







第五章 深度学习
八、目标检测
3. 目标检测模型
3.2 YOLO 系列
3.2.4 YOLOv4(2020 年 4 月)
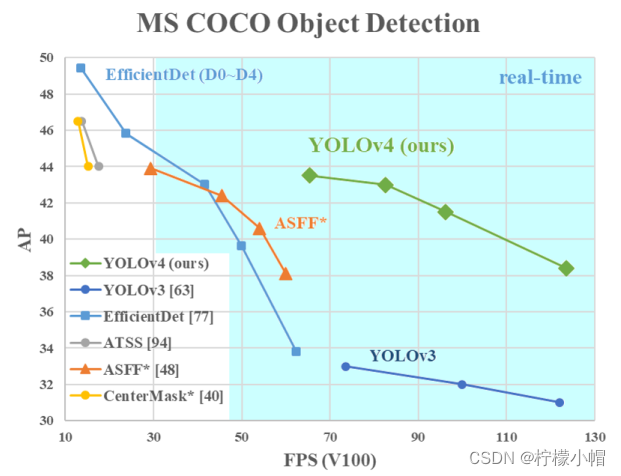
YOLOv4 将最近几年 CV 界大量的研究成果集中在一套模型中,从检测速度、精度、定位准确率上有了明显改善(相对于 YOLOv3,AP 值和 FPS 分别上涨了 10%和 12%)。YOLOv4 主要改进点有:
- 输入端。采用更大的输入图像,采用新的样本增强方法;
- 骨干网。采用新的、改进的骨干网 CSPDarknet53;新的激活函数和 dropout 策略;
- 特征融合部分。插入 SPP,FPN+PAN 等新的结构;
- 输出端。采用改进的损失函数。
3.2.4.1 Backbone, Neck, Head
首先,作者提出了一个目标检测的通用框架,将一个目标检测框架分为 Input,Backbone,Neck,Head 几个部分:
- Input(输入):输入部分,如图像、批次样本、图像金字塔
- Backbone(骨干网):各类 CNN,主要作用是对图像中的特征做初步提取
- Neck(脖子):特征融合部分,主要作用是实现多尺度检测
- Head(头):产生预测结果
YOLOv4 从以上几个结构部分均进行了优化和改进,取得了较好的综合效果。
3.2.4.2 模型结构
YOLOv4 模型结构如下图所示:
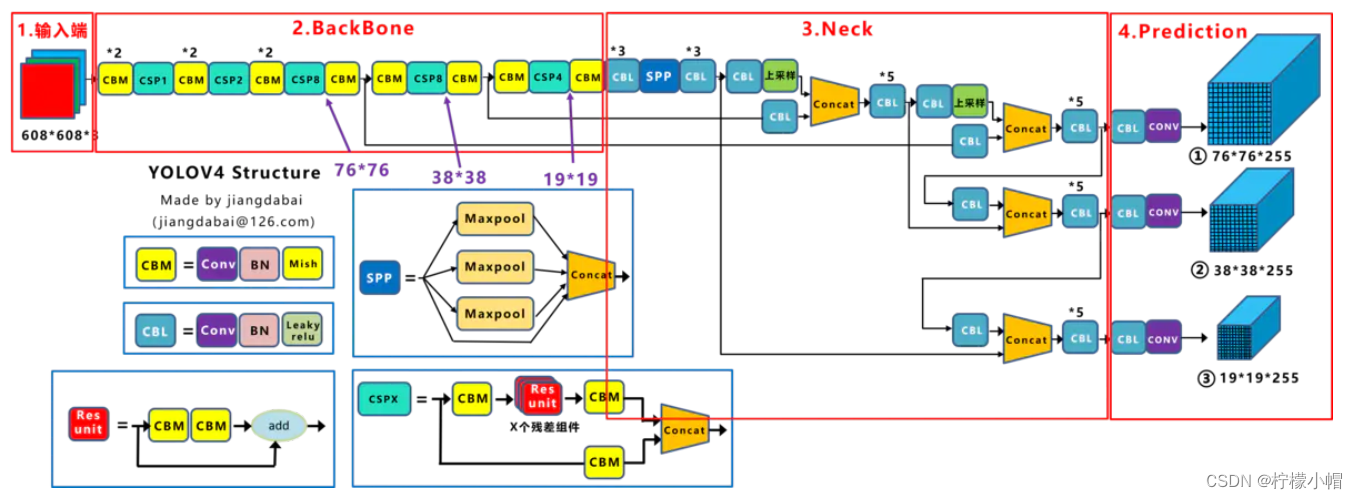
3.2.4.3 主要改进
-
输入端
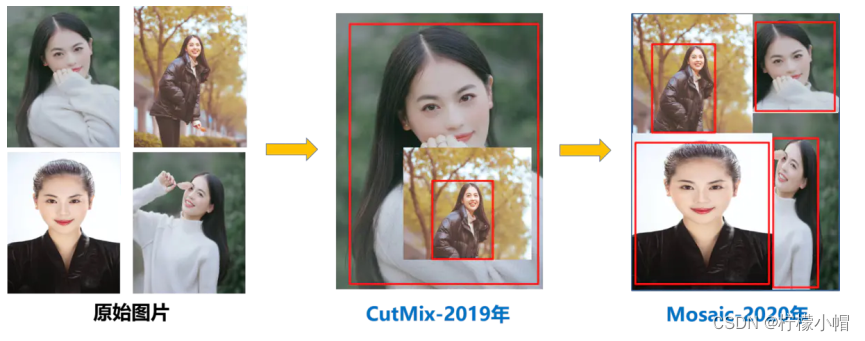
(1)Mosaic 数据增强。Mosaic 是参考 2019 年提出的 CutMix 数据增强的方式,但 CutMix 只使用了两张图片进行拼接,而 Mosaic 数据增强则采用了 4 张图片,随机缩放,随机裁剪,随机排布的方式进行拼接 。这样使得模型更获得更多相关或不相关的上下文信息,学习到更加鲁棒的特征。
(2)自对抗训练(SAT,Self Adversarial Trainning)。自对抗训练代表了一种新的数据增强技术,操作在两个向前后阶段。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自己进行了对抗性的攻击,改变原始图像来制造图像上没有需要的对象的假象。在第二阶段,训练神经网络以正常的方式在修改后的图像上检测目标。
(3)CmBN(交叉小批量归一化)。BN 策略可以缓解梯度消失、过拟合,增加模型稳定性。BN 在计算时仅仅利用当前迭代批次样本进行计算,而 CBN 在计算当前时刻统计量时候会考虑前 k 个时刻统计量,从而实现扩大 batch size 操作。CmBN 是 CBN 的修改版,CBN 在第 t 时刻,也会考虑前 3 个时刻的统计量进行汇合。
-
Backbone 部分
(1)CSPDarknet53。CSPDarknet53 是在 YOLOv3 主干网络 Darknet53 的基础上,借鉴 2019 年的 CSPNet 的经验,产生的 Backbone 结构,其中包含了 5 个 CSP 模块。 其结构如下图所示:
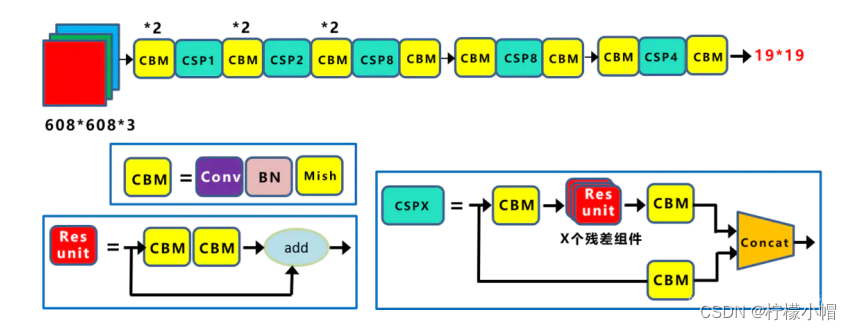
CSPNet(Cross Stage Partial Network,跨阶段局部网络)主要用来提高学习能力同时,降低模型对资源的消耗。每个 CSPX 中包含 3+2 × X 个卷积层,因此整个主干网络 Backbone 中一共包含
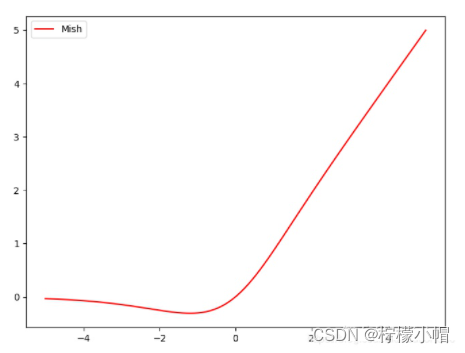
2+(3+2×1)+2+(3+2×2)+2+(3+2×8)+2+(3+2×8)+2+(3+2×4)+1=72 个卷积层。每个 CSP 模块前面的卷积核大小都是 3x3,步长为 2,因此可以起到下采样的作用。因为 Backbone 有 5 个 CSP 模块,输入图像是 608 x 608,所以特征图的变化规律是:608->304->152->76->38->19 经过 5 次 CSP 模块后得到 19*19 大小的特征图。Backbone 采用 Mish 激活函数。(2)Mish 激活函数。一种新的、非单调、平滑激活函数,其表达式为 f ( x ) = x ∗ t a n h ( l o g ( 1 + e x ) ) f(x) = x*tanh(log(1+e^x)) f(x)=x∗tanh(log(1+ex)),更适合于深度模型。根据论文实验,精度比 ReLU 略高。
(3)Dropblock 策略。Dropblock 是一种针对卷积层的正则化方法,实验在 ImageNet 分类任务上,使用 Resnet-50 结构,能够将分类精度提高 1.6%,在 COCO 检测任务上,精度提升 1.6%。其原理是在特征图上通过 dropout 一部分相邻的区域,使得模型学习别的部位的特征,从而表现出更好的泛化能力。
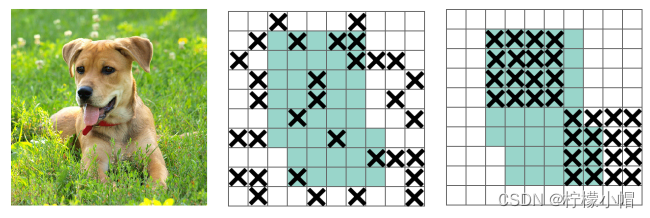
Dropblock 模块主要有两个参数,block_size 和 γ。其中,block_size 表示区域的大小,正常可以取 3,5, 7,当 block_size=1 时,dropout 退化为传统的 dropout。 -
Neck 部分
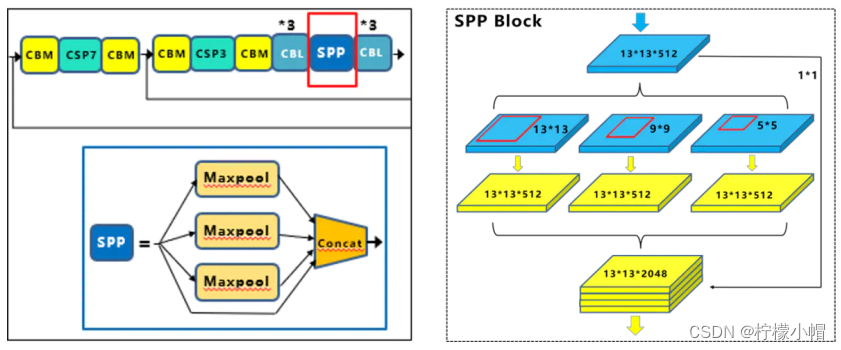
(1)SPP 模块。SPP 模块位于 Backbone 网络之后,使用 k={1x1, 5 x 5, 9 x 9, 13 x 13}最大池化操作,再将不同尺度的特征图进行 Concat 融合。
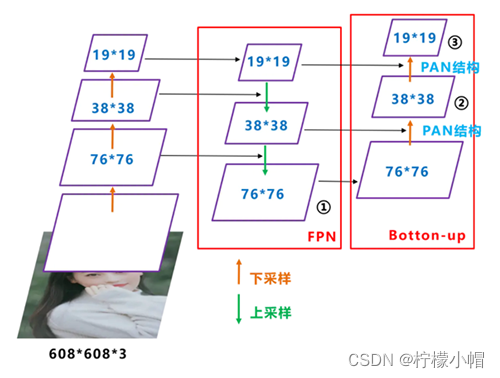
(2)FPN + PAN. FTP 指特征金字塔,其思想是将高层次卷积得到的较小特征图进行上采样,和低层次较大的特征图进行特征融合(自顶向下),这样做的优点是将高层次较强的语义特征传递下来。而 PAN 结构借鉴 2018 年图像分割领域 PANet(Path Aggregation Network,路径聚合网络)的创新点,FPN 的后面添加一个自底向上的特征金字塔,将低层次强定位特征传递上来(自底向上),从而形成对 FPN 的补充。如下图所示:
-
Head 部分
(1)CIOU_loss。IOU 用来度量预测定位是否准确,但存在一定的问题,如下图所示:
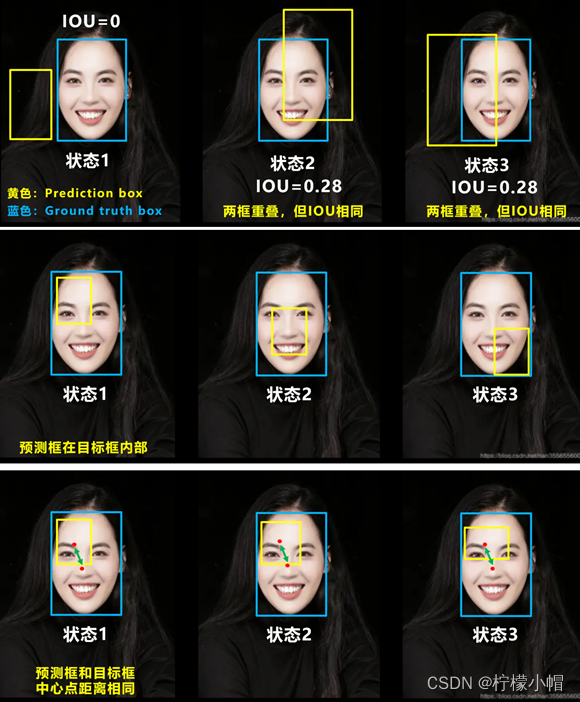
针对以上问题,出现了几个 IOU 的改进策略:
GIOU_loss:在 IOU 的基础上,解决了边界框不重合的问题
DIOU_loss:在 IOU 和 GIOU 的基础上,考虑了边界框中心点距离的信息
CLOU_Loss: 在 DIOU 的基础上,考虑边界框宽高比的尺度信
所以,CIOU_loss 在定义预测 box、真实 box 损失值时,考虑了重叠面积大小、中心点距离、长宽比例,定位更加精确。CIOU_loss 定义如下:
L C I O U = 1 − I o U + ρ 2 ( b , b g t ) c 2 + α v L_{CIOU} = 1 - IoU + \frac{\rho^2(b, b^{gt})}{c^2} + \alpha v LCIOU=1−IoU+c2ρ2(b,bgt)+αv
其中, ρ \rho ρ表示欧式距离,c 表示覆盖两个 box 的最小封闭盒子对角线长度, α \alpha α是一个正的权衡参数,v 衡量长宽比的一致性,分别定义为:
v = 4 π 2 ( a r c t a n w g t h g t − a r c t a n w h ) 2 v = \frac{4}{\pi ^2}(arctan \frac{w^{gt}}{h^{gt}} - arctan \frac{w}{h})^2 v=π24(arctanhgtwgt−arctanhw)2
α = v ( 1 − I o U ) + v \alpha = \frac{v}{(1 - IoU) + v} α=(1−IoU)+vv
(2)DIOU_NMS。NMS 主要用于预测框的筛选,YOLOv4 使用 DIOU 来进行 NMS(即选择 DIOU 最大的值),实验证明在重叠目标的检测中,DIOU_NMS 的效果优于传统的 NMS。如下图所示:

3.2.4.4 效果
3.2.5 YOLOv5(2020 年 6 月)
YOLOv5 在 YOLOv4 基础上,做了一些工程和代码方面的优化。YOLOv5 是否为一个独立的版本,目前还存在争议,有些人认为其创新度不够,不能称为一个独立的版本。YOLOv5 没有发表论文,通过对其代码(https://github.com/ultralytics/yolov5)进行分析,可以总结出一些改进优化之处。
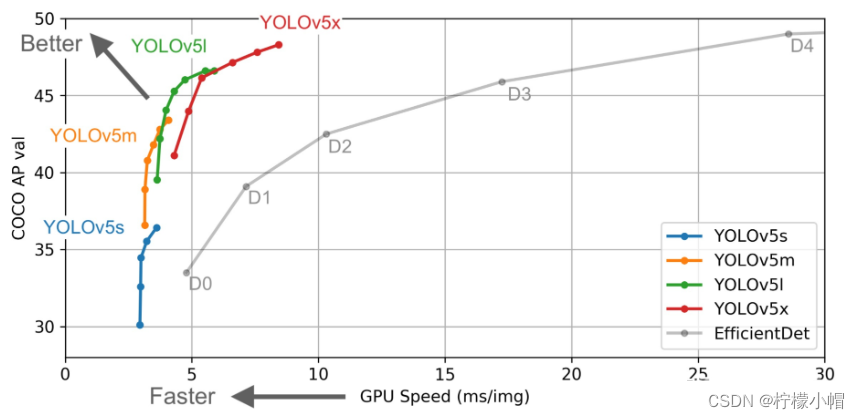
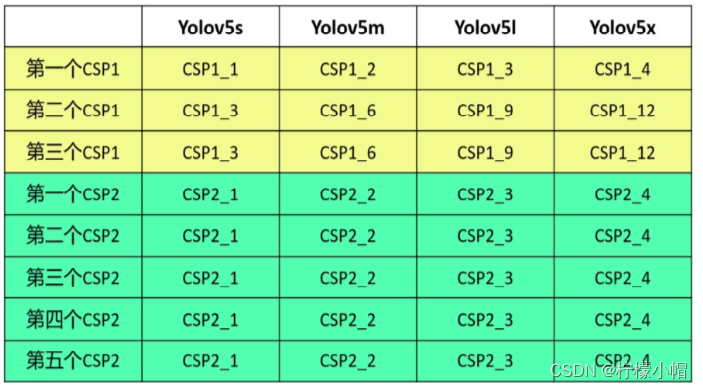
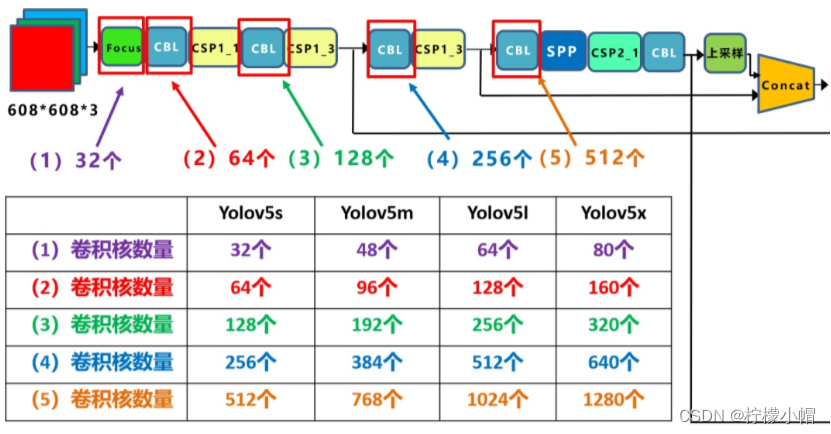
YOLOv5 提供了四个版本:Yolov5s,Yolov5m,Yolov5l,Yolov5x。其中,Yolov5s 是 Yolov5 系列中深度最小,特征图的宽度最小的网络,后面的 3 种都是在此基础上不断加深,不断加宽,从而增加模型性能。
3.2.5.1 改进
-
采用自适应锚框计算。YOLOv5 针对不同数据集,采用不同配置的 Anchors,每次训练时,自适应的计算不同训练集中的最佳锚框值;
-
自适应图片缩放。在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。Yolov5 代码中对此进行了改进,作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。YOLOv5 对原始图像进行计算,自适应对图像添加最少的边沿部分;
-
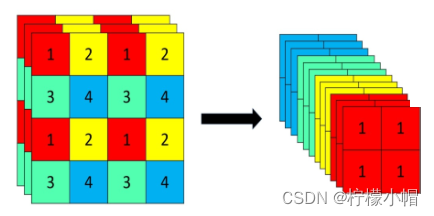
加入 Focus 结构。YOLO5 在骨干网部分加入了 Focus 结构,采用切片操作,将大图像降采样为通道数更多的小图像,然后进行卷积运算,提取特征,如下图所示:
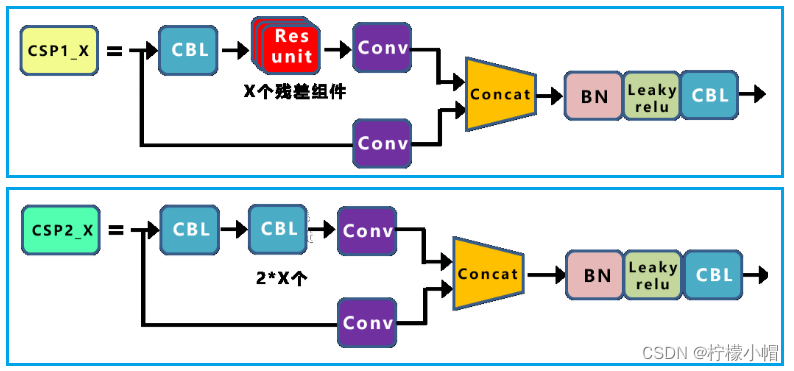
- 两种结构的 CSP 模块,加强网络特征融合的能力,如下图所示:
3.2.5.2 整体结构
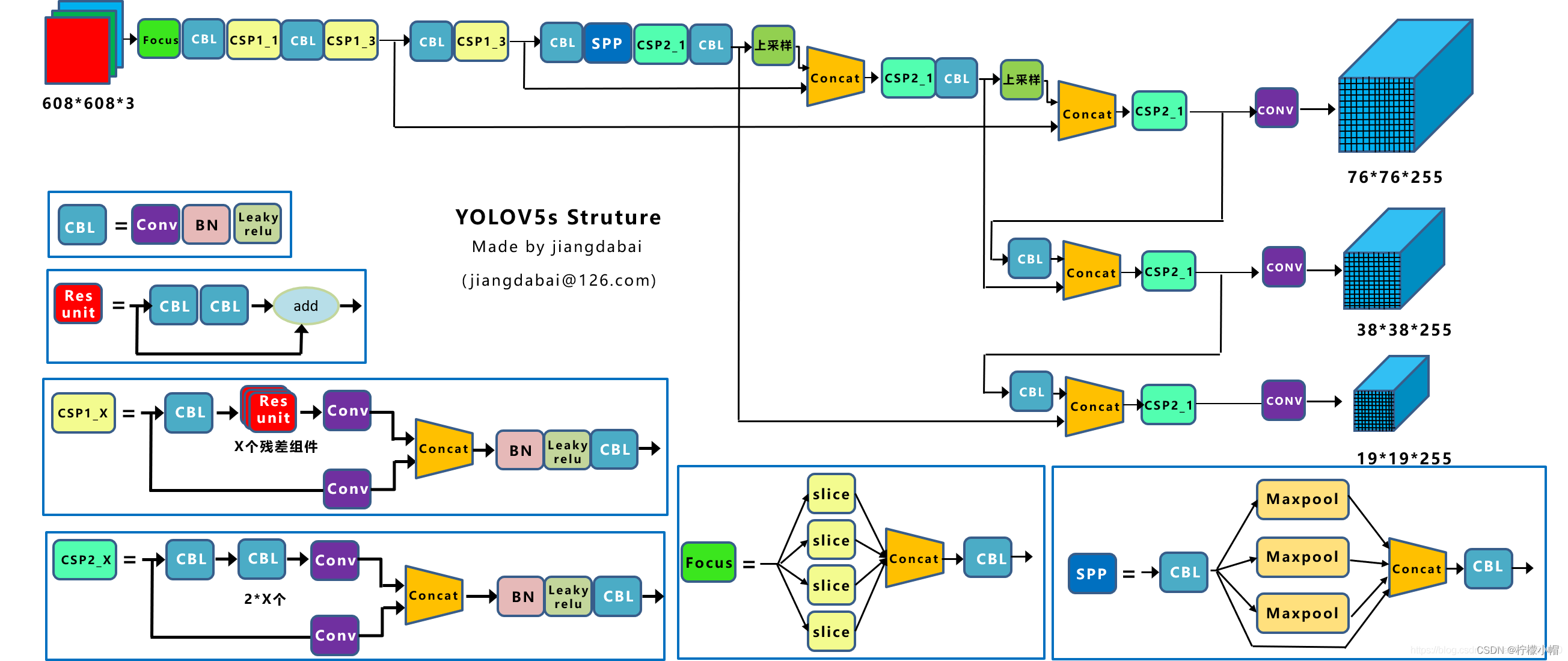
3.2.5.3 不同深度与宽度
以下是不同结构的深度差异:
以下是不同模型的宽度差异:
3.2.5.4 结论
YOLOv5 虽然创新性不足,但在代码和工程方面做了很多优化,模型参数更少(YOLOv5 大小仅有 27M,YOLOv4 为 244M,两者性能相当),使用配置更加方便,更适合移动端使用,是继 YOLOv3 之后的又一个主流版本。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











