







- 下载Hive和PIG
Pig安装包地址:https://mirrors.tuna.tsinghua.edu.cn/apache/pig/
- 通过工具上传Hive和Pig压缩包
- 解压Hive和Pig
[hadoop@master software]$ tar zxvf apache-hive-1.2.2-bin.tar.gz -C /opt/module/
[hadoop@master software]$ tar zxvf pig-0.17.0.tar.gz -C /opt/module/
- 配置Hive
4.1设置hive环境变量
[hadoop@master software]$ sudo vi /etc/profile
按i进入编辑模式
添加(根据自己安装的路径来写)
export HIVE_HOME=/opt/module/apache-hive-1.2.2-bin
export PATH=$PATH:$HIVE_HOME/bin

执行
source /etc/profile
执行
hive --version
有hive的版本显现,安装成功!

4.2配置hive配置文件
进入hive配置文件夹
cd /opt/module/apache-hive-1.2.2-bin/conf
新建hive-site.xml文件
vi hive-site.xml
复制粘贴下列代码
<configuration>
<property>
<!-- 元数据库的链接地址 mysql -->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<!-- 指定mysql驱动 -->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<!-- 指定mysql用户名 -->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>hadoop to use against metastore database</description>
</property>
<property>
<!-- 指定mysql密码 请输入自己的MySQL连接密码 -->
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
</configuration>
将MySQL的驱动mysql-connector-java-5.1.38-bin.jar添加到hive安装目录的lib下
可以到这个地址https://repo1.maven.org/maven2/mysql/mysql-connector-java/下载
(通过第三方工具将驱动器放到lib下,参考步骤2)
4.3 安装mysql(yum源安装)
(1)检查系统中是否已安装 MySQL。
rpm -qa | grep mysql
返回空值的话,就说明没有安装 MySQL 。
注意:在新版本的CentOS7中,默认的数据库已更新为了Mariadb,而非 MySQL,所以执行 yum install mysql 命令只是更新Mariadb数据库,并不会安装 MySQL 。
(2)查看已安装的 Mariadb 数据库版本。
rpm -qa|grep -i mariadb
(3)卸载已安装的 Mariadb 数据库。
rpm -qa|grep mariadb|xargs rpm -e --nodeps
(4)再次查看已安装的 Mariadb 数据库版本,确认是否卸载完成。
rpm -qa|grep -i mariadb
(5)下载安装包文件。
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
(6)安装mysql-community-release-el7-5.noarch.rpm包。
rpm -ivh mysql-community-release-el7-5.noarch.rpm
安装完成之后,会在 /etc/yum.repos.d/ 目录下新增 mysql-community.repo 、mysql-community-source.repo 两个 yum 源文件。
执行 yum repolist all | grep mysql 命令查看可用的 mysql 安装文件。
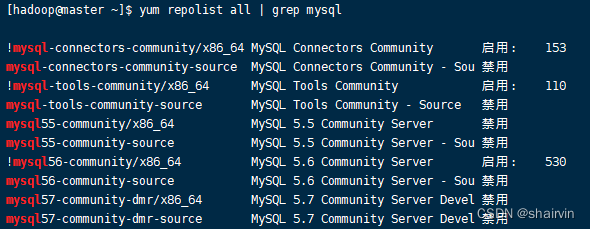
- 安装mysql。
yum install mysql-server
- 检查mysql是否安装成功。
rpm -qa | grep mysql
- 启动 mysql 服务 。
systemctl start mysqld.service #启动 mysql
systemctl restart mysqld.service #重启 mysql
systemctl stop mysqld.service #停止 mysql
systemctl enable mysqld.service #设置 mysql 开机启动
mysql常用文件路径:
/etc/my.cnf 这是mysql的主配置文件
/var/lib/mysql mysql数据库的数据库文件存放位置
/var/logs/mysqld.log 数据库的日志输出存放位置
(10)设置密码 。
mysql5.6 安装完成后,它的 root 用户的密码默认是空的,我们需要及时用 mysql 的 root 用户登录(第一次直接回车,不用输入密码),并修改密码。
# mysql -u root
mysql> use mysql;
mysql> update user set password=PASSWORD("这里输入root用户密码") where User='root';
mysql> flush privileges;
(11)设置远程主机登录
mysql> GRANT ALL PRIVILEGES ON *.* TO 'your username'@'%' IDENTIFIED BY 'your password';
- 创建数据库和用户
mysql> create database hive;
mysql>show databases;
mysql>grant all on hive.* to 'hive'@'%' identified by 'hive';(将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码)
mysql>flush privileges;(刷新mysql系统权限关系表)
mysql>exit;(quit;)
- 数据库的初始化
schematool -initSchema -dbType mysql(切换到hive的bin目录下执行)
4.4测试
- 查看现在的hadoop中的HDFS存了什么
[hadoop@master conf]$ hadoop fs -lsr /
- 进入hive并创建一个测试库和测试表
[hadoop@master conf]$ hive
hive> create database hive1;
hive> show databases;
查询一下HDFS有什么变化

多了一个库hive1
(3)查看mysql的hive数据库变化
[hadoop@master conf]$ mysql -u root -p
切换成hive数据库并查看DBS表
mysql> use hive;
mysql> select * from DBS;
 Hive客户端命令
Hive客户端命令
5.1数据准备
在/opt/目录下创建data文件夹
[hadoop@master opt]$ sudo mkdir data
修改文件权限
[hadoop@master opt]$ sudo chown hadoop:hadoop data
[hadoop@master opt]$ cd data
通过第三方工具上传数据文件,详情请看步骤2
![]()
在HDFS上创建存放数据的文件
hdfs dfs -mkdir -p /tenant/hadoop/hivedata
上传数据
hdfs dfs -mkdir /tenant/hadoop/hivedata
hdfs dfs -put employee /tenant/hadoop/hivedata
hdfs dfs -put myFunction_data.txt /tenant/hadoop/hivedata
hdfs dfs -put partitionData /tenant/hadoop/hivedata
hdfs dfs -put people /tenant/hadoop/hivedata
hdfs dfs -put person /tenant/hadoop/hivedata
hdfs dfs -put weather /tenant/hadoop/hivedata
hdfs dfs -put weibouser /tenant/hadoop/hivedata
5.2客户端操作
通过命令行hive登陆hive客户端
[hadoop@master bin]$ hive
- 创建数据库操作
CREATE DATABASE hive_db;
- 创建托管表
USE hive_db;
CREATE TABLE internal_table_test(
id INT,
name STRING,
phone STRING,
address STRING
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
- 创建临时表
CREATE TEMPORARY TABLE tmp_table_test(
id INT,
name STRING,
phone STRING,
address STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
- 插入数据
LOAD DATA INPATH '/tenant/hadoop/hivedata/person' INTO TABLE internal_table_test;
INSERT INTO TABLE tmp_table_test SELECT * FROM internal_table_test;
- 查询全表数据
SELECT * FROM internal_table_test;
- 通过MR实现条件查询
SELECT * FROM internal_table_test WHERE id < 3;
- 通过MR实现排序查询
SELECT * FROM internal_table_test ORDER BY id ASC;
- 分组查询
SELECT COUNT(*) FROM internal_table_test GROUP BY id HAVING COUNT(*) < 4;
- 两表连接查询
SELECT * FROM (SELECT * FROM internal_table_test a JOIN tmp_table_test b ON a.id = b.id) c WHERE c.id = 1;
- 覆盖插入
INSERT OVERWRITE TABLE internal_table_test SELECT * FROM tmp_table_test WHERE name != 'NULL';
SELECT * FROM internal_table_test;
- 清空表
TRUNCATE TABLE internal_table_test;
SELECT * FROM internal_table_test;
- 复杂数据类型使用
CREATE TABLE IF NOT EXISTS employee(
id INT COMMENT 'employee id',
company STRING,
money FLOAT COMMENT 'work money',
mapData MAP<STRING,STRING>,
arrayData ARRAY<INT>,
structData STRUCT<a:INT,b:DOUBLE>,
other UNIONTYPE<INT,STRING,ARRAY<INT>,STRUCT<a:INT,b:STRING,c:FLOAT>>
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '@' MAP KEYS TERMINATED BY '$' STORED AS TEXTFILE;
LOAD DATA INPATH '/tenant/username/hivedata/employee' INTO TABLE employee;
SELECT * FROM employee;
SELECT mapdata ['hello'] FROM employee;
SELECT arraydata[1] FROM employee;
SELECT structdata.a FROM employee;
- 创建并使用分区表
CREATE TABLE partition_test (
id INT,
name STRING
) PARTITIONED BY (gender STRING,age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
- 指定分区单条插入数据
INSERT INTO TABLE partition_test PARTITION (gender='m',age='19') VALUES(1,'andi');
- 创建分桶表
CREATE TABLE bucket_test(
uid STRING,
screen_name STRING,
name STRING,
city INT,
location STRING,
url STRING,
gender STRING,
followersnum INT,
friendsnum INT,
statusesnum INT,
favouritesnum INT,
created_at TIMESTAMP
)PARTITIONED BY (province INT) CLUSTERED BY (uid) SORTED BY (followersnum DESC) INTO 5 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
- 创建临时表
创建临时表(要使得分桶和动态分区生效,则必须使用INSTER语句向指定表插入数据)并插入数据。
CREATE TEMPORARY TABLE tem_bucket(
uid STRING,
screen_name STRING,
name STRING,
province INT,
city INT,
location STRING,
url STRING,
gender STRING,
followersnum INT,
friendsnum INT,
statusesnum INT,
favouritesnum INT,
created_at TIMESTAMP
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
LOAD DATA INPATH '/tenant/username/hivedata/weibouser' INTO TABLE tem_bucket;
- 临时表中的数据插入到bucket_test表中设置
将临时表中的数据插入到bucket_test表中,在插入数据之前,需要先设置如下参数,详细操作如图所示:打开动态分区功能:set hive.exec.dynamic.partition=true将动态分区模式设置为非严格模式,允许所有分区字段都可以使用动态分区:set hive.exec.dynamic.partition.mode=nonstrict设置每个执行MR节点能够创建的最大分区数为50,此值不是必须的,默认是100:set hive.exec.max.dynamic.partitions.pernode=50设置在所有执行MR的节点上能够创建的最大分区数,此值不是必须的,默认是1000:set hive.exec.max.dynamic.partitions=50打开分桶功能:set hive.enforce.bucketing=true设置在提交MR作业时,reduce task的个数是5个,此值需要与分桶个数相同:set mapred.reduce.tasks=5
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=50;
set hive.exec.max.dynamic.partitions=50;
set hive.enforce.bucketing=true;
set mapred.reduce.tasks=5;
INSERT OVERWRITE TABLE bucket_test PARTITION(province) SELECT uid,screen_name,name,city,location,url,gender,followersnum,friendsnum,statusesnum ,favouritesnum,created_at,province FROM tem_bucket SORT BY followersnum DESC;
- 查询分桶表
SELECT followersnum,name,province,url FROM bucket_test LIMIT 10;
- 普通表查询结果
SELECT followersnum,name,province,url FROM tem_bucket LIMIT 10;
- 查询province=11分区的数据
SELECT followersnum,name,province,url FROM bucket_test WHERE province=11 LIMIT 10;
- 排序记过对比
SELECT followersnum,name,province,url FROM bucket_test WHERE province=11 ORDER BY followersnum DESC LIMIT 10;
- 查询分区信息
dfs -ls /user/hive/warehouse/hive_db.db/bucket_test;
- 指定的分桶个数
dfs -ls /user/hive/warehouse/hive_db.db/bucket_test/province=11;
- Pig安装与客户端使用
6.1安装Pig
编辑/etc/profile文件
[hadoop@master software]$ sudo vi /etc/profile
添加
export PIG_HOME=/opt/module/pig-0.17.0
export PATH=$PATH:$PIG_HOME/bin
保存退出
:wq
让配置生效
source /etc/profile
修改/opt/module/hadoop-2.7.1/etc/hadoop/mapred-site.xml
[hadoop@master data]$vi /opt/module/hadoop-2.7.1/etc/hadoop/mapred-site.xml
添加
<property>
<name>mapreduce.jobhistory.address</name>
<!-- 配置实际的Master主机名和端口-->
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<!-- 配置实际的Master主机名和端口-->
<value>master:19888</value>
</property>
保存退出后开启JobHistoryServer
sudo /opt/module/hadoop-2.7.1/sbin/mr-jobhistory-daemon.sh start historyserver
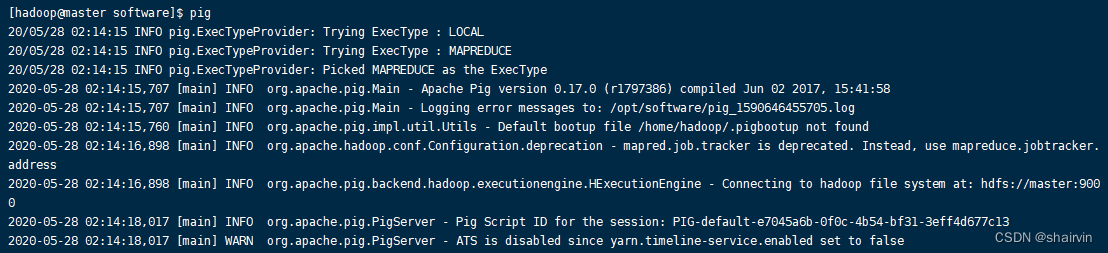
测试是否安装成功
[hadoop@master software]$pig
6.2Pig客户端使用
- 在master节点的/opt/data下创建数据文件并输入下列数据
[hadoop@master data]$ vi student.txt
C01,N0101,82
C01,N0102,59
C01,N0103,65
C02,N0201,81
C02,N0202,82
C02,N0203,79
C03,N0301,56
C03,N0302,92
C03,N0306,72
[hadoop@master data]$ vi teacher.txt
C01,Zhang
C02,Sun
C03,Wang
C04,Dong
- 将数据上传到HDFS上
[hadoop@master data]$ hdfs dfs -mkdir /tenant/hadoop/pigdata
[hadoop@master data]$ hdfs dfs -put student.txt /tenant/hadoop/pigdata
[hadoop@master data]$ hdfs dfs -put teacher.txt /tenant/hadoop/pigdata
- 加载和存储(Load,Store)
records = load'hdfs://master:9000/tenant/hadoop/pigdata/student.txt' using PigStorage(',') as(classNo:chararray, studNo:chararray, score:int);
dump records;
store records into ' hdfs://master:9000/tenant/hadoop/pigdata/student_out' using PigStorage(':');
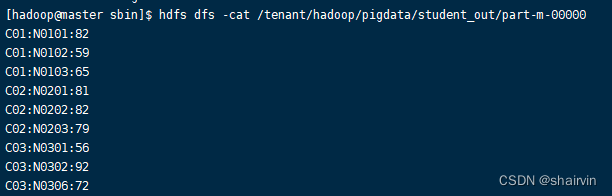
查看hdfs://master:9000/tenant/hadoop/pigdata/student_out目录下的part-m-00000文件
[hadoop@master sbin]$ hdfs dfs -cat /tenant/hadoop/pigdata/student_out/part-m-00000
其中的load是加载操作,store是存储操作。他们分别可以指定其分隔符,比如上例中的逗号和分号。
(4)筛选(Filter)
records_c01 = filter records by classNo=='C01';
dump records_c01;
(5)Foreach Generate
score_c01 = foreach records_c01 generate 'Teacher',$1,score;
dump score_c01;

(6)分组(group)
grouped_records = group records by classNo parallel 2;
dump grouped_records;

- Join
r_student = load'hdfs://master:9000/tenant/hadoop/pigdata/student.txt' using PigStorage(',') as (classNo:chararray, studNo: chararray, score: int);
r_teacher = load'hdfs://master:9000/tenant/hadoop/pigdata/teacher.txt' using PigStorage(',') as (classNo:chararray, teacher: chararray);
r_joined = join r_student by classNo,r_teacher by classNo;
dump r_joined;

(8)COGROUP
r1 = cogroup r_student by classNo,r_teacher by classNo;
dump r1;

(9)Cross
r = cross r_student,r_teacher;
dump r;

- 排序(Order)
r = order r_student by score desc, classNo asc;
dump r;

- 联合(Union)
r_union = union r_student, r_teacher;
dump r_union;

更多内容关注公众号“测试小号等闲之辈”阅读~















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









