共享目标文件(shared object file),连接器可将它与其它可重定位文件和共享目标文件连接成其它的目标文件,动态连接器又可将它与可执行文件和其它共享目标文件结合起来创建一个进程映像。
这里只分析与本实验相关的ELF可执行文件类型。ELF header在文件开始处描述了整个文件的组织。ELF的文件头包含整个执行文件的控制结构,其定义在elf.h中:
struct elfhdr {
uint magic; // must equal ELF_MAGIC
uchar elf[12];
ushort type;
ushort machine;
uint version;
uint entry; // 程序入口的虚拟地址
uint phoff; // program header 表的位置偏移
uint shoff;
uint flags;
ushort ehsize;
ushort phentsize;
ushort phnum; //program header表中的入口数目
ushort shentsize;
ushort shnum;
ushort shstrndx;
};
根据上面这个数据结构,我们知道magic必须等于ELF_MAGIC才能确保程序正确地运行,entry是程序入口的虚拟地址,phoff给出了program header表的位置偏移,根据entry这个值我们就可以找到program header的位置。phnum则说明了program header表中的入口数目。
接下来让我们了解一下program header的数据结构:
可执行文件的程序头部是一个program header结构的数组, 每个结构描述了一个段或者系统准备程序执行所必需的其它信息。目标文件的 “段” 包含一个或者多个 “节区”(section) ,也就是“段内容(Segment Contents)” 。
struct proghdr {
uint type; // 段类型
uint offset; // 段相对文件头的偏移值
uint va; // 段的第一个字节将被放到内存中的虚拟地址
uint pa;
uint filesz;
uint memsz; // 段在内存映像中占用的字节数
uint flags;
uint align;
};
在ELF头部的e_phentsize和e_phnum成员中给出其自身程序头部的大小。其中,type成员变量描述了section类型,offset描述了section相对于⽂件头的偏移量, va描述了这个section的第⼀个字节在内存中的虚拟地址,memsz是这个section在内存映像中占⽤的字节数⽬。
4.1 bootloader如何读取硬盘扇区的?
从实验指导书中的硬盘访问概述,我们已经知道了读一个扇区的基本流程了,接下来我们根据文档中所需要参看的boot/bootmain.c中的readsect函数实现来分析具体是如何读取硬盘扇区的:
/* waitdisk - wait for disk ready */
static void
waitdisk(void) {
while ((inb(0x1F7) & 0xC0) != 0x40)
/* do nothing */;
}
首先我们看到waitdisk函数,根据这个函数的命名我就知道这个函数的作用是等待硬盘。但是,具体等待什么还不知道。接下来,让我们来看到函数的实现,其中inb是从I/O端口读取一个字节然后与0xC0相与直到取出的值满足相与的值为0x40,同时根据上面的表1我们可以知道0x1F7是状态和命令寄存器。操作时先给命令,再读取,如果不是忙状态就从0x1f0端口读数据。所以,可以推断这里是为了从这里不停的读取磁盘的状态,直到磁盘的状态为不忙为止。
/* readsect - read a single sector at @secno into @dst */
static void
readsect(void *dst, uint32_t secno) {
waitdisk(); // 等待磁盘到不忙为止
outb(0x1F2, 1); // 往0X1F2地址中写入要读取的扇区数,由于此处需要读一个扇区,因此参数为1
outb(0x1F3, secno & 0xFF); // 输入LBA参数的0...7位;
outb(0x1F4, (secno >> 8) & 0xFF); // 输入LBA参数的8-15位;
outb(0x1F5, (secno >> 16) & 0xFF); // 输入LBA参数的16-23位;
outb(0x1F6, ((secno >> 24) & 0xF) | 0xE0); // 输入LBA参数的24-27位(对应到0-3位),第四位为0表示从主盘读取,其余位被强制置为1;
outb(0x1F7, 0x20); // 向磁盘发出读命令0x20
waitdisk(); // 等待磁盘直到不忙
insl(0x1F0, dst, SECTSIZE / 4); // 从数据端口0x1F0读取数据,除以4是因为此处是以4个字节为单位的,这个从指令是以l(long)结尾这点可以推测出来;
}
接下来看到的是readsect函数,发现里面大部分是向一些I/O端口写入字节,在这里需要联系一下上文中的表1,具体的作用注释在图中。接下来分析一下该函数具体的过程:
- 首先等待磁盘为不忙状态;
- 往0x1F2到0X1F6中设置读取扇区需要的参数,包括读取扇区的数量以及LBA参数;
- 往0x1F7端口发送读命令0X20;
- 等待磁盘完成读取操作;
- 从数据端口0X1F0读取出数据到指定内存中;
接下来看readseg函数:
/* *
* readseg - read @count bytes at @offset from kernel into virtual address @va,
* might copy more than asked.
* */
static void
readseg(uintptr_t va, uint32_t count, uint32_t offset) {
uintptr_t end_va = va + count;
// round down to sector boundary
va -= offset % SECTSIZE;
// translate from bytes to sectors; kernel starts at sector 1
uint32_t secno = (offset / SECTSIZE) + 1;
// If this is too slow, we could read lots of sectors at a time.
// We'd write more to memory than asked, but it doesn't matter --
// we load in increasing order.
for (; va < end_va; va += SECTSIZE, secno ++) {
readsect((void *)va, secno);
}
}
这个readreg函数将readsect的功能进一步封装,接下来让我们分析一下该函数的具体功能:
readseg将从kernel起始位置起(即磁盘第二个扇区)offset位置处的count字节读取到指定内存。由于这里可能会包括指定数据的前后扇区的内容,也就是读取的数据在内存中的起始位置不是指定原始的va。readseg函数将会读取一共count个字节存放到va到end_va的虚拟地址之中。举个例子:比如offset是700,那么读取512个字节就会读取到第四个扇区的内容。在这里,采用了一个小技巧,就是将va减去了一个offset%512 Byte的偏移量,就是700%512=188,secno(逻辑地址,可以 理解为扇区编号)是2,从2号扇区开始读,1号和0号扇区不读。所以这样减去一个偏移量,可以使得要求的读取到的数据在内存中的起始位置恰好是指定的原始的va。
最后有个循环,secno不断增加,表示依次向后访问扇区直到到达最后的end_va,同时va不断地加上SECTSIZE这里的大小是512个字节,因为每个扇区的大小就是512个字节,这里是为了每次都可以让起始地址对应上扇区的起始地址。
4.2 bootloader是如何加载ELF格式的OS?
发现在bootmain函数中有ELF出现,接下来我们来分析一下bootmain函数:
// read the 1st page off disk
readseg((uintptr_t)ELFHDR, SECTSIZE * 8, 0);
// is this a valid ELF?
if (ELFHDR->e_magic != ELF_MAGIC) {
goto bad;
}
首先调用了readseg函数读取了从磁盘1号扇区到磁盘8号扇区总共八个扇区的内容(即OS kenerl最开始的4kB代码),因为一个扇区的大小是512B,根据上文中分析的readseg函数,我们可以直到是读取到ELFHDR指针对应的地址处,然后判断读取的数据最开始的四个字节是否等于指定的ELF_MAGIC来判断该ELF header是否合法,若是不合法则直接跳转出去,合法则继续执行:
struct proghdr *ph, *eph;
// load each program segment (ignores ph flags)
ph = (struct proghdr *)((uintptr_t)ELFHDR + ELFHDR->e_phoff);
eph = ph + ELFHDR->e_phnum;
for (; ph < eph; ph ++) {
readseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset);
}
从ELF头文件中获取program header表的位置,也就是从ELFHDR里的e_phoff成员变量知道 program header 表的位置偏移,然后和ELFHDR也就是文件开始地址组合在一起,这里就可以得到program header的起始地址将其赋值给ph。e_phnum说明的是该表的入口数目,program header的起始地址加上e_phnum就可以知道各个入口的具体位置。注意这里,虽然e_phnum是一个整数,但是ph加上它之后,得到的新地址是ph地址加上了入口数目乘以该类型所占字节数。
然后遍历该表每一项,从表中获取到段应该被加载到内存中的位置(Load Address,虚拟地址),以及段的大小,然后调用readseg函数把每一个段加载到内存中,到这里也就完成了将OS加载到内存中的操作。
// call the entry point from the ELF header
// note: does not return
((void (*)(void))(ELFHDR->e_entry & 0xFFFFFF))();
最后,bootloader需要通过ELFHDR->e_entry来获得程序入口的虚拟地址,然后使用函数调用的方式跳转到该地址上去,也就是我们开始执行加载到内存中的内核程序。
练习5:实现函数调用堆栈跟踪函数 (需要编程)
我们需要在lab1中完成kdebug.c中函数print_stackframe的实现,可以通过函数print_stackframe来跟踪函数调用堆栈中记录的返回地址。在如果能够正确实现此函数,可在lab1中执行 “make qemu”后,在qemu模拟器中得到类似如下的输出:
……
ebp:0x00007b28 eip:0x00100992 args:0x00010094 0x00010094 0x00007b58 0x00100096
kern/debug/kdebug.c:305: print_stackframe+22
ebp:0x00007b38 eip:0x00100c79 args:0x00000000 0x00000000 0x00000000 0x00007ba8
kern/debug/kmonitor.c:125: mon_backtrace+10
ebp:0x00007b58 eip:0x00100096 args:0x00000000 0x00007b80 0xffff0000 0x00007b84
kern/init/init.c:48: grade_backtrace2+33
ebp:0x00007b78 eip:0x001000bf args:0x00000000 0xffff0000 0x00007ba4 0x00000029
kern/init/init.c:53: grade_backtrace1+38
ebp:0x00007b98 eip:0x001000dd args:0x00000000 0x00100000 0xffff0000 0x0000001d
kern/init/init.c:58: grade_backtrace0+23
ebp:0x00007bb8 eip:0x00100102 args:0x0010353c 0x00103520 0x00001308 0x00000000
kern/init/init.c:63: grade_backtrace+34
ebp:0x00007be8 eip:0x00100059 args:0x00000000 0x00000000 0x00000000 0x00007c53
kern/init/init.c:28: kern_init+88
ebp:0x00007bf8 eip:0x00007d73 args:0xc031fcfa 0xc08ed88e 0x64e4d08e 0xfa7502a8
<unknow>: -- 0x00007d72 –
……
请完成实验,看看输出是否与上述显示大致一致,并解释最后一行各个数值的含义。
提示:可阅读小节“函数堆栈”,了解编译器如何建立函数调用关系的。在完成lab1编译后,查看lab1/obj/bootblock.asm,了解bootloader源码与机器码的语句和地址等的对应关系;查看lab1/obj/kernel.asm,了解 ucore OS源码与机器码的语句和地址等的对应关系。
要求完成函数kern/debug/kdebug.c::print_stackframe的实现,提交改进后源代码包(可以编译执行),并在实验报告中简要说明实现过程,并写出对上述问题的回答。
补充材料:
由于显示完整的栈结构需要解析内核文件中的调试符号,较为复杂和繁琐。代码中有一些辅助函数可以使用。例如可以通过调用print_debuginfo函数完成查找对应函数名并打印至屏幕的功能。具体可以参见kdebug.c代码中的注释。
首先,我们需要了解编译器如何建立函数调用关系,这里我们可以阅读小节“函数堆栈”:
理解调用栈最重要的两点是:栈的结构,EBP寄存器的作用。一个函数调用动作可分解为:零到多个PUSH指令(用于参数入栈),一个CALL指令。CALL指令内部其实还暗含了一个将返回地址(即CALL指令下一条指令的地址)压栈的动作(由硬件完成)。下图就是函数调用栈结构:
+| 栈底方向 | 高位地址
| ... |
| ... |
| 参数3 |
| 参数2 |
| 参数1 |
| 返回地址 |
| 上一层[ebp] | <-------- [ebp]
| 局部变量 | 低位地址
这样在程序执行到一个函数的实际指令前,已经有以下数据顺序入栈:参数、返回地址、ebp寄存器。接下来,若是调用了一个函数则会产生一个栈帧结构。使用call指令的时候,将call指令的下一条指令入栈也就是返回地址,接下来保存旧的ebp的值也就是将原来ebp的值压栈保存,在函数调用返回的时候,直接pop ebp来回到上一级栈帧,还有另外一个栈指针esp来指向帧栈的另一端,两个指针共同构成了一个帧栈结构。
根据题中所讲,首先找到kdebug.c⽂件,找到其中的print_stackframe:
/* *
* print_stackframe - print a list of the saved eip values from the nested 'call'
* instructions that led to the current point of execution
*
* The x86 stack pointer, namely esp, points to the lowest location on the stack
* that is currently in use. Everything below that location in stack is free. Pushing
* a value onto the stack will invole decreasing the stack pointer and then writing
* the value to the place that stack pointer pointes to. And popping a value do the
* opposite.
*
* The ebp (base pointer) register, in contrast, is associated with the stack
* primarily by software convention. On entry to a C function, the function's
* prologue code normally saves the previous function's base pointer by pushing
* it onto the stack, and then copies the current esp value into ebp for the duration
* of the function. If all the functions in a program obey this convention,
* then at any given point during the program's execution, it is possible to trace
* back through the stack by following the chain of saved ebp pointers and determining
* exactly what nested sequence of function calls caused this particular point in the
* program to be reached. This capability can be particularly useful, for example,
* when a particular function causes an assert failure or panic because bad arguments
* were passed to it, but you aren't sure who passed the bad arguments. A stack
* backtrace lets you find the offending function.
*
* The inline function read_ebp() can tell us the value of current ebp. And the
* non-inline function read_eip() is useful, it can read the value of current eip,
* since while calling this function, read_eip() can read the caller's eip from
* stack easily.
*
* In print_debuginfo(), the function debuginfo_eip() can get enough information about
* calling-chain. Finally print_stackframe() will trace and print them for debugging.
*
* Note that, the length of ebp-chain is limited. In boot/bootasm.S, before jumping
* to the kernel entry, the value of ebp has been set to zero, that's the boundary.
* */
void
print_stackframe(void) {
/* LAB1 YOUR CODE : STEP 1 */
/* (1) call read_ebp() to get the value of ebp. the type is (uint32_t);
* (2) call read_eip() to get the value of eip. the type is (uint32_t);
* (3) from 0 .. STACKFRAME_DEPTH
* (3.1) printf value of ebp, eip
* (3.2) (uint32_t)calling arguments [0..4] = the contents in address (uint32_t)ebp +2 [0..4]
* (3.3) cprintf("\n");
* (3.4) call print_debuginfo(eip-1) to print the C calling function name and line number, etc.
* (3.5) popup a calling stackframe
* NOTICE: the calling funciton's return addr eip = ss:[ebp+4]
* the calling funciton's ebp = ss:[ebp]
*/
}
可以看出这个函数的实现部分空出来,同时也通过注释给出了题目中的要求,我们接下来明确一下题目中的要求,从而可以让我们更好的编写程序:
/*LAB1您的代码:步骤1*/
/*(1)调⽤read_ebp()获取ebp的值。类型为(uint32_t);
*(2)调⽤read_eip()获取eip的值。类型为(uint32_t);
*(3)从0到STACKFRAME_DERTH,开始读:
*(3.1)ebp、eip的printf值
*(3.2)(uint32_t)调⽤参数[0..4]=地址中的内容(uint32_t)ebp+2[0..4]
*(3.3)cprintf(“\n”);
*(3.4)调⽤print_debuginfo(eip-1)打印C调⽤函数名、⾏号等。
*(3.5)弹出调⽤堆栈帧
*注意:调⽤函数的返回地址eip=ss:[ebp+4]
*调⽤函数的ebp=ss:[ebp]
代码的实现和解析:
uint32_t ebp=read_ebp();
uint32_t eip=read_eip();
int i=0;
for(i=0;i<STACKFRAME_DEPTH&&ebp!=0;i++)
{
cprintf("ebp:0x%08x eip:0x%08x args:", ebp, eip);
uint32_t* ptr = (uint32_t *) (ebp + 8);
cprintf("args:0x%08x 0x%08x 0x%08x 0x%08x\n", ptr[0], ptr[1], ptr[2], ptr[3]);
print_debuginfo(eip - 1);
eip = *((uint32_t *) (ebp + 4));
ebp = *((uint32_t *) ebp);
}
首先这个函数实现起来的思路并不困难,就是从本函数开始不断回溯到调用者,打印所有调用者、调用者的调用者……的信息。
接下来来说一下该函数实现的思路:
- 在这里需要获得当前栈帧的基址指针寄存器也就是ebp的值以及call read_eip这条指令下一条指令的地址,然后分别存入ebp、eip两个临时变量中;
- 接下来需要打印本函数的eip、ebp的数值,这里使用的函数时cprint函数,也就是题中所给的函数
- 根据题目中的要求,接下来需要打印当前栈帧对应的函数可能的参数,根据上文中C语言的栈帧结构,可以知道参数存放在ebp+8指向的内存上,并且第一个、第二个、第三个、第四个参数…所在的内存地址分别为ebp+8,ebp+12,ebp+16,ebp+20,…,根据要求打印函数的前四个参数。
- 接下来,根据给出的print_debuginfo函数打印处当前函数的函数名,这个函数的功能是打印C调⽤函数名、⾏号等。
- 根据上图中的栈帧结构,我们可以知道当前ebp里面保存的值就是调用者函数的ebp的值,而ebp+4里面的地址值正事该函数的返回地址,这个返回地址是执行完本函数后,继续运行该函数调用的下一条指令。因此,就可以从ebp获得调用者的ebp值,从ebp+4处可以获得返回地址的值。这样给eip和ebp赋予新的值之后,它们所针对的就是调用者的ebp和eip了。
- 接下来,就是进入循环来打印调用者的调用者等等,这里如果ebp非0并且没有达到规定的STACKFRAME DEPTH的值,就继续执行循环来打印栈上帧栈和对应函数的信息;
接下来,在命令行输入make qemu我们即可获得对应的结果:
Kernel executable memory footprint: 64KB
ebp:0x00007b28 eip:0x0010098e args:args:0x00010094 0x00010094 0x00007b58 0x00100094
kern/debug/kdebug.c:294: print_stackframe+22
ebp:0x00007b38 eip:0x00100c79 args:args:0x00000000 0x00000000 0x00000000 0x00007ba8
kern/debug/kmonitor.c:125: mon_backtrace+10
ebp:0x00007b58 eip:0x00100094 args:args:0x00000000 0x00007b80 0xffff0000 0x00007b84
kern/init/init.c:48: grade_backtrace2+33
ebp:0x00007b78 eip:0x001000bd args:args:0x00000000 0xffff0000 0x00007ba4 0x00000029
kern/init/init.c:53: grade_backtrace1+38
ebp:0x00007b98 eip:0x001000db args:args:0x00000000 0x00100000 0xffff0000 0x0000001d
kern/init/init.c:58: grade_backtrace0+23
ebp:0x00007bb8 eip:0x00100100 args:args:0x0010341c 0x00103400 0x00001308 0x00000000
kern/init/init.c:63: grade_backtrace+34
ebp:0x00007be8 eip:0x00100057 args:args:0x00000000 0x00000000 0x00000000 0x00007c4f
kern/init/init.c:28: kern_init+86
ebp:0x00007bf8 eip:0x00007d6f args:args:0xc031fcfa 0xc08ed88e 0x64e4d08e 0xfa7502a8
<unknow>: -- 0x00007d6e --
++ setup timer interrupts
上图与题中所给的相对比,发现相似,所以可以知道我们的程序编写正确。同时发现只打印了八条信息,可以知道嵌套调用只进行了八次。
最后一行信息:
ebp:0x00007bf8 eip:0x00007d6f args:args:0xc031fcfa 0xc08ed88e 0x64e4d08e 0xfa7502a8
<unknow>: -- 0x00007d6e --
根据上述打印帧栈信息的过程,我们可以知道打印出来的最后一个ebp是第一个被调用函数的ebp,eip是在该栈帧对应函数中调用下一个栈帧对应函数的指令的地址,而args是传递给这第一个被调用的函数的参数。
看到ebp的值为0x7bf8,我们联想到bootloader这个程序是从0x7c00开始的。也就是说,bootloader程序拥有的堆栈是从0x7c00开始的。接下来,我们进行调试来看一下这边的程序:
0x7d68: and $0xffff,%ax
0x7d6b: incw (%bx,%si)
0x7d6d: call *%ax
0x7d6f: mov $0x8a00,%dx
也就是说,bootloader程序在0x7d70处使用call指令进行了第⼀次嵌套调用,call指令将下 ⼀条指令的地址也就是0x7d72保存在栈中。
ebp:0x00007b28 eip:0x0010098e args:args:0x00010094 0x00010094 0x00007b58 0x00100094
kern/debug/kdebug.c:294: print_stackframe+22
关于其他每行输出中各个数值的意义为:ebp, eip等这一行数值意义与上述一致,下一行的输出调试信息,在.c之后的数字表示当前所在函数进一步调用其他函数的语句在源代码文件中的行号,而后面的+22一类数值表示从该函数汇编代码的入口处到进一步调用其他函数的call指令的最后一个字节的偏移量,以字节为单位;
练习6:完善中断初始化和处理 (需要编程)
请完成编码工作和回答如下问题:
- 中断描述符表(也可简称为保护模式下的中断向量表)中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
- 请编程完善kern/trap/trap.c中对中断向量表进行初始化的函数idt_init。在idt_init函数中,依次对所有中断入口进行初始化。使用mmu.h中的SETGATE宏,填充idt数组内容。每个中断的入口由tools/vectors.c生成,使用trap.c中声明的vectors数组即可。
- 请编程完善trap.c中的中断处理函数trap,在对时钟中断进行处理的部分填写trap函数中处理时钟中断的部分,使操作系统每遇到100次时钟中断后,调用print_ticks子程序,向屏幕上打印一行文字”100 ticks”。
【注意】除了系统调用中断(T_SYSCALL)使用陷阱门描述符且权限为用户态权限以外,其它中断均使用特权级(DPL)为0的中断门描述符,权限为内核态权限;而ucore的应用程序处于特权级3,需要采用`int 0x80`指令操作(这种方式称为软中断,软件中断,Tra中断,在lab5会碰到)来发出系统调用请求,并要能实现从特权级3到特权级0的转换,所以系统调用中断(T_SYSCALL)所对应的中断门描述符中的特权级(DPL)需要设置为3。
要求完成问题2和问题3 提出的相关函数实现,提交改进后的源代码包(可以编译执行),并在实验报告中简要说明实现过程,并写出对问题1的回答。完成这问题2和3要求的部分代码后,运行整个系统,可以看到大约每1秒会输出一次”100 ticks”,而按下的键也会在屏幕上显示。
提示:可阅读小节“中断与异常”。
根据题目中的提示,我们先阅读小节“中断与异常”:
让外设在需要操作系统处理外设相关事件的时候,能够“主动通知”操作系统,即打断操作系统和应用的正常执行,让操作系统完成外设的相关处理,然后在恢复操作系统和应用的正常执行。在操作系统中,这种机制称为中断机制。
在操作系统中,有三种特殊的中断事件。由CPU外部设备引起的外部事件如I/O中断、时钟中断、控制台中断等是异步产生的(即产生的时刻不确定),与CPU的执行无关,我们称之为异步中断(asynchronous interrupt)也称外部中断,简称中断(interrupt)。
而把在CPU执行指令期间检测到不正常的或非法的条件(如除零错、地址访问越界)所引起的内部事件称作同步中断(synchronous interrupt),也称内部中断,简称异常(exception)。
把在程序中使用请求系统服务的系统调用而引发的事件,称作陷入中断(trap interrupt),也称软中断(soft interrupt),系统调用(system call)简称trap。
中断发⽣后,会产⽣⼀个中断号;中断号中的索引被提取出来,可以根据它在中断描述符表 IDT中获得对应于这个中断的⼀个中断描述符;该中断描述符中含有⼀个段选择⼦和段偏移量,可以根据该段选择⼦从段表GDT中查到段描述符,根据段描述符提供的段基址,结合中断描述符中的段偏移量,获得⼀个地址;这个地址就是终端服务例程程序所在的地址,中 断发⽣后将跳转到这⾥以执⾏中断服务。
IDT中断描述表的基本单位是“中断门”,⼀个中断门相当于⼀个中断描述符且中断门⼀共占有64位,对应8个字节。其中32位是段选择⼦,32位是段内偏移。
6.1 中断描述符表(也可简称为保护模式下的中断向量表)中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
同GDT一样,IDT是一个8字节的描述符数组,所以中断描述附表中一个表项占8个字节。
其中最开始2个字节和最末尾2个字节定义了offset(即偏移量),第16-31位(即第2-3字节)定义了处理代码入口地址的段选择子,使用其在GDT中查找到相应段的base address,加上offset就是中断处理代码的入口。
6.2 请编程完善kern/trap/trap.c中对中断向量表进行初始化的函数idt_init。在idt_init函数中,依次对所有中断入口进行初始化。使用mmu.h中的SETGATE宏,填充idt数组内容。每个中断的入口由tools/vectors.c生成,使用trap.c中声明的vectors数组即可。
首先我们根据题目中的要求找到idt_init函数:
/* idt_init - initialize IDT to each of the entry points in kern/trap/vectors.S */
void
idt_init(void) {
/* LAB1 YOUR CODE : STEP 2 */
/* (1) Where are the entry addrs of each Interrupt Service Routine (ISR)?
* All ISR's entry addrs are stored in __vectors. where is uintptr_t __vectors[] ?
* __vectors[] is in kern/trap/vector.S which is produced by tools/vector.c
* (try "make" command in lab1, then you will find vector.S in kern/trap DIR)
* You can use "extern uintptr_t __vectors[];" to define this extern variable which will be used later.
* (2) Now you should setup the entries of ISR in Interrupt Description Table (IDT).
* Can you see idt[256] in this file? Yes, it's IDT! you can use SETGATE macro to setup each item of IDT
* (3) After setup the contents of IDT, you will let CPU know where is the IDT by using 'lidt' instruction.
* You don't know the meaning of this instruction? just google it! and check the libs/x86.h to know more.
* Notice: the argument of lidt is idt_pd. try to find it!
*/
}
接下来我们来明确一下题目中的要求:
/*LAB1您的代码:步骤2*/
(1)每个中断服务例程(ISR)的⼊⼝地址在哪⾥?(只有找到中断地址,才能初始化IDT表)
所有ISR的地址都存储在_vectors中。//IST
uintptr_t___vectors[ ]在哪⾥?
__vectors[ ]位于kern/trap/vector.S中,由tools/vector.c⽣成
*(在lab1中尝试“make”命令,然后在kern/trap DIR中找到vector.S)
*您可以使⽤“extern uintptr_t ____vectors[ ];”来定义此extern变量(外部变量,意味着这个数组是其他⽂件夹⾥的,只不过本⽂件中的函数需要使⽤它来初始化idt表。),该变量将在后头⽤到。
*(2)现在您应该在中断描述符表(IDT)中设置ISR(各个中断⻔)条⽬。
*你能在这个⽂件中看到idt[256]吗?是的,这个数组就是IDT中断描述符表(只要给这个数组赋值就可以初始化IDT表了)!您可以使⽤SETGATE宏设置IDT的各个条⽬。
*(3)设置IDT的内容后,您将使⽤“lidt”指令让CPU知道IDT在哪⾥。
*你不知道这个说明的意思吗?只需⾕歌⼀下!并查看libs/x86.h以了解更多信息。
*注意:lidt的参数是idt_pd。试着找到它。
题目要求我们需要找到中断地址,然后初始化IDT表也就是初始化中断描述符表,然后在中断描述符表(IDT)中设置ISR(各个中断门)条目,这里使用的是SETGATE宏设置IDT的各个条目。
同时,在这里我们发现上方就是定义IDT的代码:
/* *
* Interrupt descriptor table:
*
* Must be built at run time because shifted function addresses can't
* be represented in relocation records.
* */
static struct gatedesc idt[256] = {{0}};
static struct pseudodesc idt_pd = {
sizeof(idt) - 1, (uintptr_t)idt
};
我们发现刚开始的时候IDT表中的每项都是0,所以我们必须要初始化,下面是代码的实现和解析:
void
idt_init(void) {
extern uintptr_t __vectors[];
int gatenum=sizeof(idt)/sizeof(struct gatedesc);
int i;
for(i=0; i<gatenum; i++)
{
SETGATE(idt[i], 0, GD_KTEXT, __vectors[i], DPL_KERNEL);
}
SETGATE(idt[T_SWITCH_TOK], 0, GD_KTEXT, __vectors[T_SWITCH_TOK],
DPL_USER);
lidt(&idt_pd);
}
根据注释,我们在这里使用extern uintptr_t ____vectors[ ]将vectors[]数组引入,便于使用。
接下来,使用gatenum保存总共的中断门数目,中断门的数目就是idt数组的元素数目,这里可以通过总字节除以gatedesc类型所占字节数求出的。
然后就是用循环来对IDT数组中的各个条目赋值,这里同通过调用SETGATE宏来实现。
最后使用lidt加载IDT即可,指令格式与LGDT类似,至此就完成了中断描述符表(IDT)的初始化过程。
相信在这里,你肯定看到代码的第二句的时候,相信你应该会对gatedesc类型的结构体产生好奇,接下来让我们来了解一下这个结构体的定义:
/* Gate descriptors for interrupts and traps */
struct gatedesc {
unsigned gd_off_15_0 : 16; // low 16 bits of offset in segment
unsigned gd_ss : 16; // segment selector
unsigned gd_args : 5; // # args, 0 for interrupt/trap gates
unsigned gd_rsv1 : 3; // reserved(should be zero I guess)
unsigned gd_type : 4; // type(STS_{TG,IG32,TG32})
unsigned gd_s : 1; // must be 0 (system)
unsigned gd_dpl : 2; // descriptor(meaning new) privilege level
unsigned gd_p : 1; // Present
unsigned gd_off_31_16 : 16; // high bits of offset in segment
};
这里我们发现这个结构体是对中断门的定义也就是中断描述符表的组成部分,知道了每个参数的具体含义,可以方便我们来编写程序;
其中,另一个很重要的点就是SETGATE宏:
/* *
* Set up a normal interrupt/trap gate descriptor
* - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate
* - sel: Code segment selector for interrupt/trap handler
* - off: Offset in code segment for interrupt/trap handler
* - dpl: Descriptor Privilege Level - the privilege level required
* for software to invoke this interrupt/trap gate explicitly
* using an int instruction.
* */
#define SETGATE(gate, istrap, sel, off, dpl) { \
(gate).gd_off_15_0 = (uint32_t)(off) & 0xffff; \
(gate).gd_ss = (sel); \
(gate).gd_args = 0; \
(gate).gd_rsv1 = 0; \
(gate).gd_type = (istrap) ? STS_TG32 : STS_IG32; \
(gate).gd_s = 0; \
(gate).gd_dpl = (dpl); \
(gate).gd_p = 1; \
(gate).gd_off_31_16 = (uint32_t)(off) >> 16; \
}
这里看一下该宏的注释:
*设置正常的中断/陷阱门描述符
*-istrap:1表示陷阱(=异常)门,0表示中断门
*-sel:中断/陷阱处理程序的代码段选择器
*-off:中断/陷阱处理程序的代码段偏移量
*-dpl:描述符权限级别-所需的权限级别
*用于软件明确调用此中断/陷阱门
*使用int指令
这里我们说一下宏中的每个参数的具体含义,由于注释中已经说明了含义,接下来只做一些补充:
第⼀个参数gate是要赋值的对象,它明显是gatedesc类型的数据,所以正好依次赋值给 gatedesc类型的数组idt[i],表⽰第i个门。
第三个参数sel将决定gd_ss,也就是段选择⼦。段选择子一共有五个段:内核代码段,内核数据段,⽤户代码段,⽤户数据段,以及⼀个任务段。
第四个参数off是偏移量,⽤外部数组vectors[i]就可以相应赋值了。这是因为,既然段已经确定,⽽且所有的服务例程全部都写在了内核的代码段⾥,所以vector[i]提供的就是i号中断门的段偏移量,也就是地址。
第五个参数dpl表⽰的是特权级,也就是这些中断服务例程的特权级。内核特权级是0,保存在DPL_KERNEL之中;⽤户特权级是3,保存在 DPL_USER之中。由于中断只能在内核态中调⽤,所以参数必须选择DPL_KERNEL。
下面,来介绍一下lidt指令:
lidt(&idt_pd);
最后调用了lidt指令,来加载idt_pd。来看一下这个指令的具体定义:
static struct pseudodesc idt_pd = {
sizeof(idt) - 1, (uintptr_t)idt
};
6.3 请编程完善trap.c中的中断处理函数trap,在对时钟中断进行处理的部分填写trap函数中处理时钟中断的部分,使操作系统每遇到100次时钟中断后,调用print_ticks子程序,向屏幕上打印一行文字”100 ticks”。
首先看到trap.c中的中断处理函数trap:
/* *
* trap - handles or dispatches an exception/interrupt. if and when trap() returns,
* the code in kern/trap/trapentry.S restores the old CPU state saved in the
* trapframe and then uses the iret instruction to return from the exception.
* */
void
trap(struct trapframe *tf) {
// dispatch based on what type of trap occurred
trap_dispatch(tf);
}
首先看注释能否给我们一些启发:
* 陷阱 - 处理或调度异常/中断。如果 trap() 返回,
* kern/trap/trapentry.s中的代码恢复保存在陷阱帧,然后使用 iret 指令从异常返回。
所以接下来我们去看一下trapentry.s中的代码:
#include <memlayout.h>
# vectors.S sends all traps here.
.text
.globl __alltraps
__alltraps:
# push registers to build a trap frame
# therefore make the stack look like a struct trapframe
pushl %ds
pushl %es
pushl %fs
pushl %gs
pushal
# load GD_KDATA into %ds and %es to set up data segments for kernel
movl $GD_KDATA, %eax
movw %ax, %ds
movw %ax, %es
# push %esp to pass a pointer to the trapframe as an argument to trap()
pushl %esp
# call trap(tf), where tf=%esp
call trap
# pop the pushed stack pointer
popl %esp
# return falls through to trapret...
.globl __trapret
__trapret:
# restore registers from stack
popal
# restore %ds, %es, %fs and %gs
popl %gs
popl %fs
popl %es
popl %ds
# get rid of the trap number and error code
addl $0x8, %esp
iret
接下来看到函数的实现部分,发现函数里面调用了trap_dispatch()函数:
/* trap_dispatch - dispatch based on what type of trap occurred */
static void
trap_dispatch(struct trapframe *tf) {
char c;
switch (tf->tf_trapno) {
case IRQ_OFFSET + IRQ_TIMER:
/* LAB1 YOUR CODE : STEP 3 */
/* handle the timer interrupt */
/* (1) After a timer interrupt, you should record this event using a global variable (increase it), such as ticks in kern/driver/clock.c
* (2) Every TICK_NUM cycle, you can print some info using a funciton, such as print_ticks().
* (3) Too Simple? Yes, I think so!
*/
break;
case IRQ_OFFSET + IRQ_COM1:
c = cons_getc();
cprintf("serial [%03d] %c\n", c, c);
break;
case IRQ_OFFSET + IRQ_KBD:
c = cons_getc();
cprintf("kbd [%03d] %c\n", c, c);
break;
//LAB1 CHALLENGE 1 : YOUR CODE you should modify below codes.
case T_SWITCH_TOU:
case T_SWITCH_TOK:
panic("T_SWITCH_** ??\n");
break;
case IRQ_OFFSET + IRQ_IDE1:
case IRQ_OFFSET + IRQ_IDE2:
/* do nothing */
break;
default:
// in kernel, it must be a mistake
if ((tf->tf_cs & 3) == 0) {
print_trapframe(tf);
panic("unexpected trap in kernel.\n");
}
}
}
我们可以知道,我们需要补写的部分就是:
switch (tf->tf_trapno) {
case IRQ_OFFSET + IRQ_TIMER:
/* LAB1 YOUR CODE : STEP 3 */
/* handle the timer interrupt */
/* (1) After a timer interrupt, you should record this event using a global variable (increase it), such as ticks in kern/driver/clock.c
* (2) Every TICK_NUM cycle, you can print some info using a funciton, such as print_ticks().
* (3) Too Simple? Yes, I think so!
*/
break;
继续看注释:
/*LAB1您的代码:步骤3*/
/*处理定时器中断*/
/*(1)计时器中断后,应使⽤全局变量(增加它)记录此事件,如kern/driver/clock.c中的ticks
*(2)每个TICK_NUM周期,您都可以使⽤⼀个函数打印⼀些信息,例如使⽤print_ticks()函数。
*(3)太简单?是的,我想是的!
*/
这里就是增加一个全局变量来记录此事件,然后当它达到上限TICK_NUM周期就可以调用print_ticks()函数来打印一些信息,放到题目中也就是加入对特定一个静态全局变量加1,并且当计数到达100时,调用print_ticks函数的代码,至此完成了每个一段时间打印"100 ticks"的功能。
代码实现如下:
ticks++;
if(ticks%TICK_NUM==0)
{ print_ticks();}
可以看到最后的输出结果为:
++ setup timer interrupts
100 ticks
100 ticks
100 ticks
100 ticks
100 ticks
100 ticks
100 ticks
100 ticks
扩展练习 Challenge 1(需要编程)
扩展proj4,增加syscall功能,即增加一用户态函数(可执行一特定系统调用:获得时钟计数值),当内核初始完毕后,可从内核态返回到用户态的函数,而用户态的函数又通过系统调用得到内核态的服务(通过网络查询所需信息,可找老师咨询。如果完成,且有兴趣做代替考试的实验,可找老师商量)。需写出详细的设计和分析报告。完成出色的可获得适当加分。
提示: 规范一下 challenge 的流程。
kern_init 调用 switch_test,该函数如下:
static void
switch_test(void) {
print_cur_status(); // print 当前 cs/ss/ds 等寄存器状态
cprintf("+++ switch to user mode +++\n");
switch_to_user(); // switch to user mode
print_cur_status();
cprintf("+++ switch to kernel mode +++\n");
switch_to_kernel(); // switch to kernel mode
print_cur_status();
}
switchto** 函数建议通过 中断处理的方式实现。主要要完成的代码是在 trap 里面处理 T_SWITCH_TO 中断,并设置好返回的状态。
在 lab1 里面完成代码以后,执行 make grade 应该能够评测结果是否正确。
首先我们先了解一下中断处理中的特权级问题:
中断处理得特权级转换是通过门描述符(gate descriptor)和相关指令来完成的。一个门描述符就是一个系统类型的段描述符,一共有4个子类型:调用门描述符(call-gate descriptor),中断门描述符(interrupt-gate descriptor),陷阱门描述符(trap-gate descriptor)和任务门描述符(task-gate descriptor)。与中断处理相关的是中断门描述符和陷阱门描述符。这些门描述符被存储在中断描述符表(Interrupt Descriptor Table,简称IDT)当中。CPU把中断向量作为IDT表项的索引,用来指出当中断发生时使用哪一个门描述符来处理中断。中断门描述符和陷阱门描述符几乎是一样的。中断发生时实施特权检查的过程如下图所示:
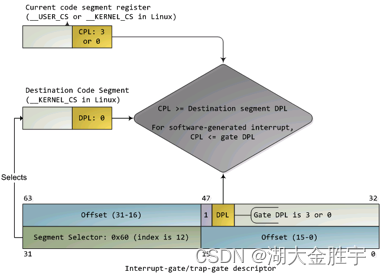
门中的DPL和段选择符一起控制着访问,同时,段选择符结合偏移量(Offset)指出了中断处理例程的入口点。内核一般在门描述符中填入内核代码段的段选择子。产生中断后,CPU一定不会将运行控制从高特权环转向低特权环,特权级必须要么保持不变(当操作系统内核自己被中断的时候),或被提升(当用户态程序被中断的时候)。无论哪一种情况,作为结果的CPL必须等于目的代码段的DPL。如果CPL发生了改变,一个堆栈切换操作(通过TSS完成)就会发生。如果中断是被用户态程序中的指令所触发的(比如软件执行INT n生产的中断),还会增加一个额外的检查:门的DPL必须具有与CPL相同或更低的特权。这就防止了用户代码随意触发中断。如果这些检查失败,会产生一个一般保护异常(general-protection exception)。
接下来,开始编写程序:
首先我们已经在 kern_init 中利用 gdt_init 函数初始化了用户态的 GDT ,切换的时候只需要设置一下几个段寄存器为用户态寄存器就好了。
在中断表中有两个中断, T_SWITCH_TOU 和 T_SWITCH_TOK ,一个是切换到用户态,另一个是切换回内核态,显然是希望我们通过这两个中断来进行上下文切换。内核已经为我们提供了这两个中段号,我们只需要在 ISR 中设置一下段寄存器。trap.h文件中定义了两个专门⽤于实现这两种中断的中断号,如下所示:
/* *
* These are arbitrarily chosen, but with care not to overlap
* processor defined exceptions or interrupt vectors.
* */
#define T_SWITCH_TOU 120 // user/kernel switch
#define T_SWITCH_TOK 121 // user/kernel switch
当然,从用户态切换到内核态需要另外设置中断号使其可以从用户态被中断。
接下来分析跟踪一下 ISR 的流程:
.text
.globl __alltraps
.globl vector0
vector0:
pushl $0
pushl $0
jmp __alltraps
.globl vector1
vector1:
pushl $0
pushl $1
jmp __alltraps
.globl vector2
vector2:
pushl $0
pushl $2
jmp __alltraps
.globl vector3
vector3:
pushl $0
pushl $3
jmp __alltraps
.globl vector4
vector4:
pushl $0
pushl $4
jmp __alltraps
.globl vector5
vector5:
pushl $0
pushl $5
jmp __alltraps
.globl vector6
vector6:
首先在中断表中注册的 vectors 数组中存放着准备参数和跳转到 __alltraps 函数的几个指令,接着跳转到 __alltraps(位于trapentry.S⽂件中)中断处理函数,其内容如下:
#include <memlayout.h>
# vectors.S sends all traps here.
.text
.globl __alltraps
__alltraps:
# push registers to build a trap frame
# therefore make the stack look like a struct trapframe
pushl %ds
pushl %es
pushl %fs
pushl %gs
pushal
# load GD_KDATA into %ds and %es to set up data segments for kernel
movl $GD_KDATA, %eax
movw %ax, %ds
movw %ax, %es
# push %esp to pass a pointer to the trapframe as an argument to trap()
pushl %esp
# call trap(tf), where tf=%esp
call trap
# pop the pushed stack pointer
popl %esp
# return falls through to trapret...
.globl __trapret
__trapret:
# restore registers from stack
popal
# restore %ds, %es, %fs and %gs
popl %gs
popl %fs
popl %es
popl %ds
# get rid of the trap number and error code
addl $0x8, %esp
iret
在 __alltraps(在 kern/trap/trapentry.S 中定义)函数中,将原来的段寄存器压栈后作为参数 struct trapframe *tf 传递给 trap_dispatch ,并在其中分别处理。接下来,让我们了解一下trapframe的结构体,trapframe结构实现位于trap.h⽂件中:
struct trapframe {
struct pushregs tf_regs;
uint16_t tf_gs;
uint16_t tf_padding0;
uint16_t tf_fs;
uint16_t tf_padding1;
uint16_t tf_es;
uint16_t tf_padding2;
uint16_t tf_ds;
uint16_t tf_padding3;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding4;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding5;
} __attribute__((packed));
中断处理函数在退出的时候会把这些参数全部 pop 回寄存器中,于是我们可以趁它还在栈上的时候修改其值,在退出中断处理的时候相应的段寄存器就会被更新。
我们这里只需要在 case T_SWITCH_TOU: 和 case T_SWITCH_TOK: 两个 case 处添加修改段寄存器的代码即可:
//LAB1 CHALLENGE 1 : YOUR CODE you should modify below codes.
case T_SWITCH_TOU:
tf->tf_cs=USER_CS;
tf->tf_ds=USER_DS;
tf->tf_es=USER_DS;
tf->tf_ss=USER_DS;
tf->tf_eflags|= FL_IOPL_MASK; //根据答案,此处设置的flag是为了用户能正常进行IO操作
break;
case T_SWITCH_TOK:
tf->tf_cs = KERNEL_CS;
tf->tf_ds = KERNEL_DS;
tf->tf_es = KERNEL_DS;
tf->tf_eflags &= ~FL_IOPL_MASK;
break;
这样的话,只要触发 T_SWITCH_TOU 和 T_SWITCH_TOK 编号的中断, CPU 指令流就会通过 ISR 执行到这里,并进行内核态和用户态的切换。
这里有一个坑,在输出的时候,由于 in out 是高权限指令,切换到用户态后跑到这两个指令 CPU 会抛出一般保护性错误(即第 13 号中断)。而源码中在切换至用户态之后还会有两次输出( lab1_print_cur_status 和 cprintf ),如果不作处理自然再次导致陷入中断,控制流再次进入 trap_dispatch 中。但是这次 T_GPLT 未被处理,所以会落到 default 中打印错误并退出……于是就递归了。tf->tf_eflags |= 0x3000;的作⽤是为了在切换到⽤户态时,修改IO的特权级,来避免错误。
接下来只需要在 kern/init/init.c 中开启题目开关,然后实现题目要求的两个函数 lab1_switch_to_user 和 lab1_switch_to_kernel 。需要另外注意保持栈平衡。
static void
lab1_switch_to_user(void) {
//LAB1 CHALLENGE 1 : TODO
asm volatile(
"sub $0x8,%%esp \n" //留出ss,esp的空间
"int %0 \n" //中断
"movl %%ebp,%%esp" //恢复栈指针
:
:"i"(T_SWITCH_TOU) //中断号
);
}
static void
lab1_switch_to_kernel(void) {
//LAB1 CHALLENGE 1 : TODO
asm volatile (
"int %0 \n"
"movl %%ebp, %%esp \n"
:
: "i"(T_SWITCH_TOK)
);
}
接下来输入指令make grade可以得到结果如下:
Check Output: (6.1s)
-check ring 0: OK
-check switch to ring 3: OK
-check switch to ring 0: OK
-check ticks: OK
Total Score: 40/40
扩展练习 Challenge 2(需要编程)
用键盘实现用户模式内核模式切换。具体目标是:“键盘输入3时切换到用户模式,键盘输入0时切换到内核模式”。 基本思路是借鉴软中断(syscall功能)的代码,并且把trap.c中软中断处理的设置语句拿过来。
注意:
1.关于调试工具,不建议用lab1_print_cur_status()来显示,要注意到寄存器的值要在中断完成后tranentry.S里面iret结束的时候才写回,所以再trap.c里面不好观察,建议用print_trapframe(tf)
2.关于内联汇编,最开始调试的时候,参数容易出现错误,可能的错误代码如下
asm volatile ( "sub $0x8, %%esp \n"
"int %0 \n"
"movl %%ebp, %%esp"
: )
要去掉参数int %0 \n这一行
3.软中断是利用了临时栈来处理的,所以有压栈和出栈的汇编语句。硬件中断本身就在内核态了,直接处理就可以了。
首先,我们先理解题意,分析题目可以知道该题目要求的是用键盘实现用户模式内核模式切换。具体目标是:“键盘输入3时切换到用户模式,键盘输入0时切换到内核模式”。
所以,我们的思路就是捕获击键,然后调用上面写的两个函数。
我们发现在trap_dispatch函数中,有⼀个中断是专门⽤来处理键盘 输⼊的,内容如下:
case IRQ_OFFSET + IRQ_COM1:
c = cons_getc();
cprintf("serial [%03d] %c\n", c, c);
break;
这里的作用就是捕获击键然后输出通过键盘输入的字符,所以只需要判断输入的字符然后来切换模式就可以了。这里切换模式也就是调用扩展一写的两个函数,所以改写之后的函数为:
case IRQ_OFFSET + IRQ_KBD:
c = cons_getc();
if ( c == '3' ) {
if(tf->tf_cs != USER_CS) {
cprintf("switch to user");
//将CS设置为用户代码段
tf->tf_cs = USER_CS;
//将DS、ES、SS设置为用户数据段
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
//设置eflags 确保ucore可以在用户模式下使用IO
tf->tf_eflags |= FL_IOPL_MASK;
print_trapframe(tf);
}else
{
cprintf("you are in user!");
}
}else if ( c == '0' ) {
if(tf->tf_cs!=KERNEL_CS)
{
cprintf("switch to kernel");
tf->tf_cs = KERNEL_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = KERNEL_DS;
tf->tf_eflags &= ~FL_IOPL_MASK;
print_trapframe(tf);
}else
{
cprintf("you are in kernel!");
}
}
cprintf("kbd [%03d] %c\n", c, c);
break;
可以看到输入3的时候,屏幕输出的结果如下:
switch to usertrapframe at 0x7b7c
edi 0x00000000
esi 0x00010094
ebp 0x00007be8
oesp 0x00007b9c
ebx 0x00010094
edx 0x0000000c
ecx 0x00000000
eax 0x00000003
ds 0x----0023
es 0x----0023
fs 0x----0023
gs 0x----0023
trap 0x00000021 Hardware Interrupt
err 0x00000000
eip 0x00100075
cs 0x----001b
flag 0x00003206 PF,IF,IOPL=3
esp 0x001036fc
ss 0x----0023
输入0的结果如下:
switch to kerneltrapframe at 0x10fcd4
edi 0x00000000
esi 0x00010094
ebp 0x00007be8
oesp 0x0010fcf4
ebx 0x00010094
edx 0x0000000c
ecx 0x00000000
eax 0x00000003
ds 0x----0010
es 0x----0010
fs 0x----0023
gs 0x----0023
trap 0x00000021 Hardware Interrupt
err 0x00000000
eip 0x00100075
cs 0x----0008
flag 0x00000206 PF,IF,IOPL=0
可以看到完成了模式的切换,所以实现是正确的。
参考答案对⽐
练习1-4的参考答案与本实验报告中的解答基本一致,为数不多的几点区别如下所示:
- 在练习1中本实验报告中较为详细的分析了Makefile中每一条与生成ucore.img的指令,包括tools/function.mk中使用宏来生成编译规则的内容,而参考答案中仅按照Makefile单个文件中按照每一个阶段对编译过程进行了分析,而没有涉及到生成编译规则的内容,该内容也恰是该Makefile文件中最不容易看懂的部分;
- 在练习2的调试中,参考答案将gdb调试结果输出到log文件中,而本实验中的解答只是将调试结果输出到屏幕上;
练习5的参考解答与本实验报告中的解答一致,均是利用栈上保存的数组来查找栈上所有栈帧的内容;
练习6的参考答案解法与本实验报告解法一致;
在拓展练习部分:
- challenge 1:
- 在切换到用户态部分的解答,参考答案是在ISR中构造了一个临时的用户栈,然后在中端返回之后再使用ebp恢复真确的esp数值;
- 基本和参考答案⼀致,通过设置tf信息来完成状态切换。
- chanllenge 2:
- 所提供参考答案没有关于challenge 2的解答,因此无法进行分析对比;
知识点列举
在本实验设计到的知识点分别有:
- 基于分段的内存管理机制;
- CPU的中断机制;
- x86 CPU的保护模式;
- 计算机系统的启动过程;
- ELF文件格式;
- 读取LBA模式硬盘的方法;
- 编译ucore OS和bootloader的过程;
- GDB的使用方法;
- c函数的函数调用实现机制;
对应到的OS中的知识点分别有:
- 物理内存的管理;
- 外存的访问;
- OS的启动过程;
- OS中对中断机制的支持;
- OS使用保护机制对关键代码和数据的保护;
两者的关系为,前者硬件中的机制为OS中相应功能的实现提供了底层支持;
实验未涉及知识点列举
OS原理中很重要,但是本次实验没有涉及到的知识点有:
- 操作系统的线程、进程管理、调度,以及进程间的共享互斥;
- 虚拟内存的管理,页式内存管理机制;
- 文件系统;
- 并发实现机制
- 进程调度管理















 5852
5852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









