







OpenAI 于 12 月 5 日起举办了为期 12 天的发布会,每天发布新的人工智能功能和产品。期间推出了 o1 及 ChatGPT Pro,o1 性能提升且支持多模态;强化微调技术可训练专家模型;Sora 视频生成器正式亮相;Canvas 协作平台发布;与苹果合作实现多方面功能;高级语音模式增加视觉能力等。还包括搜索功能升级、开放 o1 API、推出热线电话、桌面版更新等,最后预告了 o3 和 o3-mini 两款新模型,这些展示了 OpenAI 在模型能力提升、开发工具丰富及多场景应用等方面的进展。
官方具体的更新说明链接:https://help.openai.com/en/articles/10271060-12-days-of-openai-release-updates
发布会回放:https://openai.com/12-days/
详细内容
Day 1- o1 & ChatGPT Pro
link:https://openai.com/index/introducing-chatgpt-pro/
ChatGPT Pro计划完全可供购买。o1 Pro模式仅适用于ChatGPT Pro订阅用户。
-
发布o1完整版本:基于客户对o1预览版的反馈,对o1进行了优化,o1变得更加智能、快速,支持多模态,并且在指令跟随方面表现更好。
-
-
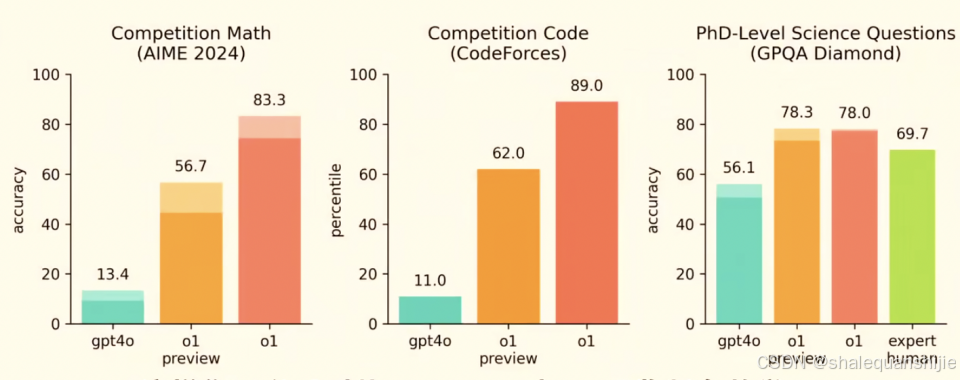
o1完整版在数学、编程、博士阶段科学问题(困难问题)领域的性能远超GPT4o,在科学问题领域,超越人类专家,并在数学、编程领域的性能较o1-preview有显著提升。
-
o1将更适合日常使用场景,不一定只是非常难的数学和编程问题,自适应思考时间会随着用户的query进行变化。与o1-preview相比,思考速度提高了50%,犯严重错误的数量减少了约34%。
-
o1的特别之处在于它是首个会在回答之前进行思考的训练模型,这意味着回答的效果更好更详细且正确。
-
o1具备多模态能力,能够同时处理图像和文本进行推理。
-
-
发布ChatGPT Pro,每月$200
-
ChatGPT Pro可让大规模访问 OpenAI 的最佳模型和工具。该计划包括无限制访问模型 OpenAI o1,以及 o1-mini、GPT-4o 和高级语音模式( Advanced Voice)等。
-
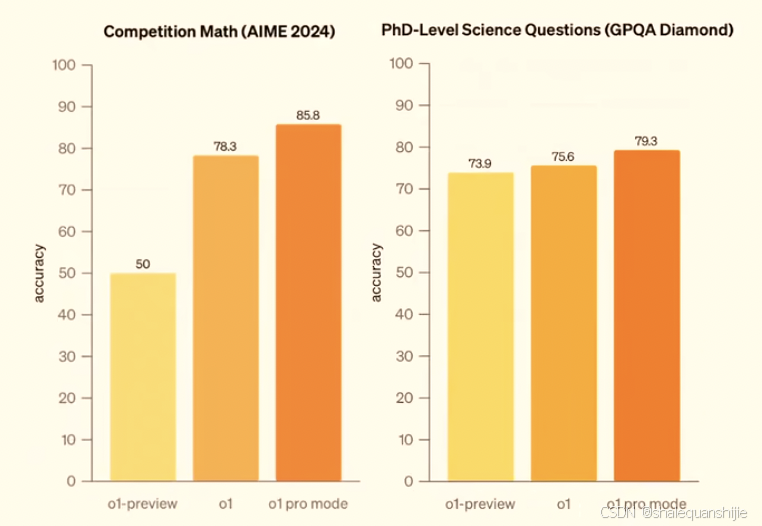
ChatGPT Pro 还支持通过 o1 Pro 模式使用 o1,在此模式下,模型会调用更多计算资源,进行更长时间的推理,以解决更复杂的问题,从而获得最可靠的响应。
-
ChatGPT Pro 为研究人员、工程师以及其他每天使用科研级智能的个人提供了一种加速生产力的方式,使他们能够处于人工智能进展的最前沿。
-
o1 pro mode可以产生更可靠、更准确、更全面的响应,尤其是在数据科学、编程和案例分析等领域。
-
-
-
-
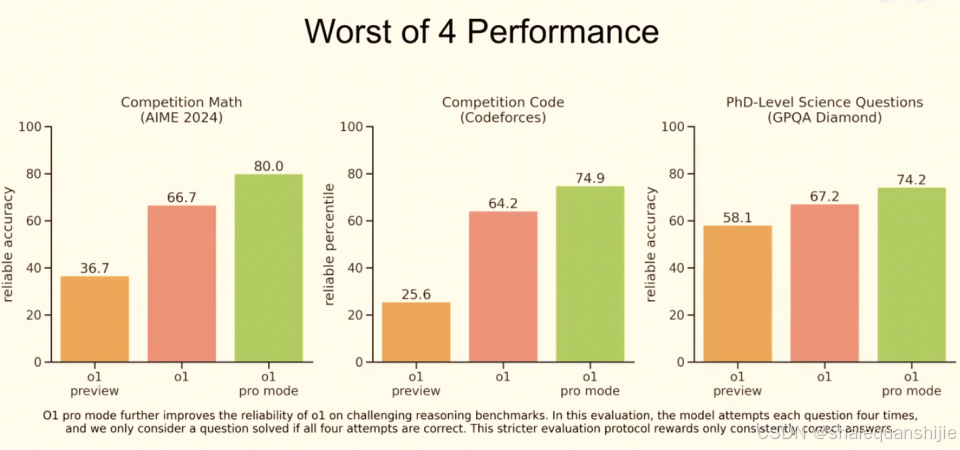
o1 Pro模式的主要优势在于提高了模型的可靠性(improved reliability),采用了更严格的评估标准:只有当模型在四次尝试中全部答对(即“4/4 可靠性”),才认为它成功解决了问题,而不仅仅是答对一次。
-
Day 2- Reinforcement Fine-Tuning(RFT)
link:https://help.openai.com/en/articles/10250364-how-to-access-reinforcement-fine-tuning
目前该功能处于Alpha阶段,OpenAI正在与选定的参与者合作,收集反馈,帮助有效和负责任地使用此功能。暂时没有公开的时间表或更多细节。
-
用户将能够在自己的数据集上对o1进行微调,强化微调(RFT)充分利用了强化学习算法,并预计将在明年初正式发布。
-
强化微调(Reinforcement Fine-Tuning, RFT)是一种新的模型定制技术,能够帮助客户为特定领域的一组狭窄任务创建“专家模型”。它通过用户提供的输入和评分器学习评估模型输出,持续优化模型的思维链(CoT),使其在特定任务上表现更好。
-
开发人员、研究人员及机器学习工程师将首次能够使用强化学习来创建专门应对特定领域任务的专家模型。
-
与监督微调(SFT)不同,RFT不仅让模型模仿输入,而是教会它在特定领域进行新的推理方式。通过为模型提供思考空间并对输出评分,强化学习有助于改善其解决问题的思维方式,并抑制错误答案的倾向。
-
快速高效:RFT 在效率上优于传统技术,尤其在医疗、法律等复杂领域,甚至在只有几十个甚至 12 个例子的情况下,就能完成有效的微调。
-
-
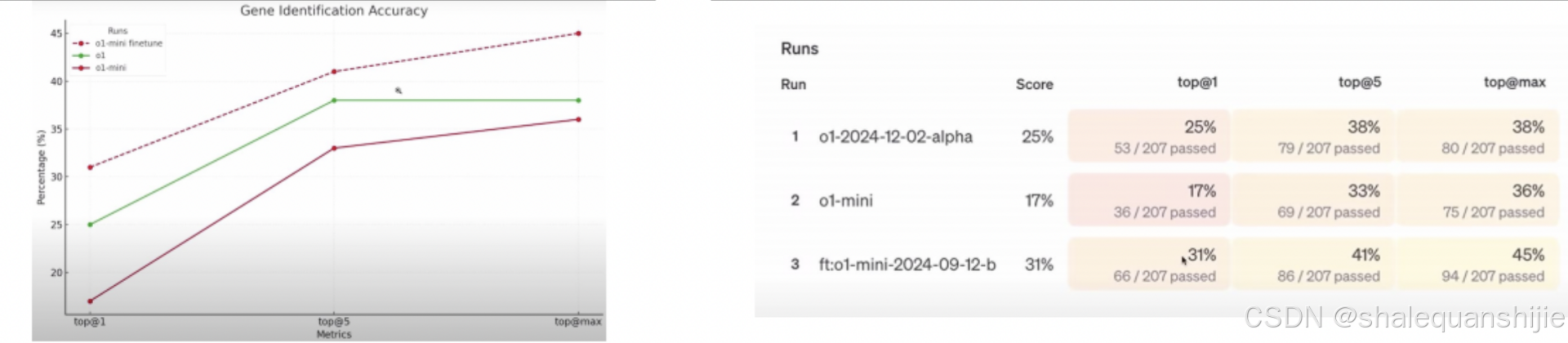
经过强化微调后,模型在特定领域的表现显著提升。发布会上,展示了通过RFT优化的o1mini在多个任务上的表现超过了原版o1。
-
-
新增通用评分器,提供了多种评分机制以覆盖强化微调中的各种需求。同时ÿ
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









